一种社交网络中社团话题演化挖掘方法与流程
本发明涉及社交网络数据挖掘领域,具体涉及了一种应用于社交网络社团话题的演化挖掘方法。
背景技术:
随着网络信息技术的不断发展,互联网已经成为主流的传播媒介。与传统的方式相比,社交网络具有大范围、大数据和突发性强等特点,社交网络中社团话题演化也成为当下关注的热点。目前,对话题演化的分析模型主要分为两类:离散观点模型和连续观点模型。离散观点模型包括:1、先离散时间型,通过把时间分成不同时间窗口的方法进行分析,在每个窗口中处理、拆分文本,进而研究话题演化过程。Alsumait[1]提出了一种在线LDA模型,该模型运用历史数据,根据时间间隔中相应的话题数据进行LDA建模,分析演化轨迹。2、后离散时间型。该方法中时间不作为一个考虑因素,而是直接通过LDA建模,然后将话题分配到相对应的时间窗口,分别计算话题记录窗口的强度,通过话题强度变化研究整个话题演化。
连续观点模型是把时间作为一个连续的变量,在话题演化模型中添加这一变量。Wang[2]在原有的基础上引入时间变量提出了TOT模型(topic over time),产生Γ分布的时间属性值,将其赋给文本中每个单词新的时间属性。但该模型仅讨论了话题强度变化关系,并未涉及话题内容的演化。Nallapati[3]等人提出了MTTM(Multi-scale topic tomography)模型,研究了多时间粒度的话题演化问题。Blei等人[4]提出了DTM(Dynamic topic model)动态话题模型,采用状态空间记录话题内容和分布强度的变化。但上述模型都是对文本集进行全局建模,无法增量处理话题演化问题。
研究话题演化过程中,话题时间判定是一个重要步骤。话题主要分为事件性和非事件性两类。事件性话题即对最新时事的关注,拥有时间性强的特点,话题和话题时间有比较单一的关联,是一种很强的位置依赖关系。非事件性话题时间呈现区域性,贯穿整个话题事件。洪宇等人[5]提出将话题映射到话题片段,再由话题片段映射到话题时间。但该方法未考虑话题演化过程中语义的动态变化。
[1]Alsumait L,Barbara D,Domeniconi C.On-line LDA:Adaptive topic modles for mining text streams with application to topic and tracking[C].Data mining,2008.ICDM’08.2008:3-12.
[2]Wang X,McCallum A.Topic over time:A non-Markov Continuous-time Modle of Topical Trends[C].ACM SIGKDD 2006:424-433.
[3]Nallapati R M,Cohen W,Ditmore S,Lafferty J,Ung K.Multi scale topic tomography.In:Proceeding of the 13th ACM International Conference on Knowledge Discovery and Data Mining(SIGKDD).San Joes,USA:ACM,2007:520-529.
[4]Blei D M,Lafferty J D.Dynamic topic models.In:Proceedings of the 23rd International Conference on Machine Learning.Pittsburgh,USA:ACM,2006.113-120.
[5]洪宇,仓玉,姚建民等.话题追踪中静态和动态话题模型的核捕捉衰减.软件学报,2010,23(5):1100-1119.
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,提供一种社交网络中社团话题演化挖掘的方法,综合考虑突发性、连续性、密集性对话题随时间演化的影响,实现准确的话题演化挖掘方法。
为了达到上述目的,本发明采用以下技术方案:
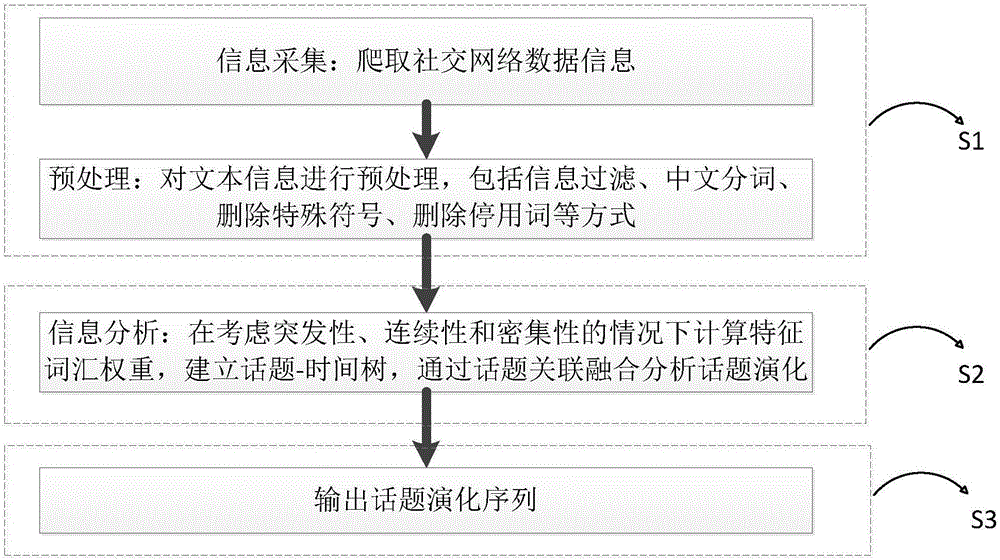
社交网络话题演化挖掘方法,包括下述步骤:
S1、采集社交网络数据,并对数据进行预处理;
S2、分析话题数据,在考虑突发性、连续性、密集性的基础上建立特征值计算模型,建立话题-时间树,抽取话题时间,并对文本进行聚类分析;
S3、实现话题演化序列的输出。话题演化序列是文本聚类的结果,能够显示话题演化轨迹,具有现实意义。
