一种基于AOV网关键路径查询的异构系统动态功耗优化方法与流程
本发明涉及异构系统低功耗领域,尤其涉及一种基于AOV网关键路径查询的异构系统动态功耗优化方法。
背景技术:
同行业已有一些降低异构系统动态功耗的方法,现有的GPU低功耗优化多是针对单个GPU任务的功耗问题,很少有工作针对CPU-GPU异构系统特点研究整个应用程序的功耗优化。然而在应用程序中存在多个不同类型任务,同时在CUDA编程环境中,主机CPU在调用cudaThreadSynchronize()后就处于空闲状态,这实际上是对计算资源的浪费,虽然GPU的计算能力非常强大,但处理大规模数据集时也是很耗时的,可以将一部分计算任务分配给处于空闲状态的CPU来处理,让CPU与GPU并行工作,势必会减少内核函数的执行时间,进而减少整个程序的执行时间。因此对于一个给定的任务(没有依赖关系的循环迭代),如何在CPU和GPU之间进行任务划分,使得异构系统在满足性能(能量)约束的条件下,取得能量(性能)最优是我们设计的新技术方案的设计初衷。
技术实现要素:
为克服现有技术的不足,在程序中寻找一组非关键任务(在程序运行过程汇总不影响整个程序执行时间的任务)并确定相应CPU或GPU频率调节系数,使得程序在CPU-GPU异构系统中运行时执行时间保持不变且能耗最优,本发明提出一种基于AOV网关键路径查询的异构系统动态功耗优化方法。
本发明的技术方案是这样实现的:
一种基于AOV网关键路径查询的异构系统动态功耗优化方法,包括步骤
S1:从程序中分离出不同类型的任务,将单GPU任务再进行划分至CPU和GPU上同时执行,同时运行的过程描述为任务之间的依赖关系,构造程序运行过程的AOV网络;
S2:对运行过程的AOV网络进行分析,确定关键路径,将非关键路径上的CPU和GPU任务进行频率调节以节省功耗;
S3:根据关键任务执行的时间确定非关键任务可以放松的执行时间范围,从而求解每个任务处理器频率调节幅度以最小化功耗的消耗。
进一步地,步骤S1中所述不同类型的任务包括CPU计算任务、通信任务和GPU计算任务。
本发明的有益效果在于,与现有技术相比,本发明无需中心节点,针对用户任务需求,通过分布式搜索并综合考虑服务节点可用能源与网络通信延迟等问题,提高了服务组合寻优搜索效率,并得到能满足应用服务质量需求的最佳节点组合。
附图说明
图1是本发明一种基于AOV网关键路径查询的异构系统动态功耗优化方法;
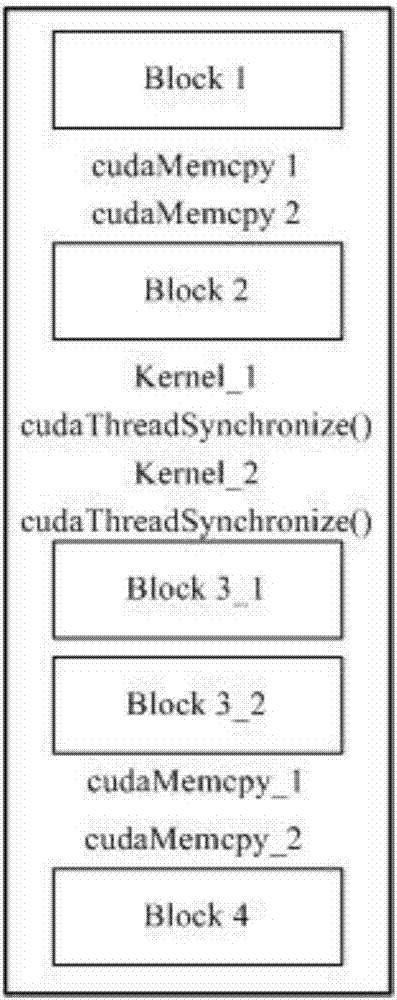
图2是本发明一种基于AOV网关键路径查询的异构系统动态功耗优化方法的一个实施例的典型CUDA程序示意图;
图3是图2的程序任务依赖图;
图4是图3的程序AOV示意图;
图5a-图5f是图4的案例分析图;
图6是图2中的各任务的EST和LST图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参见图1,本发明一种基于AOV网关键路径查询的异构系统动态功耗优化方法,包括步骤
S1:从程序中分离出不同类型的任务,将单GPU任务再进行划分至CPU和GPU上同时执行,同时运行的过程描述为任务之间的依赖关系,构造程序运行过程的AOV网络;
S2:对运行过程的AOV网络进行分析,确定关键路径,将非关键路径上的CPU和GPU任务进行频率调节以节省功耗;
S3:根据关键任务执行的时间确定非关键任务可以放松的执行时间范围,从而求解每个任务处理器频率调节幅度以最小化功耗的消耗。
进一步地,步骤S1中所述不同类型的任务包括CPU计算任务、通信任务和GPU计算任务。
一个典型的CUDA程序如图2所示,假设此时将单个GPU任务划分为2个子任务。Block1,block2,block4表示和GPU任务不相关的CPU任务,将单个GPU任务划分为N个子任务,每个子任务对应一个子Kernel函数,每个子kernel函数结束时需要通过主机调用cudaThreadSynchronize()进行同步,block3_1-block3_N表示将每个子任务分一部分任务交由CPU处理。具体做法是:
步骤1:分析程序中的任务依赖关系建立程序任务依赖图。为了简化问题并不失一般性,假定单个GPU任务划分为2个子任务,每个子任务又进行CPU与GPU的任务划分,其程序任务依赖图G=(V,E)(V表示任务依赖图中节点,E表示任务依赖关系)如图3所示。图中C代表CPU计算任务,T代表数据在CPU与GPU之间进行传输,G代表GPU计算任务。
