一种基于选取合适聚类数目的聚类算法的数字图像处理方法与流程
本发明涉及一种基于选取合适聚类数目的聚类算法的数字图像处理方法,属于聚类算法分割技术领域。
背景技术:
在图像处理领域中,图像分割对于图像的分类和处理是非常重要的。因此,我们需要将这些图像划分成不同的区域,并提取所感兴趣的对象。在不同的图像分割技术中,聚类是重要的方法之一,并且在灰度图像的图像分割上得到广泛的应用。目前有很多聚类算法:k-means聚类;Fuzzy c-means聚类;山峰聚类和ISODATA方法等。其中最常用的算法是k-means聚类算法。K-means算法是一种无监督聚类算法,它具有直观、快速和容易实现等特性。尽管这种算法是非常受欢迎的,它仍然具有一些缺陷。其中,最主要的是k-means聚类需要提前知道聚类数,这将降低它的鲁棒性和稳定性。
图像分割就是将图像中有意义的特征或区域提取出来的一个过程。特别是在医疗领域,医学研究者需要从背景中提取感兴趣的区域。因此,我们需要将这些图像划分成不同的区域,并提取所感兴趣的对象。同时,在各区域内的像素点应具有较高的相似性,区域之间的像素点应具有较高的差异性。图像分割的应用非常广泛,它几乎出现在有关于图像处理的所有领域,是图像处理中的一个基础也是重要的步骤。
在不同的图像分割技术中,聚类是重要的方法之一,并且在灰度图像的图像分割上得到广泛的应用。聚类是分组的一组物体进入相似地特征类的处理过程。它已在许多领域被广泛使用,包括在统计、机器学习、模式识别、数据挖掘和图像处理等。在数字图像处理中,分割在图像描述和分类中是必不可少的。该技术通常用于许多消费电子产品(即常规的数字图像),或在一个特定的应用领域,如医学数字图像。算法通常基于相似性和特殊性,其可分为不同的类别,如阈值、模板匹配、区域生长、边缘检测、并群集。聚类算法已经被应用在各种领域,如工程、计算机和数学数字图像分割技术。最近,聚类算法的应用已被进一步施加到医疗领域中,特别是在生物医学图像分析,其特征在于图像是由医学成像设备产生的。以前的研究证明,聚类算法能够分割和确定在医学图像中感兴趣的特定区域。在生物医学图像分割任务中,聚类算法通常被认为是适合从已知的解剖信息中分割出感兴趣的结构。
基于最小化形式的目标函数的聚类方法中,最广泛使用的就是K-means聚类。K-means算法也被称为K均值算法,是一种得到最广泛使用的聚类算法。它将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,并且类间是独立的。这一算法不适合处理离散型属性,但是对于连续型具有较好的聚类效果,用于图像分割具有直观、快速、易于实现的特点。尽管这种算法是非常受欢迎的,它仍然具有一些缺陷。首先,k-means聚类过程容易陷入局部极小。其次,它不适合用于处理具有离散属性的数据。另外,它还有可能忽略一些小的聚类。值得注意的是k-means聚类需要提前知道聚类数,这将降低它的鲁棒性和稳定性。
技术实现要素:
发明概述
针对现有技术的不足,本发明提供了一种基于选取合适聚类数目的聚类算法的数字图像处理方法;
