基于测试代价的决策树分类器构造方法与流程
本发明涉及智能服务、机器学习技术领域。
背景技术:
决策树决策方法是机器学习领域中经典算法,得到了广泛应用。早期分类中,一般认为准确率是对分类效果很重要的衡量标准之一。以ID3算法为代表,它主要是在分裂属性选择方法和优化剪支策略两方面的研究。在实际的许多分类问题中,算法ID3存在各种条件的限制。其中最主要一点是缺乏背景知识,从而限制学习过程。如一位脑肿瘤专家在判定一个患头疼的病人时,第一次并不进行最有效果的昂贵扫描,此时专家有经济标准。在这种简单常见的病症下,一开始是简单问题测试或是一些其它更为经济的测试,另外针对于数据流中需要找到最匹配的训练样本。再对此训练样本构建分类器。以增量方式更新分类器。此分类器在进行数据分类的过程中应遵循测试成本最小化归纳规则,以适应更多实际数据分类问题,基于这种需求,本发明提出了更优化的基于测试代价的决策树分类器构造方法。
技术实现要素:
本发明所要解决的技术问题是提供一种更优化的基于测试代价的决策树分类器构造算法。
本发明的目的是:使机器学习决策过程中所产生经济成本最小,构建更优化的决策树分类器。
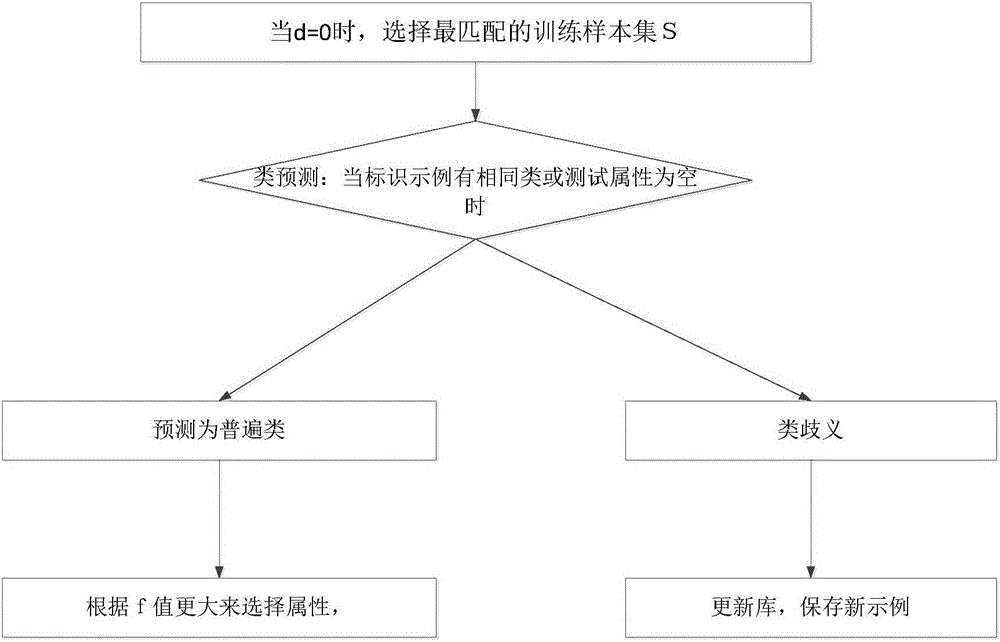
本发明为实现上述目的所采取的技术方案是:本发明从库中数据流中提取最匹配的训练示例样本为标识示例,对新示例进行类预测,若在分类过程中为相同的类,或测试属性为空时,则标识示例类符合此新示例。之后遵循测试成本代价最小原则构建决策树,这里的测试代价限制条件更加严苛,也更优化。测试代价f作为选择属性标准,c作为分裂属性标准。若在叶子结点出现未知类,同时测试成本也更优化,则更新库,保存新示例。更优化的决策树分类器就构成了。
本发明的有益效果是:
1、在第1步就进行了库中训练样本的筛选,提高对未知示例归类的准确率。
2、选择属性限制条件f在之前基础上更加严苛,使在归类过程中付出代价更少。
3、可以实现对未知示例归类基础上,如果未知示例中出现了库中未有类别,同时其代价成本又低,则更新库,保存新的示例,功能更加完善。
附图说明
基于测试代价的决策树分类器构造示意图
具体实施方式
以下,结合示意图对本发明进行详细说明。
本发明的具体实施步骤如下。
步骤1:根据保存示例与新示例之间的特征差值d来标识和鉴定训练示例样本S:
其中xtisaved/new为已有新示例第i属性值,表示它们之间相关性,取值范围为[0,1],当没有数值属性时,即为0,否则就为1;当两比较特征有至少一个值未知,就标记为0.5,当d越大,则标识了更多示例,当d=0时,则找到了最佳匹配训练示例;
步骤2:专家根据实际情况,给出每项属性进行的测试成本costX:
在训练样本集S中进行每一项属性测试需要的费用,记为cost,costX为第X属性测试成本,测试代价由相关专家给出;
步骤3:用户自定义参数经济因子ω,它范围为[0,1],经济因子w为用来校准成本花费的一个变量,当w=1为最大成本花费;完整阈值ct由相关领域专家给出,其取值范围为ct∈[0,1];
