一种基于关键词的主题网络爬虫设计方法与流程
本发明涉及网络信息处理
技术领域:
,尤其涉及一种基于关键词的主题网络爬虫设计方法。
背景技术:
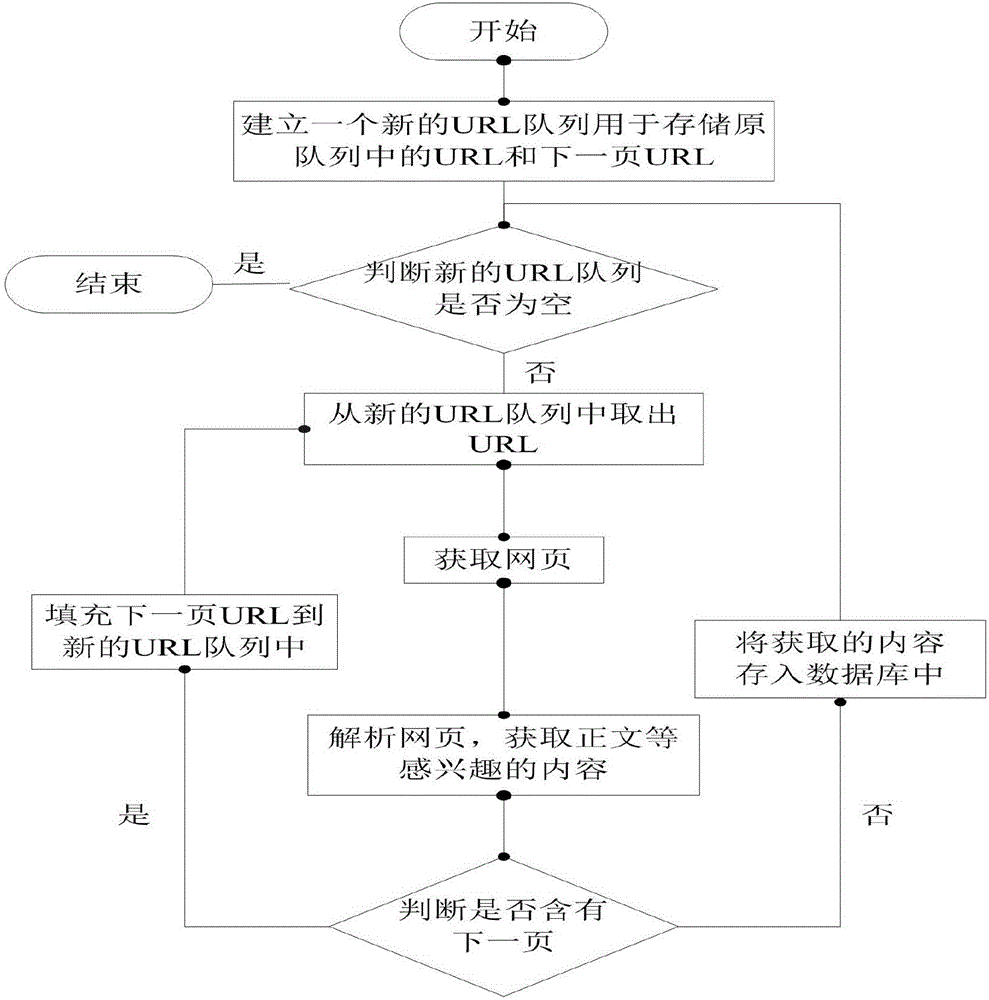
:随着互联网的发展,给人们带来丰富的信息资源的同时也给传统的搜索引擎带来了威胁,资源的覆盖率,搜索结果的准确性和相关性均有所下降,用户的搜索难度日益增大。因此,主题爬虫型搜索引擎应运而生,近几年得到了快速的发展。网络爬虫是一种自动抓取网页并提取网页内容的程序,其目的是从互联网中获取信息资源。网络爬虫主要分为两大类:通用爬虫和主题爬虫。通用网络爬虫是一般的网络爬虫,它是根据初始URL种子集采取一定的爬取策略,如广度优先策略或深度优先策略进行网页爬取的过程。通用网络爬虫的URL种子集可以是任意的门户网站,不加过滤的收集全部网页。主题爬虫是按照预先定义的爬取主题,在给定初始URL种子集合后,根据一定的分析算法,对待爬取网页进行主题相关分析,过滤与主题不相关的网页,将与主题相关的链接放入待爬取队列中,重复这个过程,直到满足一定条件为止。主题爬虫的URL种子集则必须是事先定义的与主题高度相关的页面,它只关注与主题相关的网页链接,在爬行过程中尽可能多地发现与主题相关的网页,减少无关网页的下载。在爬虫系统中,待爬取URL队列是最重要的一部分。待爬取URL队列以什么样的顺序排列,然后进行抓取是一个很重要的问题。而决定这些URL排列顺序的方法,叫做抓取策略。常见的抓取策略有深度优先遍历策略、广度优先遍历策略、反向链接数策略、PartialPageRank策略、OPIC策略、大战优先策略。主题爬虫需要对抓取的页面进行主题相关性分析,过滤相关性弱的网页,只保留主题相关性强的网页,主题相关性算法主要归纳为三种:基于文字内容的启发式方法、基于Web超链接图评价的方法和基于分类器预测的方法。基于文字内容的启发方法主要利用了Web网页文本内容、URL字符串、锚文字等文字内容信息,算法主要包括:Bestfirstsearch方法、Fishsearch方法以及Sharksearch方法。基于Web超链接图评价的方法的基本思想来自于文献计量学的引文分析理论,算法主要包括:BackLink方法、PageRank方法。而基于分类器预测的方法可以基于分类模型来描述用户感兴趣的主题和预测网页的主题相关度。通过以上研究分析发现,目前已经有很多关于主题爬虫的研究,但是如何合理地利用海量的资源信息,如何提高爬取网页的主题相关度,过滤掉相关度弱的网页还有待进一步研究。技术实现要素:发明的目的在于解决上述现有技术存在的缺陷,提供一种高效快速的爬取特定主题网络资源的主题网络爬虫的设计方法。为实现上述发明目的,本发明基于关键词的主题网络爬虫的设计方法,包括:一种基于关键词的主题网络爬虫设计方法,包括以下步骤:(1)配置主题关键词的搜索URL,形成初始种子超链接originalURL,其形式为“搜索引擎域名+主题关键词+搜索结果起始页”;(2)根据originalURL,在搜索引擎中进行检索并下载网页,根据网页内容获取初步字段,所述初步字段包括:标题、概要、URL和下一页超链接nextPageURL;其中,标题、概要和URL为抓取关键词;(3)根据主题相关性算法,利用所述标题和概要,进行主题相关性计算,得到每篇新闻与主题的相似性,将与主题相关的新闻字段(URL、标题、概要等)保留下来放入公共队列newsQueue中,过滤掉与主题不相关的新闻;(4)根据nextPageURL下载下一页的网页内容,抽取出步骤(2)所述的抓取关键词以及nextPageURL,将与主题相关的抓取关键词放入公共队列newsQueue中,不断重复步骤(4),直到没有