用于对人才的数据驱动辨识的系统和方法与流程
本申请要求提交于2015年12月23日的美国临时申请号62/387,440的优先权,该申请的内容以其全文并入本文。
背景技术:
为某一职位招聘合适的候选人对于公司而言可能是一项挑战性任务。通常而言,公司可以依赖于招聘人员和面试来确定申请人对于他们的团队而言是否将是理想的适合者。然而,找到新员工可能是耗时的、昂贵的,并且在一些情况下是徒劳的过程,在申请人池庞大的情况下尤为如此。相反,确定合适的职业道路对于新求职者而言可能是艰巨的任务,并且现有的求职资源常常并非是为个体而定制的。基于期望的特点简档来找到理想员工或工作的平台仍然不可用。
技术实现要素:
对于可以由公司和不同实体使用的系统和方法存在需求,以便:(1)辨识适应公司的具体职位需求的人才,以及(2)辨识最佳员工并推荐将这些员工安置在尽可能发挥他们潜力的职位上。
本文公开的系统和方法可以解决至少以上需求。在一些实施方式中,所述系统和方法可以基于从一个或多个基于神经科学的任务(或测试)获得的候选人的行为输出将候选人与公司相匹配。可以将候选人的行为输出与代表公司中具体职位的理想员工的员工模型进行比较。能够以基于表现的游戏的形式提供多个基于神经科学的任务,该基于表现的游戏被设计用于测试/测量一系列广泛的情绪和认知特质(emotional and cognitive trait)。使用基于神经科学的游戏以及针对员工模型对这些游戏结果的分析可以帮助公司优化其招聘和候选人寻找过程。除了作为公司有用的招聘工具之外,本文公开的系统和方法还可以辅助个体进行职业规划和才能辨识。通过使用测量一系列广泛的情绪和认知特质的测试,所述系统和方法可以探明测试主体的优势和不足,并应用该信息来推荐哪些(一个或多个)领域适合于测试主体。
根据一个方面,提供了一种用于实现基于游戏的人员招聘方法的系统。所述系统可以包括与关联多个参与者的多个计算设备通信的服务器。所述服务器可以包括用于存储交互式媒体和第一组软件指令的存储器,以及被配置用于执行所述第一组软件指令的一个或多个处理器,以向与多个参与者相关联的多个计算设备提供交互式媒体。所述交互式媒体可以包括至少一个招聘游戏(recruiting game),所述至少一个招聘游戏被设计用于测量所述参与者的一种或多种情绪和认知特质。所述招聘游戏可以包括与多个选定的基于神经科学的计算机化任务相关联的多个预定义组的图形视觉对象。所述多个预定义组的视觉对象可以在所述计算设备的图形显示器上显示给所述参与者。
所述一个或多个处理器还可以被配置用于执行所述第一组软件指令,以在所述参与者通过使用一个或多个输入设备操纵所述图形显示器上的所述图形视觉对象中的一个或多个以完成所述多个选定的基于神经科学的计算机化任务来玩所述计算设备的所述图形显示器上的所述招聘游戏时从所述计算设备接收输入数据。
所述一个或多个处理器还可以被配置用于执行所述第一组软件指令,以分析来源于所述参与者对所述招聘游戏内的所述一个或多个图形视觉对象的操纵的所述输入数据,以(1)基于所述参与者对所述(一个或多个)图形视觉对象的操纵程度,提取对所述参与者的情绪和认知特质的测量,(2)基于对所述参与者的情绪和认知特质的所述测量生成统计模型,其中所述统计模型代表选定组的参与者,和(3)通过将对所述参与者的情绪和认知特质的所述测量与所述统计模型进行比较来分类每个参与者是在组内还是组外。
所述系统还可以包括至少一个计算设备,所述计算设备包括用于存储第二组软件指令的存储器,以及被配置用于执行所述第二组软件指令的一个或多个处理器,以从所述服务器接收所述分析的输入数据,并在所述至少一个计算设备的图形显示器上将所述分析的输入数据可视化地显示为一组图形视觉对象。所述组的图形视觉对象可以包括:(i)第一密度函数图,其对应于被分类为组外的参与者,(ii)第二密度函数图,其对应于被分类为组内的参与者,以及(iii)决策边界,其相对于所述第一密度函数图和所述第二密度函数图中的每一个定义。所述决策边界可以由实体使用,以基于候选人在所述招聘游戏中所测量的表现来确定所述候选人被招聘到目标职位的适合性。
在一些实施方式中,所述一个或多个处理器可以被配置用于通过将对所述候选人的情绪和认知特质的测量与所述统计模型进行比较来测量所述候选人在所述招聘游戏中的表现。
在一些实施方式中,所述一个或多个处理器可以被配置用于基于对所述候选人的情绪和认知特质的所述测量与所述统计模型的所述比较来为所述候选人生成适配分数。所述适配分数可以指示所述候选人与选定组的所述参与者的匹配水平。所述一个或多个处理器还可以被配置用于在至少一个计算设备的图形显示器上显示指示所述适配分数的点。可以通过将所述点叠加在所述图形显示器上的所述第一密度函数图和所述第二密度函数图上来显示所述点。所述一个或多个处理器还可以被配置用于将所述候选人分类为:(1)当所述点位于相对于所述决策边界的第一区域时的组外,或(2)当所述点位于相对于所述决策边界的第二区域时的组内。
在一些实施方式中,所述决策边界可以定义在所述第一密度函数图与所述第二密度函数图之间的重叠区域中。所述第一区域可以与所述第一密度函数图重叠,并且所述第二区域可以与所述第二密度函数图重叠。当所述点位于所述第一区域中时,可以确定所述候选人更类似于被分类为组外的所述参与者,并且更不类似于被分类为组内的所述参与者。相反,当所述点位于所述第二区域中时,可以确定所述候选人更类似于被分类为组内的所述参与者,并且更不类似于被分类为组外的所述参与者。
在一些实施方式中,所述候选人被正确分类为组外的概率可以随着所述点远离所述决策边界进入所述第一区域的距离增加而增大。相反,所述候选人被正确分类为组内的概率可以随着所述点远离所述决策边界进入所述第二区域的距离增加而增大。
在一些实施方式中,当所述点位于所述第一区域中时,可以确定所述候选人不太适合于所述目标职位,并且当所述点位于所述第二区域中时,可以确定所述候选人更适合于所述目标职位。所述候选人对所述目标职位的适合性可以被确定为随着所述点远离所述决策边界进入所述第一区域的距离增加而减小。相反,所述候选人对所述目标职位的适合性可以被确定为随着所述点远离所述决策边界进入所述第二区域的距离增加而增大。
在一些实施方式中,所述决策边界相对于所述图形显示器上的所述第一密度图和所述第二密度图的位置可以由所述实体来调整,并且当调整所述决策边界的所述位置时,被分类为组内或组外的参与者的数目可以发生变化。例如,所述决策边界的所述位置可以在所述图形显示器上以第一方向调整,使得更多数目的参与者被分类为组外且更少数目的参与者被分类为组内。相反,所述决策边界的所述位置可以在所述图形显示器上以第二方向调整,使得更多数目的参与者被分类为组内且更少数目的参与者被分类为组外。所述第二方向可以与所述第一方向相反。当以所述第一方向调整所述决策边界的所述位置时,可以将更多数目的候选人分类为组外,并且可以将更少数目的候选人分类为组内。相反,当以所述第二方向调整所述决策边界的所述位置时,可以将更多数目的候选人分类为组内,并且将更少数目的候选人分类为组外。
在一些实施方式中,所述一个或多个处理器可以被配置用于基于对所述候选人的情绪和认知特质的测量与所述统计模型的比较来为多个所述候选人生成多个适配分数。所述适配分数可以指示所述候选人与所述选定组的所述参与者的匹配水平。所述一个或多个处理器还可以被配置用于在所述图形显示器上达到指示所述多个适配分数的多个点的显示。可以通过将所述点叠加在所述第一密度函数图和所述第二密度函数图上来显示所述多个点。
在一些实施方式中,当所述多个参与者正在所述多个计算设备上玩所述招聘游戏时,所述多个计算设备可以彼此通信,并且与被配置用于提供所述交互式媒体的所述服务器通信。所述输入数据可以存储在所述服务器的所述存储器中。所述输入数据可以包括每个参与者在所述招聘游戏中执行所述多个选定的基于神经科学的计算机化任务的历史和/或当前表现数据。所述一个或多个处理器可以被配置用于基于每个参与者的历史和/或当前表现数据来预测每个参与者在所述招聘游戏中执行所述多个选定的基于神经科学的计算机化任务的将来表现。
在一些实施方式中,所述历史和/或当前表现数据可以包括:(1)每个参与者在所述选定的基于神经科学的计算机化任务中的一个或多个上花费的时间量,(2)每个参与者完成所述选定的基于神经科学的计算机化任务中的一个或多个所采取的尝试数,(3)每个参与者完成所述选定的基于神经科学的计算机化任务中的一个或多个所采取的不同行动,(4)每个参与者执行所述不同行动中的一个或多个所占据的时间量,(5)每个参与者执行所述不同行动中的一个或多个的准确度,和/或(6)每个参与者在做出某些决策或判断以完成所述选定的基于神经科学的计算机化任务中的一个或多个时所应用的权重。
在一些实施方式中,所述一个或多个处理器可以被配置用于分析所述输入数据以确定每个参与者是否已经正确地选择、放置和/或使用不同的视觉对象以在所述招聘游戏中完成所述多个选定的基于神经科学的计算机化任务。所述处理器还可以被配置用于分析所述输入数据以评估每个参与者的学习、认知技能以及从玩所述招聘游戏中所犯的先前错误中学习的能力。在一些情况下,所述处理器可以被配置用于在所述招聘游戏中以随机方式对所述多个参与者中的两个或更多个参与者进行配对,使得每个参与者不知道(一个或多个)其他配对参与者的身份,并且所述多个选定的基于神经科学的计算机化任务中的至少一个可以被设计用于测试所述配对参与者之间的信任水平和/或宽容水平(generosity level)。
在一些实施方式中,所述统计模型可以被配置用于在所述多个参与者玩多轮相同的招聘游戏时和/或当所述多个参与者玩多个不同的招聘游戏时动态地计入(factor in)对所述参与者的情绪和认知特质的所述测量的变化。
在一些实施方式中,所述一个或多个处理器可以被配置用于通过遮掩正在玩所述招聘游戏的所述参与者的身份来去辨识(de-identify)所述输入数据,以及在分析所述输入数据之前将所述去辨识的输入数据存储在所述服务器的所述存储器中。
在一些实施方式中,所述多个参与者可以被所述实体雇用。所述选定组的参与者可以对应于所述实体的一组员工,所述实体的一组员工至少满足由所述实体预定义的一组工作表现度量。所述统计模型可以与所述组的工作表现度量相关。
在一些实施方式中,可以通过由所述参与者使用一个或多个输入设备选择和/或空间操纵所述图形显示器上的所述一个或多个图形视觉对象以完成所述多个选定的基于神经科学的计算机化的任务来达到对所述一个或多个图形视觉对象的所述操纵。可以基于所述参与者在完成所述多个选定的基于神经科学的计算机化任务中的速度、准确度和/或判断来测量所述参与者的所述多种情绪和认知特质。
在一些实施方式中,所述招聘游戏可以被配置成允许所述多个参与者通过所述图形显示器上的所述一个或多个图形视觉对象来彼此交互,以便完成所述多个选定的基于神经科学的计算机化任务。在一些情况下,可以为多个不同的领域、功能、行业和/或实体生成不同的统计模型。
在本发明的另一个方面提供了一种计算机实现的基于游戏的人员招聘方法。所述方法可以包括向与多个参与者相关联的多个计算设备提供交互式媒体。所述交互式媒体可以包括至少一个招聘游戏,所述至少一个招聘游戏被设计用于测量所述参与者的一种或多种情绪和认知特质。所述招聘游戏可以包括与多个选定的基于神经科学的计算机化任务相关联的多个预定义组的图形视觉对象。所述多个预定义组的视觉对象可以在所述计算设备的图形显示器上显示给所述参与者。
所述方法还可以包括在所述参与者通过操纵所述图形显示器上的所述图形视觉对象中的一个或多个以完成所述多个选定的基于神经科学的计算机化任务来玩所述计算设备的所述图形显示器上的所述招聘游戏时从所述计算设备接收输入数据。
所述方法还可以包括分析来源于所述参与者对所述招聘游戏内的所述一个或多个图形视觉对象的操纵的所述输入数据,以(1)基于所述参与者对所述(一个或多个)图形视觉对象的操纵程度,提取对所述参与者的情绪和认知特质的测量,(2)基于对所述参与者的情绪和认知特质的所述测量生成统计模型,其中所述统计模型代表选定组的参与者,和(3)通过将对所述参与者的情绪和认知特质的所述测量与所述统计模型进行比较来分类每个参与者是在组内还是组外。
另外,所述方法可以包括将所述分析的输入数据可视化地显示为一组图形视觉对象,包括:(i)第一密度函数图,其对应于被分类为组外的参与者,(ii)第二密度函数图,其对应于被分类为组内的参与者,以及(iii)决策边界,其相对于所述第一密度函数图和所述第二密度函数图中的每一个定义。所述决策边界可以由实体使用,以基于候选人在所述招聘游戏中所测量的表现来确定所述候选人被招聘到目标职位的适合性。
在本发明的另一个方面,提供了一种存储指令的有形计算机可读介质,所述指令在由一个或多个服务器执行时使所述一个或多个服务器执行计算机实现的基于神经科学的人员招聘方法。所述方法可以包括向与多个参与者相关联的多个计算设备提供交互式媒体。所述交互式媒体可以包括至少一个招聘游戏,所述至少一个招聘游戏被设计用于测量所述参与者的一种或多种情绪和认知特质。所述招聘游戏可以包括与多个选定的基于神经科学的计算机化任务相关联的多个预定义组的图形视觉对象。所述多个预定义组的视觉对象可以在所述计算设备的图形显示器上显示给所述参与者。
所述方法还可以包括在所述参与者通过使用一个或多个输入设备操纵所述图形显示器上的所述图形视觉对象中的一个或多个以完成所述多个选定的基于神经科学的计算机化任务来玩所述计算设备的所述图形显示器上的所述招聘游戏时从所述计算设备接收输入数据。
所述方法还可以包括分析来源于所述参与者对所述招聘游戏内的所述一个或多个图形视觉对象的操纵的所述输入数据,以(1)基于所述参与者对所述(一个或多个)图形视觉对象的操纵程度,提取对所述参与者的情绪和认知特质的测量,(2)基于对所述参与者的情绪和认知特质的所述测量生成统计模型,其中所述统计模型代表选定组的参与者,和(3)通过将对所述参与者的情绪和认知特质的所述测量与所述统计模型进行比较来分类每个参与者是在组内还是组外。
另外,所述方法可以包括存储所述分析的输入数据以供实体使用。所述分析的输入数据可以包括被配置成可视化地显示在至少一个计算设备的图形显示器上的一组图形视觉对象。所述组的图形视觉对象可以包括:(i)第一密度函数图,其对应于被分类为组外的参与者,(ii)第二密度函数图,其对应于被分类为组内的参与者,以及(iii)决策边界,其定义在所述第一密度函数图与所述第二密度函数图之间的重叠区域中。所述决策边界可以由所述实体使用,以基于候选人在所述招聘游戏中所测量的表现来确定所述候选人被招聘到目标职位的适合性。
在一些实施方式中,提供了一种包括具有编码于其中的计算机可执行代码的计算机可读介质的计算机程序产品。所述计算机可执行代码可适于被执行用于实现包括以下各项的方法:a)提供招聘系统,其中所述招聘系统包括:i)任务模块;ii)测量模块;iii)评估模块;以及iv)辨识模块;b)由所述任务模块向主体提供计算机化任务;c)由所述测量模块测量所述主体在所述任务的执行中所展示出的表现值;d)由所述评估模块基于所测量的表现值来评估所述主体的特质;以及e)由所述辨识模块基于所评估的特质来为雇用官辨识所述主体适合于被实体雇用。
在一些实施方式中,提供了一种包括具有编码于其中的计算机可执行代码的计算机可读介质的计算机程序产品。所述计算机可执行代码可适于被执行用于实现包括以下各项的方法:a)提供人才辨识系统,其中所述人才辨识系统包括:i)任务模块;ii)测量模块;iii)评估模块;iv)辨识模块;以及v)输出模块;b)由所述任务模块向主体提供计算机化任务;c)由所述测量模块测量所述主体在任务的执行中所展示出的表现值;d)由所述评估模块基于所测量的表现值来评估所述主体的特质;e)由所述辨识模块基于对主体的所述特质的评估来辨识职业倾向;以及f)由所述输出模块向雇用官输出所辨识的职业倾向。
在一些实施方式中,计算机实现的方法可包括:a)向主体提供计算机化任务;b)测量所述主体在所述任务的执行中所展示出的表现值;c)基于所述表现值来评估所述主体的特质;d)由计算机系统的处理器对所述主体的所述特质与测试主体的数据库进行比较;e)基于所述比较来确定所述主体适合于被实体雇用;以及f)向所述实体处的雇用官报告所述主体适合于雇用。
在一些实施方式中,计算机实现的方法可包括:a)向主体提供计算机化任务;b)测量所述主体在所述任务的执行中所展示出的表现值;c)基于所述表现值来评估所述主体的特质;d)由计算机系统的处理器基于所评估的所述主体的特质与测试主体的数据库的比较来辨识所述主体的职业倾向;以及e)向雇用官输出所述比较的结果。
在本发明的一个方面,提供了一种计算机实现的基于神经科学的人员招聘方法。所述方法可以包括:向与多个参与者相关联的多个计算设备提供交互式媒体,其中所述交互式媒体包括用一组选定的基于神经科学的任务创建的至少一个招聘游戏,所述组选定的基于神经科学的任务被设计用于测量所述参与者的多种情绪和认知特质,其中所述招聘游戏包括与所述组选定的基于神经科学的任务相关联的预定义组的视觉对象,并且其中所述预定义组的视觉对象呈现在所述计算设备的图形显示器上;当所述参与者通过与所述预定义组的视觉对象交互以完成所述组的选定的基于神经科学的任务来在所述计算设备的所述图形显示器上玩所述招聘游戏时,从所述计算设备接收输入数据;分析来源于所述参与者与所述招聘游戏内的所述预定义组的视觉对象的交互的所述输入数据,以(1)提取对所述参与者的情绪和认知特质的测量,(2)基于对所述参与者的情绪和认知特质的所述测量生成统计模型,其中所述统计模型代表选定组的参与者,和(3)通过将对所述参与者的情绪和认知特质的所述测量与所述统计模型进行比较来分类每个参与者是在组内还是组外;以及在所述图形显示器上将所述分析的输入数据可视化地显示为多个密度函数图,其中所述多个密度函数图包括对应于被分类为组外的所述参与者的第一密度函数图和对应于被分类为组内的所述参与者第二密度函数图,并且其中决策边界被定义在所述第一密度函数图与所述第二密度函数图之间的重叠区域中。