本发明介绍了一种最优化准则来解决聚类数目对最终分割图像的影响。我们基于类内像素差异和类间像素差异来定义一个公式。通过该标准,可以用尽量少的聚类数目得到较好的分割结果。通过客观的评估测试量度NU and F(I),我们验证了该标准性能的稳定性。此外,本发明还改进了传统k-means算法中确定初始聚类中心的方法,利用分位数策略代替了随机选择的方法。使用分位数来确定初始聚类中心可以使分割图像更稳定,同时可以节省运行时间。
发明详述
术语解释
1、分位数,分位数即分位点,拿四分位数为例,即统计学中,把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数。在本发明中,设聚类数位K,即把要分割的图像的所有像素由小到大排列分成K等份,求出每等份的中心值作为初始聚类中心。
2、K-means聚类,一种在数据集中寻找数据聚类的算法,让差异性度量的成本函数(目标函数)达到最小。
本发明的技术方案如下:
一种基于选取合适聚类数目的聚类算法的数字图像处理方法,具体步骤包括:
(1)输入灰度图像;
(2)设置需要迭代聚类数K的数目;K的初始值为2;
众所周知,在传统的k-means算法中迭代聚类数K是未知的。实际上,对于大多数的数字图像和显微图像,把迭代聚类数K设置为2,这是不足以恰当的进行图像分割的。也有一些实验者根据自己的经验来选择k的值,例如,头部医学图像包括的区域为软组织,骨头,脂肪和背景区域,所以他们把k的值设定为4。为了确定k的最优值,本发明找到一种测量标准,自动地确定最优的k值。在进行聚类之前,设置k从2至16循环,以代替一个固定假设值。提供了更直观的趋势以帮助我们分析。
(3)搜索初始聚类中心:使用分位数的概念寻找初始聚类中心;具体步骤包括:
A、将步骤(1)输入的灰度图像中的所有像素按照灰度值进行升序排列,得到向量,即:所述灰度图像的大小m*m为一个矩阵,将该矩阵转换成1*m2的向量,再将1*m2的向量中的所有元素按从小到大的升序排列,得到所述向量;所述向量的分位数Pi通过式(Ⅰ)计算,i=1,2,...,K:
B、通过步骤A计算得到K个分位数,包括P1,P2,...,Pi,P1,P2,...,Pi分别对应着步骤A所述向量,P1,P2,...,Pi即为步骤(1)输入的灰度图像的初始聚类中心;
例如,K=4,计算得到四个分位点:P1,P2,P3,P4,P1,P2,P3,P4四个值的结果为:12.5,37.5,62.5,87.5。这些值对应着向量的初始聚类中心。
根据传统K-均值聚类算法,需要从图像中随机选择k个点作为初始聚类中心。然后该算法根据最小欧氏距离将数据点分配到各个聚类中。通过一定次数的迭代,它最大限度地减少从每个对象到聚类中心的距离之和,直至这些质心不会再发生变化。但是,这种传统的方法效率低,运行时间比较久。而本发明寻找初始聚类中心是非常高效的,它相比随机寻找的方法节省了运行时间。在接下来的说明中,会进行对比测试来验证它的效率。
(4)按照标准的k-means聚类步骤进行图像分割,输出的分割图像;
(5)采用最优化准则选出最优分割结果,具体步骤包括:
①通过式(Ⅱ)求取输出的分割图像的类内差异值Sin,类内差异值Sin是指在一个聚类中所有像素的像素值之间的标准偏差:
式(Ⅱ)中,C1,C2,C3,......,Ci是指步骤(3)求取的初始聚类中心P1,P2,...,Pi对应的聚类,n是当前分割图像中像素的数量,x代表在聚类Ci中每个像素的像素值,是第i个类中所有像素的像素值的平均值;