下一页超链接(提取出的nextPageURL字段为空)为止;(5)从newsQueue中取出URL交给爬虫处理线程,即消费者线程;所述主题相关性算法包括以下步骤:(I)选取主题词集,获取训练集选定主题关键词,在搜索引擎中搜索得到相应关键词的Web文件和文本文件,作为word2vector的训练集;(II)利用word2vector工具将主题关键词转换为向量用word2vector工具对上一步得到的训练集进行训练,训练后,得到一个vectors.bin的二进制文件,利用该文件,将主题关键词转换为向量,得到向量集其中表示主题词j的向量,一共有n个主题词,得到n个主题向量;(III)选取m个待处理Web文档的特征词,并获取其特征向量采用分词方法对文档进行分词,并计算每个词的词频,在每个词的词频上相应乘以一个权重,即可得到每个词的最终权重w,最后,选取权重w排名前m位的词作为特征词,通过vectors.bin文件,将这m个特征词转换为向量,得到向量集其中表示特征词i的向量;(IV)计算向量集s和向量集d的相似性将d中向量与s中每个向量求余相似性得到其中,表示d中第i个向量的第k个维度上的数值,k从1取到向量的维数。同理表示s中第j个向量的第k维上的数值,k从1取到向量的维数。取余弦相似性最大值即为该向量与主题词的相似性,这样计算完d中每个向量与s中每个向量的相似性以后得到一个m维向量,将每一维值相加,并进行归一化(除以m)后得到待处理文档最终的主题相似性sim(s,d)(VI)设定阈值,URL入库设定一个阈值K,如果sim(s,d)>K,则将URL标题、摘要存入URL库,Web文本存入原始网页库,以便后期分析处理。进一步地,在上述步骤(1)之前还包括以下步骤:(1)配置领域本体的描述信息并作为主题爬虫的模板,所述描述信息包括:主题关键词、抓取关键词;其中,主题关键词是指根据主题确定的关键词并且需要提交给搜索引擎进行资源检索的关键词;抓取关键词是指最终要爬取的有效信息所对应的关键词;(2)确定主题关键词集合。进一步地,确定主题关键词集合的方法包括以下步骤:(I)人工挑选主题关键词,即在搜索引擎中检索有关主题的内容,在内容中抽取与主题相关的关键词,存储在数据库表中;(II)把(I)中人工挑选出的关键词作为搜索关键词在搜索引擎中进行检索,检索出的内容存储在文本文件中;(III)对该文本文件进行分词和采用TF-IDF算法进行词频排序后,取排名靠前的关键词作为主题关键词存储数据库中。TF-IDF算法具体如下:对文本文件进行分词,并计算每个词的词频,在每个词的词频上相应乘以一个权重,这个权重根据这个词的标签的重要性来定,如果这个词出现在标题中,那么它的权重就设定高一点,如果这个词出现在内容中,权重就低一点,计算每个词的词频和权重的乘积得到每个词的最终权重,根据最终权重值的大小,选择权重高的前若干个关键词作为主题关键词即可,关键词最终权重wf计算公式如下:其中,i表示不同的标签,wi表示不同标签下关键词的权重系数,fi表示关键词在该文本文件中该标签下出现的次数;(IV)再重新把数据库表中的关键词作为搜索关键词在搜索引擎中进行搜索,重复这样的检索和词频排序动作,以不断地添加新的关键词存入数据库表中,最后数据库表中的所有关键词即为主题关键词。进一步地,步骤(5)所述从newsQueue中取出URL交给爬虫处理线程,即消费者线程具体包括以下步骤:下载URL对应网页,解析出正文和步骤(2)中获得的对应新闻的抓取关键词形成新闻的完整信息保存到数据库中,不断重复,直到待抓取newsQueue队列库中没有可以取出的URL为止。