基于使用概率的数据检索推荐方法与流程
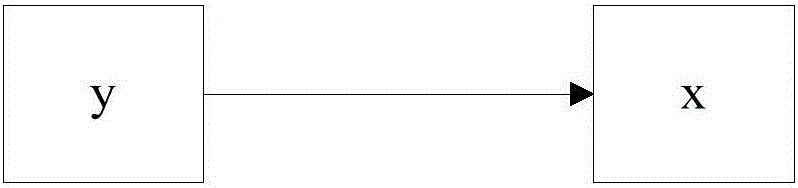
本发明属于数据分析技术领域,尤其涉及一种基于使用概率的数据检索推荐方法。
背景技术:
随着科技互联网快速的发展,人们对数据信息的需求越来越强烈,怎么样才能获取到自身想要的数据信息成为客户和系统产品开发企业最关心的问题。在数据化信息的今天,数据个性化检索推荐显得尤为重要,协同数据过滤技术(collaborative filtering)目前被成功的运用于个性化推荐系统中,在数据信息定点检索推送领域占有相当地位,但随着系统数据规模不断的扩大,人们对信息需求更加的理性,需要分析的维度也成几何倍数的增加,它的效能逐渐降低。
技术实现要素:
本发明的发明目的是:为了解决现有技术中协同数据过滤技术存在的数据稀疏性、扩展局限性等问题,本发明提出了一种完善并解决应用协同过滤技术在数据检索推荐上存在数据稀疏性和扩展局限性的基于使用概率的数据检索推荐方法。
本发明的技术方案是:一种基于使用概率的数据检索推荐方法,包括:
A、将包含用户需求的数据信息进行划分,构建多个数据信息集合;
B、根据步骤A中的数据信息集合构建数据集合数组;
C、设定检索推荐数据信息,分析该检索推荐数据信息所属的数据信息集合,计算一个数据信息集合中产生该检索推荐数据信息的概率;
D、根据步骤C中检索推荐数据信息在一个数据信息集合产生的概率,计算步骤C中检索推荐数据信息在所属的数据信息集合中的分布概率;
E、根据步骤D中检索推荐数据信息所属的数据信息集合的分布概率,计算检索推荐数据信息的出现概率;
F、根据步骤E中检索推荐数据信息的出现概率得到检索推荐数据信息的被检索推荐概率,完成数据检索推荐。
进一步地,所述步骤A中构建的数据信息集合具体表示为:
xn=(data1,data2,data3...)
其中,xn为数据信息集合,n为数据信息集合个数,data1,data2,data3为数据信息。
进一步地,所述步骤B中构建的数据集合数组具体表示为:
array[]=[x1,x2,x3...xn]
其中,array[]为数据集合数组。
进一步地,所述步骤D中检索推荐数据信息在所属的数据信息集合中的分布概率包括单数据分布和联合概率分布。
进一步地,所述单数据分布下检索推荐数据信息在所属的数据信息集合中的分布概率p(y|xn)为检索推荐数据信息y在所属的数据信息集合xn中的数据总量除以所有数据信息集合中的数据总量。
进一步地,所述联合概率分布下检索推荐数据信息在所属的数据信息集合中的分布概率的计算公式具体为
其中,p((y1,y2,y3...ym)/xn)为联合概率分布下检索推荐数据信息在所属的数据信息集合中的分布概率。
进一步地,所述步骤E中检索推荐数据信息的出现概率的计算公式具体为:
probabolity=p(y|xn)*p(xn)
其中,probabolity为检索推荐数据信息的出现概率,p(xn)为检索推荐数据信息y在数据信息集合xn中产生的概率。
进一步地,所述步骤步骤F中检索推荐数据信息的被检索推荐概率的计算公式具体为:
其中,p(xn|y)为检索推荐数据信息的被检索推荐概率,p(y)为一个数据信息集合中产生检索推荐数据信息的概率。
本发明的有益效果是:本发明的基于使用概率的数据检索推荐方法针对协同数据过滤技术数据稀疏性、扩展局限性等缺陷,更高效的通过数据整理分析,从给定的限制条件分析未知的概率分布,在提高精确性的基础上减少了很多计算上的耗费,从而较好的完善并解决了应用协同过滤技术在数据检索推荐上存在的数据稀疏性、扩展局限性等方面的问题,使得用户可以快速精确的获取到个性化的推荐信息。
附图说明
图1是本发明的基于使用概率的数据检索推荐方法流程示意图。
图2是本发明实施例中检索推荐数据信息为单数据分布示意图。
