一种基于工作序列的文档自动生成模型的构建方法与流程
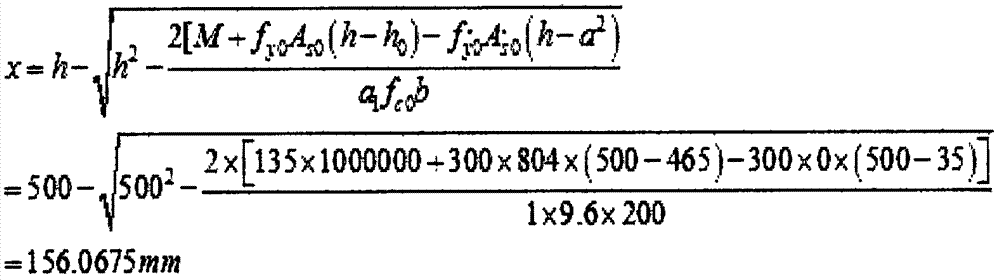
本发明涉及文档自动生成技术领域,更具体的涉及一种基于工作序列的文档自动生成模型的构建方法。
背景技术:
随着计算机的普及和信息化技术的发展,使用字处理软件撰写文档、完成工作报告,已经成为人们生活工作必不可少的事情。微软Office Word因满足办公需求、功能齐全、操作方便,已经成为流行的应用软件。在数据展示方面,使用Word可以制作图、问、表并茂的文档,具有一些报表工具不可替代的优点,包括多层次嵌套表格、斜线表格等;在专业文档方面,Word支持复杂的数学公式编辑和格式化呈现,支持对象嵌入扩展功能。
在企业生产环境中,因业务的连续性和重复性,工作过程中需要编制的检测报告、技术方案书、计算书等文档是重复发生的行为。同一类型的文档,在格式、结构和内容方面往往相似,在数据分析和结论评价方面常常不同。如果所有文档的编制工作全部由手工完成,无疑工作量巨大,而且因人为原因导致文档数据纰漏的风险极大。
值得庆幸的是Word不仅仅是一个文字编辑软件,还是一个可扩展编程开发环境,可以通过程序对Word进行二次开发自动生成文档,以满足用户的特定要求。目前,有关文档自动生成的研究取得了初步的进展,结合具体的行业,出现了一些成功的案例,但仍缺乏有效的理论支持。
早期文档自动生成的研究主要集中在Word二次开发的文档生成技术等方面(如报告生成、试卷生成、文档水印、自动排版、公式嵌入、数据填充等),开发技术使用VBA和OLE较为常见。这些研究结合具体的应用场景解决了一些实际问题,具有一定的现实意义。
在生成文档时使用模板是通用的做法:将一篇规范的通用文档中可被替换的部分采用插入批注的形式设置标签,通过标签查询与替换实现文档生成。葛芬等使用COM Add-In技术实现了_IDTExtensibility2派发接口,制作了模板定制工具,构建了模板数据库,实现了Word文档的自动生成。李自胜等采用XML技术,对文档模板进行了结构化设计,将文档内容归纳为既有文本、输入文本、单选文本和多选组合文本4种类型,分别采用编辑框、单选框和复选框控件界面,从而降低了文档处理的难度。
然而在企业生产环境中,待生成的目标文档并非简单地用数据替换模板中的标签,文档中嵌入的数据往往来自于数据库或依赖企业的某些业务系统。这些数据有些能直接从数据库查询得到;有些分散在业务系统中,需要按工作流程在网络中传递、汇总和审批;有些需要按自定义的规则经过进一步的计算和处理。因此,文档自动生成系统与工作流系统的结合成为一个研究方向。
曲明成等针对企业在编辑数据汇总文档时因手动计算、人工检验造成效率低下且容易出错等问题,结合工作流系统提出了一个文档自动生成的数学模型。数据经过工作流系统流转、审批,文档自动生成系统从中心数据库抽取数据嵌入模板自动生成文档。该模型清晰地描述了文档生成过程中的公式换算、数据抽取与映射及模板替换的问题,在电力制造企业的复杂计算文档自动化应用成功。但是对于如何识别计算步骤之间的依赖关系,如何通过复杂的计算序列控制文档生成过程,该模型没有提及。
姜鹏等在防汛文档智能生成模型构建中,借鉴和改造了传统的工作流概念,引入了有向图表示工作流模型,并将模型应用于防汛防旱简报生成,从而快速生成格式规范、数据准确、内容完善的防汛文档。作者在文中提出了使用有向图的节点表示工作步骤的概念,用节点之间的边表示数据流动关系。该文虽然给出了计算序列处理数据生成文档的轮廓,但重点却放在模板标签的查找替换算法和系统架构实现上。