有益效果:本发明提供的基于关键词的主题网络爬虫设计方法,通过搜索引擎全网爬取与主题相关的内容,而非针对特定网站,大大提高了爬取的广泛性,增加了URL资源的数量;针对爬取结果与主题相关性弱的问题,通过主题词集与网页内容的相似性算法对爬行网页进行主题相关分析,过滤与主题不相关的URL,保留与主题相关的URL,在爬行过程中尽可能多地发现与主题相关的网页,减少无关网页的下载。这样,大大提高了主题网络爬虫的爬取效率,增强了爬取出的URL资源的有效性。附图说明图1是本发明基于关键词的主题网络爬虫设计方法的生产者线程的具体实施流程图;图2是本发明基于关键词的主题网络爬虫设计方法的消费者线程的具体实施流程图;图3是本发明基于关键词的主题网络爬虫设计方法的生产者消费者模型图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明提供一种基于关键词的主题网络爬虫设计方法,包括以下步骤:(1)配置主题关键词的搜索URL,形成初始种子超链接originalURL,其形式为“搜索引擎域名+主题关键词+搜索结果起始页”;(2)根据originalURL,在搜索引擎中进行检索并下载网页,根据网页内容获取初步字段,所述初步字段包括:标题、概要、URL和下一页超链接nextPageURL;其中,标题、概要和URL为抓取关键词;(3)根据主题相关性算法,利用所述标题和概要,进行主题相关性计算,得到每篇新闻与主题的相似性,将与主题相关的新闻字段(URL、标题、概要等)保留下来放入公共队列newsQueue中,过滤掉与主题不相关的新闻;(4)根据nextPageURL下载下一页的网页内容,抽取出步骤(2)所述的抓取关键词以及nextPageURL,将与主题相关的抓取关键词放入公共队列newsQueue中,不断重复步骤(4),直到没有下一页超链接(提取出的nextPageURL字段为空)为止;(5)从newsQueue中取出URL交给爬虫处理线程,即消费者线程;所述主题相关性算法包括以下步骤:(I)选取主题词集,获取训练集选定主题关键词,在搜索引擎中搜索得到相应关键词的Web文件和文本文件,作为word2vector的训练集;(II)利用word2vector工具将主题关键词转换为向量用word2vector工具对上一步得到的训练集进行训练,训练后,得到一个vectors.bin的二进制文件,利用该文件,将主题关键词转换为向量,得到向量集其中表示主题词j的向量,一共有n个主题词,得到n个主题向量;(III)选取m个待处理Web文档的特征词,并获取其特征向量采用分词方法对文档进行分词,并计算每个词的词频,在每个词的词频上相应乘以一个权重,即可得到每个词的最终权重w,最后,选取权重w排名前m位的词作为特征词,通过vectors.bin文件,将这m个特征词转换为向量,得到向量集其中表示特征词i的向量;(IV)计算向量集s和向量集d的相似性将d中向量与s中每个向量求余相似性得到其中,表示d中第i个向量的第k个维度上的数值,k从1取到向量的维数。同理表示s中第j个向量的第k维上的数值,k从1取到向量的维数。取余弦相似性最大值即为该向量与主题词的相似性,这样计算完d中每个向量与s中每个向量的相似性以后得到一个m维向量,将每一维值相加,并进行归一化(除以m)后得到待处理文档最终的主题相似性sim(s,d)(VI)设定阈值,URL入库设定一个阈值K,如果sim(s,d)>K,则将URL标题、摘要存入URL库,Web文本存入原始网页库,以便后期分析处理。本发明基于关键词的主题网络爬虫的设计方法,通过主题关键词在搜索引擎中全网爬取网页,计算主题词集与网页内容的相似性对爬行网页进行主题相关分析,过滤与主题不相关的URL,将与主题相关的URL放入待爬取队列中。在爬行过程中尽可能多地发现与主题相关的网页,减少无关网页的下载。