②通过式(Ⅲ)求取输出的分割图像的类间差异值Sout,类间差异值Sout是指i个初始聚类中心的像素值之间的标准偏差,其值越大越好。
式(Ⅲ)中,K是指聚类数,Pi是指第i个初始聚类中心(的像素值),是所有初始聚类中心的平均像素值;
③通过式(Ⅳ)求取最优化标准为G,如下所示:
④根据以上步骤依次求取K为2、3、4、5、6、7、8、9、10、11、12、13、14、15、16时对应的最优化标准为G,根据求取的对应的最优化标准G获得最好的分割效果。
根据本发明优选的,所述步骤(4),具体步骤包括:
a、初始化聚类中心Pi;
b、确定隶属度矩阵uij:当第j个像素点的像素值Xj属于Ci时,uij为1,否则为0;即:如果Pi是所有初始化聚类中心中最接近Xj的中心点,则Xj属于Ci;
c、通过式(Ⅴ)计算成本函数J:
当计算得到的成本函数J低于0.005时,则停止计算成本函数,否则继续计算成本函数;
d、根据式(Ⅵ)获取最优聚类中心,即是聚类Ci的平均值:
式(Ⅵ)中,|Ci|即为Ci的大小;
e、输出分割图像。
本发明的有益效果为:
1、本发明提出了一个在分割图像中可以决定聚类数目的最优化准则。它采用了类内差异和类间差异的概念以较少的聚类数目可以获得最佳的分割结果。实验结果表明,该准则具有足够的效率和稳定性。此外,其他的评价方法也得到一致的结果。
2、本发明通过改进寻找初始聚类中心方法的k-means算法也比传统的k-means算法在运行时间上更有优势。
附图说明
图1为本发明所述基于选取合适聚类数目的聚类算法的数字图像处理方法的流程示意图;
图2为实施例中得到的不同K值下得到的最优化标准为G的变化趋势图;
具体实施方式
下面结合说明书附图和实施例对本发明做进一步限定,但不限于此。
实施例
一种基于选取合适聚类数目的聚类算法的数字图像处理方法,本实施例用南加州大学的USC-SIPI图像测试库来验证,如图1所示,具体步骤包括:
(1)输入灰度图像;
(2)设置需要迭代聚类数K的数目;K的初始值为2;
众所周知,在传统的k-means算法中迭代聚类数K是未知的。实际上,对于大多数的数字图像和显微图像,把迭代聚类数K设置为2,这是不足以恰当的进行图像分割的。也有一些实验者根据自己的经验来选择k的值,例如,头部医学图像包括的区域为软组织,骨头,脂肪和背景区域,所以他们把k的值设定为4。为了确定k的最优值,本发明找到一种测量标准,自动地确定最优的k值。在进行聚类之前,设置k从2至16循环,以代替一个固定假设值。提供了更直观的趋势以帮助我们分析。
(3)搜索初始聚类中心:使用分位数的概念寻找初始聚类中心;具体步骤包括:
A、将步骤(1)输入的灰度图像中的所有像素按照灰度值进行升序排列,得到向量,即:所述灰度图像的大小m*m为一个矩阵,将该矩阵转换成1*m2的向量,再将1*m2的向量中的所有元素按从小到大的升序排列,得到所述向量;所述向量的分位数Pi通过式(Ⅰ)计算,i=1,2,...,K:
B、通过步骤A计算得到K个分位数,包括P1,P2,...,Pi,P1,P2,...,Pi分别对应着步骤A所述向量,P1,P2,...,Pi即为步骤(1)输入的灰度图像的初始聚类中心;
K=4,计算得到四个分位点:P1,P2,P3,P4,P1,P2,P3,P4四个值的结果为:12.5,37.5,62.5,87.5。这些值对应着向量的初始聚类中心。