在一些实施方式中,所述多个参与者还可以包括至少一个候选人,并且所述方法还可以包括:将对所述候选人的情绪和认知特质的测量与所述统计模型进行比较,并基于所述比较为所述候选人生成分数;在所述图形显示器上的所述多个密度函数图上显示指示所述分数的点;以及将所述候选人分类为:(1)当所述点位于相对于所述决策边界的第一区域时的组内,或(2)当所述点位于相对于所述决策边界的第二区域时的组外。
本发明的另一方面可以提供一种用于实现基于神经科学的人员招聘方法的系统。所述系统可以包括:与关联多个参与者的多个计算设备通信的服务器,其中所述服务器包括用于存储第一组软件指令的存储器,以及被配置用于执行所述第一组软件指令的一个或多个处理器,以:向与多个参与者相关联的多个计算设备提供交互式媒体,其中所述交互式媒体包括用一组选定的基于神经科学的任务创建的至少一个招聘游戏,所述组选定的基于神经科学的任务被设计用于测量所述参与者的多种情绪和认知特质,其中所述招聘游戏包括与所述组选定的基于神经科学的任务相关联的预定义组的视觉对象,并且其中所述预定义组的视觉对象呈现在所述计算设备的图形显示器上;当所述参与者通过与所述预定义组的视觉对象交互以完成所述组的选定的基于神经科学的任务来在所述计算设备的所述图形显示器上玩所述招聘游戏时,从所述计算设备接收输入数据;分析来源于所述参与者与所述招聘游戏内的所述预定义组的视觉对象的交互的所述输入数据,以(1)提取对所述参与者的情绪和认知特质的测量,(2)基于对所述参与者的情绪和认知特质的所述测量生成统计模型,其中所述统计模型代表选定组的参与者,和(3)通过将对所述参与者的情绪和认知特质的所述测量与所述统计模型进行比较来分类每个参与者是在组内还是组外。所述多个计算设备可以包括用于存储第二组软件指令的存储器,以及被配置用于执行所述第二组软件指令的一个或多个处理器,以:从所述服务器接收所述分析的输入数据;并且在所述图形显示器上将所述分析的输入数据可视化地显示为多个密度函数图,其中所述多个密度函数图包括对应于被分类为组外的所述参与者的第一密度函数图和对应于被分类为组内的所述参与者第二密度函数图,并且其中决策边界被定义在所述第一密度函数图与所述第二密度函数图之间的重叠区域中。
根据本发明的另一方面,提供了一种存储指令的有形计算机可读介质,所述指令在由一个或多个服务器执行时使所述一个或多个服务器执行计算机实现的基于神经科学的人员招聘方法。所述方法可以包括:向与多个参与者相关联的多个计算设备提供交互式媒体,其中所述交互式媒体包括用一组选定的基于神经科学的任务创建的至少一个招聘游戏,所述组选定的基于神经科学的任务被设计用于测量所述参与者的多种情绪和认知特质,其中所述招聘游戏包括与所述组选定的基于神经科学的任务相关联的预定义组的视觉对象,并且其中所述预定义组的视觉对象呈现在所述计算设备的图形显示器上;当所述参与者通过与所述预定义组的视觉对象交互以完成所述组的选定的基于神经科学的任务来在所述计算设备的所述图形显示器上玩所述招聘游戏时,从所述计算设备接收输入数据;分析来源于所述参与者与所述招聘游戏内的所述预定义组的视觉对象的交互的所述输入数据,以(1)提取对所述参与者的情绪和认知特质的测量,(2)基于对所述参与者的情绪和认知特质的所述测量生成统计模型,其中所述统计模型代表选定组的参与者,和(3)通过将对所述参与者的情绪和认知特质的所述测量与所述统计模型进行比较来分类每个参与者是在组内还是组外;以及在所述图形显示器上将所述分析的输入数据可视化地显示为多个密度函数图,其中所述多个密度函数图包括对应于被分类为组外的所述参与者的第一密度函数图和对应于被分类为组内的所述参与者的第二密度函数图,并且其中决策边界被定义在所述第一密度函数图与所述第二密度函数图之间的重叠区域中。
应当理解,本发明的不同方面可以单独地、共同地或彼此组合地理解。本文描述的本发明的各个方面可以应用于以下阐述的任何特定应用。
通过回顾说明书、权利要求和附图,本发明的其他目的和特征将会变得显而易见。
援引并入
本说明书中提到的所有出版物、专利和专利申请均通过引用并入本文,其程度如同特别地且单独地指出每一个单独的出版物、专利或专利申请均通过引用而并入。
附图说明
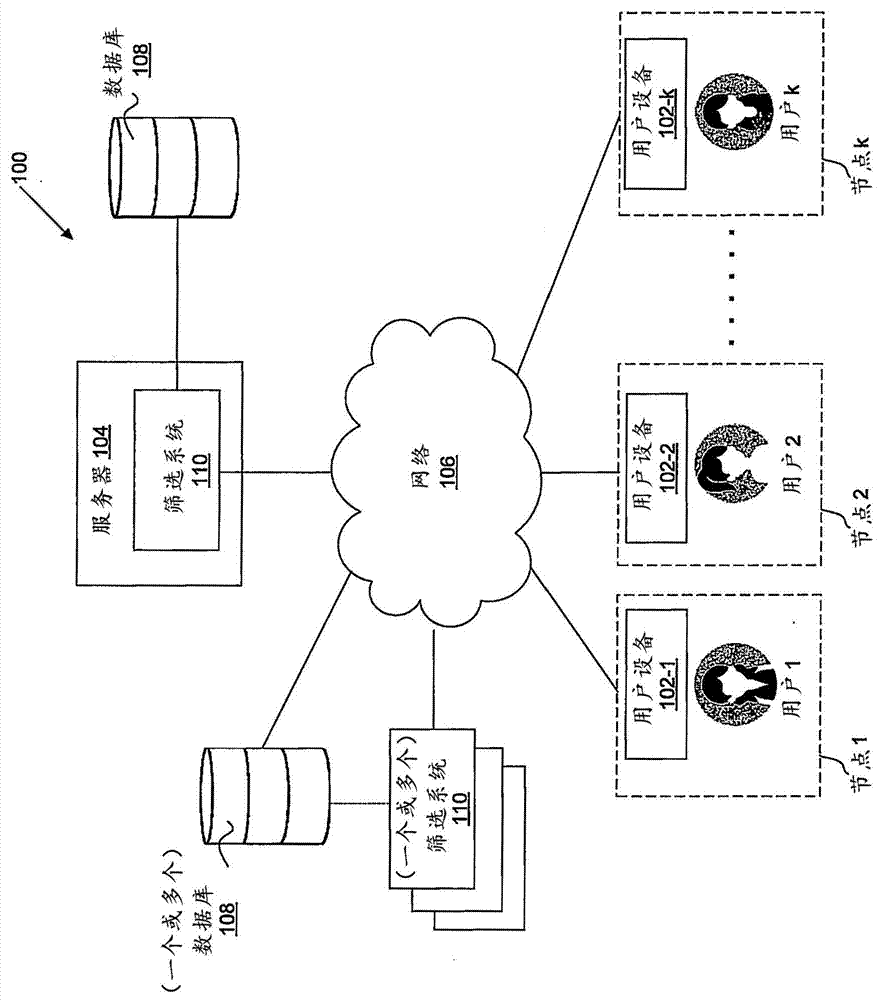
图1图示了根据一些实施方式的包括一个或多个筛选系统的示例性网络布局;
图2图示了根据一些实施方式的筛选系统中的示例性组件和筛选系统的输入/输出的示意性框图;
图3图示了根据一些实施方式的示例性注册窗口和登录窗口;
图4图示了根据一些实施方式的示例性寻找模型窗口;
图5图示了根据一些实施方式的示例性候选人窗口;
图6图示了根据一些实施方式的图5的候选人窗口内的示例性过滤窗口;
图7和图8图示了根据一些实施方式的示例性候选人简档窗口;
图9图示了根据一些实施方式的示例性通信窗口;
图10图示了根据一些实施方式的示例性员工面板窗口;
图11图示了根据一些实施方式的示例性员工参与窗口;
图12和图13图示了根据一些实施方式的当用户在图11的窗口内导航时的员工参与信息的显示;
图14和图15图示了根据一些实施方式的示例性模型特质窗口;
图16图示了根据一些实施方式的当用户在图14的窗口内导航时的特质统计的显示;
图17A图示了根据一些实施方式的示例性模型准确度窗口;
图17B图示了根据一些实施方式将候选人的特质与图17A的员工模型进行比较的结果;
图18图示了根据一些实施方式的当用户在图17A的窗口内导航时的组特点的显示;
图19图示了根据一些实施方式的图17A的窗口中的示例性分类和交叉验证表;
图20图示了根据一些实施方式的示例性模型偏差窗口;
图21图示了根据一些实施方式的图20的窗口中的不同偏差因素的评分表;
图22图示了根据一些实施方式的当用户在图21的窗口内导航时的偏差适配分数的显示;
图23图示了根据一些实施方式的示例性筛选模型窗口;
图24图示了根据一些实施方式的示例性内部流动性模型窗口;
图25图示了根据一些实施方式的邮箱文件夹中的示例性消息窗口;
图26图示了根据一些实施方式的账户文件夹中的示例性组设置窗口;
图27和图28图示了根据一些实施方式的账户文件夹中的示例性隐私设置窗口;
图29和图30图示了根据一些实施方式的常见问题(FAQ)文件夹中的示例性FAQ窗口;
图31图示了根据一些实施方式的图29和图30的FAQ窗口中的示例性查询窗口;
图32描绘了根据一些实施方式的建模系统的概况;
图33是根据一些实施方式的本发明的示例中的员工参与的图形化表示;
图34示出了根据一些实施方式的由本发明的系统生成的模型的准确度;
图35是图示可与本发明的示例实施方式结合使用的计算机系统的第一示例架构的框图;
图36是图示可与本发明的示例实施方式结合使用的计算机网络的示图;
图37是图示可与本发明的示例实施方式结合使用的计算机系统的第二示例架构的框图;
图38图示了可以传输本发明的产品的全球网络;
图39图示了根据一些实施方式的用于生成员工统计模型的示例性方法的流程图;以及
图40图示了根据一些实施方式的用于将候选人与图39的员工统计模型进行比较的示例性方法的流程图。
具体实施方式
公司常常依赖于低效的招聘实践,这可能导致雇用不佳的申请人,并最终降低员工留用率。进一步地,由于招聘过程可能很昂贵,因此雇主可能不情愿雇佣新的人才。这种不情愿可能导致公司停滞不前并且导致最佳员工离开以追求更好的机会。因此,公司面临着成本有效同时雇用准确的艰巨任务。相反,新毕业生或求职者面临着找到最适合于其才能和意向的职业的挑战,这不仅是因为就业市场不可预测,而且还因为最初确定要追求什么职业道路很困难。
在一些情况下,员工可能期望在公司内转换到不同的工作角色,但由于内部调动指导更多地关注专长或经验,而不是员工擅长该角色的天资或潜力,因此可能缺乏这种转换的机会。在公司内丧失机会可能会导致最佳员工离开,以追求其他地方的更好机会。
因此,对于可以由公司使用的系统和方法存在需求,以便(1)辨识适应公司的具体职位需求的人才,以及(2)辨识最佳员工并推荐将这些员工安置在尽可能发挥他们潜力的职位上。
本文公开的系统和方法可以解决至少以上需求。在一些实施方式中,所述系统和方法可以基于从一个或多个基于神经科学的任务(或测试)获得的候选人的行为输出将候选人与公司相匹配。可以将候选人的行为输出与代表公司中具体职位的理想员工的员工模型进行比较。能够以基于表现的游戏的形式提供多个基于神经科学的任务,该基于表现的游戏被设计用于测试/测量一系列广泛的情绪和认知特质。使用基于神经科学的游戏以及针对员工模型对这些游戏结果的分析可以帮助公司优化其招聘和候选人寻找过程。除了作为公司有用的招聘工具之外,本文公开的系统和方法还可以辅助个体进行职业规划和才能辨识。通过使用测量一系列广泛的情绪和认知特质的测试,所述系统和方法可以探明测试主体的优势和不足,并应用该信息来推荐哪些(一个或多个)领域适合于测试主体。
如上所述,基于神经科学的游戏可用于收集关于一个人的认知和情绪特质的信息。在一些实施方式中,本文公开的系统和方法可以通过评估一组员工在基于神经科学的游戏上的表现来为公司创建员工模型。该组员工可以包括公司的现有员工。可选地,该组员工还可以包括公司的前员工。该组员工可以包括公司的一些或全部员工。在一些实施方式中,该组员工可以包括公司中的选定组的员工(例如,具体地理位置或办公室中的那些员工)。员工模型可以代表公司中具体职位的理想员工,并且可以根据基于神经科学的游戏结果和员工的工作表现数据来生成。可能会要求候选人完成相同的基于神经科学的游戏。所述系统和方法可以用于分析候选人对员工模型的结果,以确定候选人对具体职位的适合性。所述系统和方法还可以跨多个职位比较候选人,以基于员工模型确定哪些(一个或多个)职位(如果有的话)适合于候选人。
本发明的方法和系统
范围广泛的严密方法可以由本发明的系统使用以发现用于预测关于公司感兴趣的主体的因素的贴切信息。系统的评估可以包括使用系统的评估模块来收集客观数据,并继而对学习行为动态进行建模。对学习行为动态进行建模的优势是,系统不用利用例如平均分数等静态分数来检查行为,而是相反可以随时间推移来检查行为。该方法可以允许系统探明学习度量,例如,测试者如何从错误中学习或者奖励如何影响测试者的学习。这些学习度量在人力资本分析中经常被忽略,但在确定重要的员工特点方面可能是有价值的。
系统可以使用由系统内的个体评估所生成的分数来创建主体的适配分数。适配分数可以是个体任务的分数的聚合。适配分数的范围可以从0-100%变化并且预测主体将适合于具体职位或职业行业的似然度。在执行预测分析之前,系统可以量化现有数据中的关系,并且量化可以辨识该数据的主要特征并且提供该数据的汇总。例如,在系统能够预测特定候选人在具体公司是否能够成为一名成功的管理咨询员之前,该系统可以构建当前员工的特质与其作为成功的管理咨询员之间关系的描述性模型。系统的分析引擎可以实施用于非监督分类的各种数据挖掘和聚类算法以生成这些描述性模型。为了创建描述性模型,系统可以获取来自当前员工的评估数据并且使该数据与由公司提供给系统的员工评级相关联。这些评级可以是客观的度量,诸如在绩效考核中所使用的并且公司特别感兴趣的那些度量。
本文公开的系统和方法可以被配置用于通过收集和分析这些公司中代表性员工样本的基于神经科学的游戏表现数据来确定最佳/成功员工或专业人员在各个领域内和类似领域中的公司内的情绪和认知特质。例如,通过分析基于神经科学的游戏表现数据,本文的系统和方法可以确定最佳/成功员工或专业人员在以下场景中的情绪和认知特质:(1)在公司内,(2)在同一领域中的不同公司之间,(3)在领域或行业内,(4)在不同领域之间,和/或(5)在不同领域的不同公司之间。可以针对以上(1)至(5)场景中的每一个中的相似性和/或差异来分析这些最佳/成功员工的情绪和认知特质。在一些情况下,最佳/成功员工的特质的第一子集可以在不同领域之间保持一致,这可能导致候选人在不同领域的职业中取得成功。在其他情况下,最佳/成功员工的特质的第二子集可以在同一领域内的不同公司之间保持一致,这可能导致候选人在该领域的不同公司中取得成功。在一些其他情况下,最佳/成功员工的特质的第三子集可以在公司内保持一致,这可能导致候选人在该特定公司中取得成功。上述特质的第一、第二和第三子集可以包括至少一些重叠特质和/或一些不同特质。因此,本文公开的系统和方法可以生成最佳员工在不同组织水平上的模型,例如(1)在公司内,(2)在同一领域中的不同公司之间,(3)在领域或行业内,(4)在不同领域之间,和/或(5)在不同领域的不同公司之间。可以将一个或多个候选人与一个或多个模型中的最佳员工的特质进行比较,以确定该候选人在具体工作职位中成功的似然度。
图1图示了根据一些实施方式的包括一个或多个筛选系统的示例性网络布局。在一个方面,网络布局100可以包括多个用户设备102、服务器104、网络106、一个或多个数据库108以及一个或多个筛选系统110。组件102、104、108和110中的每一个都可以经由网络106或允许从一个组件到另一个组件传输数据的任何类型的通信链路可操作地彼此连接。
用户设备可以是例如被配置用于执行与所公开的实施方式一致的一个或多个操作的一个或多个计算设备。例如,用户设备可以是能够执行由筛选系统提供的软件或应用的计算设备。在一些实施方式中,软件可以提供基于神经科学的游戏,该游戏被设计用于收集关于一个人的认知和情绪特质的信息。公司可以使用该信息来优化其招聘和候选人寻找过程。游戏可以由服务器托管在一个或多个交互式网页上,并由一个或多个用户玩耍。一个或多个用户可以包括公司的员工、工作候选人、求职者等。在一些实施方式中,软件或应用可以包括客户端基于网络的门户,其被配置用于接收和分析从基于神经科学的游戏收集的信息,并向一个或多个终端用户报告结果。终端用户可以包括招聘人员、公司的人力资源人员、管理者、监督者等。
此外,用户设备可以包括台式计算机、膝上型计算机或笔记本计算机、移动设备(例如,智能电话、移动电话、个人数字助理(PDA)和平板计算机)或可穿戴设备(例如,智能手表)。用户设备还可以包括任何其他媒体内容播放器,例如,机顶盒、电视机、视频游戏系统或者能够提供或呈现数据的任何电子设备。用户设备可以包括已知的计算组件,诸如一个或多个处理器以及存储由(一个或多个)处理器执行的软件指令和数据的一个或多个存储器设备。
在一些实施方式中,网络布局可以包括多个用户设备。每个用户设备可以与用户相关联。用户可以包括公司的员工、工作职位的候选人、求职者、招聘人员、人力资源人员、学生、教师、讲师、教授、公司管理员、游戏开发者或者使用由筛选系统提供的软件或应用的任何个体或个体组。在一些实施方式中,多于一名用户可以与用户设备相关联。或者,多于一名用户设备可以与用户相关联。用户可以在地理上位于相同的位置,例如在同一办公室工作的员工,或者在特定地理位置的工作候选人。在一些情况下,一些或所有用户和用户设备可以位于遥远的地理位置(例如,不同的城市、国家等),但这不是对本发明的限制。
网络布局可以包括多个节点。网络布局中的每个用户设备可以对应于节点。如果“用户设备102”后面跟着数字或字母,则意味着“用户设备102”可以对应于共享相同数字或字母的节点。例如,如图1中所示,用户设备102-1可以对应于与用户1相关联的节点1,用户设备102-2可以对应于与用户2相关联的节点2,并且用户设备102-k可以对应于与用户k相关联的节点k,其中k可以是大于1的任何整数。
节点可以是在网络布局中逻辑上独立的实体。因此,网络布局中的多个节点可以代表不同的实体。例如,每个节点可以与用户、一组用户或多组用户相关联。例如,在一个实施方式中,节点可以对应于单个实体(例如,个体)。在一些特定的实施方式中,节点可以对应于多个实体(例如,具有针对招聘或人才安置的不同角色/职责的一组个体)。这些特定实施方式的示例可以是共享公用节点的招聘人员和人力资源人员。
用户可以是注册的,或与提供与由所公开的实施方式执行的一个或多个操作相关联的服务的实体相关联。例如,用户可以是实体(例如,公司、组织、个体等)的注册用户,该实体提供用于与某些公开的实施方式一致的数据驱动人才辨识的服务器104、数据库108和/或筛选系统110中的一种或多种。所公开的实施方式不限于用户与实体、(一个或多个)人员或者提供服务器104、数据库108和筛选系统110的实体之间的任何具体关系或从属关系。
用户设备可以被配置用于从一个或多个用户接收输入。用户可以使用输入设备向用户设备提供输入,该输入设备例如键盘、鼠标、触摸屏面板、语音辨识和/或听写软件或者上述的任何组合。输入可以包括在神经科学游戏环境中执行各种虚拟行动(例如,由员工或工作候选人执行)。输入还可以包括终端用户对筛选系统的指令,以针对存储在一个或多个数据库中的员工模型分析员工或工作候选人的表现。不同的用户可以根据他们的角色和职责提供不同的输入(例如,员工、工作候选人、招聘人员和人力资源人员可以提供不同的输入)。
在图1的实施方式中,可以在服务器与每个用户设备之间提供双向数据传输能力。用户设备还可以经由服务器彼此通信(即,使用客户端-服务器架构)。在一些实施方式中,用户设备可以经由点对点通信渠道彼此直接通信。点对点通信渠道可以通过利用用户设备的资源(例如,带宽、存储空间和/或处理能力)来帮助减少在服务器上的工作量。
服务器可以包括被配置用于执行与所公开的实施方式一致的一个或多个操作的一个或多个服务器计算机。在一方面,服务器可以实现为单个计算机,用户设备能够通过该计算机与网络布局的其他组件通信。在一些实施方式中,用户设备可以通过网络与服务器通信。在其他实施方式中,服务器可以代表用户设备通过网络与(一个或多个)筛选系统或数据库通信。在一些实施方式中,服务器可以体现一个或多个筛选系统的功能。在一些实施方式中,(一个或多个)筛选系统可以实现在服务器内部和/或外部。例如,(一个或多个)筛选系统可以是包括在服务器内或远离服务器的软件和/或硬件组件。
