一种多维尺度的异构代价敏感决策树构建方法与流程
本发明涉及机器学习、人工智能以及数据挖掘领域。
背景技术:
决策树相关课题是数据挖掘和机器学习中的一项重要和积极的研究课题。所提出的算法被广泛和成功地应用于实际问题中,如ID3,CART和C4.5,决策树此类经典算法主要是研究准确率的问题,生成的决策树准确率更高。在现有的算法中,有些只考虑测试代价,有些只考虑误分类错误代价,此类被称之为一维尺度代价敏感,其构建的决策树在现实案例中并不能解决综合问题。例如,在代价敏感学习中除了需考虑测试代价和误分类代价对分类的影响,还需考虑待时间代价对分类预测的影响。例如,患者可能存在测试代价约束,也有可能存在等待时间上的约束,根据不同类别需求人所具备的自身资源不同,所需的时间长短也不同,考虑各种代价单位机制不同的问题,另外在构建决策树过程中,采用先剪支技术来解决决策树中过拟合问题,为了解决这种需求,本发明在之前一维和二维尺度代价基础上,提出了一种多维尺度的异构代价敏感决策树构建方法。
技术实现要素:
针对于解决同时考虑测试代价、误分类代价以及等待时间代价影响因子来构建多维尺度决策树过程的问题、考虑各种代价单位机制不同的问题,提出了一种多维尺度的异构代价敏感决策树构建方法。
为解决上述问题,本发明提出了以下技术方案:
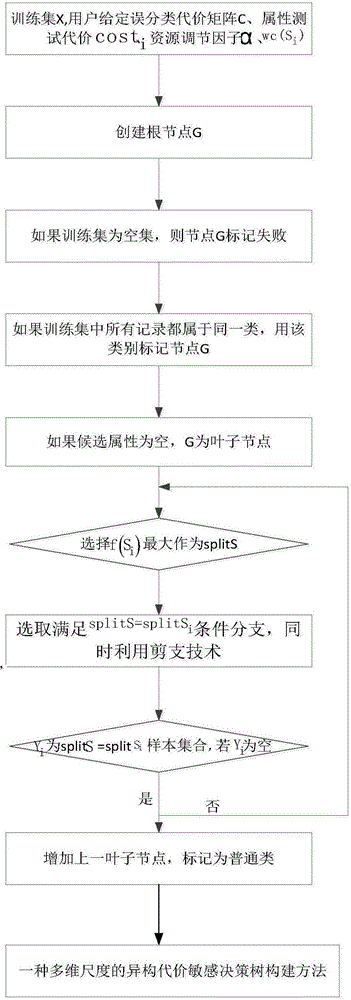
一种多维尺度的异构代价敏感决策树构建方法,包括如下步骤:
步骤1:设训练集中有X个样本,属性个数为n,即n=(S1,S2,…Sn),同时分裂属性Si对应了m个类L,其中Lr∈(L1,L2…,Lm),i∈(1,2…,n),r∈(1,2…,m)。相关领域用户设定好误分类代价矩阵C、属性Si测试代价为costi、资源调节因子∝、相对等待时间代价wc(Si)。
步骤2:创建根节点G。
步骤3:如果训练数据集为空,则返回节点G并标记失败。
步骤4:如果训练数据集中所有记录都属于同一类别,则该类型标记节点G。
步骤5:如果候选属性为空,则返回G为叶子结点,标记为训练数据集中最 普通的类。
步骤6:根据属性Si的目标函数f(Si)从候选属性中选择splitSi。
目标函数f(Si):
averagegini(Si)为信息纯度函数,D(Si)为各种代价效度函数。当选择属性splitSi满足目标函数f(Si)越大,则找到标记节点G。
当出现目标函数f(Si)相等时,为打破平局标准,则按照下面的优先顺序再进行选择:
(1)更大的Dmc(Si)
(2)更小的ZTC(Si)
步骤7:标记节点G为属性splitSi。
步骤8:由节点延伸出满足条件为splitS=splitSi分支,同时利用先剪枝技术对叶子结点进行剪枝操作,一边建树一边剪枝,如果满足以下两条件之一,就停止建树。
8.1这里假设Yi为训练数据集中splitS=splitSi的样本集合,如果Yi为空,加上一个叶子结点,标记为训练数据集中最普通的类。
8.2此结点中所有例子属于同一类。
步骤9:非8.1与8.2中情况,则递归调用步骤6至步骤8。
步骤10:更新训练数据集,保存新的示例数据。
本发明有益效果是:
1、构建的决策树有更好分类准确度,加强了分类能力,避免了当类中有稀有类时,把它当做普通类进行分类。