步骤2:构造AOV网络图。并发执行的任务之间存在资源冲突,遵循仲裁机制:假定若某一时刻任务流中同时存在多个满足先后依赖关系但存在资源冲突的任务,则优先选择任务流编号较小的任务执行。建立资源冲突任务之间的依赖关系。例如图3中,当CPU任务C1执行完成后,满足任务依赖关系的任务包括T1,C2和T2。其中T1和T2同属于通信任务,因此存在资源冲突不能同时执行,根据仲裁机制优先执行T1,因此应在原图的基础上增加T1与T2之间的任务依赖关系。程序依赖任务图扩展为图4。
步骤3:确定程序中各任务的最早开始时间与最迟开始时间。用EST(Mi)表示任务Mi最早开始时间函数,LST(Mi)表示任务Mi最晚开始时间函数,<vj,vi>则表示节点j要先于节点i执行。
最早开始时间:
最迟开始时间:
因此任务Mi最早与最晚开始执行时间EST(Mi)和LST(Mi)可以根据公式(1)和(2)递推得出。
步骤4:判断关键路径。如果任务的最早可能开始时间等于其最晚允许开始时间,则可以判断该任务位于AOV网的关键路径上,其运行时间直接影响整个程序的运行时间,不能进行放松。反之如果任务的最早可能开始时间小于其最晚允许开始时间,则判断该任务位于AOV网的非关键路径上,可以对该任务进行频率调节,适当增加运行时间,降低系统动态能耗。
步骤5:将动态能耗最优问题转变为N元极值问题进行求解。针对非关键节点集合Pi,我们构造一个AOV子网假定AOV子网中有N个非关键的CPU和GPU任务节点,记为其处理器和存储器初始频率为1≤j≤N,进行频率调节后它们的频率分别变为此时各任务的计算时间变为访存时间变为其他任务的时间不变。我们可以根据公式(15)计算出调节后的最早可能开始时间,记为
当时,在一定范围内增大计算操作时间(T′comp),降低处理器运行频率,系统动态能耗归结为N元极值问题:
当时,在一定范围内增大存储操作时间(T′mem),降低存储器访存频率,系统动态能耗归结为N元极值问题:
图5a-图5f给出了实施例程序的分析过程。其中图5a为原始算法流程,共包括6个步骤:首先是对a,b两个数组的初始化,然后调用过程f1和f2分别对a和b进行处理,得到数组c和d。第4行表示函数f3由一个标量α计算出一个数组e;第5行则表示函数f4由a,b两个数组计算出标量结果β;最后一行表示函数f5由β,c,d和e计算出数组g。图5b给出了上述算法的一个CUDA实现,假设f1,f2,f3和f5函数可以被并行化,因此使用Kernel函数实现,分别对应于Kernel1-Kernel4;f4函数不能被并行化,因此仍由CPU完成。Kernel1和Kernel2执行之前需要调用cudaMemcpy将输入数组a和b载入GPU存储器,Kernel4执行结束后需将数组g回存至CPU存储器,为了开发Kernel计算和通信的并行性,隐藏通信开销,CUDA实现中将Kernel1、Kernel2、Kernel3及其对应的通信操作设定为异步模式,而Kernel4使用到了前3个Kernel函数的输出,因此调用Kernel4之前先进行全局的任务流同步操作。图5c给出了构造的任务依赖图,假定各个任务的执行时间如图5d所列,加入了T1到T2,G3到G1和G1到G2的资源依赖边,生成的AOV网络如图5e所示。此时利用公式(1)和(2)可以推算出各个节点的最早可能开始和最迟允许开始时间如图6所示。可以看出,任务C1,T1,T2,G2,S1,G4,T3的最早可能开始时间和最晚允许开始时间相等,他们构成AOV网的关键路径,如图5f中的阴影结点所示。因此系统中可以进行频率调节的非关键任务包括G1,G3和C2。这3个任务可以划分为互不可达的两组,如图5f中的虚线框所示,可以独立进行功耗调节。C2的情况比较简单,它的最早可能和最晚允许开始时间分别为1和13,因此根据公式(3-4)给出的先定条件,C2调节CPU的频率只要不影响S1的最早可能开始时间即可。根据公式(1)可知C2执行时间可以延长为16,因此执行任务C2时,CPU的频率最低可降至原来的1/4,C2的能量消耗降为原来的1/16。对于G1和G3,同理可知对GPU的频率调节不能影响S1的最早可能开始时间。由于G1和G3的初始运行时间都是2,不放假设它们在初始频率下消耗的能量都为E,调节后运行时间变为和根据公式(1),G1和G3任务能量最优的运行时间可表示为
其中,
求解上式可得,时,两者总能量消耗最小为8/9E。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!