在一些实施方式中,用户设备可以通过单独的链路直接连接到服务器(图1中未示出)。在某些实施方式中,服务器可以被配置用于作为前端设备操作,该前端设备被配置用于提供对与某些公开的实施方式一致的一个或多个筛选系统的访问。在一些实施方式中,服务器可以利用(一个或多个)筛选系统处理来自用户设备的输入数据,以便确定基于神经科学的用户游戏玩法表现,并分析用户的游戏玩法表现以确定用户与员工模型之间的匹配。服务器可以被配置用于将员工和候选人的游戏玩法表现数据存储在数据库中。服务器还可以被配置用于搜索、取回和分析存储在数据库中的数据和信息。数据和信息可以包括用户在一个或多个基于神经科学的游戏中的历史表现,以及用户在一个或多个基于神经科学的游戏中的当前表现。
服务器可以包括网络服务器、企业服务器或任何其他类型的计算机服务器,并且可以被计算机编程用于接受来自计算设备(例如,用户设备)的请求(例如,HTTP或可以发起数据传输的其他协议)并用请求的数据服务于计算设备。另外,服务器可以是广播设施,诸如免费设施、电缆设施、卫星设施和其他广播设施来分发数据。服务器也可以是数据网络(例如,云计算网络)中的服务器。
服务器可以包括已知的计算组件,诸如一个或多个处理器、存储由(一个或多个)处理器执行的软件指令和数据的一个或多个存储器设备。服务器可以具有一个或多个处理器和至少一个用于存储程序指令的存储器。(一个或多个)处理器可以是能够执行特定指令集的单个或多个微处理器、现场可编程门阵列(FPGA)或数字信号处理器(DSP)。计算机可读指令可以存储在有形的非暂时性计算机可读介质上,诸如软盘、硬盘、CD-ROM(光盘只读存储器)和MO(磁光盘)、DVD-ROM(数字多用盘-只读存储器)、DVD RAM(数字多用盘-随机存取存储器)或半导体存储器。或者,本文公开的方法可以在硬件组件或硬件和软件的组合中实现,诸如例如ASIC、专用计算机或通用计算机。虽然图1将服务器图示为单个服务器,但是在一些实施方式中,多个设备可以实现与服务器相关联的功能。
网络可以被配置用于提供图1中描绘的网络布局的各种组件之间的通信。在一些实施方式中,网络可以被实现为连接网络布局中的设备和/或组件以允许它们之间的通信的一个或多个网络。例如,如本领域普通技术人员将认识到的,网络可以实现为因特网、无线网、有线网、局域网(LAN)、广域网(WAN)、蓝牙、近场通信(NFC)或在网络布局的一个或多个组件之间提供通信的任何其他类型的网络。在一些实施方式中,可以使用手机和/或寻呼机网络、卫星、许可无线电或许可和未许可无线电的组合来实现网络。网络可以是无线的、有线的或其组合。
(一个或多个)筛选系统可以被实现为存储指令的一个或多个计算机,所述指令在由一个或多个处理器执行时处理基于神经科学的游戏玩法表现数据以便确定用户的情绪和认知特质,并将用户特质与一个或多个模型(例如,代表公司中具体工作职位的理想员工的员工模型)进行比较以确定用户与一个或多个模型的匹配/兼容性。(一个或多个)筛选系统还可以搜索、取回和分析存储在数据库中的基于神经科学的游戏玩法表现数据和员工/候选人的工作表现数据。基于神经科学的游戏玩法表现数据可以包括,例如:(1)用户玩游戏花费的时间量,(2)用户完成游戏所采取的尝试数,以及(3)用户在游戏期间执行的不同行动,(4)用户执行每个行动占据的时间量,(5)用户执行某些行动的准确度,以及(6)用户在游戏期间做出某些决定/判断时应用的权重。在一些实施方式中,服务器可以是在其中实现(一个或多个)筛选系统的计算机。
然而,在一些实施方式中,(一个或多个)筛选系统中的至少一些可以在单独的计算机上实现。例如,用户设备可以向服务器发送用户输入,并且服务器可以通过网络连接到(一个或多个)其他筛选系统。在一些实施方式中,(一个或多个)筛选系统可以包括软件,该软件当由(一个或多个)处理器执行时执行用于数据驱动的人才辨识的过程。
服务器可以访问和执行(一个或多个)筛选系统以执行与所公开的实施方式一致的一个或多个过程。在某些配置中,(一个或多个)筛选系统可以是存储在服务器可访问的存储器中(例如,在服务器本地的存储器或经由诸如网络等通信链路可访问的远程存储器中)的软件。因此,在某些方面,(一个或多个)筛选系统可以实现为一个或多个计算机、实现为存储在服务器可访问的存储器设备上的软件,或其组合。例如,一个筛选系统可以是执行一个或多个数据驱动的人才辨识技术的计算机硬件,而另一个筛选系统可以是当由服务器执行时执行一个或多个数据驱动的人才辨识技术的软件。
(一个或多个)筛选系统可以用于以各种不同方式将候选人与公司匹配。例如,(一个或多个)筛选系统可以存储和/或执行软件,该软件执行用于处理基于神经科学的员工游戏玩法数据的算法,以生成代表针对公司中具体工作职位的理想员工的员工模型。(一个或多个)筛选系统还可以存储和/或执行软件,该软件执行用于基于基于神经科学的员工游戏玩法数据和/或工作表现评级的变化来动态修改员工模型的算法。(一个或多个)筛选系统可以进一步存储和/或执行软件,该软件执行用于将基于神经科学的候选人游戏玩法数据与员工模型进行比较的算法,以确定候选人的行为与员工模型中的员工行为的匹配程度,以及候选人在具体工作职位上取得成功的似然度。
所公开的实施方式可以被配置用于实现(一个或多个)筛选系统,使得可以执行各种算法以执行一个或多个数据驱动的人才辨识技术。尽管已经描述了用于执行上述算法的多个筛选系统,但是应该注意,可以使用与所公开的实施方式一致的单个筛选系统来执行一些或全部算法。
用户设备、服务器和(一个或多个)筛选系统可以连接或互连到一个或多个数据库。(一个或多个)数据库可以是被配置用于存储数据(例如,基于神经科学的游戏玩法数据和员工模型)的一个或多个存储器设备。另外,在一些实施方式中,(一个或多个)数据库还可以实现为具有存储设备的计算机系统。在一个方面,(一个或多个)数据库可以由网络布局的组件使用以执行与所公开的实施方式一致的一个或多个操作。在某些实施方式中,一个或多个数据库可以与服务器共同定位,或者可以在网络上彼此共同定位。普通技术人员将认识到,所公开的实施方式不限于(一个或多个)数据库的配置和/或布置。
在一些实施方式中,任何用户设备、服务器、(一个或多个)数据库和/或(一个或多个)筛选系统都可以实现为计算机系统。另外,虽然网络在图1中示为用于网络布局的组件之间通信的“中心”点,但是所公开的实施方式不限于此。例如,如本领域普通技术人员将理解的,网络布局的一个或多个组件能够以各种方式互连,并且在一些实施方式中可以彼此直接连接、彼此共同定位或彼此远离。另外,虽然一些公开的实施方式可以在服务器上实现,但是所公开的实施方式不限于此。例如,在一些实施方式中,其他设备(诸如一个或多个用户设备)可以被配置用于执行与所公开的实施方式一致的过程和功能中的一个或多个,所述实施方式包括关于服务器和筛选系统描述的实施方式。
尽管图示了特定的计算设备并描述了网络,但是应当理解和了解,在不脱离本文所述的实施方式的精神和范围的情况下,可以利用其他计算设备和网络。另外,如本领域普通技术人员将理解的,网络布局的一个或多个组件能够以各种方式互连,并且在一些实施方式中可以彼此直接连接、彼此共同定位或彼此远离。
图2图示了根据一些实施方式的筛选系统中的示例性组件和筛选系统的输入/输出的示意性框图。如前所述,筛选系统可以实现在服务器内部和/或外部。例如,筛选系统可以是包括在服务器内或远离服务器的软件和/或硬件组件。
参考图2,筛选系统110可以包括特质提取引擎112、模型分析引擎114和报告引擎116。筛选系统可以被配置用于从多个用户接收输入。用户可以包括一个或多个终端用户、员工或工作候选人。终端用户可以是公司的招聘人员或公司的人力资源人员。该组员工可以包括公司的现有员工。可选地,该组员工可以包括公司的前员工。该组员工可以包括公司的一些或全部员工。在一些实施方式中,该组员工可以包括公司中选定组的员工。可以基于地理位置、工作职能、工作表现或任何其他因素来选择一组员工。工作候选人可以包括申请公司中的具体职位的用户、活跃的求职者、简历/简档在数据库中并且可能与公司潜在匹配的用户、新大学毕业生、学生等。
终端用户可以向筛选系统提交请求(例如,经由用户设备)以辨识可能适应公司对具体职位的需求的最佳候选人。终端用户可以使用筛选系统通过使用员工模型分析候选人的行为输出来将候选人与公司匹配。员工模型可以代表公司中具体职位的理想(或模范)员工。可以基于多个基于神经科学的游戏的结果和员工的工作表现数据来生成员工模型。游戏可以被设计用于通过使员工完成多个基于神经科学的任务来测试/测量员工的广泛情绪和认知特质。这些特质可能指示并可能转化为员工在公司/职场中以其角色的成功。工作表现数据可以包括公司提供的员工评级(例如,来自人力资源人员、管理者、监督者等)。评级可以是客观度量,诸如在绩效考核中使用的度量和公司特别感兴趣的度量。筛选系统可以被配置用于确定雇主提供的评级与员工在基于神经科学的游戏上的表现之间的相关性。
如图1中所示,特质提取引擎可以被配置用于接收多个员工(员工1、员工2到员工m,其中m可以是大于2的任何整数)的游戏玩法数据。在一些情况下,特质提取引擎可以直接从与员工相关联的用户设备接收游戏玩法表现数据。或者,特质提取引擎可以从数据库或服务器接收员工的游戏玩法数据。数据库或服务器(员工的游戏玩法数据存储在其上或从其传输)可以是在其上实现筛选系统的服务器本地或远程的。游戏可以由公司给予员工。或者,游戏可以由可能隶属于公司或不隶属于公司的第三方给予员工。在一些实施方式中,游戏可以由筛选系统使用一个或多个交互式网页或通过移动应用来提供。可选地,游戏不需要由筛选系统提供,并且可以托管在远离筛选系统的服务器上。特质提取引擎可以被配置用于从员工的游戏玩法数据中提取员工的多种情绪和认知特质。
基于神经科学的游戏中的任务的示例可以包括类比推理、仿真气球冒险任务、选择任务、独裁者任务、数字广度、EEfRT、面部影响任务、手指敲击、未来折现、Flanker任务、Go/No-Go、眼神读心、N-Back、图案识别、奖励学习任务、伦敦塔以及信任任务。稍后将在说明书中描述上述任务中的每一个的细节。
在提取了员工的情绪和认知特质之后,特质提取引擎可以将特质输入到模型分析引擎。模型分析引擎可以被配置用于确定特质与雇主提供的员工评级之间的相关性,并且基于相关特质生成员工模型。例如,模型分析引擎可以将数据挖掘和聚类算法应用于相关员工的游戏玩法数据和雇主提供的评级,以生成和微调员工模型。如前所述,员工模型包括针对公司具体职位的理想员工可能拥有的特点。因此,员工模型可以基于进行基于神经科学的测试(玩游戏)的所有员工中的最佳员工的目标群体。可以将员工模型与适当的基线组进行对比。可以从包括来自其他领域的员工的数据库中选择基线组,所述员工可以在人口统计因素(诸如性别、年龄、种族、教育背景)方面类似于进行基于神经科学的测试的目标员工组,但不与目标员工组在同一领域工作。通过将员工的游戏玩法数据与基线组进行对比,模型分析引擎可以确定将进行基于神经科学的测试的员工分类为组内还是组外。
在一些实施方式中,模型分析引擎可以通过使用机器学习算法分析员工的行为输出和工作表现评级,有方法地辨识某些特质并建立它们与员工的工作表现评级的关系。机器学习算法可以利用支持向量机(SVM),但不限于此。在一些实施方式中,可以使用随机森林和其他分析技术。机器学习算法可以基于统计推断。模型分析引擎可以被配置用于从员工的游戏玩法表现数据和工作表现评级中自动辨识某些特质及其相关性。在一些实施方式中,模型分析引擎可以被配置用于通过分析存储在一个或多个数据库中的现实世界基于神经科学的游戏玩法数据的大型库来学习有助于在公司或具体工作角色中获得成功的新特质。模型分析引擎可以包括能够做出基于将实值权重附加到每个特质的软概率决策的统计模型。在一些实施方式中,自然语言处理(NLP)可以用于解析候选人和/或员工的简历和人口统计数据。
在一些实施方式中,模型分析引擎可以从员工的游戏玩法数据和工作表现评级中辨识感兴趣的特点,而不需要知道这些特点之间的潜在概率分布,并确定观察到的变量之间的具体关系。机器学习的一个优点是基于对游戏玩法数据和工作表现评级的分析来自动识别复杂模式和做出智能决策。在一些实施方式中,模型分析引擎可以使用非线性非参数的分类技术,所述分类技术在小的训练数据集的情况下,与传统的模式分类算法相比,在具有许多属性的数据集中可以执行得更好。
在使用上述数据对模型分析引擎进行充分“训练”之后,终端用户(例如,公司的招聘人员或人力资源人员)可以使用员工模型来预测候选人在公司的具体工作职位中获得成功的似然度。现在可以向一个或多个候选人提供基于神经科学的游戏(其由员工预先玩耍以生成员工模型)。筛选系统可以被配置用于从候选人基于神经科学的游戏的表现获得候选人的行为输出。例如,特质提取引擎可以被配置用于基于每个候选人的游戏玩法数据提取关于每个候选人的情绪和认知特质。在一些实施方式中,可以为每个候选人生成简档。该简档可以包含对候选人唯一或特定的特质列表。
随后,特质提取引擎可以将候选人特质输入模型分析引擎。模型分析引擎可以被配置用于通过将候选人特质与员工模型进行比较来分析候选人特质,以便为每个候选人生成适配分数。适配分数可以用于确定每个候选人在公司的特定角色中获得成功的似然度。使用员工模型对候选人进行评分可以提供每个候选人与在具体工作职位中获得成功相关的情绪或认知的定量评估。通过将候选人的特质与公司中员工(例如,最佳员工)的特质进行比较,终端用户(例如,招聘人员或人力资源人员)可以确定候选人是否适合雇用来填补具体的工作职位。在一些实施方式中,可以跨多个职位比较候选人特质,以基于一个或多个员工模型确定什么(一个或多个)职位(如果有的话)适合于候选人。
候选人的适配分数可以是候选人基于神经科学的任务的分数的聚合。适配分数可以在0-100%的范围内,并且可以用于预测候选人将会适合于具体职位或职业行业的似然度。适配分数可以是,例如,约0%、约1%、约2%、约3%、约4%、约5%、约6%、约7%、约8%、约9%、约10%、约15%、约20%、约25%、约30%、约35%、约40%、约45%、约50%、约60%、约70%、约80%、约90%或约100%。
随后,报告引擎可以从模型分析引擎接收每个候选人的适配分数,并向终端用户提供适配分数和推荐。该推荐可以包括特定候选人是否适合于被雇用以填补具体工作职位,以及候选人在该职位中获得成功的似然度。
因此,通过使用上述筛选系统和方法,可以提取并分析关于候选人的贴切信息以预测/辨识公司感兴趣的因素。筛选系统可以用于收集来源于基于神经科学的游戏玩法数据和员工工作表现评级的客观数据,并创建能够辨识有助于在公司中的具体工作职位获得成功的不同特质的动态模型。模型的动态性质允许随着时间的推移检查员工/候选人的行为,而不是使用一次性静态分数来检查行为。筛选系统还可以确定与不同特质相关联的表现度量,例如,员工/候选人如何从玩游戏时产生的错误学习,以及奖励如何影响他们的学习和表现。这些学习的度量在人力资本分析中经常被忽略,但在确定与成功相关的员工特点方面可能是有价值的。
商业实体可以使用图2的筛选系统来辨识和招聘有才能的候选人。商业实体的非限制性示例可包括企业、合作社、合伙企业、公司、股份有限公司、私人公司、上市公司、有限责任公司、有限责任合伙企业、租赁企业、组织、非营利性组织、人事机构、学术机构,政府设施、政府机构、军事部门或慈善组织。筛选系统的终端用户例如还可以包括招聘人员、人力资源人员、管理者、监督者、雇用官、职业顾问、职业安置专业人员或职业介绍所。
可代表企业实体工作的主体的非限制性示例包括员工、全职员工、兼职员工、法定员工、临时员工、承包商、独立承包商、分包商、退休员工、咨询员以及顾问。
本发明的系统还可以由主体使用来确定该主体的职业倾向。可以使用本发明的主体例如包括学生、研究生、求职者以及寻求关于职业规划的辅助的个体。主体可以完成系统的任务,在这之后,系统可以基于所辨识的主体特质来创建该主体的简档。用户可以从计算机系统访问本发明的系统。用户可继而使用例如计算机、膝上型计算机、移动设备或平板计算机来完成系统的计算机化任务。
可以将主体的简档与测试主体的数据库进行比较以对该主体进行评分并且基于参考模型而生成针对该主体的模型。测试主体例如可以为商业实体工作。系统可以基于为商业实体工作的测试主体以及测试主体在该商业实体的具体职位而附加地生成针对该主体的适配分数。本发明的系统还可以基于主体的确定职业倾向而向该主体推荐各种行业。可由系统推荐的行业的非限制性示例包括咨询、教育、医疗保健、营销、零售、娱乐、消费品、创业、技术、对冲资金、投资管理、投资银行、私募股权、产品开发以及产品管理。
在一些实施方式中,模型分析引擎可以通过将主体的特质与多个模型进行比较来辨识主体的职业倾向。该主体可以是求职者、寻求转换到不同领域的人、新大学毕业生、研究生、学生或寻求关于职业规划的辅助的个体。模型可以与为不同商业实体工作的员工相关联。模型可以与不同领域(例如,银行业务、管理咨询、工程等)相关联。或者,模型可以与同一领域内的不同工作职能(例如,软件工程师、过程工程师、硬件工程师、销售或营销工程师等)相关联。终端用户(例如,招聘人员或职业顾问)可以使用特质比较的结果向主体推荐一个或多个合适的职业。
可以要求主体完成一个或多个基于神经科学的游戏,之后筛选系统可以基于所辨识的主体特质为主体创建简档。可以在用户设备上向主体提供游戏,并且主体可以在该用户设备上玩游戏。在完成游戏后,用户设备可以将主体的游戏玩法数据传输到筛选系统以供分析。筛选系统可以通过将主体的特质与多个模型进行比较来生成主体的适配分数。筛选系统可以使用适配分数来确定主体的职业倾向并向主体推荐合适的职业领域。筛选系统可以推荐的领域(或行业)的非限制性示例可以包括咨询、教育、医疗保健、营销、零售、娱乐、消费品、创业、技术、对冲资金、投资管理、投资银行、私募股权、产品开发或产品管理。
如上所述,筛选系统可以从候选人或主体的基于神经科学的游戏玩法数据提取情绪和认知特质,以确定候选人在具体工作职位中获得成功的似然度,以及主体在不同领域中的职业倾向。