这样,大大提高了主题爬虫的爬取效率,增强爬取出的URL的有效性。对于主题爬虫性能的评价,重复率、覆盖率和准确率是常用的判断指标。覆盖率和准确率可以定量化的判断主题爬虫的过滤能力,保留有效内容的能力。重复率是指一定量的文章中内容相同的文章数目占总文章数百分比;覆盖率是抓取的主题相关网页数量与Web中主题相关网页数量的百分比;准确率是指抓取到的主题相关网页的数量与所有抓取网页数量的百分比。由于很难估计Web中主题相关网页数量,所以使用重复率和准确率作为评估指标。显然,重复率越高,爬虫爬取网页效果越差,准确率越高表示爬虫将更多的时间花在了抓取主题相关页面上,忽略了那些与主题无关的网页,说明其抓取主题能力越强。下面是具体的实验结果:(1)文章去重结果表1:主题爬虫的去重结果文章数(篇)重复数(篇)重复率1000636.3%50003747.48%100008488.48%(2)通过对种子URL的分析和计算主题相关性对种子URL进行过滤,得到与主题相关的URL的过程,分析得到过滤策略的准确率:表2:主题爬虫的准确率结果通过上述表1和表2的实验结果,我们可以看出,在去重效果上,文章的重复率基本维持在10%以内,重复率较低,说明本文提出的主题爬虫方法性能较好。而准确率能达到75%,说明爬虫花费了更多的时间在抓取主题相关页面上,说明本发明提出的主题相关性算法有较好的效果,提高了与主题相关网页的爬取效率。另外,在涉及主题相关性计算时,本发明只将文章的标题和摘要纳入了主题相关性计算的范围,相比于将全文进行主题相关性计算的方法,本发明提出的方法在计算主题相关性方面,用时更短,能够更快速地爬取网页。优选地,在上述步骤(1)之前,还包括以下步骤:(1)配置领域本体的描述信息并作为主题爬虫的模板,所述描述信息包括:主题关键词、抓取关键词;其中,主题关键词是指根据主题确定的关键词并且需要提交给搜索引擎进行资源检索的关键词;抓取关键词是指最终要爬取的有效信息所对应的关键词;(2)确定主题关键词集合。本步骤是基于关键词的主题网络爬虫设计方法的关键一步——怎样确定主题关键词集合。本步骤用关键词集合来描述我们的主题,关键词集合的准确度直接决定主题的准确度,我们必须要挑选出与主题关联性最强的一些词语,如在“食品安全”这个主题下,我们可以找到以下与主题相关的词语,如“食品添加剂”,“食品检测”,“食品原料”等等。因此,本发明选择了人工加自动提取主题的方法,首先人工地挑选出与主题相关的词语,然后通过这些词语在搜索引擎中搜索内容,根据内容中词语的排名,自动地确定其他关键词,最终形成我们的主题关键词集合。优选地,步骤(2)确定主题关键词集合的方法包括以下步骤:(I)人工挑选主题关键词,即在搜索引擎中检索有关主题的内容,在内容中抽取与主题相关的关键词,存储在数据库表中;(II)把(I)中人工挑选出的关键词作为搜索关键词在搜索引擎中进行检索,检索出的内容存储在文本文件中;(III)对该文本文件进行分词和TF-IDF算法词频排序后,取排名靠前的关键词作为主题关键词存储在数据库中。TF-IDF算法具体如下:对文本文件进行分词,并计算每个词的词频,在每个词的词频上相应乘以一个权重,这个权重根据这个词的标签的重要性来定,如果这个词出现在标题中,那么它的权重就设定高一点,如果这个词出现在内容中,权重就低一点,计算每个词的词频和权重的乘积得到每个词的最终权重,根据最终权重值的大小,选择权重高的前若干个关键词作为主题关键词即可,关键词最终权重wf计算公式如下:其中,i表示不同的标签,wi表示不同标签下关键词的权重系数,fi表示关键词在该文本文件中该标签下出现的次数;(IV)再重新把数据库表中的关键词作为搜索关键词在搜索引擎中进行搜索,重复这样的检索和词频排序动作,以不断地添加新的关键词存入数据库表中,最后数据库表中的所有关键词即为主题关键词。