在现代工业,尤其是在化工、机械、建筑等行业中,设计校核计算是工程设计过程中极其重要的一个环节。计算书的正确、有效及可靠性是保证工程设计质量的重要条件,也是追溯设计源头的重要依据。计算书中往往包含较多的计算步骤,步骤之间存在着依赖关系,步骤当中嵌有计算变量。变量的取值依赖于上下文环境,主要来自三个方面:第一,通过数学公式的计算获得;第二,通过业务数据库查询获得;第三,通过用户交输入互获得;对此,本人开发基于工作序列的文档自动生成模型的构建方法,针对文档生成过程中需要计算和利用上下文数据的问题,借鉴工作流程的思想,明确了计算步骤、计算序列和工作序列的概念,给出了变量内存栈和工作序列栈的定义,可依此建立一个基于工作序列的文档自动生成模型,完善了公式计算引擎、工作序列计算引擎、模板标签替换和目标文档转换的算法以及步骤,并在建筑结构加固设计计算书的自动生产中得到应用,经过测试,达到了不同加固方法的计算书自动生成要求,极大地简化了建筑加固设计的工作过程,显著提高了工作效率。
技术实现要素:
有鉴于此,本发明提供了一种基于工作序列的文档自动生成模型的构建方法,可实现公式计算引擎算法、工作序列计算引擎算法、模板标签替换算法和目标文档转换算法,并能够在建筑结构加固设计计算书的自动生成中得到应用,可达到不同加固方法的计算书自动生成要求,极大地简化了建筑加固设计的工作过程,显著提高了工作效率。
为解决上述技术问题,本发明的技术方案是:
一种基于工作序列的文档自动生成模型的构建方法,模型中包含模板文档、中间文档和目标文档,模板文档由不变的文字和变量关键字组成,变量值来自内存变量栈和工作序列栈,将变量值代替模板文档中的变量,实现向中间文档的转换,再利用设定规则和算法,实现向目标文档的转换,
步骤1、建立基于工作序列的文档自动生成模型的基本结构:
基本机构以文档自动生成系统为核心,外部构建公共数据构造器、设计参数构建器、计算序列构造器和模板构造器;
步骤2、模型系统的基础设置:
包括定义变量规则、定义标签规则和定义运算符;
步骤3、公共数据处理:
首先定义公共数据规范,再编制接口文档,最后导入公共数据;
步骤4、设计数据处理:
包括定义设计数据规范,配置界面参数,自动生成界面,采集保存数据,导入设计数据;
步骤5、工作序列定义:
维护计算步骤,维护工作序列,公式变量编辑器,公式验证;
步骤6、文档生成引擎:
构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成。
所述步骤1,其中公共数据构造器,负责从个业务系统中提取数据构成G集合,为模型运算提供基础数据;设计参数构造器,根据配置文件生成标准化的UI程序界面,为用户设计输入提供支持,最后导入设计参数集P参与模型运算;计算序列构造器,用来编辑和生成工作序列S集合,模型根据S集合表达的计算逻辑进行计算;模板构造器,用来生成基于XML格式的模板文档;文档自动生成系统,包括变量存储器M,用来完成数据转换、计算序列运算、模板数据填充和文档生成,计算步骤如下
第一步:数据初始化,构建初始内存变量栈和计算序列栈,通过转换函数将基础数据和设计数据加载到内存变量栈中;
第二步:启动计算序列栈运算,识别并计算步骤公式和条件跳转公式,并根据需要从内存变量栈中取值,同时动态更新计算步骤所代表变量的值,并写回到内存变量栈中;
第三步:模板标签值替换,计算序列运算结束后,内存变量栈和计算序列栈中有明确的值,遍历模板提取标签,解析处变量名称,从中查询相应的值替换,生成中间文档;
第四步:目标文档生成,根据目标文档生成的规则,将中间文档格式化成目标文档所要求的格式。
所述步骤2,其中定义变量规则,对内存变量栈和计算序列栈进行定义,包括
定义1定义变量标识K由模板文档中的文字C′经过函数GK(C′)转化而来,即K=GK(C′);
定义2定义变量标识K的类型为一个二元组K<μ,δ>,Kυ<μυ,δυ>为K的最终生成值。μ和δ代表了两种不同类型的变量,μυ和δυ分别对应它们的最终计算值;
定义3定义内存变量γ为一个二元组γ<k,υ>,k为变量γ的标识符,υ为变量γ的值,内存变量空间R={γ};
定义4函数Ve=Ge(VE)将计算出VE的结果,Ve为算术公式的计算结果;
定义5函数Ke=Q(SE)将变量公式SE中的变量提取出来,SE中包括内存变量和预设的计算操作符,Ke是从变量公式中提取的内存变量标识符集合;
定义6函数VE=C(M,SE,Ke)将变量公式SE转化为算术公式VE,其中M为内存变量栈