情绪特质可能是确定候选人或主体是否适合公司并适合履行公司内的具体角色的重要因素。筛选系统可以评估各种情绪特质,以帮助系统的终端用户做出雇用决策。可以由系统提取并测量的情绪特质可以包括信任、利他主义、毅力、风险简况、从反馈中学习、从错误中学习、创造力、模糊耐受性、延迟满足的能力、奖励敏感度、情绪敏感度或情绪辨识,并在下文描述。
信任可被评价为在不知晓其他人的行动的情况下依赖另一人的行动的意愿。信任可以表明主体是否能够在团体环境中有效地工作并且依赖其他人的意见和行动。
利他主义可被评估为无私,或者为其他人的福利而进行行动的意愿。利他主义可以表明,主体可能更愿意为公司的需求而不是自我的需求服务。
毅力可被描述为继续行动进程而不顾挫折。毅力可以表明,即使在失败或反对的时候,主体也可以找到到解决方案并且致力于所分派的任务。
创造力可以表明,主体可以具有用于解决问题和执行任务的非常规途径。
候选人的风险简况可以辨识主体承担风险的意愿。更愿意承担风险的主体可能更有利于处理高风险、高压情况的公司。
从反馈中学习可以测量主体是否能够在执行工作职能时使用来自他人的建议来修改行为或行动。从错误中学习可以评估主体是否能够使用任务中所犯的错误来修改执行同一任务的未来行为。
模糊耐受性可以评估在不确定或不完全的情境和刺激的情况下主体的舒适水平,以及主体对不确定或不完全的情境和刺激的反应。当面临不完全或有问题的数据时,具有模糊耐受性的主体可能更具创造性且更有智慧。
倾向于延迟满足的主体可能对公司有吸引力,这是因为该主体能够更努力地工作,并且能够工作达较长的时间段期望有加薪或奖金。
奖励敏感度与延迟满足的关系在于奖励敏感度可以测量主体受奖励承诺激励的程度。公司可能期望一个不仅会内在激励,而且还对诸如加薪和奖金等奖励敏感的主体。
情绪敏感度和情绪辨识可以描述主体是否能够以适当的方式回应另一人的情绪,以及主体是否能够正确地辨识另一人的情绪。具有较高情绪敏感度和情绪辨识能力的主体能够是更好的团队合作者和领导者。
除了上述情绪特质之外,还可以由商业实体评估和使用认知特质以确定主体是否适合于聘用。可以通过筛选系统提取或测量的认知特质可以包括,例如,处理速度、图案识别、持续性注意力、避免分心的能力、冲动性、认知控制、工作记忆、规划、记忆广度、排序、认知灵活性或学习,并在下文描述。
处理速度与在无需有意的思考的情况下彻底且快速地处理信息的能力有关。具有较高处理速度的主体对于公司而言可能是期望的在于该主体能够迅速思考并对情况作出反应。
图案识别可以是指识别以一定方式布置的一组刺激的能力,所述一定方式是该组刺激的特点。具有较高图案识别技巧的主体可以展示出更好的批判性思考技巧并且辨识出数据的趋势。
具有较高持续性注意力分数的主体可以展示出较高的将注意力维持于单一任务上的能力。还可以评估主体避免分心的能力以及集中于具体任务的能力。
冲动性可被评价为在没有远见、反思或考虑后果的情况下进行行动。冲动的主体可被潜在雇主看作是不适宜的,这是因为该主体可能作出可证明对公司不利的鲁莽决策。如果公司期望主体更愿意冒险、创造性地思考并且迅速地行动,则冲动型主体也可被看作是适宜的。
认知控制可以描述多种认知过程,包括工作记忆、学习、认知灵活性以及规划。工作记忆是记忆系统的活动部分并且可以涉及短期记忆和短期注意力二者。具有高工作记忆的主体可以显示出对任务更为集中的注意力以及针对多任务的能力。
认知灵活性可被描述为从不同任务切换以及同时地且有效地考虑多个任务的能力。具有认知灵活性的主体可以有效地平衡许多任务。
规划展示出组织行动以实现目标的能力,并且可以展示出任务执行中的远见。
记忆广度是短期记忆的测度并且可以通过使主体背诵先前呈现的一系列数字或字来评估。具有较大记忆广度的主体可以记住指令并且与具有短记忆广度的某人相比执行具体任务更好。
序列学习是对行动和思考进行排序而非自发意识到这样的排序正在发生的能力。序列学习可以包括四种排序问题。第一,序列预测可以试图基于先前的元素来预测序列元素。第二,序列生成可以试图在序列元素自然发生时将各元素一个接一个地拼接在一起。第三,序列识别可以试图基于预定准则来探明序列是否合法。最后,序列决策可以涉及选择行动序列来实现目标、遵循轨迹或者使成本函数最大化或最小化。
本发明的系统可以用于使个体或个体组与另一个体或另一个体组相匹配,以便在专业领域或个人领域内推荐兼容性。
使用基于神经科学的游戏以及这些游戏结果针对一个或多个员工模型的分析可以帮助公司优化其招聘和候选人寻找过程。除了作为公司有用的招聘工具之外,本文公开的系统和方法还可以辅助个体进行职业规划和才能辨识。通过使用测量一系列广泛的情绪和认知特质的测试,所述系统和方法可以探明主体的优势和不足,并应用该信息来推荐哪些(一个或多个)领域适合于该主体。
在一些实施方式中,筛选系统可以包括数据集线器,其充当筛选系统的中央通信集线器。数据集线器可以被配置用于控制和引导员工的游戏门户、候选人的游戏门户、主体的游戏门户、一个或多个数据库、特质提取引擎、模型分析引擎和报告引擎之间的通信。在一些情况下,数据集线器可以被配置用于向一个或多个用户(例如,员工、候选人等)提供一个或多个基于神经科学的游戏。应用编程接口(API)可用于将游戏与数据集线器和一个或多个用户设备连接。游戏可以是可在用户设备上执行的软件。在一些实施方式中,游戏可以是基于网络的,并且可以包括可以使用用户设备上的网络浏览器显示的多个交互式网页。在一些实施方式中,游戏可以是可在用户设备上(例如,在移动设备上)执行的移动应用。
游戏可以被设计用于测量员工和候选人的情绪或认知特质。可以由游戏开发者、心理学家、招聘人员、人力资源人员、管理者、监督者和/或专门设计这样的游戏的实体来设计游戏。可以在被配置成显示在用户设备上的虚拟环境中提供游戏。在一些实施方式中,虚拟环境可以包括可以由用户操纵的多个对象。用户可以通过虚拟环境中的各种不同行动来操纵对象。这些行动的示例可以包括选择一个或多个对象、拖放、平移、转动、旋转、推、拉、放大、缩小等。可以考虑对象在虚拟空间中的任何类型的移动行动。用户对对象的操纵可以指示某些情绪或认知特质。
在一些实施方式中,游戏门户可以被配置用于在用户玩游戏时从用户设备接收每个用户(例如,员工和/或候选人)的实时游戏玩法数据,并将游戏玩法数据传输到数据集线器。游戏玩法数据可以指示用户在各种基于神经科学的任务中的表现。用户在虚拟环境中执行的行动可以被编码在通过游戏门户提供给数据集线器的时间戳信号中。如前所述,那些行动可以包括操纵虚拟环境中的一个或多个对象以完成游戏所需的具体任务。数据集线器可以被配置用于通过游戏门户收集关于用户玩每个游戏花费的时间长度、用户完成每个游戏采取的尝试数、用户在游戏期间执行某些行动的准确度的游戏玩法数据。
特质提取引擎可以被配置用于处理和分析游戏玩法数据以确定至少以下内容。例如,特质提取引擎可以确定用户是否已经正确地选择、放置和/或使用游戏中的不同对象以完成所需的基于神经科学的任务。特质提取引擎还可以评估用户的学习技能、认知技能和从先前错误中学习的能力。
在一些实施方式中,筛选系统可以包括允许终端用户访问提供给筛选系统的游戏玩法数据的用户门户。不同的终端用户可以访问不同域中的不同数据集。例如,人力资源人员可能能够访问第一域中的一组员工的游戏结果/表现,并且招聘人员可能能够访问第二域中的一组候选人的游戏结果/表现。在一些情况下,可能不允许公司的人力资源人员访问其他公司的员工的游戏结果/表现。在一些情况下,招聘人员可能能够访问不同公司的员工的游戏结果/表现。可以针对不同的终端用户和实体考虑任何形式的权限或数据特权。
用户门户可以被配置用于在允许终端用户访问数据之前认证终端用户。在一些实施方式中,用户门户可以生成登录窗口,在终端用户可以访问数据之前提示终端用户填写认证凭证(例如,用户名和密码)。用户门户可以被配置用于接收终端用户的登录数据并将其与存储在终端用户数据库中的预先存在的用户数据进行比较。终端用户数据可以包括姓名、认证信息、用户权限/特权、用户类型等。可以根据用户类型来定义用户权限/特权。终端用户的示例可以包括招聘人员、人力资源人员、管理者、监督者、教师、讲师、管理员、游戏开发者等。在一些情况下,系统管理员和游戏开发者可以拥有允许他们修改数据和基于神经科学的游戏的某些权限/特权。
在一些实施方式中,在数据集线器接收游戏玩法数据之后,数据集线器可以将游戏玩法数据存储在游戏玩法数据库中。游戏玩法数据可以存储在传统的关系表中。游戏玩法数据还可以存储在对单个游戏唯一的数据的非关系名称-值对中。在一些实施方式中,数据集线器可以被配置用于去辨识游戏玩法数据并将去辨识的游戏玩法数据存储在游戏玩法数据库中。可以通过使用诸如员工1、员工2、候选人1、候选人2等描述符来遮掩玩游戏的员工和候选人的身份,从而对游戏玩法数据去辨识。因此,招聘人员或人力资源人员可以仅基于通过报告引擎提供的分析和推荐来审核游戏玩法数据,而没有影响他们审核的外在因素和/或外部偏见。在一些实施方式中,可以使用可以由某些利益相关者(例如,管理员、管理者、监督者等)生成的共享密钥来显露(解锁)去辨识的游戏玩法数据。
模型分析引擎可以被配置用于将候选人的特质与员工模型中的特质进行比较,并且将比较结果提供给报告引擎。报告引擎可以被配置用于基于比对员工模型对候选人特质的评估来生成每个候选人对具体工作职位的适合性的概况。报告引擎可以基于候选人在基于神经科学的游戏中的表现来生成辨识每个候选人的某些特质和适配分数的视觉指标。在一些实施方式中,报告引擎可以被配置用于生成包含视觉指示符的一个或多个窗口,该视觉指标允许招聘人员或人力资源人员一眼辨识候选人在具体工作职位中获得成功的似然度。招聘人员或人力资源人员可以继而基于指标联系最佳候选人。
在一些实施方式中,报告引擎可以使用所辨识的或去辨识的游戏玩法数据来提供候选人的表现比较。例如,可以将候选人的表现与一个或多个其他候选人的表现进行比较。招聘人员或人力资源人员可以使用这些比较来确定每个候选人的表现与其他候选人相比如何。
报告引擎可以被配置用于生成用于在用户设备上显示数据的多个图形用户界面(GUI)。这样的GUI的示例在图3至图31中示出。如前所述,用户设备可以是可以显示一个或多个网页的计算设备。此外,用户设备可以包括台式计算机、膝上型计算机或笔记本计算机、移动设备(例如,智能电话、移动电话、个人数字助理(PDA)和平板计算机)和可穿戴设备(例如,智能手表)。用户设备还可以包括任何其他媒体内容播放器,例如,机顶盒、电视机、视频游戏系统或者能够提供或呈现数据的任何电子设备。用户设备可以包括已知的计算组件,诸如一个或多个处理器以及存储由(一个或多个)处理器执行的软件指令和数据的一个或多个存储器设备。GUI是一种接口类型,其允许用户通过图形图标和视觉指标(诸如二次记数)与电子设备交互,与基于文本的界面、键入的命令标签或文本导航相反。GUI中的行动通常通过直接操纵图形元素来执行。除了计算机之外,GUI还可以存在于手持设备,诸如MP3播放器、便携式媒体播放器、游戏设备以及较小的家庭、办公和工业设备中。可以在软件、软件应用、网络浏览器等中提供GUI。可以通过应用编程接口(API)生成链路,API是用于构建软件应用的一组例程、协议和工具。
图3图示了根据一些实施方式的示例性注册窗口和登录窗口。图3的A部分图示了注册窗口300,图3的B部分示出了登录窗口310。
用户可能需要注册账户或登录由筛选系统管理的账户。用户可以是终端用户,诸如公司的招聘人员或人力资源人员。用户可以通过填写相关信息(例如,名字、姓氏、电子邮件、密码、确认密码、电话号码、雇主或公司以及国家)302、同意服务和隐私政策条款304并选择注册按钮306来注册账户。在用户注册账户之后,可以生成窗口310。用户可以通过键入与账户312相关联的用户的电子邮件地址和密码来登录账户。在一些实施方式中,在用户选择登录按钮314之后,可以显示图4的窗口400。在一些实施方式中,窗口400可以是用户在登录到其账户时看到的着陆页(或主页)。然而,本发明不限于此。可以考虑到任何类型的着陆页(或主页)。
参考图4,窗口400可以包括到筛选系统提供的不同应用/功能的多个链接。例如,窗口400可以包括到寻找模型的链接402、到筛选模型的链接404、到内部流动性模型的链接406、到下载的链接408、到邮箱的链接410、到用户的账户设置的链接412以及到常见问题(FAQ)部分的链接414。
图4图示了根据一些实施方式的示例性寻找模型窗口。用户可以使用寻找模型窗口访问一个或多个寻找模型。用户可以使用寻找模型来辨识与目标个体组最相似的候选人(即,与员工模型密切匹配的候选人)。因此,公司和招聘人员可以使用寻找模型来“寻找”人才。用户可以使用寻找模型来辨识满足截止阈值的候选人,并将这些候选人呈现给公司以满足其雇用需求。
寻找模型可以使用一个或多个员工模型。如前所述,员工模型可以包括针对公司具体工作职位的理想员工可能拥有的特点。员工模型可以代表公司的最佳员工的目标群体。可以将员工模型与基线组进行对比。可以从包括来自其他领域的员工的数据库中选择基线组,所述员工可以在人口统计因素(诸如性别、年龄、种族、教育背景)方面类似于进行基于神经科学的测试的目标员工组,但不与目标员工组在同一领域工作。可以将候选人与员工模型进行比较,以确定他们对公司中具体工作职位的匹配/兼容性。
如图4中所示,公司的最佳员工的目标组416可以包括八名员工,并且可以将目标组的员工模型与基线组418进行对比。可以将多个候选人(例如,四个)420与员工模型进行比较,以确定候选人与员工模型适配或匹配的程度。
如窗口400的右侧所示,组功能422可以是灵活的。组可以与公司或一组公司、职业领域等相关联。用户可以与不同的组相关联。例如,用户可以是已经由不同公司签约以辨识填补不同职位的候选人的第三方招聘人员。或者,用户可以是与公司内的不同组相关联的人力资源人员。可选地,用户可以是找寻多个跨学科领域中的最佳人才的招聘人员。因此,如果用户是多个组的成员,则用户可以在不同组之间切换424以访问不同的模型/数据。
用户可以在组功能422和设置功能426之间切换。稍后将参考图26、图27和图28在说明书中更详细地描述设置功能。
在一些情况下,可以在窗口400中提供聊天窗口428。用户可以使用聊天窗口与帮助代表实时通信。帮助代表可以与提供筛选系统的实体相关联。或者,用户可以在聊天窗口中向帮助代表留下消息。
当用户选择窗口400中的候选人420时,可以生成图5的窗口500。窗口500图示了根据一些实施方式的示例性候选人窗口。可以在候选人窗口中显示每个候选人的一般简档502。例如,可以在窗口500中显示各个候选人A、候选人B、候选人C和候选人D的一般简档502-1、502-2、502-3和502-4。每个一般简档可以包括候选人的图片504(例如,504-1、504-2、504-3和504-4)、候选人的教育背景506(例如,506-1、506-2、506-3和506-4)、到候选人简历的链接(例如,508-1、508-2和508-4),并指示候选人是否对公司发布的具体工作职位表达了兴趣(例如,510-1和510-2)。用户(例如,招聘人员)可以通过选择每个简档中的一个或多个按钮来保存512候选人的简档、联系514候选人或存档516候选人的简档。如窗口500中所示,候选人A和候选人B已经表达了对具体工作职位的兴趣(510-1和510-2),而候选人C和D尚未表达对工作职位的兴趣。候选人A、候选人B和候选人D已经上传了他们的简历(508-1、508-2和508-4),而候选人C尚未上传他的简历。候选人C和候选人D的简档已由用户保存(512-3和513-4),而候选人A和候选人B的简档尚未保存。
在图4的示例中,候选人链接520是灵活的,因为窗口400对应于候选人窗口。窗口400还可以包括员工链接522、参与链接524、模型特质链接526、模型准确度链接528和模型偏差链接530。每个链接将会在说明书他处详细描述。
在一些实施方式中,用户可以基于一组标准过滤候选人。图6图示了根据一些实施方式的图5的候选人窗口内的示例性过滤窗口。用户可以使用过滤窗口600来基于地理位置(例如,城市)602、候选人上的学校604、候选人获得的学位606和/或候选人毕业的年数608来过滤候选人。过滤还可以包括候选人是否新添加到系统610、候选人是否对工作职位感兴趣612、候选人是否已经上传了简历614、候选人是否在系统中使用化身(遮掩的身份)616、招聘人员是否已对简档进行保存618和/或存档620以及招聘人员是否已联系候选人622。应当注意,过滤不限于上述内容,并且可以包括能够帮助用户过滤候选人列表的附加过滤。
返回参考图5,当用户点击候选人A的一般简档502-1时,可以生成图7的窗口700。窗口700可以对应于候选人A的具体简档702。当用户向下滚动窗口700时,可以生成图8的窗口800。如图7和图8中所示,候选人A的工作经历和教育经历可以按时间顺序详细列出。如前所述,候选人A可能已经表达了对具体工作职位的兴趣并上传了她的简历。在该示例中,用户尚未联系候选人A,并且用户尚未保存或存档她的简档。窗口700还可以包括到候选人A的网络存在的链接704(例如,通过LinkedInTM、GithubTM、TwitterTM等)。如图8中所示,可以向用户(可以是招聘人员)提供链接802以联系候选人A。
当用户点击窗口700中的联系按钮706时,可以生成图9的窗口900。窗口900可以显示用户与候选人A之间关于具体工作职位的通讯902。当用户点击窗口700中的简历按钮708时,可以在窗口中显示候选人A的简历的副本。