步骤4:根据f遍历输入的训练样本集候选属性列表,计算每个候选属性,得出当前选择属性;
步骤4.1:遍历所有训练样本集的属性,计算每个属性的f,选择f值最大的属性作为测试代价决策树分类器的根结点;
候选属性的选择因子f为:
f=I2(X)/ICF(X)
其中I(X)为训练示例集中属性为X的信息增益,ICF(X)为属性X的信息成本函数;
步骤5:对应于步骤4得出的最大候选属性每一个属性值,在结点下生成相应分支(即分裂抽象属性);每个分支样本集合为所有属性值对应分支的训练样本,这样训练样本集为i个子集,i也为属性值个数;
步骤6:将每个子集Si作为新的训练样本集,对各子集递归调用本算法,即重回步骤4,用同样的方法将样本子集分割,产生分支的分支,同时获得相应子集的子集,直到满足以下两条件之一则终止建树过程,即:
条件1:在一个子集或分支结点中所有样例属性都为同一类别,又称之为观测值;
条件2:在一个子集或分支结点中所有样本为空;
步骤7:在叶子结点分类时出现未知类同时又有廉价的测试功能,则更新库保存新的示例。
一、所述步骤4.1计算候选属性的选择因子f,需要求出信息增益函数、信息成本函数、以及在求解过程中会用到信噪比函数,具体计算过程如下:
1、信息成本函数
1)根据信息论,信噪比这一函数功能在数据分析方面得到了广泛的应用,有下式:
有UI+NI=TI(总信息)
得出z()=[UI/NI]=[TI/NI]-1
根据上面的信噪比z()函数和ID3决策树算法原理,有:
ΔT=R(TI)-R(NI)=[2R(TI)/2R(NI)]
由于TI=2R(TI),NI=2R(NI)
所以
2ΔT=[TI/NI],2ΔT=[UI/NI+1]=z()+1
所以上式信噪比函数又可写为z()=2ΔT-1;
2)根据信噪比函数和ΔT函数可得知:
这里ΔTX为属性X信息增量,w为检验经济标准一个变量,w∈[0,1],costX为属性X的测试成本,costX+1>1,当cost=0时,f(cost)有意义;ICF是信息成本函数,用来表征每一属性的选择;
2、信息增益函数I2(X)
这里X为属性,ti为属性X的第i个属性值,{C}为类集合,p(Cj|X=ti)当属性X的值为ti时类为Cj的概率,直到训练样本集有相同类或是属性为空时,这个分类过程结束。
二、所述步骤5分裂属性的选择方法为:
定义分裂抽象属性选择因子为c,未知示例样本属性的叶子结点i的种类个数为m,我们把此叶子结点称为观测值,其中i∈[1,2…,m],已保存训练样本叶子结点数为j,其中j∈[1,2…,n]:
其中,当已保存示例样本集中第j个叶子结点中包含第i类观测值时,h(i,j)=1;相反如果已保存示例样本集第j个叶子结点中不包含第i类观测值,即h(i,j)=0:
当时,我们选择这个抽象属性进行分裂;
当c=0时,更新库,保存新示例对象。
- 还没有人留言评论。精彩留言会获得点赞!