定义7定义内存变量栈M为R的子集,内存变量γ的标识符在M中全局唯一,M包含读取变量值和写入变量两种操作;
定义8函数Kυ=GV(M,K)从内存栈M中读取变量标识符为K的变量值Kυ;
定义9函数SR(M,γ)定义将变量γ写入内存变量栈M,如果γ,k在M中出现,那么SR将覆盖原值,否则新增保存;
定义10定义计算序列栈S由计算步骤s组成,即S={s},计算步骤s为计算序列的计算单元;
定义11函数Ks=GS(S,K)定义从计算序列栈S中读取变量标识符K所指定步骤集合计算的结果集Ks;
模板标签包括模板变量标签、计算序列结果占位符标签和模板格式控制标签。
所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中构建内存变量栈包括
定义12定义Rg为由系统预设参数集生成的内存变量集合,记Rg={γg}={γ|γ=fg(g)∧g∈G},其中G为系统预设参数集合,g为G的元素,γg表示从集合G中转换出的内存变量元素,函数fg实现g→γg的转换;
定义13定义Rp为业务设计参数集生成的内存变量集合,记Rp={γp}={γ|γ=fp(p)∧p∈P},其中P为业务设计参数集合,p为P的元素,γp表示从集合P中转换出的内存变量元素,函数fp实现p→γp的转换;
定义14定义Rs为由计算序列S生成的内存变量集合,记Rs={γs}={γ|γ=fs(s)∧s∈S},其中S为计算序列,s为S的元素,γs表示从集合S中转换出的内存变量元素,函数fs实现s→γs的转换;
定义15函数M=Rg+Rp+Rs,M为内存变量栈,函数指明了M的组成,其中“+”表示并集运算,即相同的变量在并集运算时相同标识符的变量的值会被新值覆盖。
所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中公式计算引擎,包括:①定义了表达式的操作符及优先级;
②加载操作符及优先级;
③取中序表达中的操作数或变量名并以列表返回,为变量替换时使用;
④计算中序数值表达式的值;
⑤中序表达式转后序表达式;
⑥计算后序表达式的值;
⑦求两个操作符的优先级别;
⑧计算两个操作数的表达式值;
⑨将两数运算的表达式转成word公式表达式形式。
所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中工作序列计算引擎包括:
定义16定义计算步骤s<sk,se,υe,sυ,type,sc>为一个六元组,其中sk为变量标识符,se为变量公式,υe为变量替换后的算术公式;sυ为算术公式运算结果值,sc为运算条件表达式,sc的计算结果决定了下一个参与运算的计算步骤元素的跳转条件,他控制着计算序列的运算逻辑,计算步骤的类型s.type=enum{VAR,EXP,TXT,FUN},VAR表示s.se是一个内存变量,参与计算时可以直接在M中取值;EXP表示s.se是一个由数值常量、内存变量和运算符等组成的变量公式,在参与计算时,首先提取公式中的变量,然后依次在M中取值替换生成算术公式,最后计算算术公式的值作为计算步骤的值;TXT表示s.se是一个嵌入内存变量的文本串,文本串中可以包含数值常量串、内存变量以及它们组成的公式串,参与计算时,文本串中的内存变量将被提取,内存变量由对应的值替换,公式串不参与算术运算;FUN表示s.se是一个自定义函数,表现形式为一个格式化的文本串,串中可以包含数值常量串和内存变量,参与运算时,首先取变量值替换自定义函数串的变量,然后对自定义函数串进行解析,最后在自定义函数库中调用相关函数进行计算;
定义17函数Vc=Gc(SC)计算条件表达式SC的值,SC中可以包含若干数值串、内存变量和条件运算符;
定义18函数Vf=Gf(FS)解析自定义函数串FS,分离函数名和参数,并调用相关的自定义函数计算结果,FS中可以包括若干数值串和内存变量,内存变量根据上下文在内存变量栈M中取值;
定义19定义计算步骤s的类型由一个四元组表示sk<w,x,y,z>,其中w,x,y,z分别代表了VAR,EXP,TXT,FUN类型的计算步骤,