返回参考图4,当用户选择窗口400中的员工416时,可以生成图10的窗口1000。或者,用户可以通过点击图5的窗口500中的员工链接522来访问窗口1000。图10图示了根据一些实施方式的示例性员工面板窗口。窗口1000可以示出每名员工1004在完成基于神经科学的游戏中的进度1002,以及基于员工的游戏玩法数据,每名员工是“组内””还是“组外”1006。在图10的示例中,除员工#4之外,所有员工可能已经完成了游戏,如1002中的进度条所示。另外,可以基于员工的游戏玩法数据确定所有员工都在组内1006。在一些实施方式中,用户可以通过键入搜索输入1008来搜索用户是组内还是组外。
当用户选择窗口500中的参与链接524时,可以生成图11的窗口1100。如图11中所示,可以向十名员工(总参与者1102)提供基于神经科学的游戏。九名员工已经完成了游戏1104,均未正在进行中1106,并且一名员工尚未开始玩游戏1108。参与快照1110可以显示在窗口1100的左侧部分上。参与快照可以包括员工在游戏中的参与率的视觉表示的饼图1112。窗口1100的右侧部分可以显示员工在不同时间段1116(例如,1个月、3个月、6个月、年初至今、1年等)的游戏完成进度的曲线图1114。
当用户将光标移动到参与率的视觉表示的饼图1112上时,可以显示不同的信息。例如,图12的A部分示出一名员工尚未开始玩游戏1202,并且图12的B部分示出九名员工已完成游戏1204。能够以不同格式(例如,PNG、JPEG、PDF、SVG矢量图像、CSV或XLS)1206下载员工的游戏玩法数据的图表,如图12的C部分中所示。
用户可以操纵窗口1100中的曲线图1114以查看不同时间点的员工的游戏完成进度。例如,如图13的A部分中所示,在第一时间实例1304处,没有员工完成游戏并且没有游戏正在进行1302。图13的B部分显示,在第二时间实例1308处,两名员工完成了游戏并且两名员工正在进行中1306。图13的C部分显示,在第三时间实例1312处,六名员工完成了游戏并且两名员工正在进行中1310。图13的D部分显示,在第四时间实例1316处,七名员工完成了游戏并且两名员工正在进行中1314。
当用户选择图5的窗口500中的模型特质链接526时,可以生成图14的窗口1400。窗口1400可以包括员工的特质1402的快照。特质快照可以包括不同特质类别1406的视觉表示的饼图1404。如前所述,可以使用例如筛选系统中的特质提取引擎从员工的游戏玩法数据(神经科学行为数据)提取特质。如特质快照所示,特质类别可以包括规划、学习、注意力、努力、风险和灵活性变化速度。当用户向下滚动窗口1400时,可以生成图15的窗口1500。
可以在位于特质快照1402下方的特质表1502中提供每个特质类别和(一个或多个)相关特质特点的描述。每个特质类别1406可以包括一个或多个特质特点1408。例如,风险类别1410可以包括多个特质特点,诸如主体在受控风险情况下的反应速度、显示谨慎的风险厌恶以及主体在高风险条件下和中等风险条件下有效学习的能力。学习类别1412可以包括多个特质特点,诸如主体轻松地从学习挫折中恢复的能力,以及主体在程序性学习中是否更快。努力类别1414还可以包括多个特质特点,诸如主体快速使出努力的能力,以及努力工作以实现目标的能力。
可以使用不同的颜色和阴影来将饼图1404中的部分彼此区分开。在一些实施方式中,可以针对每个特质类别使用不同的颜色方案。可以考虑到任何颜色方案或任何其他视觉区分方案(诸如形状、字体大小、阴影等)。
可以评估本文所述的基于神经科学的测试(游戏)对情绪和认知特质的测量精确度。测试的精确度对于确定基于神经科学的测试是否是这些特质的准确预测指标可能是重要的。为了探明基于神经科学的测试的精确度,可以执行信度评估。对于测试信度可以测量的一个输出是Pearson相关系数(r)。Pearson的相关系数可以描述两个结果之间的线性关系并且介于-1与+1之间。样本的相关系数r可以使用以下公式计算得到:
其中n是样本大小;i=1,2,...,n;X和Y是变量,以及和是变量的均值。Pearson相关系数的平方称为确定系数,并且可以用于在简单线性回归中解释作为X的函数的Y的方差分数。Pearson相关系数还可以用于描述效应大小,效应大小可被定义为两个组之间的关系的量级。当Pearson相关系数用作效应大小的测度时,结果的平方可以估计由实验模型解释的实验内的方差量。
如图15的窗口1500中所示,每个特质类别和对应的特质特点可以具有r值1416和R2值1418。每个特质特点的r值可以指示相应的特质特点与员工模型中的预测方程之间的相关性。每个特质特点的R2值可以指示如相应的特质特点所表示的员工模型中的方差。
可以将每个特质类别中的(一个或多个)特质特点的R2值相加并用于生成特质快照中的饼图。用户可以通过将光标移动到饼图上的每个特质类别来查看每个特质类别的R2值。例如,当用户将光标移动到饼图上的“灵活性变化速度”类别上时,可以生成弹出窗口1602,其显示该类别的总R2值为0.114(如图16的A部分中所示)。类似地,当用户将光标移动到饼图上的风险类别上时,可以生成弹出窗口1604,其显示该类别的总R2值为0.356(如图16的B部分中所示)。可以通过将特质特点“在风险可控的情况下反应较慢”(0.101)、“显示谨慎的风险厌恶”(0.095)、“在高风险条件下有效学习”(0.085)和“在中等风险条件下学习不佳”(0.075)的R2值相加来获得风险类别的总R2值。
信度可以是测量随时间推移一致并且没有随机误差的程度的指标。信度可以测量测试结果是否稳定且内部一致。测试-重测方法是也可用于测试信度的一种测量。当在两个不同时间对主体实施相同测试时,测试-重测信度测试可以测量样本结果的变化。如果在两个不同时间给出的测试结果相似,则该测试可被认为是可信的。这两个结果之间的关系可以使用Pearson相关系数来描述;相关系数的值越高,则测试的信度就越高。
测试-重测信度的相关系数的值例如可以为约-1.0、约-0.95、约-0.9、约-0.85、约-0.8、约-0.75、约-0.7、约-0.65、约-0.6、约-0.55、约-0.5、约-0.45、约-0.4、约-0.35、约-0.3、约-0.25、约-0.2、约-0.15、约-0.1、约-0.05、约0.05、约0.1、约0.15、约0.2、约0.25、约0.3、约0.35、约0.4、约0.45、约0.5、约0.55、约0.6、约0.65、约0.7、约0.75、约0.8、约0.85、约0.9、约0.95或约1.0。
可用于测量测试的信度的另一测试是分半信度测试。分半信度测试将测试分为两个部分,假设这两个部分包含相似的主题,并且对样本实施测试。继而,将来自主体的每一半测试的分数彼此进行比较。来自测试的两半的分数之间的相关性和相似程度可以使用Pearson相关系数来描述,其中如果相关性高,则测试是可信的。
分半信度的相关系数的值例如可以为约-1.0、约-0.95、约-0.9、约-0.85、约-0.8、约-0.75、约-0.7、约-0.65、约-0.6、约-0.55、约-0.5、约-0.45、约-0.4、约-0.35、约-0.3、约-0.25、约-0.2、约-0.15、约-0.1、约-0.05、约0.05、约0.1、约0.15、约0.2、约0.25、约0.3、约0.35、约0.4、约0.45、约0.5、约0.55、约0.6、约0.65、约0.7、约0.75、约0.8、约0.85、约0.9、约0.95或约1.0。
有效性是测试测量目的是什么的程度。对于要作为有效的测试,测试能够展示出该测试的结果被上下文支持。具体而言,关于测试有效性的证据可以经由测试内容、响应过程、内部结构、与其他变量的关系以及测试后果来呈现。
霍特林T方检验(Hotelling’s T-squared test)是多变量测试,其可由筛选系统采用来确定使用该系统的不同主体群体的结果的均值的差异。T方测试的测试统计量(T2)是使用以下公式计算得到的:
其中是样本均值,Sp是样本的合并方差-协方差,以及n为样本大小。
为了计算F-统计量,使用以下公式:
其中p是被分析的变量的数目,并且F-统计量是以自由度p和n1+n2–p的F-分布。F-表可以用于确定在指定α水平或显著性水平下的结果的显著性。如果观察到的F-统计量大于在表中以正确自由度找到的F-统计量,那么测试在所定义的α水平下显著。例如,如果α水平被定义为0.05,则结果可能在小于0.05的p-值处显著。
方差分析(ANOVA)是统计测试,其可由筛选系统使用来确定两个或更多个数据组的均值之间的统计上的显著差异。ANOVA的F-统计量可以计算如下:
其中是样本均值,n是样本大小,s是样本的标准偏差,I是组的总数,以及N是总的样本大小。F-表继而用于确定在指定α水平下结果的显著性。如果观察到的F-统计量大于在表中以指定自由度找到的F-统计量,那么测试在所定义的α水平下显著。例如,如果α水平被定义为0.05,则结果可能在小于0.05的p-值处显著。
霍特林T方检验或ANOVA的α水平例如可以设置在约0.5、约0.45、约0.4、约0.35、约0.3、约0.25、约0.2、约0.15、约0.1、约0.05、约0.04、约0.03、约0.02、约0.01、约0.009、约0.008、约0.007、约0.006、约0.005、约0.004、约0.003、约0.002或约0.001处。
返回参考图5的窗口500,当用户选择模型准确度链接528时,可以生成图17A的窗口1700。窗口1700可以包括员工模型的准确度报告快照1702。准确度报告快照可以包括曲线图1704,其示出了组内或组外的员工的比例。该曲线图可以包括对应于组外员工的第一密度图1706,以及对应于组内员工的第二密度图1708。用户可以在第一密度图和第二密度图的曲线重叠的区域中绘制决策边界1710。例如,落在决策边界左侧的员工可以被分类为组外,而落在决策边界右侧的员工可以被分类为组内。与落在决策边界略微左侧的员工相比,落在决策边界最左侧的员工可能更有可能被正确分类为组外。相反,与落在决策边界略微右侧的员工相比,落在决策边界最右侧的员工更有可能被正确分类为组内。落入重叠区域的员工可以被分类为组内或组外,并且在一些情况下,可以代表进行基于神经科学的测试的员工总数的一小部分。
用户可以使用决策边界1710作为用于评估候选人的游戏表现的阈值。例如,图17B图示了根据一些实施方式将一组候选人的特质与图17A的员工模型进行比较的结果。如图17B的窗口1750中所示,可以在一个或多个密度图中描绘比较结果。例如,比较结果可以包括对应于与组内员工更密切地匹配的候选人的第三密度图1720。另外,比较结果还可以包括对应于与组外员工更密切地匹配的候选人的第四密度图1722。用户可以确定落在决策边界右侧的候选人可能在具体工作职位获得成功,因为他们更密切地匹配组内员工。同样,用户可以确定落在决策边界左侧的候选人更不可能在具体工作职位获得成功,因为他们更密切地匹配组外员工。
在一些实施方式中,决策边界不需要位于第一密度图和第二密度图的曲线重叠的区域。用户可以根据用户希望更具包容性(即,包括更大的候选人池)还是更严格(即,缩小候选人池)来调整决策边界的位置。例如,当用户将决策边界向重叠区域的左侧移动到组外密度图内(1710-1)时,可能有更多候选人能够满足决策边界阈值1710-1。相反,当将决策边界向重叠区域的右侧移动到组内密度图内(1710-2)时,可能有更少候选人能够满足决策边界阈值1710-2。因此,用户可以根据公司的筛选和雇用需求来调整决策边界(例如,公司是否愿意接受更大的候选人池,或者仅需选定数目的候选人)。
用户可以将光标移动到窗口1700中的密度图上,以查看相对于决策边界在组内或组外的员工的百分比。例如,图18的A部分示出,37.9%的员工可能在第一密度图上的选定点1802处的组外。图18的B部分示出,8.33%的员工可能在第二密度图上的选定点1804处的组内。
返回参考窗口1700,模型准确度报告可以包括命中1712、未命中1714、误报1716和正确否定1718。上述参数的细节图示于图19的窗口1900中。命中1712可以对应于被标记为组内,并且被模型分析引擎预测并正确地分类为组内的员工。未命中1714可以对应于被标记为组外,被模型分析引擎错误地分类为组外,但是应该被分类为组内的员工。误报1716可以对应于被标记为组内,但是被模型分析引擎正确地分类为组外的员工。正确否定1718可以对应于被标记为组外,并且被模型分析引擎预测并正确地分类为组外的员工。
窗口1900可以包括分类表1902,其总结了命中、未命中、误报和正确否定的结果。在图19的示例中,模型分析引擎确定了12个命中和29个正确区域,在模型中产生100%的准确度。分类表1902可以基于根据一组员工的游戏玩法数据生成的单个员工模型。
在一些实施方式中,窗口1900还可以包括交叉验证表1904。对于交叉验证表而言,可以为每个员工生成模型,并且可以相互交叉验证多个模型以预测每个员工的组内或组外状态。与分类表1902不同,交叉验证表1904不需要预先标记员工在组内还是组外。因此,与分类表相比,交叉验证表可以提供对模型更精确的分析,并且可以用于验证分类表的准确度。
返回参考图17A,当用户点击窗口500中的模型偏差链接530时,可以生成图20的窗口2000。窗口2000可以基于员工的不同固有特点提供关于模型是否偏差(或偏斜)的信息。例如,窗口2000可以包括性别偏差(gender bias)报告快照2002和种族偏差报告快照2004。性别偏差报告可以按性别(男性和女性)分类,种族偏差报告可以按种族(例如,白种人、黑种人、亚裔、西班牙裔/拉美裔等)分类。每份报告可以显示每个性别或种族群体内适配分数的条形图2006和2008。当用户向下滚动窗口2000时,可以生成图21的窗口2100。窗口2100可以包括总结性别偏差测试结果的性别偏差表2102,以及总结种族偏差测试结果的种族偏差表2104。用户可以将光标移动到条形图上方以查看不同组的平均适配分数,例如如图22中所示。在图22的A部分中,弹出窗口2202可以显示男性员工的平均适配分数为45.49。在图22的B部分中,弹出窗口2204可以显示亚洲人员工的平均适配分数为42.55。
适配分数可以是对员工的基于神经科学的单个评估的分数的加总。可以进行适配分数的多变量统计分析以评估人口统计因素对分数的影响。例如,可以使用霍特林T方检验来评估性别组之间的统计上显著的差异(如果有的话)。可以使用多变量ANOVA测试来评估不同种族组之间的统计上显著的差异(如果有的话)。在图20的示例中,多变量统计分析显示性别或种族中在统计上均不与适配分数显著相关。
返回参考图4,当用户选择窗口400左侧的筛选链接404时,可以生成图23的窗口2300。图23图示了根据一些实施方式的示例性筛选模型窗口。用户可以使用筛选模型窗口访问一个或多个筛选模型。筛选模型与寻找模型之间的区别在于对员工模型和候选人来源的使用,而不是员工模型本身。支持筛选和寻找的模型可以是相同的。对于寻找而言,用户(例如,招聘人员)可以使用寻找模型来辨识与目标个体组最相似的候选人(即,辨识与员工模型密切匹配的候选人),并将这些候选人呈现给公司以满足其雇用需求。对于筛选而言,公司可以使用筛选模型来筛选公司已经选择的候选人池。在寻找中,招聘人员可能仅向公司提供通过阈值截止的候选人,并且不需要分享未通过阈值截止的候选人的数据。相反,公司可以在筛选中接收所有候选人的数据,无论每个候选人是否超过阈值截止。
如前所述,员工模型可以代表公司的最佳员工的目标组,并且可以将员工模型与基线组进行对比。可以从包括来自其他领域的员工的数据库中选择基线组,所述员工可以在人口统计因素(诸如性别、年龄、种族、教育背景)方面类似于进行基于神经科学的测试的目标员工组,但不与目标员工组在同一领域工作。可以将候选人与员工模型进行比较,以确定他们对公司的具体工作职位的匹配/兼容性。
参考图23中的窗口2300,公司的最佳员工的目标组2316可以包括八名员工,并且可以将目标组的员工模型与基线组2318进行匹配。可以将多个候选人3220(例如,五个)与员工模型进行比较,以确定候选人与员工模型适配或匹配的程度。
当用户选择窗口2300左侧的内部流动性链接406时,可以生成图24的窗口2400。图24图示了根据一些实施方式的示例性内部流动性模型窗口。用户可以使用内部流动性模型窗口访问一个或多个内部流动性模型。内部流动性模型窗口、筛选模型与寻找模型之间的区别在于对员工模型和候选人来源的使用,而不是员工模型本身。支持筛选、寻找和内部流动性的模型可以是相同的。公司可以使用内部流动性模型来寻找公司内的候选人2420,以便那些候选人可以在公司内部具有流动性并且承担使其潜力最大化的不同功能/角色。在一些实施方式中,候选人可以玩基于神经科学的游戏,该游戏可以托管在公司的内联网网站上。基于候选人的游戏玩法表现,内部流动性模型可以针对公司内的合适位置向候选人推荐匹配。类似于寻找模型和筛选模型,候选人2420还与最佳员工的目标组2416的员工模型相匹配。
当用户选择图23的窗口2300左侧的邮箱链接410时,可以生成图25的窗口2500。窗口2500可以包括用户与不同候选人(例如,候选人A和候选人B)之间关于具体工作职位的通讯(消息)2502。
当用户选择图23的窗口2300中的账户链接412时,可以生成窗口2600。窗口2600可以允许用户管理用户可以与之关联的组的组设置2602。例如,用户可以更新特定组的公司名称2604、公司大小2606和公司徽标2608。
当用户选择窗口2600中的定制链接2610时,可以生成图27的窗口2700。用户可以通过在窗口2700中提供他们的电子邮件地址2704来邀请并授予其他用户访问他/她的账户的许可2702。用户还可以启用或禁用供其他用户查看的某些特征2706。例如,如图27和图28的窗口2700和窗口2800所示,用户可以选择其他用户可以在账户中查看哪些特征。这些特征可以包括特质报告2706-1、职业报告2706-2、公司报告2706-3、招聘报告2706-4、候选人或员工的个人简档2706-5、关系2706-6、仪表板2706-7等。