2、考虑了多种代价影响因子,此生成的决策树模型应用范围要更广,更符合实际的需求。
3、在决策树构建过程中,避免了分裂属性信息存在因过小而被忽略的风险。
4、建树过程中,利用了效度来度量测试代价以及待时间代价总代价能使误分类代价得到最大力度的降低,以及解决了现实中把误分类代价、测试代价以及待时间代价看成同一度量单位的不合理性,形成的决策树具有高的分类精度和降低误分类代价、测试代价以及待时间代价。
5、利用先剪支技术对决策树进行剪支提高了分类学习的速率。
附图说明
图1为一种多维尺度的异构代价敏感决策树构建的流程图
具体实施方式
为解决同时考虑测试代价、误分类代价以及待时间代价影响因子来构建多维尺度决策树过程的问题、以及考虑各种代价单位机制不同的问题,最后生成的决策树更好的规避了过度拟合问题,结合图1对本发明进行了详细说明,其具体实施步骤如下:
步骤1:设训练集中有X个样本,属性个数为n,即n=(S1,S2,…Sn),同时分裂属性Si对应了m个类L,其中Lr∈(L1,L2…,Lm),i∈(1,2…,n),r∈(1,2…,m)。相关领域用户设定好误分类代价矩阵C、属性Si测试代价为costi、资源调节因子∝、wc(Si)—相对等待时间代价值。
1)上述步骤1中所述的误分类代价矩阵C具体设定如下:
相关领域用户误分类代价矩阵C的设定:
类别标识个数为m,则该数据的代价矩阵m×m方阵是:
其中cij表示第j类数据分为第i类的代价,如果i=j为正确分类,则cij=0,否则为错误分类cij≠0,其值由相关领域用户给定,这里i,j∈(1,2,…,m)
步骤2:创建根节点G。
步骤3:如果训练数据集为空,则返回节点G并标记失败。
步骤4:如果训练数据集中所有记录都属于同一类别,则该类型标记节点G。
步骤5:如果候选属性为空,则返回G为叶子结点,标记为训练数据集中最普通的类。
步骤6:根据属性Si的目标函数f(Si)从候选属性中选择splitSi。
目标函数f(Si):
averagegini(Si)为信息纯度函数,D(Si)为代价效度函数,
其中D(Si)—代价效度函数公式为:
Dmc(Si)为误分类损失代价减少函数,ZTC(Si)为测试代价与相对等待时间代 价的总代价函数。
当选择属性splitSi满足目标函数f(Si)越大,,则找到标记节点G。
2)上述步骤6求解目标函数f(Si),需要先求解averagegini(Si)—信息纯度函数、D(Si)—代价效度函数,具体求解过程如下:
2.1)计算averagegini(Yi)—信息纯度函数的具体过程如下:
基尼指数是一种不纯度分裂方法,基尼指数表示为gini(Yi),定义为:
其中p(Li/Yi)为类别Li在属性值Yi处的相对概率,当gini(Yi)=0时,即在此结
点处所有记录都属于同一类别,增加一叶子结点,即信息纯度越大。反之,gini(Yi)最大,得到的有用信息最小,则继续根据目标函数f(Si)候选下一个属性。
根据gini(Yi)可以得知averagegini(Si)
这里属性S有j个属性值,即属性值为(Y1,Y2,…,Yj)
信息纯度函数averagegini(Si)作用:可以提高决策树的分类精度
2.2)求解D(Si)—代价效度函数
求解D(Si)—代价效度函数,需要先求解Dmc(Si)—误分类损失代价减少函数和ZTC(Si)—测试代价与相对等待时间代价的总代价函数。