通过人工与自动提取主题关键词相结合的方法,可以提高被描述的主题的准确性。如果单靠人工挑选,不同的人对于主题的理解的侧重点不同,可能挑选出与主题不同关联度的词语,并且人工挑选相对较慢,效率低下,而简单地自动获取关键词也不能达到很好的效果。因此采用人工加自动提取主题的方式,可以扬长避短,互相补充,既能提高提取主题关键词的准确率也能获取更多与主题相关的关键词集合。优选地,步骤(5)所述从newsQueue中取出URL交给爬虫处理线程,即消费者线程具体包括以下步骤:下载URL对应网页,解析出正文和步骤(3)中对应URL的抓取关键词形成新闻的完整信息保存到数据库中,不断重复,直到待抓取news队列库中没有可以取出的URL为止。实施例:图1是关于生产者线程的具体实施流程图,具体步骤如下:(1)配置领域本体的描述信息并作为主题爬虫的模板,这些描述信息包括:主题关键词、抓取关键词。(2)确定“食品安全”主题关键词集合,得到食品安全主题关键词表foodsecureWord。在本实施中,采用百度、google、bing和360作为搜索引擎,设置主题为“食品安全”,首先在搜索引擎中检索有关食品安全的内容,在内容中抽取如“食品安全法”,“食品生产安全标准”,“食品超标”,“食品添加剂”等与食品安全相关的关键词,存储在数据库表foodsecureWord中,这就是所谓的人工挑选主题关键词的过程。然后再把这些关键词作为搜索关键词在搜索引擎中进行检索,检索出的内容存储在文本文件中,最后,对该文本文件进行分词和词频排序(如采用TF-IDF算法)后,取前10或20名的关键词作为主题关键词存储在foodsecureWord中,再重新把foodsecureWord中的关键词作为搜索关键词在搜索引擎中进行搜索,重复这样的检索和词频排序动作,这样就可以不断地添加新的关键词存入foodsecureWord中,最后foodsecureWord表中的所有关键词即为主题关键词。(3)形成初始种子超链接originalURL。根据表foodsecureWord中的主题关键词在搜索引擎中进行检索,配置搜索URL信息,形成初始种子超链接originalURL,其一般形式为:搜索引擎域名+搜索关键词+搜索结果起始页码,如360搜索“食品超标”的originalURL形式为:http://news.haosou.com/ns?q=%E9%A3%9F%E5%93%81%E8%B6%85%E6%A0%87%20&pn=1,其中“q=”的后面为主题关键词的16进制编码,“&pn=1”表示当前结果从第一页开始。要获取下一页URL可通过上一页网页正则匹配出下一页URL。(4)根据主题相关性,将与主题相关的抓取关键词放入队列newsQueue中。根据originalURL,在搜索引擎中进行检索并下载网页,根据网页内容,抓取相关字段包括:“标题(title)”、“URL”、“概要(summary)”、“图片(img_src)”、“网站(siteName)”、“新闻时间(newsTime)”、“源网站(sourceURL)”、“下一页链接(nextPageURL)”。其中除下一页链接外,其他关键词均为抓取关键词,根据主题相关性算法,将与主题相关的抓取关键词对应地放入待抓取新闻队列newsQueue中。以上所有关键词均可通过分析网页内容,设定正则表达式对相关内容进行抽取。4.1)生产者线程通过OriginalURL,下载网页,用Jsoup工具或者正则表达式可以抽取出其中的数据字段包括:“标题(title)”、“标题链接(URL)”、“内容概要(summary)”、“新闻来源(stieName)”、“图片(img_src)”、“新闻时间(newsTime)。