计算步骤计算的过程描述
(1)由定义8、定义16可知:
w.υe=GV(M,w.se)
w.sυ=w.υe
(2)由定义5、定义6、定义4和定义16可知:
Kx=Q(x.se)
x.υe=C(M,x.se,Kx)
x.sυ=Ge(x.υe)
(3)由定义5、定义6和定义16可知:
Ky=Q(y.se)
y.υe=C(M,y.se,Ky)
y.sυ=y.υe
(4)由定义5、定义6、定义4和定义17可知:
Kz=Q(z.se)
z.υe=C(M,z.se,Kz)
z.sυ=Gf(z.υe)
(5)由定义5、定义6、定义4、定义17可知:
Kc=Q(s.sc)
iNext=Gc(C(M,s.sc,Kc))
sNext=S[iNext]
其中iNext为下一个参与运算的步骤元素在计算序列栈中索引;sNext为下一个参与运算的步骤元素。
所述所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中文档转换与生成包括对模板与文档的定义:
定义20定义模板为一个二元组T<C,K>,C为模板文档中不变的文字部分,K为模板文档中的变量标识符,K在模板文档上下文中表示相同含义;
定义21定义中间文档为一个二元组W′<C,U>,C为模板中不变的文字部分,U为模板文档变量的在上下文计算后的结果值;
定义22函数Z(K,U)将K替换成U,其中K为文档中的变量,U为模板变量的在上下文计算后的结果值;
定义23函数W=X(W′,Ru)将中间文档转换为目标文档,其中W′为中间文档,W为最终的目标文档,Ru为中间文档向目标文档转换规则。
所述文档转换与生成中还包括计算逻辑的存储定义:
定义24定义集合STO存储了文档生成过程中使用的计算逻辑,记STO={M,S,T,K,K<μ,δ>,Ru},其中变量分别表示:内存变量栈、模板、模板变量、模板变量类型和中间文档向目标文档的转换规则;
定义25操作Get(STO)→T实现从STO中已存储的计算逻辑提供给模板进行处理;
所述文档生成的计算步骤如下:
A、U=Kυ<μυ,δυ>
B、W′<C,U>=Get(STO)→T<C,K>=Get(STO)→T<C,Z(K,U)>
=Get(STO)→T<C,Z(K,Kυ<μυ,δυ>)>
C、μ=GK(C′1),δ=GK(C′2)
D、μυ=GV(M,μ),δυ=GS(S,δ)
E、W′<C,U>=Get(STO)→T<C,Z(GK(C′),Kυ<μυ,δυ>)>
=Get(STO)→T<C,Z(GK(C′),Kυ<GV(M,μ),GS(S,δ)>)>
=Get(STO)→T<C,Z(GK(C′),Kυ<GV(M,GK(C′1)),GS(S,GK(C′2))>)>。
较现有技术,本发明有益技术效果主要体现在:针对文档生成过程中需要计算和利用上下文数据的问题,借鉴工作流程的思想,明确了计算步骤、计算序列和工作序列的概念,给出了变量内存栈和工作序列栈的定义,可依此建立一个基于工作序列的文档自动生成模型,完善了公式计算引擎、工作序列计算引擎、模板标签替换和目标文档转换的算法以及步骤,并在建筑结构加固设计计算书的自动生产中得到应用,经过测试,达到了不同加固方法的计算书自动生成要求,极大地简化了建筑加固设计的工作过程,显著提高了工作效率。
附图说明
图1:本发明的模型结构示意图;
图2:本发明的公式引擎通用表达式的计算示例图;
图3:本发明的工作序列计算引擎算法流程图;
图4:本发明的计算书生成流程图。
具体实施方式
以下结合附图,对本发明的具体实施方式作进一步详述,以使本发明技术方案更易于理解和掌握。
实施例1
如图1、图2、图3和图4所示,一种基于工作序列的文档自动生成模型的构建方法,模型中包含模板文档、中间文档和目标文档,模板文档由不变的文字和变量关键字组成,变量值来自内存变量栈和工作序列栈,将变量值代替模板文档中的变量,实现向中间文档的转换,再利用设定规则和算法,实现向目标文档的转换,
步骤1、建立基于工作序列的文档自动生成模型的基本结构:
基本机构以文档自动生成系统为核心,外部构建公共数据构造器、设计参数构建器、计算序列构造器和模板构造器;
步骤2、模型系统的基础设置:
包括定义变量规则、定义标签规则和定义运算符;
步骤3、公共数据处理:
首先定义公共数据规范,再编制接口文档,最后导入公共数据;
步骤4、设计数据处理:
包括定义设计数据规范,配置界面参数,自动生成界面,采集保存数据,导入
设计数据;
步骤5、工作序列定义:
维护计算步骤,维护工作序列,公式变量编辑器,公式验证;
步骤6、文档生成引擎:
构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成。
所述步骤1,其中公共数据构造器,负责从个业务系统中提取数据构成G集合,为模型运算提供基础数据;设计参数构造器,根据配置文件生成标准化的UI程序界面,为用户设计输入提供支持,最后导入设计参数集P参与模型运算;计算序列构造器,用来编辑和生成工作序列S集合,模型根据S集合表达的计算逻辑进行计算;模板构造器,用来生成基于XML格式的模板文档;文档自动生成系统,包括变量存储器M,用来完成数据转换、计算序列运算、模板数据填充和文档生成,计算步骤如下
第一步:数据初始化,构建初始内存变量栈和计算序列栈,通过转换函数将基础数据和设计数据加载到内存变量栈中;
第二步:启动计算序列栈运算,识别并计算步骤公式和条件跳转公式,并根据需要从内存变量栈中取值,同时动态更新计算步骤所代表变量的值,并写回到内存变量栈中;
第三步:模板标签值替换,计算序列运算结束后,内存变量栈和计算序列栈中有明确的值,遍历模板提取标签,解析处变量名称,从中查询相应的值替换,生成中间文档;
第四步:目标文档生成,根据目标文档生成的规则,将中间文档格式化成目标文档所要求的格式。
所述步骤2,其中定义变量规则,对内存变量栈和计算序列栈进行定义,包括
定义1定义变量标识K由模板文档中的文字C′经过函数GK(C′)转化而来,即K=GK(C′);
定义2定义变量标识K的类型为一个二元组K<μ,δ>,Kυ<μυ,δυ>为K的最终生成值。μ和δ代表了两种不同类型的变量,μυ和δυ分别对应它们的最终计算值;
定义3定义内存变量γ为一个二元组γ<k,υ>,k为变量γ的标识符,υ为变量γ的值,内存变量空间R={γ};
定义4函数Ve=Ge(VE)将计算出VE的结果,Ve为算术公式的计算结果;
定义5函数Ke=Q(SE)将变量公式SE中的变量提取出来,SE中包括内存变量和预设的计算操作符,Ke是从变量公式中提取的内存变量标识符集合;
定义6函数VE=C(M,SE,Ke)将变量公式SE转化为算术公式VE,其中M为内存变量栈
定义7定义内存变量栈M为R的子集,内存变量γ的标识符在M中全局唯一,M包含读取变量值和写入变量两种操作;
定义8函数Kυ=GV(M,K)从内存栈M中读取变量标识符为K的变量值Kυ;
定义9函数SR(M,γ)定义将变量γ写入内存变量栈M,如果γ,k在M中出现,那么SR将覆盖原值,否则新增保存;
定义10定义计算序列栈S由计算步骤s组成,即S={s},计算步骤s为计算序列的计算单元;
定义11函数Ks=GS(S,K)定义从计算序列栈S中读取变量标识符K所指定步骤集合计算的结果集Ks;
模板标签包括模板变量标签、计算序列结果占位符标签和模板格式控制标签。
所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中构建内存变量栈包括
定义12定义Rg为由系统预设参数集生成的内存变量集合,记Rg={γg}={γ|γ=fg(g)∧g∈G},其中G为系统预设参数集合,g为G的元素,γg表示从集合G中转换出的内存变量元素,函数fg实现g→γg的转换;
定义13定义Rp为业务设计参数集生成的内存变量集合,记Rp={γp}={γ|γ=fp(p)∧p∈P},其中P为业务设计参数集合,p为P的元素,γp表示从集合P中转换出的内存变量元素,函数fp实现p→γp的转换;