图3是本发明实施例中检索推荐数据信息为联合概率分布示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,为本发明的基于使用概率的数据检索推荐方法流程示意图。一种基于使用概率的数据检索推荐方法,包括:
A、将包含用户需求的数据信息进行划分,构建多个数据信息集合;
B、根据步骤A中的数据信息集合构建数据集合数组;
C、设定检索推荐数据信息,分析该检索推荐数据信息所属的数据信息集合,计算一个数据信息集合中产生该检索推荐数据信息的概率;
D、根据步骤C中检索推荐数据信息在一个数据信息集合产生的概率,计算步骤C中检索推荐数据信息在所属的数据信息集合中的分布概率;
E、根据步骤D中检索推荐数据信息所属的数据信息集合的分布概率,计算检索推荐数据信息的出现概率;
F、根据步骤E中检索推荐数据信息的出现概率得到检索推荐数据信息的被检索推荐概率,完成数据检索推荐。
在步骤A中,本发明将包含用户需求的数据信息划分为若干组,并分别构建多个数据信息集合,这里的构建的数据信息集合具体表示为:
xn=(data1,data2,data3...)
其中,xn为数据信息集合,n为数据信息集合个数,data1,data2,data3为数据信息。每一个数据信息集合中的数据信息数量不一定相同。
在步骤B中,本发明根据步骤A中的数据信息集合构建数据集合数组,这里的构建的数据集合数组具体表示为:
array[]=[x1,x2,x3...xn]
其中,array[]为数据集合数组。
在步骤C中,本发明设定一个检索推荐数据信息y,分析该检索推荐数据信息y所属的数据信息集合,并计算某一个数据信息集合中产生该检索推荐数据信息的概率。
在步骤D中,本发明根据步骤C中检索推荐数据信息y在一个数据信息集合产生的概率,计算步骤C中检索推荐数据信息y在其所属的数据信息集合中的分布概率,这里的检索推荐数据信息在所属的数据信息集合中的分布概率包括单数据分布和联合概率分布。
如图2所示,为本发明实施例中检索推荐数据信息为单数据分布示意图。当检索推荐数据信息y在数据集合数组中为单数据分布时,即检索推荐数据信息y只存在于一个数据信息集合中,则检索推荐数据信息在所属的数据信息集合中的分布概率p(y|xn)为检索推荐数据信息y在所属的数据信息集合xn中的数据总量除以所有数据信息集合中的数据总量。
如图3所示,为本发明实施例中检索推荐数据信息为联合概率分布示意图。当检索推荐数据信息y在数据集合数组中为联合概率分布时,即检索推荐数据信息y存在于多个数据信息集合中,则检索推荐数据信息在所属的数据信息集合中的分布概率的计算公式具体为
其中,p((y1,y2,y3...ym)/xn)为联合概率分布下检索推荐数据信息在所属的数据信息集合中的分布概率。
在步骤E中,本发明根据步骤D中检索推荐数据信息y所属的数据信息集合的分布概率,计算检索推荐数据信息的出现概率。由于不同的数据集合xn都可能包含检索推荐数据信息y,但检索推荐数据信息y在每一个数据信息集合中出现的概率是不一样的,因此得到检索推荐数据信息的出现概率的计算公式具体为:
probabolity=p(y|xn)*p(xn)
其中,probabolity为检索推荐数据信息的出现概率,p(xn)为检索推荐数据信息y在数据信息集合xn中产生的概率。
在步骤F中,本发明根据步骤E中检索推荐数据信息的出现概率得到检索推荐数据信息的被检索推荐概率;根据步骤C中设定的一个检索推荐数据信息y可以直接得到一个数据信息集合中产生检索推荐数据信息的概率p(y),这里的一个数据信息集合中产生检索推荐数据信息的概率p(y)为恒定的值,从而得到检索推荐数据信息的被检索推荐概率的计算公式具体为:
其中,p(xn|y)为检索推荐数据信息的被检索推荐概率,p(y)为一个数据信息集合中产生检索推荐数据信息的概率,根据检索推荐数据信息的被检索推荐概率完成数据检索推荐。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!