基于局部加权回归的室内空气数据预处理方法与流程
本算法能对随时间变化的空气参数(温度,湿度,甲醛浓度,PM2.5浓度,二氧化碳浓度等)中的数据空缺进行填补,并可以对数据中的异常跳变值进行去除,以及可以对数据进行零点偏移的修正。属于特定数据预处理的领域。具体讲,涉及基于局部加权回归的室内空气数据预处理方法。
背景技术:
目前对数据进行预处理的技术方法难易皆具,然而简单的预处理方法难以做到有效,而有效的预处理方法往往比较复杂[1]。本技术预处理的数据对象是室内空气数据:第一,这种数据具有整体上随时间缓慢变动但是每时每刻都有着不同程度的随机噪声的特点(如图1);第二,由于硬件系统具有数据空缺报警功能,故可以确保数据空缺的时长很短;第三,已经具有了修正零点偏移的标定曲线。所以相比于对数据空缺进行填补和零点偏移,本技术的核心是对数据中的跳变异常值进行去除,并且能够保证与人行为变化相关的数据大幅度变动不被识别成异常值被剔除。
在对数据异常值进行剔除的方法中,最常见的是对数据直接使用C4.5决策树进行分类判定[2],但是该算法易将因为人行为变化导致的数据大幅度变动值和异常跳变值一并被分类成异常值;其次CD(Curve Description)法也被用于对异常值的分类[3],此方法以相邻的数值的变化量和变化率为阈值进行判定,然而对于本专利要解决的问题而言,它和决策树法有着相似的缺陷,而且在程序实现上也比决策树法复杂;国外也使用噪声数据过滤法(Filters)识别并剔除异常值,比较典型的是Ensemble Filter(EF)[4]和Iterative-Partitioning Filter(IPF)[5],这两种方法都比较有名,但是都比较复杂,得对其额外设置多个参数[1],这对本技术所面对的问题是没有必要的。
技术实现要素:
为克服现有技术的不足,本发明旨在用简单但有效的方法对室内空气随时间变化的数据进行预处理,包括短时长数据空缺的填补,数据异常跳变值的去除,与此同时保证与人行为变化相关的数据大幅度变动不被识别成异常值,最后进行零点偏移的矫正。本发明采用的技术方案是,基于局部加权回归的室内空气数据预处理方法,首先进行短时长数据空缺的填补,要确保整个数据不存在空缺的0值,然后再进行数据异常跳变值的去除,在保证不再存在针状的数据跳变点时,再进行零点偏移的矫正,即将处理好的数据代入到标定曲线中。
进行数据异常跳变值的去除具体步骤是,使用拟合曲线将有意义的信息拟合出来,并且同时不拟合针状数据跳变和所有的高频噪声,具体选用局部加权回归(Local Weight Regression)进行有用信息的拟合,再用原数据曲线减去拟合曲线得到噪声曲线,解决有用信息对跳变值去除的干扰。
局部加权回归原理具体步骤是,先用一定数目的横轴上的参考点将整个数据等分开来,并以这些点为中心分别求算线局部性回归,在使用最小二乘法求解回归参数时,离中心点越远的数据点所占的权数越小,最后得到这些点的回归数值,然后用插值将这些回归数值点相连,这里使用线性插值即可;
进一步地,对每一个训练数据点,都要使得:
∑iw(i)(y(i)-θTx(i))2 (1)
最小;
其中i是训练数据的个数角标;x指时间轴的时间值;y是目标值;θ是回归方程的系数向量,使用二次回归,故θ是个三维向量;w是高斯权数,表示成:
其中没有上角标的x指的是选定的横轴上的参考点,τ是带宽(bandwidth),τ越大,局部回归的强度越大;
局部加权回归在每个残差平方项之前多一个高斯权,对每个参考点都要求得二次的回归曲线,且曲线参数一定是不同的,对任一个参考点x,都有:
θ=(XTWX)-1XTWy (3)
其中,X是由1,x(i),(x(i))2组成的m维矩阵,称之为设计矩阵(design matrix)m即训练数据数量,X写作:
W是m阶对角矩阵,写作diag(w(1)…w(i)…w(n));y是目标值排成的m阶列向量,记作(y(1)…y(i)…y(n))T;最终得到的θ是一个3×3的矩阵,取θ中第一列中的从上到下三个元素分别作为二次回归曲线中的常数项前系数,一次项前系数和二次项前系数,对于每一个参考点xck(j),代回回归曲线都有其对应的回归值yck(j),其中j是参考点数据的个数角标,这样便形成一个回归点(xck(j),yck(j));
将相邻的回归点进行线性插值就得到对整个数据曲线进行回归的回归曲线。
使用局部加权回归识别并剔除跳变值的流程:
a.将原数据曲线进行局部加权回归,生成拟合曲线;
b.将原数据减去拟合曲线得到残差曲线;
c.求残差曲线的平均值和标准差;
d.遍历所有的残差数据,利用拉依达准则,挑选出所有超出限制的数据:
e.获取d中选中的数据的标号,并将对应标号中的原数据替换成跳变数据两端的正常数据之间的插值,达到平滑的目的。
本发明的特点及有益效果是:
本发明具有原理简单,计算快速并效果显著的特点。该发明对室内空气质量(IAQ)随时间的数据有着良好的有益效果:本发明能够有效的从原数据中分离出噪声;能够通过分析噪声特点来对数据中的跳变异常值进行去除,并且能够保证与人行为变化相关的数据大幅度变动不被识别成异常值被剔除。
附图说明:
图1:对一间办公室使用传感器的实测室内空气数据,横轴是时间,以1秒为单位;纵轴是相应的数值强度。图中1-2和1-3都有针状的数据跳变。
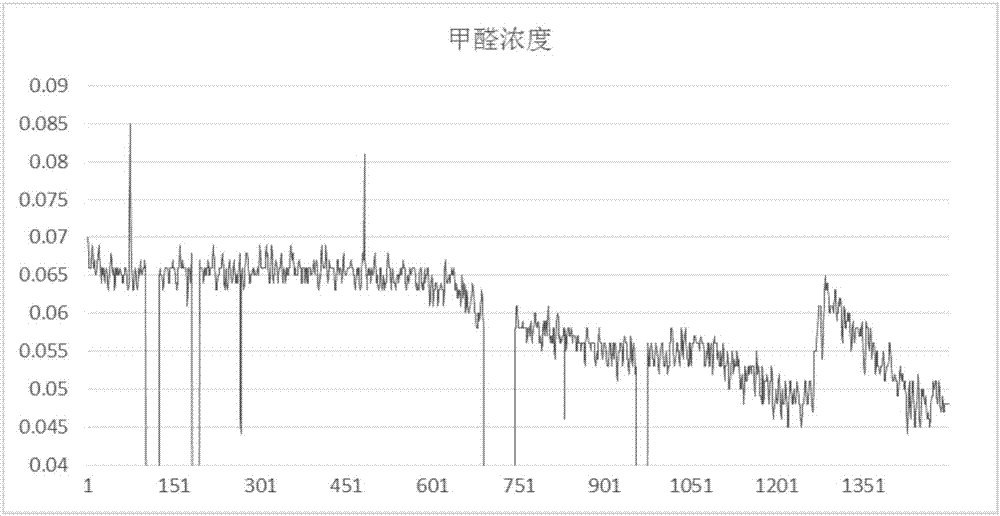
图2:带有数据空缺和数据跳变的实测甲醛随时间的变化数据曲线。
图3数据平滑流程图。
图4:数据空缺被插值的实测甲醛随时间的变化数据曲线。
图5:对图1曲线进行局部加权回归后的实测甲醛随时间的变化数据拟合曲线
图6:甲醛随时间的变化数据的残差曲线,可见数据跳变在其中,且不含有任何有用信息。
图7:数据跳变被平滑的实测甲醛随时间的变化数据曲线,可见有用信息都被保留了下来。
具体实施方式
为了防止算法的复杂以及误差的放大,对可能带有短时间数据空缺的室内空气数据进行预处理时,首先进行短时长数据空缺的填补,要确保整个数据不存在空缺的0值,然后再进行数据异常跳变值的去除,在保证不再存在针状的数据跳变点时,再进行零点偏移的矫正,即将处理好的数据代入到标定曲线中。
1)在原始数据中,凡是空缺值都已经用0代替。
首先选择n个数值组成的时序数据,这里n需要是容易被整除的数,比如2000,这为了能够有效的进行数据跳变值的去除。然后将原始数据进行空缺值的填补,并根据(三)中提到的数据性质,在这里选用对数据进行插值,将结果替换掉对应位置的0值。
2)确保整个数据中没有0值时,开始对跳变值进行去除。
这里注意到不能将因为人行为变化的数据大幅度变动去除,以带有数据空缺,数据跳变和因为人行为变化的数据大幅度变动的实测甲醛数据为例(如图2),发现数据跳变和因为人行为变化的数据变动有着很大的区别:
如图2中右侧虚线曲线部分,此处对应的时刻,办公室门被打开,使得对门的实验室里面的实验甲醛气体部分涌入办公室,导致了室内甲醛浓度升高,这属于典型的人行为变化。这种甲醛浓度的变化不能被当做异常值识别并剔除。其次,左侧的实线红圈的部分是数据缺失,为0值。
在这里,不适宜直接将数据进行异常值的剔除,一方面数据整体走势就呈现出缓慢的变动,从左侧的0.07变到右侧的0.047,另一方面就是右侧虚线红圈的曲线很容易被当作异常值,这些都是数据曲线中的有意义的信息。因此有必要将数据曲线中有意义的信息保留,所以适合的策略就是使用拟合曲线将有意义的信息拟合出来,并且同时不拟合针状数据跳变和所有的高频噪声,这里选用局部加权回归(Local Weight Regression)进行有用信息的拟合,再用原数据曲线减去拟合曲线得到噪声曲线,便可以完全解决有用信息对跳变值去除的干扰。
3)局部加权回归原理
局部加权回归是一般线性回归的改进版,能够克服后者欠拟合或过拟合的缺陷。它的步骤是先用一定数目的横轴上的参考点将整个数据等分开来,并以这些点为中心分别求算线局部性回归,在使用最小二乘法求解回归参数时,离中心点越远的数据点所占的权数越小。最后可以得到这些点的回归数值,然后用插值将这些回归数值点相连,这里使用线性插值即可。
对每一个训练数据点,都要使得:
∑iw(i)(y(i)-θTx(i))2 (1)
最小。
其中i是训练数据的个数角标;x是特征值,在本文中即指时间轴的时间值;y是目标值,本文中即甲醛浓度值;θ是回归方程的系数向量,本方法使用二次回归,故θ是个三维向量;w是高斯权数,表示成:
其中没有上角标的x指的是选定的横轴上的参考点,τ是带宽(bandwidth),τ越大,局部回归的强度越大。
局部加权回归在每个残差平方项之前多一个高斯权,这就会极大削弱离参考点比较远的数据对拟合的影响,进而达到局部回归的目的。对每个参考点都要求得二次的回归曲线,且曲线参数一定是不同的,对任一个参考点x,都有:
θ=(XTWX)-1XTWy (3)