作为优选的,步骤S1中,数据来源于社交网络,用户量大、更新速度快,经过爬虫得到的原始数据集具有“多、乱、杂”的特点,建立数据字典,对其进行数据预处理(删除特殊符号、去除链接、中文分词、去除停用词等)能够保证数据集的有效性,为之后建模分析话题演化提供保障。所述步骤S1中,预处理中,中文分词作为关键;首先,建立好一个字典,把输入的中文文本和字典进行匹配,根据唯一的匹配结果,把该词分离为一个独立的词;如果输入词不在字典中,就把该词加入字典,作为扩充字典。
作为优选的,步骤S2中,同时对突发性、连续性、密集性进行定量分析,建立特征值计算模型;包括下述步骤:
S21、定义突发性特征值。构建时间与词项的列联表,设计K2的独立性检测。根据时间与词项之间的关联度归一化词项的卡方统计值,用该值表示突发性特征值。K2的独立性检测即为卡方检验,根据次数资料判断两类因子彼此相关或者相互独立。拟合度公式为其中,n为试验次数,fi为落入第i区间的频率,pi为落入第i区间的概率。
S22、定义连续性特征值。连续性权重的计算需要用到时态表达规范化处理,通过分析社交网络的类别和网页结构,提出话题-时间关系树,通过话题和时间信息间位置、语义两种相互依存关系,反映社交网络话题和话题时间之间的映射关系。
S23、定义密集性特征值。通过特征在当前时间窗口T出现的次数和截止该时间窗口出现的次数比定义特征在时间上的密集程度。对每个时间窗口做增量更新的操作即可得到话题特征对整个演化轨迹的密集性。
S24、定义原始特征值。利用传统的增量式TF×IDF模型来表示词项在文本中的基本权重,作为基础权重。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明的模型与TOT模型对比,在考虑话题强度的基础上考虑了话题内容的变化;与DTM模型相比,能够实现增量处理话题演化挖掘。在考虑连续性权重方面。
2、话题-时间树结合了不同类型的社交网络和网页结构特点,采用叶子话题时间合并产生话题时间的方法,优于传统的采用发布时间和网页统计时间方法。
3、本发明同时考虑了话题演化过程中的突发性、连续性、密集性,结合传统的TF×IDF模型,利用层次聚类的方法获取特征演化序列。相较于划分聚类(如k-means)而言,层次聚类具有树状特点,在处理大数据时效率较高。综合考虑以上属性,能够提升话题演化轨迹提取的准确性。
4、实现话题演化轨迹提取并输出,具有现实意义和价值。
附图说明
图1是本发明社交网络中社团话题演化挖掘方法的流程图;
图2是本发明话题演化特征属性图;
图3是本发明话题-时间树图;
图4是本发明的数据预处理方式图;
图5是本发明话题演化方法实验结果。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本实施例社交网络社团话题演化挖掘方法,该方法包括下述步骤:
S1、采集社交网络数据,并对数据进行预处理,如图4所示;
S2、分析话题数据,如图2所示,在考虑突发性、连续性、密集性的基础上建立特征值计算模型,建立话题-时间树,如图3所示,抽取话题时间,并对文本进行聚类分析;
S3、实现话题演化序列的输出,如图5所示。
下面对于本发明中的关键技术做进一步的分析:
步骤S2中,首先定义突发性特征值、连续性特征值、密集性特征值和基础特征值(TF×IDF值)并实现其计算方法,建立话题-时间树提取话题时间,利用层次聚类对词项进行聚类。
S21、突发性。构建时间和词项的列联表表示其关联性,通过归一化词项wi的卡方统计值表示词项的突发性,定义为:其中,Nwt表示t时刻话题中出现词w;N-wt表示t时刻话题中未出现词w;NwT表示t时刻之前话题中出现过词w;N-wT表示t时刻之前话题中未出现过词w。
计算方法代码描述如下:
S22、连续性。话题特征在它所载的话题演化阶段内会表现出连续性,结合话题-时间关系树,通过时态表达规范处理,定义:
其中,t(di)表示具有特征f的第i个文本的话题时间;tmax表示现有文本集合中最新文本的话题时间;tmin表示现有文本集合中最早文本的话题时间;N表示文本流中文本的总数目。
计算方法代码描述如下:
S23、密集性。特征f在当前时间窗口T出现的次数和截至该时间窗口出现的次数比说明特征f在时间上的密集程度,定义:
其中,D表示窗口T中所有的文档集合;CD(f)表示特征f在最新文档集合D上的出现总次数;CT-1(f)表示特征f在T之前出现的总次数。
计算方法代码描述如下:
通过上述对特征值的定义并计算,在话题-时间树种提取话题时间,利用层次聚类的方式获取聚类结果,得到最终的话题演化序列。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!