当用户选择窗口2300中的FAQ链接414时,可以生成图29和图30的窗口2900和窗口3000。窗口2900和窗口3000可以提供到关于不同模型如何工作、候选人寻找/筛选等常见问题的答案的链接2902。如果用户没有找到问题的答案,则用户可以使用图31的窗口3100输入问题。
图32是系统的分析引擎可以如何用作商业实体的预测模型的概况,该商业实体试图预测潜在雇用作为员工将会获得成功的似然度。在第一步中,当前员工可以完成系统的测试。在测试完成后,系统可以基于员工在测试中的表现提取认知和情绪特质数据。接下来,系统可以使用员工的评级数据和测试数据来训练分析引擎,以确定商业实体的具体职位的理想员工应该拥有哪些特点。
一旦分析引擎得到充分培训,该模型就可以在第二步中用于预测性分析和预示。首先,候选人可以完成系统的测试。完成后,系统可以基于候选人在测试中的表现提取关于候选人的特质。继而可以将来自测试的数据应用于经训练的分析引擎以为候选人创建适配分数。这些预测模型可以用于评估包括例如潜在雇用在公司的特定角色中将会成功的似然度等因素。准确的预测模型可以检测细微的数据模式以回答有关员工未来表现的问题,以便指导雇主优化其人力资本。
本发明的系统可以提供向主体提供计算机化任务的方法。所述任务可以是基于神经科学的情绪或认知评估。在任务完成后,系统可以基于主体在任务上的表现来测量主体的表现值。继而可以基于该表现值评估具体特质,其中所评估的特质可以用于为主体创建简档。继而可以通过计算机系统的处理器将该特质与测试主体的数据库进行比较。可以使用主体的特质与测试主体的数据库的比较来创建对测试主体特定的模型。继而可以使用该模型对主体进行评分,这可以帮助创建主体的情绪或认知的定量评估。测试主体可以为商业实体工作。可以使用主体的特质与测试主体的数据库的比较来确定该主体是否适合被雇用。
本发明的系统可以提供向主体提供计算机化任务的方法。所述任务可以是基于神经科学的情绪或认知评估。在任务完成后,系统可以基于主体在任务上的表现来测量主体的表现值。继而可以基于该表现值评估具体特质,其中所评估的特质可以用于为主体创建简档。所评估的特质可以进一步用于基于对主体的超过一种特质的评估以及主体的模型与参考模型的比较来生成主体的模型。继而可以使用计算机系统的处理器基于主体的特质与测试主体的数据库的比较来辨识主体的职业倾向。将主体的特质与测试主体的数据库进行比较也可以用于生成主体的模型。比较结果可以输出给雇用官。比较结果可以进一步用于向主体推荐职业。
以下是可以提供给员工、候选人和主体的游戏中的基于神经科学的任务,以及完成这些任务所获得的结果的实施例。
实施例1:类比推理。
类比推理任务可以测量主体辨别看起来不相关的概念或事件之间的联系的能力。类比推理可以进一步是指这样的任务:其使用类比来对表面上看起来不相似的情境或表示之间的新颖联系进行建模。类比推理通常与创造性的问题解决相连结,这是因为两者都需要个体在特定任务的约束内产生创新的想法。两种情境显得越不相干,类比推理过程就能越有创造性。两种情境、概念、事件或表示之间的相似度可以通过语义距离来描述。语义距离越大,所呈现的这两个情境之间存在的相似性就越小。在类比推理任务中,语义距离可以与独立评级者对创造性的评价高度相关,这是因为当主体在看起来非常不相似的情境之间形成联系时,该主体可被认为是更具创造性。功能性磁共振成像(fMRI,functional magnetic resonance imaging)可以用于测量类比推理任务期间的大脑活动,并且类比项之间的语义距离可以参数化地变化。关键是,类比映射的语义距离而非由响应时间、正确性和评级难度所测定的任务难度可以调节大脑活动。
在本发明中,向主体呈现两组词对并继而要求主体确定第二组是否与第一组之间的关系类似。本发明的系统使用本科生样本(N=38)进行了测试-重测研究,其中在测试期之间有两周间隔。发现类比推理任务的测试-重测信度在约r=0.63处是可接受的。
实施例2:仿真气球冒险任务(BART,Balloon Analogue Risk Task)。
在BART中,主体在计算机游戏中挣了钱,其中随着每次点击卡通泵,就向临时银行账户中存放充气的模拟气球和少量的钱。允许主体在任何点处收集钱。然而,如果气球弹出,则临时银行账户不累积钱并且试验结束。主体的点击数用作对冒险的测度,并且该任务持续达约80次试验。
在BART上的表现可以与若干其他风险相关构思有关,所述构思包括Barratt冲动量表(Barratt Impulsivity Scale)、感觉寻求量表(Sensation Seeking Scale)以及行为约束量表(Behavioral Constraint scale)。
BART的有效性可以通过察看BART上的表现如何与测试主体完成的自我报告测度相关来确定。为了展示出BART在预测风险性行为中有效性递增,可以使用年龄、性别、冲动性以及步骤一中的感觉寻求和步骤二中的将BART结果作为因素计入来完成逐步回归分析。步骤一和步骤二中的回归分析可以示出,即使在控制其他因素时,较高的BART分数也可以与较高的风险性行为的倾向相连结。BART可以与冲动性、感觉寻求以及风险分数显著相关,而与其他人口统计因素不具有显著相关性。
测试-重测研究是由本发明的系统使用本科生样本(N=40)进行的,其中在测试期之间有两周间隔。发现测试-重测信度的范围从r为约0.65至约0.88变化,这取决于风险水平。对社区样本(N=24)进行的另一研究示出分半信度的范围从r为约0.88至约0.96变化,这取决于风险水平。
实施例3:选择任务。
选择任务可以用作主体的冒险倾向的测度。选择任务可以包括一组场景,其中要求主体基于一系列选择集来进行评价。所述选择集可以包括相互排斥且相互独立的备选项,并且通常而言,一个备选项可被认为是这两个选项中更具风险性的那个。可以进行研究,其中要求主体完成测量个性和行为风险测度的多种测试。主体可以完成的测试包括Zuckerman的感觉寻求量表、Eysenck的冲动量表、回顾性行为自我控制量表、域特定冒险量表、选择任务、仿真气球冒险任务、方差偏好任务、未来贴现I以及未来贴现II。可以进行主成分分析以确定哪些主成分是基础的风险测度。例如,方差偏好可以与选择任务有关。方差偏好可以是针对风险的有力测度,并且可被描述为兴奋和外向的个性倾向。
在本发明的系统中,询问主体他们是否将收到固定数量的钱或者对收到更高数量的钱的机会上下注。可以改变钱的数量以及收到钱的机会,以使选项看起来更有风险或不那么有风险。系统进行了两个研究来建立选择任务的测试-重测信度。一个研究是利用本科生样本(N=40)进行的,其中在测试期之间有两周间隔。发现测得的测试-重测信度约为r=0.62。第二个研究是使用社区样本(N=24)的分半信度研究。发现分半信度约为r=0.82。
实施例4:独裁者任务(Dictator Task)。
独裁者任务可以在行为经济学中使用,作为对慷慨和利他主义的测度。为了确定该游戏的有效性,可以要求主体报告其在过去一年的慈善事业。例如,能够发现在任务期间捐赠其虚构收入的主体在过去一年中实际上比在该任务期间没有捐赠其虚构收入的那些主体向慈善事业捐赠得更多。
在本发明中,主体与随机参与者配对,其中该主体和随机参与者最初都收到相同数量的钱。随后,给予主体额外数量的钱并且指示主体不将该钱给予随机参与者或者将该钱中的一些或全部给予随机参与者。捐赠给随机参与者的钱的数量用作对利他主义的测度。测试-重测研究是由本发明的系统使用本科生样本(N=40)的,其中在测试期之间有两周间隔。发现测试-重测信度在约r=0.62处是可接受的。分半信度还可以使用社区样本(N=24)测量得到,并且发现信度在约r=0.65处是可接受的。
实施例5:数字广度。
数字广度任务可以用于测量主体的工作记忆数存储容量。在本发明的系统中,向主体呈现一系列数字并且在提示时要求主体通过在键盘上输入数字来重复数字的序列。如果主体成功地背诵出所述数,那么给予该主体更长的要记住和背诵的序列。主体可以记住的最长列表的长度是该主体的数字广度。
数字广度会与工作记忆的所有测度(包括用于表示容量和处理的测度)正相关,并且数字广度会与年龄负相关。对于健康成人而言数字广度任务在一个月的间隔内能够具有足够的信度。
进行数字广度测试。在社区样本(N=23)中,发现针对数字广度任务的分半信度在r=0.63处是可接受的。在测试期之间有两周间隔的情况下对本科生样本(N=39)进行的测试-重测研究还示出了可接受信度,其中r=0.68。
实施例6:EEfRT(简单或困难)。
付出努力以获得奖励任务(EEfRT,Effort-Expenditure for Rewards Task)可用于探索人类基于努力的决策。EEfRT可以测量个人愿意付出多少努力来获得奖励。在多个分析中,在快感缺乏与为奖励愿意付出努力之间可以观察到显著的相反关系。特质快感缺乏增加可以显著地预测出为奖励付出努力的总体似然度减小,这指示出EEfRT任务可以是激励和基于努力的决策的有效代用指标(proxy)。
在本发明的系统中,向主体呈现完成简单任务或困难任务的选择。相比于困难任务,简单任务涉及更少次地按键盘的空格键。简单任务的完成保证每次有相同的奖励,而困难任务的完成提供了收到高得多的奖励的机会。将更倾向于挑选较困难任务的主体评估为更多地受到奖励激励,即使需要更多的努力亦如此。
系统进行了对EEfRT的信度测试。在社区样本(N=24)中,发现EEfRT的分半信度在r=0.76处在平均值以上。第二个研究是使用本科生样本(N=40)进行的,其中在测试期之间有两周间隔。发现测试-重测信度在r=0.68处是可接受的。
实施例7:面部情绪测试。
如果面部表情提供了相关但不清楚的信息,则情境因素可能对主体对情绪表情的解读具有强烈的影响。在有限的背景下,大多数主体可以判断表达者感觉到与情境相匹配的情绪,而非其实际的面部表情。当暗示非基本情绪时,情境信息可能尤其有影响力,例如,一个人可能处于痛苦的情境中,却显示出恐惧的表情。判断该人表情的主体常常推断出该人的表情是痛苦而非恐惧的表情。
在本发明的系统中,向主体呈现显示不同情绪的男人和女人的照片。在一些情况下,一些照片与描述情境的故事一起呈现,而其他照片则单独呈现。指示主体从一组四种情绪中选择最佳地描述了照片中的人的表情的情绪。把在未呈现有故事的情况下会正确地辨识出情绪的主体描述为具有敏锐的读取面部表情的能力。
系统对面部影响任务进行信度测试。使用社区样本(N=24)来测量面部影响任务的分半信度。发现分半信度在平均值以上,其中r值范围从约0.73-0.79。测量两次本科生样本(N=40),其中在测试期之间有两周间隔。发现测试-重测信度是可接受的,其中r值约为0.57-0.61。
实施例8:手指敲击(按键)。
手指敲击测试(FTT,Finger-Tapping test)是一种心理测试,其可以评估神经肌肉系统的完整性并检查运动控制。该任务可以在一个月的间隔内具有良好的信度。
可以对健康主体进行简单的运动敲击任务。可以要求主体在60秒内尽可能快地用其惯用手的食指敲击触屏监视器上的静止圆圈。测试-重测间隔可以约为四周,并且可以具有相当高的信度相关性。
在本发明的系统中,要求主体在指定时间量内使用惯用手重复点击键盘的空格键。使用社区样本(N=24)来评估FTT的分半信度。发现关键测度在r值约为0.68-0.96时是可信的。测试-重测研究使用了本科生样本(N=40),其中在测试期之间有两周间隔。发现相关测度的信度在r值介于约0.58-0.77之间时是可接受的。
实施例9:未来贴现(Future Discounting)。
时间上的未来贴现可以是指相比于未来但可观的奖励,个体更喜欢直接但适度的奖励的程度。可以将时间贴现建模为指数函数,从而导致偏好随时间延迟的增加而单调减小,其中个体通过随奖励延迟而增加的因子来对未来奖励值进行贴现。双曲线贴现可以是指时间不一致的未来贴现的模型。当双曲线模型用于对未来贴现进行建模时,模型可以表明,对于小的延迟周期,估值下降得很快,但是对于较长的延迟周期,则下降得缓慢。双曲线可以显示比其他模型更好的适配,从而提供个体对延迟的奖励进行贴现的证据。
在本发明的系统中,向主体呈现问题,其中主体必须在现在接收一定数量的钱或者在未来的指定时间接收更多的钱之间进行选择。改变钱的数量以及将钱给予主体的时间以增加或减小奖励的延迟和大小。
系统对未来贴现任务进行了信度测试。使用社区样本(N=24)来评估未来贴现任务的分半信度。发现经对数变换的数据的分半信度在约r=0.65处是可接受的。测试-重测研究使用本科生的样本(N=40)对未来贴现任务的信度进行了评估,其中在测试期之间有两周间隔。发现经对数变换的数据的信度在约r=0.72处是可接受的。
实施例10:Flanker任务。
Flanker任务可以用于检查主体的任务切换能力。Flanker任务可以是指一组反应抑制测试,反应抑制测试用于评估遏制在特定背景下不适当的反应的能力。Flanker任务可以用于评估选择性注意和信息处理能力。靶可由非靶刺激侧抑制(flank),所述非靶刺激对应于与该靶相同的定向反应(一致刺激)、对应于相反的反应(不一致刺激),或者不对应于两者中任一种(中性刺激)。给予主体关于该主体应当如何对他们所看到的作出反应的不同规则。
当要求主体切换任务和重复任务时,可以观察到一贯不佳的表现,这显示出flanker任务的任务切换效果的有效性。与一致刺激相比,在Flanker任务期间可以激活可以对不一致刺激作出更积极反应的前扣带皮层(ACC,anterior cingulate cortex),并且其可以监视任务的冲突量。在下一试验中,由ACC测量的冲突水平可以向主体提供更多的控制,这指示出在试验n中所呈现的冲突越多,在试验n+1中能够由主体呈现的控制就越多。
Flanker任务和经颅磁函数(TMS,transcranial magnetic function)可以用于找到导致误差后减慢(PES,post-error slowing)的误差后调整的时间进程。一些结果可以显示出,活动运动皮层的兴奋度可以在错误反应之后减小。
在本发明的系统中,指示主体根据呈现的五个箭头的方向和颜色来按压键盘上的具体箭头键。如果红色箭头是五个红色箭头之中的中心箭头,那么该中心的红色箭头的方向规定了按哪个键。如果红色箭头是都指向同一方向的四个蓝色箭头中的中心箭头,那么蓝色箭头的方向规定了主体应当按哪个键。例如,如果向主体显示出指向右的五个红色箭头的序列,那么该主体应当按右箭头键。如果下一图像显示出红色,中心箭头指向右,但其余的红色箭头指向左,那么该主体应当再次按右箭头键。然而,如果下一图像显示出红色,指向右的中心箭头由指向左的蓝色箭头围绕,那么该主体应当已经按了左箭头键。推动基于“flanker”的正确的箭头键或围绕中心箭头的箭头的能力用于测量主体的任务切换能力。
系统对Flanker任务进行了信度测试。使用社区样本(N=14)来评估Flanker任务的分半信度。发现关键测度在r值约为0.70-0.76时是可信的。在第二个研究中,使用本科生样本(N=34)来评估测试-重测信度。发现相关测度的结果在r值约为0.51-0.69时是可接受的。
实施例11:Go/No-Go。
Go/No-Go测试可用于评估主体的注意广度和反应控制。Go/No-Go测试的示例可以包括在呈现具体刺激时使主体按下按钮(“Go”),而在呈现不同刺激时不按下相同按钮(“No-Go”)。尤其是对于抑制试验而言,Go/No-Go测试上的表现可能与通过Wisconsin卡片分类任务(Wisconsin Card Sorting Task)、Stroop色词测试(Stroop Color-Word Test)和连线测试(Trail Making Test)所测得的复杂的执行功能相关。
在本发明的系统中,向主体呈现红色圆圈或绿色圆圈并且指示主体在示出红色圆圈时按下空格键,而在示出绿色圆圈时不按任何键。使用社区样本(N=23)来研究Go/No-Go任务的分半信度。发现相关测度的分半信度在r值约为0.56时是可接受的。测试-重测研究也是对本科生样本(N=33)进行的,其中在测试期之间有两周间隔。发现关键测度的信度很强,约为0.82。
实施例12:眼神读心(Mind in the Eyes)。
眼神读心测试可以通过评估主体仅使用眼睛周围的表情来识别他人的精神状态的能力来评价该主体的社会认知。可以进行使情绪类型、用作刺激的面容数量以及刺激的性别发生改变的一系列实验来确定主体如何感知基本情绪和复杂情绪。健康控制可以从整个面部来感知基本情绪和复杂情绪二者良好,但对于复杂的精神状态,主体的分数在仅察看眼睛时可能更高。这一发现暗示出,眼睛能够比整个面部拥有更多的信息。
在本发明的系统中,向主体呈现在照片中仅展现个体的眼睛的一系列照片。继而指示该主体选择他们觉得眼睛最佳地表示出的情绪。情绪的选择范围从例如悲伤、快乐、生气和惊讶等基本情绪到例如傲慢、遗憾、判断和紧张等复杂情绪变化。将能够从眼睛正确地解读出情绪的主体描述为在情绪上更具洞察力。
系统对眼神读心任务进行了信度测试。在社区样本(N=23)中评估眼神读心任务的分半信度,并且该分半信度具有平均值之上的相关性,约为r=0.74。在测试期之间有两周间隔的情况下对本科生样本(N=38)进行的测试-重测研究具有约为r=0.67的可接受信度。
实施例13:N-Back(字母)。
N-back任务是持续操作任务,其可以用于测量主体的工作记忆。例如,可以向主体呈现刺激的序列,并且该主体必须指出当前刺激何时与该序列中n步前的刺激相匹配。可以调整n的值以使任务更难或不那么难。可以将两个复杂度水平下的N-back任务与韦氏成人智力量表修订版(WAIS-R)上的数字广度测试中的表现进行比较。N-back任务的准确度分数可以与WAIS-R的数字广度子测试中的表现正相关。WAIS-R的数字广度子量表能够反映某些认知过程,所述认知过程能够与工作记忆容量重叠,从而指示出N-back任务的准确度分数可能与个体在工作记忆容量方面的差异相关联。