获取到的URL信息如表3所示:表3:URL信息4.2)获取网页阶段,网页编码均统一为UTF-8格式,根据服务器返回网页html中的head区域中的charset标签后的内容得到网页的编码,若该编码为UTF-8,则直接返回网页,若为其他编码,则转码为UTF-8之后再返回html网页。4.3)根据主题相关性算法,由于生产者线程目前获取到的数据字段中的标题和概要是与主题最相关的信息,因此取URL的标题和概要进行主题相关性计算,得到该URL和主题的相似度α,将主题相关的种子URL,即主题相似度α>0.6的URL的新闻信息,包括title、URL、summary、siteName、img_src和newsTime放入newsQueue中。主题相关性算法步骤如下:(I)选取主题词集,获取训练集选定主题关键词,在搜索引擎中搜索得到相应关键词的Web文件和文本文件,作为word2vector的训练集;(II)利用word2vector工具将主题关键词转换为向量用word2vector工具对上一步得到的训练集进行训练,训练后,得到一个vectors.bin的二进制文件,利用该文件,将主题关键词转换为向量,得到向量集其中表示主题词j的向量,一共有n个主题词,得到n个主题向量;(III)选取m个待处理Web文档的特征词,并获取其特征向量采用分词方法对文档进行分词,并计算每个词的词频,在每个词的词频上相应乘以一个权重,即可得到每个词的最终权重w,最后,选取权重w排名前m位的词作为特征词,通过vectors.bin文件,将这m个特征词转换为向量,得到向量集其中表示特征词i的向量;(IV)计算向量集s和向量集d的相似性将d中向量与s中每个向量求余相似性得到其中,表示d中第i个向量的第k个维度上的数值,k从1取到向量的维数。同理表示s中第j个向量的第k维上的数值,k从1取到向量的维数。取余弦相似性最大值即为该向量与主题词的相似性,这样计算完d中每个向量与s中每个向量的相似性以后得到一个m维向量,将每一维值相加,并进行归一化(除以m)后得到待处理文档最终的主题相似性sim(s,d)(VI)设定阈值,URL入库设定一个阈值K=0.6,如果sim(s,d)>K,则将URL标题、摘要存入URL库,Web文本存入原始网页库,以便后期分析处理。(5)根据nextPageURL下载网页内容,抽取出步骤(3)所述的相关字段,用步骤4.3)的方法计算主题相关性,将与主题相关的抓取关键词放入newsQueue中,不断重复步骤(5),直到没有nextPageURL为止;(6)从newsQueue中取出URL交给爬虫处理线程,即消费者线程。图2是消费者线程具体实施流程图,具体步骤如下:如图2所示,消费者线程取出队列newsQueue中的URL,对URL下载相应的网页,利用正文提取算法,提取出URL的正文内容,和生产者线程抓取的关键词形成新闻的完整信息包括“标题(title)”、“标题链接(URL)”、“内容概要(summary)”、“新闻来源(stieName)”、“图片(img_src)”、“新闻时间(newsTime)”和“正文(content)”,最后,将完整的信息字段全部放入mysql数据库中。图3是生产者消费者模型,用于调度和消费者线程,具体步骤如下:如图3所示,当队列newsQueue为空时,就通知生产者进行生产URL,当队列中的URL过多或者已满时,生产者线程就通知消费者线程取出URL,这时候生产者自我阻塞,具体实现中调用了java多线程中的wait()和notify()机制。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1