2.2.1)求解Dmc(Si)—误分类损失代价减少函数具体过程如下:
如果对事例预测的类标签La与真实类标签Lb相同,则分类正确,此时的误分类代价C(La,Lb)=0,如果La≠Lb,则C(La,Lb)≠0。在分类过程中,通常不知道事例的实际标签,所以这里用误分类代价的期望Emc来代替误分类代价的值,即,把一个事例的类标签预测为La的误分类代价的期望为:
其中,L为数据集中所有类标签集合,p(Lb/Si)为当前选择属性Si中含有类Lb的概率,C(La,Lb)为把类Lb误分为类La的代价花费。
分裂属性的选择还应该以误分类代价降低最大为基本原则,在没有选择属性 Si时有一个总的误分类代价mc,选择任何一个属性进行测试,都有可能减少一定的误分类代价,这里构造出误分类损失代价减少函数Dmc(Si)。
Dmc(Si)=mc-Emc(Si,La)
Mc为还没有选择分裂属性Si前的所有误分类代价的总和,这个可以根据用户设定的误分类代价矩阵很容易求得出来。
2.2.2)求解ZTC(Si)—测试代价与相对等待时间代价的总代价函数具体过程如下:
ZTC(Si)=TC(Si)+∝wc(Si)
其中∝是个调节因子,不同资源∝不同,资源越多∝越大,反之也成立。TC(Si)为属性测试代价函数,wc(Si)为相对等待时间代价函数,wc(Si)由专家确定。
属性测试代价为TC(Si)设定如下:
TC(Si)=(1+costi)
其中costi为属性Si测试代价,这个由用户指定
以下具体介绍相对等待时间代价wc(Si):
等待时间代价与时间有关,即我们可以用数值来描述这些时间敏感代价,如果结果可以马上得到,等待时间代价为0;如果结果要几天,就由相应专家确定一个数值。另外规定,如果一定要这个测试结果出来才能进行下一个测试,即使等待的时间不多,如半天或一天,都把这个等待时间代价设为一个很大的常数,即m→∞。
等待时间同时还和当地资源有关,同时考虑时间代价和资源约束代价。
当出现目标函数f(Si)相等时,为打破平局标准,则按照下面的优先顺序再进行选择:
(1)更大的Dmc(Si)
(2)更小的ZTC(Si)
步骤7:标记节点G为属性splitS。
步骤8:由节点延伸出满足条件为splitS=splitSi分支,同时利用先剪支技术对叶子结点进行剪枝操作,一边建树一边剪枝,如果满足以下两条件之一,就停止建树。
8.1这里假设Yi为训练数据集中splitS=splitSi的样本集合,如果Yi为空,加上一个叶子结点,标记为训练数据集中最普通的类。
8.2此节点中所有例子属于同一类。
3)上述步骤8所述的先剪枝技术,其判定条件具体如下:
为一个叶子结点类Lr的样本数,X为训练集总体样本数,p为用户基于训练集的样本个数百分比的最小值设定的一个适当的阈值。剪枝条件首先要达到用户指定条件。
步骤9:非8.1与8.2中情况,则递归调用步骤6至步骤8。
步骤10:更新训练数据集,保存新的示例数据。
一种多维尺度的异构代价敏感决策树构建方法,其伪代码计算过程如下:
输入:X个样本训练集,误分类代价矩阵C、属性Si测试代价为costi、资源调节因子∝、wc(Si)—相对等待时间代价。
输出:一种多维尺度的异构代价敏感决策树构建方法。
- 还没有人留言评论。精彩留言会获得点赞!