在本发明的系统中,向主体呈现字母并且指示主体当在两个帧之前显示相同字母时按下空格键。将能够正确地辨识第二例字母的主体评估为具有高工作记忆。
系统对N-Back任务进行了信度测试。在社区样本(N=24)中评估了N-Back测试的分半信度,并且发现该分半信度在约r=0.83处具有平均值以上的信度。测试-重测研究使用了本科生样本(N=38),其中在测试期之间有两周间隔。发现信度在约r=0.73处是可接受的。
实施例14:图案识别。
图案识别任务可以测量主体从刺激或物体的序列中辨别图案和相似点的能力。
Raven的渐进矩阵(RPM,Raven’s Progressive Matrices)测试与图案识别任务相似。高级渐进矩阵(APM,Advanced Progressive Matrices)测试——是Raven的渐进矩阵测试的一种形式——能够具有非常好的测试-重测信度。信度系数可以从约0.76到约0.91变化。
在本发明的系统中,向主体呈现彩色正方形的网格,其中一个角缺失。主体必须从六个图像中选择一个将正确地使该网格中的图案完整的图像,并且将能够正确地辨识出该图像的主体评估为具有较高的图案识别能力。
系统对图案识别任务进行了信度测试。为了评估测试-重测信度,对本科生样本(N=36)实施了该任务,其中在测试期之间有两周间隔。发现信度在约r=0.55处是可接受的。
实施例15:奖励学习任务。
为了评估主体根据奖励调整行为的能力之间的关系,可以开发奖励学习任务,其中主体挣得通过区别强化时间表所确定的某数量的钱。可以向主体呈现选择,其中一个选择可以与奖励相关联,但是奖励的接收取决于挑选了正确的选择。随着主体得知哪个选择是正确的,可以增加奖励。
在本发明的系统中,向主体呈现具有短嘴或长嘴的数字脸。脸长的差异是最小的,但可被人眼感知到。要求主体在呈现具有长嘴的脸时按下右箭头键并且在呈现具有短嘴的脸时按下左箭头键。另外,告诉主体如果他们挑选出了正确的选择则可以收到钱。奖励学习任务用于基于接收到奖励来确定主体是否能够得知哪个刺激是正确的。
系统对奖励学习任务进行了信度测试。在社区样本(N=24)中评估了奖励任务的分半信度,并且发现关于关键测度,该分半信度具有平均值以上的信度,其中r=0.78。在测试-重测研究中使用了本科生样本(N=40),其中在测试期之间有两周间隔。发现关键测度的测试-重测信度在约r=0.66处在平均值以上。
实施例16:伦敦塔(TOL,Tower of London)。
TOL任务可以用于评估执行功能和规划能力。对于任务的不同难度水平,可以计算平均移动次数和平均初始思考时间(ITT,initial thinking time)。ITT可以对应于呈现拼图与主体开始解决拼图的时刻之间所经过的时间。负相关可以存在于总平均ITT分数与总平均移动分数之间,这暗示出较长的ITT分数有助于减少移动次数,换句话说,ITT能够反映规划。测量移动次数、准确表现以及在伦敦塔任务中作出第一次移动之前的时间的变量可以具有介于0.61与1.43之间的效应大小。
可以评估用于在搜索和临床环境中使用的一系列TOL任务以在最小移动上显示出任务难度的明显且近乎完美的线性增加。换句话说,表现不佳、表现中等以及表现良好的主体可以分别在多达但不超出低水平、中等水平以及高水平最小移动的问题上获得正确的解决方案。任务的准确度可以根据最小移动次数而不同。
在本发明的系统中,向主体呈现两组钉子,每组三个钉子。靶组钉子在一个钉子周围具有五个彩色圆盘,而实验组钉子具有跨这三个钉子分布的五个彩色圆盘。任务的目标是使实验组中的彩色圆盘的布置与靶组的彩色圆盘的布置相匹配。将可以在指定时间段内以最小移动次数完成任务的主体评估为具有高规划能力。
系统对TOL任务进行了信度测试。在社区样本(N=24)中评估了TOL任务的分半信度,并且发现该TOL任务对于时间—关键测度具有良好信度,约为r=0.77。使用本科生样本(N=39)进行了测试-重测研究,其中在测试期之间有两周间隔。发现使用这种方法的时间信度在约r=0.69处在平均值以上。
实施例17:信任任务。
信任任务可以用于研究信任和互惠,同时控制声誉、合同义务或惩罚。信任任务可以具有两个阶段。首先,给予主体钱,并且继而所述主体可以决定其将会向不同位置的未知人派送多少钱(如果有的话)。可以告诉主体他们派送的钱在到达其他人时数量将会加倍。继而,该其他人具有将钱派送回主体的选项。
信任任务的表现可以与个性测度相关联,所述个性测度包括马基雅维里主义(Machiavellianism)和关系动机,例如,对他人的高度关注以及对自我的较少关注。参与信任任务能够影响神经生理反应,例如,催产素的产生,并且能够与大脑区域中与信任和社会关系相关的神经反应的位置、量级和定时相关联。
在本发明的系统中,将主体与随机参与者配对。主体收到钱,而随机参与者没有收到钱。指示主体将其所有的钱或者一些钱派送给随机参与者,同时主体知道在钱到达其他人的时候钱将会增至三倍。该其他人继而能够不将该钱派送回主体,或者将该钱的一些或全部派送回主体。主体可继而基于随机参与者派送回的钱数量来评估随机参与者的公平性。与向随机参与者派送较少钱的那些主体相比,将派送较多钱的主体视为是更值得信任的。
系统对信任任务进行了信度测试。对于信任任务,利用社区样本(N=24)进行了分半信度研究。发现分半信度在约r=0.60处是合理的。在本科生的样本(N=40)中测量了测试-重测信度。发现关键信度在约r=0.59处是可接受的。
表1显示了在针对可由本发明的系统使用的说明性任务的在前实施例中所计算得到的信度测度的汇总。
实施例18:使用本发明的系统来对员工进行分类
公司A是有22名员工的咨询公司。公司将其这组中的四名员工辨识为表现最佳者,而其他18名员工则不被辨识为表现最佳者。系统能够使用来自员工在本文描述的、使用集成算法的神经科学测试上的表现的行为数据来将员工分类为表现最差者或表现最佳者。系统的算法将每个员工的一组行为数据转换为范围从0-100变化的适配分数。适配分数指示出了员工属于一个组或另一组的似然性。具有50%适配分数的个体可被等可能地分类为表现最差者或表现最佳者,而具有90%适配分数的员工可能极有可能是真正的表现最佳者,并且具有10%适配分数的员工可能极有可能是表现最差者。系统在使模型准确度最大化的同时执行二进制分类,并且调整决策边界以确保误报率和漏报率最小化。
系统构建了正确辨识了四个表现最佳者的模型。该模型还将两个表现最差者分类为表现最佳者,这意味着16名员工被正确地辨识为表现最差者。系统使用60%的决策边界来使误报率和漏报率二者最小化。表2显示了这一分析的结果并且指示出系统的分类如何与公司的分类相匹配。例如,系统将两名员工分类为表现最佳者,而实际上公司将那些员工分类为表现最差者。因此,使用22名个体的样本,系统构建了以91%的准确度对员工进行分类的模型。
实施例19:使用本发明的系统来确定潜在的工作表现。
在招聘工作期间,公司A有235份个人申请。申请人池包括从大型高校录取的本科生。所有申请人都由公司A的标准简历审核过程和系统的一套测试二者进行评估。该系统用于提升简历审核的效率并降低错失人才的似然性。
利用在实施例18中构建的预测模型,系统试图辨识最有可能接收工作邀请的申请人。为了了解系统的算法是否能够增加所发出邀请的收益率(yield),系统首先基于公司A的标准简历审核过程对公司A向其发出了邀请的候选人数目与被邀请面试的候选人数目进行比较。随后,系统基于该系统的算法结合公司A的标准简历审核过程来计算所发出的邀请与面试的类似比率(表3)。通过利用本文中的算法与公司A的标准简历审核过程相结合,该系统使所发出邀请的收益率从5.3%增加至22.5%。
公司A还使用了该系统来帮助减少错失申请人之中的人才。公司要求系统从被公司A的标准简历审核过程拒绝的141名申请人中推荐10名申请人。通过在系统推荐的10名候选人之中辨识出值得邀请的一名候选人,系统能够在评价公司拒绝的候选人时匹配并稍微超过公司的标准简历审核过程的收益率(表4)。
公司A还使用了该系统作为用于替代简历审核的服务。该系统的算法从235名申请人中辨识出28名值得面试的申请人。公司面试了那28名个人并向其中的五人发出邀请(表5)。因此,系统能够使被发出邀请的申请人的收益率从8.5%增加至17.9%。
系统可被用于三种不同的目的。系统可以通过增加邀请所发给的申请人的收益率来增加简历审核的效率。系统可以通过评估公司的简历审核过程原本未考虑的候选人来减少错失人才。最后,在公司没有预算来支持招聘团队的情况下,系统可以用于替代简历审核。
实施例20:使用本发明的系统来提供职业反馈。
公司B要求系统构建模型以使用来自员工在一套基于神经科学的测试上的表现的数据,从一个月内测量到的一组782名员工中将一系列销售职位的员工分类为表现最佳者。分析的目的是在必要时提供职业发展反馈和人员再配备的建议。
系统使用算法构建了模型以将每一员工职位内的员工分类为表现最佳者或最差员工。这些模型允许系统报告划定表现最佳者与表现最差者的特质。系统的特质辨识特征允许该系统通过定量地对个体员工的简档与针对公司职位的模范员工简档进行比较并继而报告该员工的优势以及需要改进的方面来提供职业发展建议。
关于在选定间隔的时间内参与的员工数的详细信息在表6中列举出并在图33中表示出。表7中详述了来自四个员工职位的每一个的表现最佳者的最终组大小。
模型准确度确定如下:正确的分类/总数N,其中N为组大小,并且员工的正确分类通过系统与公司之间的组分类的重叠来确定。
对于所检查的四个职位,基于训练数据的模型准确度结果都大于95%,如图34中所示。图34描绘了一组4个直方图,每个模型化的职位一个直方图,并且每个直方图在Y轴上显示了员工数,而在X轴上显示了适配分数。适配分数小于0.8的、处于深灰色的员工根据本发明的度量被准确地分类为非表现最佳者。适配分数大于或等于0.8的、以浅灰色描绘的员工被本发明准确地分类为表现最佳者。适配分数大于或等于0.8的、以深灰色描绘的员工被不准确地分类为表现最佳者(误报),而那些分数小于0.8的、以浅灰色描绘的员工被不准确地分类为非表现最佳者(漏报)。在[00115]节中描述且在表2中描绘了误报和漏报。公司B通过针对由系统构建的四个模型中的每一个的特质来接收简档分析。这些简档暗示出对于具体职位的模范员工的特质特点。
系统还为公司B的员工提供了职业发展反馈。系统具体而言为每名员工提供了使该员工理想地适合于其职位的前三个特质的列表以及该员工可以改进的前三个特质的列表。另外,系统提供了关于对于每个特质而言员工可以如何改进的建议。
系统在四个不同的销售职位上以大于95%的准确度将员工分类为表现最佳者或表现最差者。系统对于公司B处的人员再配备而言是可用的,这是因为公司B对利用来自系统的结果来帮助在部门之间调任员工(如果必要的话)感兴趣。此外,员工收到直接基于评估的职业发展反馈。系统的评估具体辨识出在公司某一职位成功员工的特质。系统继而向表现最差的员工给予关于该员工如何与模范员工进行比较的反馈以及表现最差的员工可以改进表现的方式。
实施例21:使用本发明的系统来增加临时员工的转化率。
公司C和公司D是从主要商学院大量招聘暑期实习生的咨询公司。在2012年和2013年,公司C聘用了57名MBA暑期实习生,而公司D聘用了106名学生暑期实习生。本发明的系统评估了公司在两个夏天的过程中面试的学生,并且确定与公司能够辨识出将会继续在咨询领域的学生相比,系统的算法是否能够更正确地辨识出那些学生。系统在不管所担任的职位的情况下根据在公司C和公司D工作的学生构建了文化适配模型。研究的目的是增加暑期实习生向全职员工的转化率。
在暑期实习生项目之后,公司C发出了八个邀请,并且那些人中的六人在完成学业后继续在咨询行业工作。公司D发出了16个邀请,并且那些人中的11人在学业结束后继续在咨询行业工作。系统为公司C和公司D二者构建了模型并且生成了适配分数来预测公司应当向谁发出邀请。系统建议公司C向11名学生发出邀请,其中有还10人继续在咨询行业工作。系统还建议公司D向10个人发出邀请,其中9人还继续在咨询行业工作(表8)。
实施例22:使用本发明的系统来增加申请人接受邀请的收益率。
公司C在2012年和2013年与57名暑期实习生一起工作。公司C向这些实习生中的13人发出了邀请。这13名实习生中的十人接受了公司C的邀请。公司C请求系统测试算法是否可以预测谁更有可能接受公司的邀请。使用先前在实施例21中为公司C构建的模型,系统对接受公司邀请的那些人的平均适配分数与拒绝公司邀请的那些人的适配分数进行比较。
接受公司C的全职邀请的十名暑期实习生的平均适配分数为69%。未接受公司C的邀请的三个人的平均适配分数为35%。因此,系统的适配分数可以追踪更有可能接受公司邀请的个人。对于公司C,接受公司C邀请的个人比那些拒绝公司C邀请的个人具有更高的文化适配分数。
实施例23:评估本发明的系统中的不利影响。
由本发明的系统创建的适配分数可以是作为系统的一部分的个人评估的分数的聚合。进行对适配分数的多变量统计分析以评价人口因素对分数的影响。为了调查年龄对系统分数的影响,分析来自人群(N=179)的两个年龄组,39岁和39岁以下以及40岁和40岁以上。使用霍特林T方检验来评估年龄组之间的任何统计上显著的差异。未观察到组中基于年龄的差异。通过将人群分为4个年龄组:a)29岁和29岁以下、b)30-34、c)35-39以及d)40岁或40岁以上,来进一步分析年龄的影响。采用多变量单向ANOVA测试,其还示出在年龄组间无差异(p>0.05)。使用相同的数据集和霍特林T方检验,女性与男性之间的变化在统计上不显著(p>0.05)。在多变量ANOVA测试中,在种族类别上未观察到显著差异(p>>0.1),所述种族类别包括亚裔、黑种人、西班牙裔、中东裔、美洲原住民、白种人、其他种族以及混合种族。
多变量统计分析展示出,年龄、性别和种族在统计上都不与适配分数显著相关。
系统可以通过针对基于年龄、种族或性别的结果的差异而测试每个个体测试中的偏差来检查测试的不利影响。在个人评估水平下检查了系统测试的结果。系统针对年龄组、性别组或种族组的差异检查了每个任务,以及包括在针对每个任务的一个与十个单独测度之间的分析。表9中给出了来自统计分析的显著结果。没有一个任务显示出种族的差异,并且任务的子集显示出基于年龄和性别的差异。对于多组之间显示出显著差异的那些任务,报告了那些差异的效应大小。效应大小的相关系数(r)0.1可被认为很小;0.3可被认为适中;而0.5可被认为很大。17个显著结果中的十六个落在从小到适中的范围中,并且来自伦敦塔任务的单一测度(每次正确移动的时间)实现了处于适中范围中的为0.32的r。
仿真气球冒险任务(BART)
BART的一个测度显示出性别之间的显著差异;具体而言,女人比男人更会规避风险。这种差异表示了由性别解释的观察到的方差的3%。
选择任务
对于选择任务,结果根据年龄和性别二者而不同。较年轻的参与者比年龄在40以上的参与者具有更高的百分比博弈分数。这种差异表示了2.6%的样本方差。根据性别检查百分比博弈展现出男人比女人具有更高的分数,并且这种差异表示了1.96%的样本方差。
独裁者任务
给予随机参与者钱的数量根据性别而不同,并且女人在任务中比男人给予得更多。这种差异表示了1.2%的样本方差。
EEfRT
在其之后选择更困难的任务的拐点更通常地根据性别而不同,并且男人比女人具有更高的分数。性别差异解释了1.96%的数据方差。
面部情绪测试
面部情绪测试的结果根据年龄而不同,因为年老参与者在根据面部表情辨别情绪方面比年轻参与者更准确。年龄差异解释了3.61%的数据方差。
手指敲击任务
手指敲击任务的反应时间根据年龄和性别二者而不同。年老参与者在反应时间测度上比年轻参与者更慢,并且女人比男人更慢。这些效果分别解释了4%和6.25%的数据方差。
Flanker任务
Flanker任务的一个测度示出了男人与女人之间的显著差异。男人在切换准确度上得分更高,并且这种差异解释了2.25%的数据方差。
未来贴现
在未来贴现任务中,系统辨别出因年龄和性别二者而造成的差异。年老参与者比年轻参与者更有可能等待未来的机会。这种效果解释了1.96%的数据方差。折现率还根据性别而不同在于,女人比男人更有可能等待未来的机会。
N-Back测试
在N-Back测试中的准确度的测度根据性别而不同。男人比女人具有更高的准确度分数,结果解释了2.89%的数据方差。
信任任务
系统辨识出因性别而造成的数量和公平性二者方面的差异。男人比女人给出更高的数量,效果解释了2.89%的数据方差。女人给出了更高的公平性评级,效果解释了2.25%的数据方差。
图案识别
在图案识别任务中,系统辨识出基于性别的显著差异。男人比女人具有更高的图案识别分数,效果解释了2.56%的数据方差。
伦敦塔
在伦敦塔任务中,系统辨识出年龄的显著效果。年老参与者对每次正确的移动比年轻参与者花费更多的时间,效果解释了10.24%的方差。
实施例24:适配分数检查。
系统针对存在于系统针对来自公司B的样本而生成的适配分数内的不利影响的证据来检查样本数据。表10报告了样本人口统计,包括按职位对样本进行细分。
对于每个职位,系统测试对总样本(N=464)的不利影响。来自公司B的4个职位中的514名员工完成了一套测试。由系统根据538名员工的总样本为每个职位构建了个体模型。系统具有关于538名员工中的464名的性别数据。在一个职位内或者跨不同职位在性别之间未发现适配分数的差异。
系统无法获取上文报告的、针对公司B的员工的人种数据。然而,系统使用上文生成的模型测试了来自内部数据库的样本以获得人种偏差。系统为来自内部数据库的962个人的样本生成了适配分数(表11)。人群包括本科生、MBA学生以及行业专家的混合。
针对表12中报告的样本,在人种之间未观察到适配分数的差异(表12)。
a:单向ANOVA。
实施例25:适配分数检查:行业适配模型。
系统还针对性别和人种偏差检查了系统的全部行业模型。系统为来自内部数据库的962个人的样本生成了适配分数(表11和表13)。人群包括本科生、MBA学生以及行业专家的混合。在系统认为是稳定的任何行业模型中,未观察到性别或人种的偏差。