根据传统K-均值聚类算法,需要从图像中随机选择k个点作为初始聚类中心。然后该算法根据最小欧氏距离将数据点分配到各个聚类中。通过一定次数的迭代,它最大限度地减少从每个对象到聚类中心的距离之和,直至这些质心不会再发生变化。但是,这种传统的方法效率低,运行时间比较久。而本发明寻找初始聚类中心是非常高效的,它相比随机寻找的方法节省了运行时间。在接下来的说明中,会进行对比测试来验证它的效率。
(4)按照标准的k-means聚类步骤进行图像分割,输出的分割图像;具体步骤包括:
a、初始化聚类中心Pi;
b、确定隶属度矩阵uij:当第j个像素点的像素值Xj属于Ci时,uij为1,否则为0;即:如果Pi是所有初始化聚类中心中最接近Xj的中心点,则Xj属于Ci;
c、通过式(Ⅴ)计算成本函数J:
当计算得到的成本函数J低于0.005时,则停止计算成本函数,否则继续计算成本函数;
d、根据式(Ⅵ)获取最优聚类中心,即是聚类Ci的平均值:
式(Ⅵ)中,|Ci|即为Ci的大小;
e、输出分割图像。
(5)采用最优化准则选出最优分割结果,具体步骤包括:
①通过式(Ⅱ)求取输出的分割图像的类内差异值Sin,类内差异值Sin是指在一个聚类中所有像素的像素值之间的标准偏差:
式(Ⅱ)中,C1,C2,C3,......,Ci是指步骤(3)求取的初始聚类中心P1,P2,...,Pi对应的聚类,n是当前分割图像中像素的数量,x代表在聚类Ci中每个像素的像素值,是第i个类中所有像素的像素值的平均值;
②通过式(Ⅲ)求取输出的分割图像的类间差异值Sout,类间差异值Sout是指i个初始聚类中心的像素值之间的标准偏差,其值越大越好。
式(Ⅲ)中,K是指聚类数,Pi是指第i个初始聚类中心(的像素值),是所有初始聚类中心的平均像素值;
③通过式(Ⅳ)求取最优化标准为G,如下所示:
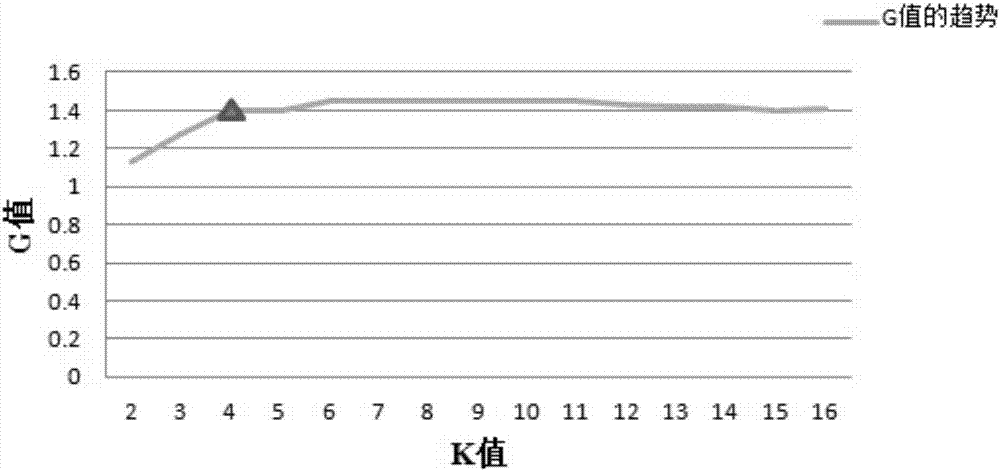
④根据以上步骤依次求取K为2、3、4、5、6、7、8、9、10、11、12、13、14、15、16时对应的最优化标准为G,根据求取的对应的最优化标准G获得最好的分割效果。如图2所示,G值的变化趋势就会像图2所示的一样。我们发现当聚类数超过4之后G值的趋势是趋于水平的。我们可以解释为在K小于4时,这些聚类不足以将图像进行良好的分类。而当K大于4时,G值几乎收敛成一条直线,说明在K等于4之后,每幅分割图像的分类效果不会有大的改变,即已经有足够的聚类数进行分类了。因此当k等于4时,我们可以获得最好的分割效果。
最优化准则:当我们使用改进的k-means聚类算法之前,要先设置迭代次数K来进行实验。我们尝试使用不同的K去得到不同的分割结果因为我们需要用最优化准则来评估哪个值可以给我们带来最好的分割结果。许多准则已经开发用于确定k-means聚类的有效性,所有这些准则都试图去找到分割效果最好的聚类数。例如,Bezdek等人鉴于修改的Hubert统计,Davies–Bouldin和Dunn指标提出了聚类有效性的一些新的指标。Milligan等人测试了很多程序去确定一个数据集中聚类的数目。Cooper等人测试了在聚类分析中聚类的数目对测量误差的影响。
