一种监控系统高频数据的存储及查询方法与流程
本发明涉及一种数据存储方法,具体的说,涉及了一种监控系统高频数据的存储及查询方法。
背景技术:
在监控系统中,通常需要存储大量的原始数据供后期查询验证等。在此类系统中,不仅需要保证存储数据的完整性和准确性,还需要提供可靠的数据循环覆盖策略。此类系统最常用的查询方式是按数据产生的时间段查询,因此需要保证按时间段查询的快速性。
目前现有的做法是将数据存储到数据库中,数据库作为一种通用的存储工具,更多的是考虑常用数据存储,此类方法不适合这种特定的场合,存在的缺点如下:1、占用空间大,数据存储到数据库中不能进行有效的压缩,并且数据库产生的自有字段也会占用一定的空间;2、没循环覆盖,数据库存储数据后,需要另外的管理过程来删除超量旧数据以供新数据的存入,不能自动循环覆盖;3、查询速度不理想,数据库虽然可以建立索引,但当存储数据达到数百万条,数千万条时,查询效果并不好,尤其是运行在嵌入式系统上时,系统资源的有限性更加凸显这一问题;4、数据不可恢复,当存储硬件出现问题后,由于数据库的黑盒特性,会导致数据丢失,不可恢复或不好恢复。
为了解决以上存在的问题,人们一直在寻求一种理想的技术解决方案。
技术实现要素:
本发明的目的是针对现有技术的不足,提供一种结构明确,占用空间小,可以自动循环覆盖和快速查找的监控系统高频数据的存储及查询方法。
为了实现上述目的,本发明所采用的技术方案是:一种监控系统高频数据的存储及查询方法,当监控系统接收到数据后,解析数据字段,加入时间戳,再存入到缓冲队列中;存储线程定时从缓冲队列中取出数据,写入存储文件并更新存储记录数据分索引和总索引文件;
当查询线程接收到按时间段查询的请求后,先读取总索引文件,确定起始和结束存储文件,然后读取存储文件分索引,确定存储文件的起始和结束位置,最后读取存储文件返回查询结果;
其中,所述监控系统的存储系统在初始阶段生成一个总索引文件和多个存储文件。
基于上述,所述总索引文件的数据结构包括基本信息、开始存储文件编号、结束存储文件编号和顺次排列的存储文件信息。
基于上述,每个存储文件信息包括数据记录开始时间、数据记录结束时间、下次存储数据写入的偏移位和记录个数。
基于上述,所述存储文件的数据结构包括数据部分和索引部分;
所述数据部分包括多个存储数据记录,每个存储数据记录包括头部和多条存储数据,所述头部包括存储数据时间戳、存储数据记录总长度,所述存储数据包括存储数据的时间戳和存储数据的其他字段;
所述索引部分包括顺次排列的存储数据记录分索引,所述存储数据记录分索引包括存储数据时间戳、存储数据开始位置和存储数据长度。
基于上述,所述数据部分和所述索引部分以秒为单位记录数据。
本发明相对现有技术具有突出的实质性特点和显著的进步,具体的说,本发明通过对存储系统中的存储数据的某些字段的压缩,减小了占用的存储空间;2、存储数据采用自动循环覆盖,避免了对存储空间的管理;3、存储系统采用二级索引,可以对超大量数据实现快速查找;4、存储系统的数据结构明确,当存储系统出现问题后,可以实现绝大多数数据的恢复。
附图说明
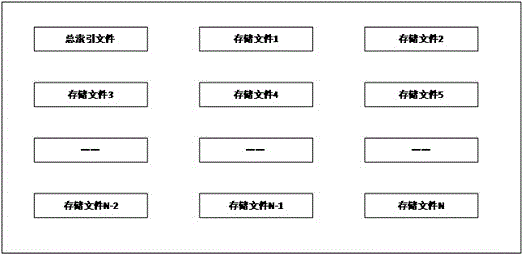
图1是本发明的存储系统的文件结构。
图2是本发明的总索引文件的数据结构。
图3是本发明的存储文件的数据结构。
具体实施方式
下面通过具体实施方式,对本发明的技术方案做进一步的详细描述。
如图1-3所示,一种监控系统高频数据的存储及查询方法,当监控系统接收到数据后,解析数据字段,加入时间戳,再存入到缓冲队列中;存储线程定时从缓冲队列中取出数据,写入存储文件并更新存储数据记录分索引和总索引文件;当查询线程接收到按时间段查询的请求后,先读取总索引文件,确定起始和结束存储文件,然后读取存储文件分索引,确定存储文件的起始和结束位置,最后读取存储文件返回查询结果。
所述监控系统的存储系统在初始阶段生成一个总索引文件和多个存储文件。
所述总索引文件的数据结构包括基本信息、开始存储文件编号、结束存储文件编号和顺次排列的存储文件信息。每个存储文件信息包括数据记录开始时间、数据记录结束时间、下次存储数据写入的偏移位和记录个数。
所述存储文件的数据结构包括数据部分和索引部分;所述数据部分包括多个存储数据记录,每个存储数据记录包括头部和多条存储数据,所述头部包括存储数据时间戳、存储数据记录总长度,所述存储数据包括存储数据的时间戳和存储数据的其他字段;所述索引部分包括顺次排列的存储数据记录分索引,所述存储数据记录分索引包括存储数据时间戳、存储数据开始位置和存储数据长度。其中,所述数据部分和所述索引部分以秒为单位记录数据。
具体的,该监控系统高频数据的存储及查询方法为:
存储过程
首先,监控系统接收到具体数据后,解析具体字段,加入时间戳(可以精确到毫秒),作为一条数据存入到缓冲队列中。
然后,存储线程定时(依具体而定,例如10s)从缓冲队列中取出当前秒之前的所有数据,以秒为单位组合成存储数据记录并生成相应的存储数据记录分索引,接着将该段时间的存储数据写入到存储文件中,完成后写入总索引文件。当前存储文件写满后顺序写到下个存储文件中,存储文件全部写完后,循环覆盖开始的存储文件写入。
需要特别说明的是,总索引文件从系统启动后就从文件读入到内存中缓存,每次存储文件写入成功后更新总索引文件缓存,每分钟总索引文件缓存同步到文件中一次。另外,因为存储过程不是实时写入,中间存在缓存。如果不是7*24小时运行系统,需要配备UPS或者超级电容等设备或器件用以确保在断电时存储数据的完全写入。
查询过程
首先,根据接收到查询数据中的开始和结束时间,查找总索引文件缓存,得到查询区间的开始存储文件和结束存储文件;
然后,根据前面查到的开始存储文件和结束存储文件,按总索引文件缓存中的各自记录个数,读取相应长度存储数据分索引到内存中,按快速查找算法分别查找查询开始文件偏移和查询结束文件偏移;
接下来,根据开始存储文件、结束存储文件和相应的偏移,读取中间的数据并返回给查询者。如果需要解析查询结果,可以在该步骤解析后再返回。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制;尽管参照较佳实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换;而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
- 还没有人留言评论。精彩留言会获得点赞!