其中,X是由1,x(i),(x(i))2组成的m维矩阵,称之为设计矩阵(design matrix)m即训练数据数量,X写作(此时为了求二次回归曲线,所以矩阵只有三列,若求n次回归曲线,矩阵就有n+1列):
W是m阶对角矩阵,写作diag(w(1)…w(i)…w(n));y是目标值排成的m阶列向量,记作(y(1)…y(i)…y(n))T;最终得到的θ是一个3×3的矩阵,取θ中第一列中的从上到下三个元素分别作为二次回归曲线中的常数项前系数,一次项前系数和二次项前系数。对于每一个参考点xck(j),代回回归曲线都有其对应的回归值yck(j),其中j是参考点数据的个数角标,这样便形成一个回归点(xck(j),yck(j))。
将相邻的回归点进行线性插值就可以比较准确的得到对整个数据曲线进行回归的回归曲线,这样的曲线能够保留所有的有用信息。
4)使用局部加权回归识别并剔除跳变值的流程
a.将原数据曲线进行局部加权回归,生成拟合曲线。
b.将原数据减去拟合曲线得到残差曲线。
c.求残差曲线的平均值和标准差。
d.遍历所有的残差数据,利用拉依达准则,挑选出所有超出限制的数据:
拉依达准则规定:所有超出三倍标准差范围之内的数据都被剔除。即:去掉所有的x,若x满足|x-μ|<3σ。因为一次性处理的数据量较大,远超过了拉依达准则的使用数据下限:100个数据。所以这里采取较为简便的拉依达准则。
e.获取d中选中的数据的标号,并将对应标号中的原数据(跳变数据)替换成跳变数据两端的正常数据之间的插值,达到平滑的目的。
5)在用局部加权回归识别并剔除跳变值后,将得到的处理后数据代入到标定的回归方程中,进而得到完整的预处理结果数据。
1)自定义函数的命名,输入变量和输出变量。
输入变量有两个:一个为“原始数据”,从excel表格中导入,以列向量的形式存在;另一个为“对时间维度的分割间隔数”。
输出变量有一个:为“经过异常数据平滑算法之后的结果数据”,并填回excel表格。
2)将原数据进行基于局部加权回归的室内空气数据异常值平滑的流程(原数据中不能有
为0的空缺值),如图3所示。
这里以被填补之后的实测甲醛随时间的变化数据曲线为实例(见图4):取含有1500个数据的原始数据向量,“对时间维度的分割间隔数”取50;图5给出了对图4曲线的局部加权回归的拟合曲线,由此可见,所有的有用信息都被保留了下来,图6给出了图4数据曲线减去图5数据曲线得到的残差曲线,也称噪声曲线,由此可见,针状的数据跳变都被从原数据中分离了出来,将残差曲线根据拉依达准则判定,去掉并用插值替代不符合判定的跳变数据,再将其和图5的拟合曲线相加,得到经过跳变值平滑之后的数据曲线(如图7)。
参考文献:
[1]Salvador García,Julian Luengo,Tutorial on practical tips of the most influential data preprocessing algorithms in data mining.Knowledge-Based Systems,2016;98:1-29..
[2]J.R.Quinlan,C4.5:Programs for Machine Learning,Morgan Kaufmann Pub-lishers Inc.,1993.[3]Hao Zhou;Lifeng Qiao,Ph.D.;Yi Jiang,Ph.D.;Hejiang Sun,Ph.D.;Qingyan Chen,Ph.D.Recognition of air-conditioner operation from indoor air temperature and relative humidity by a data mining approach.Energy and Buildings,2016;111:233-241.
[4]C.E.Brodley,M.A.Friedl,Identifying mislabeled training data,J.Artif.Intell.Res.1999;11:131–167.
[5]T.M.Khoshgoftaar,P.Rebours,Improving software quality prediction by noise filtering techniques,J.Comput.Sci.Technol.2007;22:387–396。
- 还没有人留言评论。精彩留言会获得点赞!