定义14定义Rs为由计算序列S生成的内存变量集合,记Rs={γs}={γ|γ=fs(s)∧s∈S},其中S为计算序列,s为S的元素,γs表示从集合S中转换出的内存变量元素,函数fs实现s→γs的转换;
定义15函数M=Rg+Rp+Rs,M为内存变量栈,函数指明了M的组成,其中“+”表示并集运算,即相同的变量在并集运算时相同标识符的变量的值会被新值覆盖。
所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中公式计算引擎,包括:①定义了表达式的操作符及优先级;
②加载操作符及优先级;
③取中序表达中的操作数或变量名并以列表返回,为变量替换时使用;
④计算中序数值表达式的值;
⑤中序表达式转后序表达式;
⑥计算后序表达式的值;
⑦求两个操作符的优先级别;
⑧计算两个操作数的表达式值;
⑨将两数运算的表达式转成word公式表达式形式。
所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中工作序列计算引擎包括:
定义16定义计算步骤s<sk,se,υe,sυ,type,sc>为一个六元组,其中sk为变量标识符,se为变量公式,υe为变量替换后的算术公式;sυ为算术公式运算结果值,sc为运算条件表达式,sc的计算结果决定了下一个参与运算的计算步骤元素的跳转条件,他控制着计算序列的运算逻辑,计算步骤的类型s.type=enum{VAR,EXP,TXT,FUN},VAR表示s.se是一个内存变量,参与计算时可以直接在M中取值;EXP表示s.se是一个由数值常量、内存变量和运算符等组成的变量公式,在参与计算时,首先提取公式中的变量,然后依次在M中取值替换生成算术公式,最后计算算术公式的值作为计算步骤的值;TXT表示s.se是一个嵌入内存变量的文本串,文本串中可以包含数值常量串、内存变量以及它们组成的公式串,参与计算时,文本串中的内存变量将被提取,内存变量由对应的值替换,公式串不参与算术运算;FUN表示s.se是一个自定义函数,表现形式为一个格式化的文本串,串中可以包含数值常量串和内存变量,参与运算时,首先取变量值替换自定义函数串的变量,然后对自定义函数串进行解析,最后在自定义函数库中调用相关函数进行计算;
定义17函数Vc=Gc(SC)计算条件表达式SC的值,SC中可以包含若干数值串、内存变量和条件运算符;
定义18函数Vf=Gf(FS)解析自定义函数串FS,分离函数名和参数,并调用相关的自定义函数计算结果,FS中可以包括若干数值串和内存变量,内存变量根据上下文在内存变量栈M中取值;
定义19定义计算步骤s的类型由一个四元组表示sk<w,x,y,z>,其中w,x,y,z分别代表了VAR,EXP,TXT,FUN类型的计算步骤,
计算步骤计算的过程描述
(1)由定义8、定义16可知:
w.υe=GV(M,w.se)
w.sυ=w.υe
(2)由定义5、定义6、定义4和定义16可知:
Kx=Q(x.se)
x.υe=C(M,x.se,Kx)
x.sυ=Ge(x.υe)
(3)由定义5、定义6和定义16可知:
Ky=Q(y.se)
y.υe=C(M,y.se,Ky)
y.sυ=y.υe
(4)由定义5、定义6、定义4和定义17可知:
Kz=Q(z.se)
z.υe=C(M,z.se,Kz)
z.sυ=Gf(z.υe)
(5)由定义5、定义6、定义4、定义17可知:
Kc=Q(s.sc)
iNext=Gc(C(M,s.sc,Kc))
sNext=S[iNext]
其中iNext为下一个参与运算的步骤元素在计算序列栈中索引;sNext为下一个参与运算的步骤元素。
所述所述步骤6,文档生成引擎:构建内存变量栈,公式计算引擎,工作序列计算引擎,模板标签替换,文档转换与生成,其中文档转换与生成包括对模板与文档的定义:
定义20定义模板为一个二元组T<C,K>,C为模板文档中不变的文字部分,K为模板文档中的变量标识符,K在模板文档上下文中表示相同含义;
定义21定义中间文档为一个二元组W′<C,U>,C为模板中不变的文字部分,U为模板文档变量的在上下文计算后的结果值;