可以提供任何工具、接口、引擎、应用、程序、服务、命令或其他可执行项目作为以计算机可执行代码编码在计算机可读介质上的模块。在一些实施方式中,本发明提供在其中编码有计算机可执行代码的计算机可读介质,该计算机可执行代码编码用于执行本文所述的任何行动的方法,其中该方法包括提供包括本文所述的任何数目的模块的系统,每个模块执行本文所述的任何功能以向用户提供结果,诸如输出。
实施例26:计算机架构。
各种计算机架构适合于与本发明一起使用。图35是图示了可与本发明的示例实施方式结合使用的计算机系统3500的第一示例架构的框图。如图35中所描绘,示例计算机系统可以包括用于处理指令的处理器3502。处理器的非限制性示例包括:Intel Core i7TM处理器、Intel Core i5TM处理器、Intel Core i3TM处理器、Intel XeonTM处理器、AMD OpteronTM处理器、三星32位RISC ARM 1176JZ(F)-S v1.0TM处理器、ARM Cortex-A8三星S5PC100TM处理器、ARM Cortex-A8苹果A4TM处理器、Marvell PXA 930TM处理器或功能等效处理器。可以使用多个执行线程以进行并行处理。在一些实施方式中,多个处理器或具有多个核的处理器可以在单一计算机系统中或者在集群中使用,或者通过网络跨各个系统分布,所述网络包括多个计算机、移动电话和/或个人数据助理设备。
数据采集、处理和存储。
如图35中所示,高速缓冲存储器3501可以连接至处理器3502或并入于其中以提供用于最近或频繁地由处理器3502使用的指令或数据的高速存储器。处理器3502通过处理器总线3505连接至北桥3506。北桥3506通过存储器总线3504连接至随机存取存储器(RAM)3503并且通过处理器3502来管理对RAM 3503的访问。北桥3506还通过芯片组总线3507连接至南桥3508。南桥3508转而连接至外围总线3509。外围总线例如可以为PCI、PCI-X、PCI Express或其他外围总线。北桥和南桥常常被称为处理器芯片组并且管理处理器、RAM以及外围总线3509上的外围组件之间的数据转移。在一些架构中,北桥的功能可以并入到处理器中,而不是使用单独的北桥芯片。
在一些实施方式中,系统3500可以包括附接至外围总线3509的加速器卡3512。加速器可以包括现场可编程门阵列(FPGA)或者用于加速某些处理的其他硬件。
(一个或多个)软件接口。
软件和数据储存在外部存储3513中并且可被加载到RAM 3503和/或高速缓冲存储器3501中以供处理器使用。系统3500包括用于管理系统资源的操作系统;操作系统的非限制性示例包括:Linux、WindowsTM、MACOSTM、BlackBerry OSTM、iOSTM和其他功能等效操作系统,以及运行在操作系统之上的应用软件。
在该示例中,系统3500还包括连接至外围总线的网络接口卡(NTC)3510和3511,用于向外部存储提供网络接口,所述外部存储诸如为网络附接存储(NAS)以及可用于分布式并行处理的其他计算机系统。
计算机系统。
图36是示出具有多个计算机系统3602a和3602b、多个移动电话和个人数据助理3602c以及网络附接存储(NAS)3601a和3601b的网络3600的示图。在一些实施方式中,系统3602a、3602b和3602c可以管理数据存储并且优化对储存于网络附接存储(NAS)3601a和3602b中的数据的数据存取。数学模型可用于该数据并且可使用跨计算机系统3602a和3602b以及移动电话和个人数据助理系统3602c的分布式并行处理来评价。计算机系统3602a和3602b以及移动电话和个人数据助理系统3602c还可以提供并行处理,以便对储存于网络附接存储(NAS)3601a和3601b中的数据进行自适应性数据重构。图36仅图示了示例,并且各种各样的其他计算机架构和系统可以与本发明的各个实施方式相结合地使用。例如,刀片服务器可用于提供并行处理。处理器刀片可以通过底板相连以提供并行处理。存储还可以连接至所述底板或者通过单独的网络接口而被连接为网络附接存储(NAS)。
在一些实施方式中,处理器可以保持单独的存储空间并且通过网络接口、底板或用于由其他处理器进行并行处理的其他连接器来传输数据。在一些实施方式中,一些或所有处理器可以使用共享的虚拟地址存储空间。
虚拟系统。
图37是使用共享的虚拟地址存储空间的多处理器计算机系统的框图。该系统包括可以访问共享的存储器子系统3702的多个处理器3701a-f。系统将多个可编程硬件存储器算法处理器(MAP)3703a-f并入存储器子系统3702中。每个MAP 3703a-f可以包括存储器3704a-f以及一个或多个现场可编程门阵列(FPGA)3705a-f。MAP提供了可配置的功能单元,并且可以向FPGA 3705a-f提供特定的算法或算法的一部分,以便与相应处理器密切配合地进行处理。在该示例中,出于这些目的,每个MAP在全球范围内可由所有处理器访问。在一种配置中,每个MAP可以使用直接存储器访问(DMA)来访问相关联的存储器3704a-f,从而允许其独立于相应微处理器3701a-f且与其异步地执行任务。在该配置中,MAP可以直接向另一MAP馈送结果,以供算法的流水线化和并行执行。
上文计算机架构和系统仅仅是示例,并且各种各样的其他计算机、移动电话以及个人数据助理架构和系统可以与示例实施方式相结合地使用,其包括使用通用处理器、协处理器、FPGA和其他可编程逻辑器件、芯片上系统(SOC)、专用集成电路(ASIC)以及其他处理元件和逻辑元件的任何组合的系统。任何种类的数据存储介质可以与示例实施方式相结合地使用,其包括随机存取存储器、硬盘驱动器、闪速存储器、磁带驱动器、磁盘阵列、网络附接存储(NAS)以及其他本地或分布式数据存储设备和系统。
在示例实施方式中,计算机系统可以使用在上文或其他计算机架构和系统中的任一个上执行的软件模块来实现。在其他实施方式中,系统的功能部分地或完全地实现在固件、诸如图37中所引用的现场可编程门阵列(FPGA)等可编程逻辑器件、芯片上系统(SOC)、专用集成电路(ASIC)或其他处理元件和逻辑元件中。例如,固定(set)处理器和优化器可以利用通过使用诸如图35中所图示的加速器卡3512等硬件加速器卡的硬件加速来实现。
本文所描述的本发明的任何实施方式例如可由同一地理位置内的用户产生和传输。本发明的产品例如可从一个国家中的某一地理位置产生和/或传输,并且本发明的用户可以存在于不同的国家中。在一些实施方式中,由本发明的系统访问的数据是可从多个地理位置3801中的一个传输给用户3802的计算机程序产品(图8)。由本发明的计算机程序产品生成的数据例如可通过网络、安全网络、不安全的网络、因特网或内联网在多个地理位置间来回传输。在一些实施方式中,由本发明提供的本体论层次结构被编码在物理且有形的产品上。
图39图示了根据一些实施方式的用于生成员工统计模型的示例性方法的流程图。参考图39,方法3900可以包括以下步骤中的一个或多个。应当注意,本发明不限于此,并且可以添加附加步骤。或者,可以省略一个或多个步骤。
首先,可以将交互式媒体提供给与多个参与者相关联的多个计算设备(3902)。交互式媒体可以由例如图1中描述的筛选系统110和/或服务器104提供。交互式媒体可以存储在一个或多个数据库108中。多个计算设备可以对应于图1中所示的用户设备102。交互式媒体可以包括用一组选定的基于神经科学的任务创建的至少一个招聘游戏,该一组选定的基于神经科学的任务被设计用于测量参与者的多种情绪和认知特质。招聘游戏可以包括与该组选定的基于神经科学的任务相关联的一组预定义的视觉对象,如本说明书中他处所述。该组预定义的视觉对象可以呈现在计算设备的图形显示器上。
随后,当参与者在计算设备的图形显示器上玩招聘游戏时,可以从计算设备接收输入数据(3904)。输入数据可以由例如筛选系统110接收。在一些情况下,输入数据可以由图2中所示的特质提取引擎112接收。在一些情况下,输入数据还可以存储在一个或多个数据库108中。参与者可以通过与该组预定义的视觉对象交互来玩招聘游戏以完成该组选定的基于神经科学的任务,如本说明书中他处所述。
随后,可以分析来源于参与者与招聘游戏内的该组预定义的视觉对象的交互的输入数据(3906)。可以使用例如筛选系统110分析输入数据。例如,特质提取引擎112可以提取对参与者的情绪和认知特质的测量。模型分析引擎114可以基于对参与者的情绪和认知特质的测量来生成统计模型。统计模型可以代表选定组的参与者。在一些情况下,该选定组的参与者可以对应于公司的一组最佳员工。然后,筛选系统110可以通过将参与者的情绪和认知特质的测量与统计模型进行比较来分类每个参与者是在组内还是组外。
随后,分析的输入数据可以在图形显示器上可视化地显示为多个密度函数图(3908)。多个密度函数图可以包括对应于被分类为组外的参与者的第一密度函数图和对应于被分类为组内的参与者的第二密度函数图。决策边界被定义在第一密度函数图与第二密度函数图之间的重叠区域中,例如如图17A中所示。
图40图示了根据一些实施方式的用于将候选人与图39的员工统计模型进行比较的示例性方法的流程图。参考图40,方法4000可以包括以下步骤中的一个或多个。应当注意,本发明不限于此,并且可以添加附加步骤。或者,可以省略一个或多个步骤。
如图40中所示,可以将对候选人的情绪和认知特质的测量与统计模型进行比较,并且可以基于该比较为候选人生成分数(4002)。可以测量候选人的情绪和认知特质以确定候选人的特质是否与公司的组内员工的特质匹配。然后,可以在图形显示器上的多个密度函数图上显示指示分数的点(4004)。在一些实施方式中,可以将多个候选人与统计模型进行比较,并且因此可以生成多个点。能够以密度函数图的形式提供该多个点,例如由图17B中所示的1720和1722表示。随后,候选人可以被分类为:(1)当点位于相对于决策边界的第一区域时的组内,或(2)当点位于相对于决策边界的第二区域时的组外(4006)。例如,参考图17B,当候选人的点位于决策边界左侧时,候选人可以被分类为组外。相反,当候选人的点位于决策边界右侧时,候选人可以被分类为组内。因此,终端用户(例如,招聘人员或人力资源人员)可以查看与不同候选人相关联的点,并确定每个候选人与组内员工还是组外员工匹配更密切。通过查看候选人的点相对于决策边界所处的位置,可以快速(一眼)执行该确定。另外,对于落在每个组(组内或组外)中的候选人,终端用户可以看到每个候选人的点相对于决策边界所处的位置。例如,如果候选人的点位于决策边界的最右侧,与仅位于决策边界略微右侧的另一候选人的点相比,可以确定该候选人非常密切地匹配于组内员工。
实施方式
以下非限制性实施方式提供了对本发明的说明性示例,但不限制本发明的范围。
实施方式1.一种包括具有编码于其中的计算机可执行代码的计算机可读介质的计算机程序产品,所述计算机可执行代码适于被执行用于实现包括以下各项的方法:a)提供招聘系统,其中所述招聘系统包括:i)任务模块;ii)测量模块;iii)评估模块;以及iv)辨识模块;b)由所述任务模块向主体提供计算机化任务;c)由所述测量模块测量所述主体在所述任务的执行中所展示出的表现值;d)由所述评估模块基于所测量的表现值来评估所述主体的特质;以及e)由所述辨识模块基于所评估的特质来为雇用官辨识所述主体适合于被实体雇用。
实施方式2.如实施方式1所述的计算机程序产品,其中所述招聘系统还包括简档模块,其中所述方法还包括由所述简档模块基于对所述主体的特质的评估为所述主体创建简档。
实施方式3.如实施方式1-2中任一项所述的计算机程序产品,其中所述招聘系统还包括模型模块、参考模型和比较模块,并且其中所述方法还包括由所述模型模块基于对所述主体的不止一个特质的评估生成所述主体的模型,其中所述方法还包括由所述比较模块对所述主体的模型与所述参考模型进行比较。
实施方式4.如实施方式1-2中任一项所述的计算机程序产品,其中所述招聘系统还包括模型模块和比较模块,并且其中所述方法还包括由所述模型模块基于对所述主体的不止一个特质的评估来生成所述主体的模型,其中所述方法还包括由所述比较模块对所述主体的模型与测试主体的数据库进行比较。
实施方式5.如实施方式4所述的计算机程序产品,其中所述测试主体为所述实体工作。
实施方式6.如实施方式1-5中任一项所述的计算机程序产品,其中所述雇用官为所述实体工作。
实施方式7.如实施方式4所述的计算机程序产品,其中所述招聘系统还包括聚合模块,其中所述方法还包括由所述聚合模块收集来自所述主体的数据并且将来自所述主体的数据聚合到所述测试主体的所述数据库中。
实施方式8.如实施方式3所述的计算机程序产品,其中所述招聘系统还包括评分模块,其中所述方法还包括由所述评分模块基于所述主体的所述模型与所述参考模型的比较来对所述主体进行评分。
实施方式9.如实施方式4所述的计算机程序产品,其中所述招聘系统还包括评分模块,其中所述方法还包括由所述评分模块基于所述主体的所述模型与测试主体的数据库的比较来对所述主体进行评分。
实施方式10.一种包括具有编码于其中的计算机可执行代码的计算机可读介质的计算机程序产品,所述计算机可执行代码适于被执行用于实现包括以下各项的方法:a)提供人才辨识系统,其中所述人才辨识系统包括:i)任务模块;ii)测量模块;iii)评估模块;iv)辨识模块;以及v)输出模块;b)由所述任务模块向主体提供计算机化任务;c)由所述测量模块测量所述主体在任务的执行中所展示出的表现值;d)由所述评估模块基于所测量的表现值来评估所述主体的特质;e)由所述辨识模块基于对主体的所述特质的评估来辨识职业倾向;以及f)由所述输出模块向雇用官输出所辨识的职业倾向。
实施方式11.如实施方式10所述的计算机程序产品,其中所述人才辨识系统还包括推荐模块,其中所述方法还包括由所述推荐模块基于所述主体的职业倾向来推荐职业。
实施方式12.如实施方式10-11中任一项所述的计算机程序产品,其中所述人才辨识系统还包括模型模块、参考模型和比较模块,并且其中所述方法还包括由所述模型模块基于对所述主体的不止一个特质的评估来生成所述主体的模型,其中所述方法还包括由所述比较模块对所述主体的模型与所述参考模型进行比较。
实施方式13.如实施方式10-11中任一项所述的计算机程序产品,其中所述人才辨识系统还包括模型模块和比较模块,并且其中所述方法还包括由所述模型模块基于对所述主体的不止一个特质的评估来生成所述主体的模型,其中所述方法还包括由所述比较模块对所述主体的模型与测试主体的数据库进行比较。
实施方式14.一种方法,包括:a)向主体提供计算机化任务;b)测量所述主体在所述任务的执行中所展示出的表现值;c)基于所述表现值来评估所述主体的特质;d)由计算机系统的处理器对所述主体的所述特质与测试主体的数据库进行比较;e)基于所述比较来确定所述主体适合于被实体雇用;以及f)向所述实体处的雇用官报告所述主体适合于雇用。
实施方式15.如实施方式14所述的方法,还包括基于对所述主体的所述特质的评估为所述主体创建简档。
实施方式16.如实施方式14-15中任一项所述的方法,还包括基于所述主体的不止一个特质与测试主体的数据库的比较来生成所述主体的模型。
实施方式17.如实施方式16所述的方法,还包括基于所述主体的所述模型来对所述主体进行评分。
实施方式18.如实施方式14-17中任一项所述的方法,其中所评估的特质是认知特质。
实施方式19.如实施方式14-18中任一项所述的方法,其中所评估的特质是情绪特质。
实施方式20.如实施方式14-19中任一项所述的方法,其中所述测试主体为所述实体工作。
实施方式21.如实施方式14-20中任一项所述的方法,其中所述计算机化任务具有由测试-重测评估所确定的可接受水平的信度。
实施方式22.如实施方式14-21中任一项所述的方法,其中所述计算机化任务具有由分半信度评估所确定的可接受水平的信度。
实施方式23.一种方法,包括:a)向主体提供计算机化任务;b)测量所述主体在所述任务的执行中所展示出的表现值;c)基于所述表现值来评估所述主体的特质;d)由计算机系统的处理器基于所评估的所述主体的特质与测试主体的数据库的比较来辨识所述主体的职业倾向;以及e)向雇用官输出所述比较的结果。
实施方式24.如实施方式23所述的方法,还包括基于对所述主体的所述特质的评估来为所述主体创建简档。
实施方式25.如实施方式23-24中任一项所述的方法,还包括基于对所述主体的不止一个特质与测试主体的数据库进行比较来为所述主体生成模型。
实施方式26.如实施方式23-25中任一项所述的方法,还包括基于所述主体的职业倾向来向所述主体推荐职业。
实施方式27.如实施方式23-26中任一项所述的方法,其中所述计算机化任务具有由测试-重测评估所确定的可接受水平的信度。
实施方式28.如实施方式23-27中任一项所述的方法,其中所述计算机化任务具有由分半信度评估所确定的可接受水平的信度。
实施方式29.如实施方式23-28中任一项所述的方法,其中所评估的特质是认知特质。
实施方式30.如实施方式23-29中任一项所述的方法,其中所评估的特质是情绪特质。
本公开内容通过引用并入于2015年6月26日提交的题为“Systems and Methods for Data-Driven Identification of Talent”的美国专利申请号14/751,943。
尽管本文中已经显示并描述了本公开内容的优选实施方式,但对于本领域技术人员显而易见的是,这些实施方式仅以示例的方式提供。本领域技术人员在不脱离本公开内容的情况下现将想到多种变化、改变和替代。应当理解,在实施本公开内容的过程中可以采用本文描述的本公开内容实施方式的各种替代方案。以下权利要求旨在限定本公开内容的范围,并由此涵盖这些权利要求范围内的方法和结构及其等同项。
- 还没有人留言评论。精彩留言会获得点赞!