作为一个聚类算法,我们肯定希望在一个聚类中的所有聚类的类内差异最小,同时一幅数字图像所有类的类间差异最大。我们定义类内差异值为Sin,它代表在一个类中所有像素的像素值之间的标准偏差。假设初始聚类中心为C1,C2,C3,......,Ci,则Sin定义为:
通过计算所有聚类中心之间的标准差得到它,被定义为:
考虑前面提到的类内差异值和类间差异值,我们需要组合它们变成比值作为测量标准。因为我们希望最小化类内差异值,最大化类间差异值,所以我们应该将类内差异值放到分子上,把类间差异值放到分母上,公式为:
我们确定最优化结果只需要找到比值的最小值。通过多次的实验,我们发现当使用我们的算法去分割图像时,Sin呈现一个逐渐下降的趋势,Sout首先增加然后逐渐趋于持平。但是Sin的变化快于Sout,这将会导致比值呈下降趋势。如果结果是这样的,我们则不能确定聚类的最佳数量。因此我们需要修改公式来解决这个问题,重新排列展示公式:
即式(IV)。
通过重排公式我们发现,中间一项为2次幂,而常数K只是一次幂。因此如果它只乘以K,该公式将导致单调下降。为了解决这个问题,我们在原有的公式上再乘以K,使得后两项的幂数相同。这样就可以产生我们在本文中提出的最优化标准。
为了进一步证明提出方法的能力和适用性,我们通过与Fuzzy C-means算法和OTSU算法的对比来检验我们的方法。首先,我们使用被称为归一化度量(NU)的灰度图像的客观评价参数来比较分割结果。归一化度量的公式:
NU=1-GU/C (Ⅷ)
f(x,y)为一幅灰度图像,Zi是第i个分割区域,Ai是区域Zi的面积,C是归一化参数,GU是f(x,y)的归一化量度。一个区域的特征一致性可以通过计算每个区域在所属区域的方差来评价。因此,一个更好的分割结果应该具有较大的NU值。我们分别使用Fuzzy C-means算法和改进的k-means算法对原始图像和分割图像计算NU的值,把K的值分别设置为2,3,4。同时,我们还增加了当K等于2时OTSU算法的结果。
因为OTSU输出的是二值图像,所以我们只能展示它两个聚类时的结果。通过实验可以得出,NU的最大值是在k等于4时用改进的k-means算法分割的结果。这个结论和之前通过最优化准则得到的结论一致。此外我们证明了在所有的聚类数目中用改进的k-means算法都比fuzzy c-means有更好的分割结果。
为了局部和全局同时评价结果,我们又使用了Liu和Yang的评价函数。评价函数定义为:
其中I是用来被分割的图像,k是聚类数,Ai是第i个区域的面积,ei被定义为原始图像和分割图像在这个区域的每个像素点之间的特征向量的欧式距离总和。
该函数不会因为人为的设置参数而对结论产生影响。F(I)的值越小就说明分割结果越好。我们还可以得出结论,即由我们的最优化准则产生的聚类数为4的分割图像具有最小的F(I)值。验证结果也证实,由我们的最优化准则选定的分割图像是最好的分割结果。
此外,改进的K-means算法比传统的K-means算法在处理时间上更有效率。我们从数据库中选择了5幅图像进行测试。每个图像的处理时间是聚类数k从2到6循环处理的总时间。实验结果证明了改进的k-means算法相比传统的k-means算法得到了更短的运行时间。这个结果也说明了在改进了新招初始聚类中心的方法后算法展现了更高的效率。
- 还没有人留言评论。精彩留言会获得点赞!