定义22函数Z(K,U)将K替换成U,其中K为文档中的变量,U为模板变量的在上下文计算后的结果值;
定义23函数W=X(W′,Ru)将中间文档转换为目标文档,其中W′为中间文档,W为最终的目标文档,Ru为中间文档向目标文档转换规则。
所述文档转换与生成中还包括计算逻辑的存储定义:
定义24定义集合STO存储了文档生成过程中使用的计算逻辑,记STO={M,S,T,K,K<μ,δ>,Ru},其中变量分别表示:内存变量栈、模板、模板变量、模板变量类型和中间文档向目标文档的转换规则;
定义25操作Get(STO)→T实现从STO中已存储的计算逻辑提供给模板进行处理;
所述文档生成的计算步骤如下:
A、U=Kυ<μυ,δυ>
B、W′<C,U>=Get(STO)→T<C,K>=Get(STO)→T<C,Z(K,U)>
=Get(STO)→T<C,Z(K,Kυ<μυ,δυ>)>
C、μ=GK(C′1),δ=GK(C′2)
D、μυ=GV(M,μ),δυ=GS(S,δ)
E、W′<C,U>=Get(STO)→T<C,Z(GK(C′),Kυ<μυ,δυ>)>
=Get(STO)→T<C,Z(GK(C′),Kυ<GV(M,μ),GS(S,δ)>)>
=Get(STO)→T<C,Z(GK(C′),Kυ<GV(M,GK(C′1)),GS(S,GK(C′2))>)>。
如图1所示,根据以上定义,绘制出模型的整体结构,对模型结构进行分析,方框之内的功能主要目标是完成数据转换、计算序列运算、模板数据填充和文档生成,称之为文档自动生成系统,方框外部的公共数据构造器(Global Creator,GCR)、设计参数构建器(Design Creator,DCR)、计算序列构造器(Sequences Creator)和模板构造器(Template Creator,TCR)是模型的支撑系统。
GCR可看成是外部业务系统的抽象,负责从各业务系统中提取数据构成G集合,为模型运算提供基础数据。DCR可看成是设计系统的抽象。根据配置文件生成标准化的UI程序界面,为用户设计输入提供支持,最后导入设计参数集P参与模型运算。SCR用来编辑和生成工作序列S集合,模型根据S集合表达的计算逻辑进行计算。TCR是主要用来生产基于XML格式的模板文档。
在文档自动生成系统内部,M是变量储存器,主要计算步骤如下:
步骤1数据初始化,构建初始内存变量栈M和计算序列栈S。通过转换函数fg和fp将基础数据和设计数据加载到M中,形式描述为f({G,D})→M。
步骤2启动计算序列栈S运算。S的计算逻辑由其自身决定,计算过程的关键任务是识别和计算步骤公式和条件跳转公式。序列计算过程中,算法根据计算步骤公式变量的需要从M中取值,同时动态更新计算步骤所代表变量的值,并写回到M中,直到所有步骤执行结束。
步骤3模板标签值替换。计算序列运算结束后,M和S中有明确的值。遍历模板提取标签,解析出变量名称,从中查询相应的值替换,生成中间文档。
步骤4目标文档生成。根据目标文档生成的规则,将中间文档格式化成目标文档所要求的格式。
该模型结构描述了文档自动生成的逻辑,定义了文档生成过程中的内部结构及操作,以下将上述操作封装成系统的功能模块,该系统包括系统基础设置、公共数据处理、设计数据处理、工作序列定义和文档生成引擎,每个模块对应的功能如表1所示:
表1文档生成系统功能模块
其中模板以XML文件的形式存在,模板标签包含三种类型:模板变量标签、计算序列结构占位符标签和模板格式控制符标签,其中,
(1)模板变量标签,使用“{$”和“$}”界定标签标识符,如{$f#a$}表示变量f#a,在工作序列计算完成之后,该变量的值可直接从内存栈中读取并替换,在文档中,变量需格式化呈现,引入“#”表示下前,“$”表示上签,如变量f#a在文档中呈现fa。
(2)计算序列结构占位符标签,使用“{”和“}”界定标签标识符,格式为{starIndex-endIndex},它是起始计算步骤号starIndex到结束计算步骤号endIndex执行结果的占位符。
(3)模板格式控制标签,模板XML向Word文件转换的过程中,通过该标签控制输出格式,如:Setfont、Settext、paragraph、Table、Merge、Setcell、Cell、subscript、superscript、Field、Header、Footer等。
其中,公式计算引擎的主要作用是完成通用表达式的识别与运算,如图2所示,表达式计算时具有通用性,不仅能根据表达计算最终的结果,还能识别变量表达式,并将计算的过程格式化输出到最终的Word中呈现。这涉及如下几个方面的问题:(1)能够识别表达式字符串运算逻辑;(2)能够从表达式串中分离变量;(3)能够对替换数值的表达式进行运算;(4)能够对字符串表达式和数值表达式进行形式化表示,公式计算引擎中定义的操作摘要如下:
·OperatorPrority定义了表达式的操作符及操作符优先级;
·LoadOperatorAndPrority加载操作符及优先级字典;
·ValidInOrderExp校验中序表达式是否合法;
·GetInOrderOperands取中序表达中的操作数或变量名,以列表返回,为变量替换时使用;
·CalcInOrder计算中序数值表达式的值;
·InOrderToPostOrder中序表达式转后序表达式;
·CalcPostOrder计算后序数值表达式的值;
·CompareTwoOperatorSPriority求两个操作符的优先级别;
·CalcTwoNum计算两个操作数的表达式值;
·ToWordExpString将两数运算的表达式转车Word公式表达式形式。
如图3所示,工作序列计算引擎的核心是执行工作序列的计算,一个工作序列可以存在着若干个计算序列,每个计算序列包含若干个计算步骤。工作序列计算引擎执行前,所有的公共基础数据和设计业务数据均在内存变量栈中准备好;执行过程中,运算所需的数据根据上下文从内存栈中取值,计算步骤相关的属性值在运算的被更新,计算步骤计算结果更新到内存栈中。
工作序列计算引擎算法执行完成以后,如图4所示,将运算的过程数据保存在当前计算实例的内存变量栈中,程序控制权交给模板数值填充算法。填充算法查找对应的模板XML文件,将内存变量栈中的变量值替换到模板中,生成XML中间文档,程序控制权交给Word文档生成算法,将XML中间文档转换成目标文档。
以下以“钢筋混凝土结构梁外贴钢板加固方法”为例进行应用验证,其参数配置步骤如下:
(1)对加固设计方法中要用到的加固设计行业的现行国家标准和行业标准数据进行初始化;
(2)对加固方法的计算流程进行分析,找出设计过程中用到的变量;
(3)对变量进行分类、识别出哪些变量是在加固设计时与用户进行交互,对这些变量使用界面参数配置工作进行建库,从而设计出加固设计界面;
(4)对计算流程进行规划,把计算过程变成一系列具有逻辑关系的计算步骤,使用工作序列生成工具进行建模;
(5)设计计算书转换所需的XML文档
上述步骤完成之后,接着对加固方法进行调试,调试成功后,就可以通过用户界面生成器产生加固设计界面,获得设计参数,启动工作序列计算自动生成计算书。
为了动态生成用户界面获得加固设计数据还需配置界面参数,加固方法的就算过程是与需要加固的建筑构件的部位相关的,一个建筑构件的多个部位可能需要使用到相同的参数,因此一个加固方法的参数是具有层次的。
加固方法的工作序列配置是一个复杂的过程,梁加固计算工作序列涉及到5个计算序列:梁跨中抗弯、左支座抗弯、左支座抗剪、右支座抗弯、右支座抗剪。
外粘钢板梁加固包含5个计算序列,每个计算序列的结构都出现在计算书中,因此为每个计算序列指定一个模板,L-B-0模板用于转换计算书中的变量表格,表格中的数据来源于加固设计完成后的内存变量栈;L-B-1模板用于转换计算书中的梁跨中抗弯序列。
当然,以上仅是本发明的具体应用范例,对本发明的保护范围不构成任何限制。凡采用等同变换或者等效替换而形成的技术方案,均落在本发明权利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!