一种精确的注塑机选型方法与流程
本发明涉及大数据信息推荐领域,尤其涉及到注塑机电商平台中的信息流推荐方法和注塑机选型服务平台的选型方法,具体涉及一种精确的注塑机选型方法。
背景技术:
塑料超过了钢铁,成为全世界的第一大工业材料,而我国如今成为全球塑料消费量级最大的国家,规模达2.6万亿。但是,由于注塑机器械的智能化正处于起步阶段,整个注塑行业的信息化水平较低和行业资源缺乏统一的规划,导致注塑机上下游产业出现人力成本高、效率低、产品附加值低等问题,严重制约了中国制造2025的整体发展。
当前,传统注塑行业对注塑机的选型还停留在人工主观分析,即消耗人员和技术人员当面和客户沟通,根据客户需求通过人为的经验和主观分析从而给客户进行注塑机的选型并进行销售。
这样的注塑机选型方式不仅效率低、耗费大量的资源(人力、物力和时间资源),同时没办法根据用户的个性化需求进行个性化注塑机的选型,严重制约了传统注塑行业和中国制造2025的整体发展。
技术实现要素:
本发明的目的是为了解决在传统注塑行业在注塑机选型上现有技术中的上述缺陷,提供一种精确的注塑机选型方法。
本发明的目的可以通过采取如下技术方案达到:
一种精确的注塑机选型方法,所述方法包括以下步骤:
将终端采集的用户的大量关于注塑机选型和购买行为和数据发送至服务器端;
将采集到的注塑机用户数据进行除噪、过滤;
将采集到的注塑机用户数据进行归一化处理;
对注塑机用户数据进行选型特征偏好提取;
在服务器端通过基于Spark大数据平台执行基于皮尔逊相关系数和最小二乘法的注塑机选型方法进行个性化的注塑机选型;
从服务器端返回注塑机选型结果至终端并显示。
进一步地,所述的将采集到的注塑机用户数据进行除噪、过滤的具体过程包括:
以注塑机用户为键,对应用户关于注塑机选型系统和商城行为记录数为值,进行统计;
将注塑机用户提取出来,u的大小代表数据记录的用户个数,利用Spark Mllib的user.filter(line=>line.contains(a))函数方法将原始数据中的所有关于注塑机用户a的记录筛选出来,并构造关于用户a的键值对;
移除注塑机行为数据记录中的噪声数据,所述噪声数据包括用户的恶意刷单、失误操作。
进一步地,所述的将采集到的注塑机用户数据进行归一化处理额具体过程包括:
采用Z-score标准化方法对不同注塑机选型行为和注塑机商城购买行为的数值取值进行归一化处理,具体方法为:
其中,u为所有样本数据的均值,σ为所有样本数据的标准差。
进一步地,所述的对注塑机用户数据进行选型特征偏好提取的具体过程包括:
将原始数据中的所有关于用户a的注塑机行为记录筛选出来,并构造关于用户a的键值对;
将用户选型参数中选择、浏览、收藏、加购物车、与购买的基础评分分别设置为1、2、3、4、5;
对用户的关于注塑机行为基础评分分别在其基础上加上不同适当权值分数加成,最后得到所有与用户a相关注塑机商品的评价;
循环上述步骤流程,将其他剩余用户的内容提取出来。
进一步地,所述的在服务器端通过基于Spark大数据平台执行基于皮尔逊相关系数和最小二乘法的注塑机选型方法进行个性化的注塑机选型的具体过程包括:
采用皮尔逊相关系数计算注塑机用户之间的相似度;
描述用户对注塑机选型需求问题;
采用交替最小二乘法预测用户的注塑机选型需求;
在Spark大数据平台实现基于采用交替最小二乘法预测用户的注塑机选型需求。
进一步地,所述的采用皮尔逊相关系数计算注塑机用户之间的相似度的具体过程如下:
利用两个注塑机用户之间的协方差和标准差计算皮尔逊相关系数:
其中,Cov(Xuser1,Xuser2)代表两个注塑机用户之间的协方差,σXuser1和σXuser2分别代表两个注塑机用户的标准差;
若需要对样本的协方差和标准差进行估算,可得到样本相关系数,即样本皮尔逊系数:
其中:
是Xi样本的标准分数,是Yi样本的标准分数;
是Xi的样本平均数,是Yi的样本平均数;
σx是Xi的样本标准差,σy是Yi的样本标准差。
进一步地,所述的描述用户对注塑机选型需求问题的具体过程如下:
用户u对商品i的兴趣偏好可以表示为:
其中Xu,k是用户u的兴趣和第k个隐类的关系,而Yi,k是第i个物品和第k个隐类直接的关系;
求解X和Y的过程可以转化为求损失函数最小的问题:
其中λ是正则化项的系数,式中右边两项的引入是为了防止过拟合。
进一步地,所述的采用交替最小二乘法预测用户的注塑机选型需求的具体过程如下:
利用最小二乘法求解X,然后固定X,求解Y,如此交替往复直至收敛,即所谓交替最小二乘法;
先固定Y,将Y带入损失函数L(X,Y)并对Xu求偏导,令导数=0,得到:
Xu=(YTY+λI)-1YTru,
同理固定X,可得:
Yu=(XTX+λI)-1XTri,
迭代步骤,首先随机选取Y,利用固定Y的公式更新得到X,然后利
用固定X的公式更新Y,直到均方根误差很小或达到迭代次数:
进一步地,所述的在Spark大数据平台实现基于采用交替最小二乘法预测用户的注塑机选型需求具体过程如下:
定义参数rank:模型中隐语义因子的个数;
定义参数iterations:迭代的次数,所述参数iterations的取值范围为:10-20;
定义参数lambda:惩罚函数的因数,是ALS的正则化参数,所述参数lambda的取值范围为:0.005-0.02;
通过调整上述参数,从而优化注塑机商品的选型算法,使注塑机选型结果的均方差逐渐变小。
进一步地,所述的在Spark大数据平台实现基于采用交替最小二乘法预测用户的注塑机选型需求在Spark MLlib中实现步骤如下:
使用ALS训练的注塑机行为数据通过函数方法ALS.train()建立注塑机选型模型;
通过model.predict()方法使用注塑机选型模型对用户对注塑机进行预测评分,得到预测评分的数据集;
使用ratings.map{case Rating(user,item,rate)}方法将真实注塑机评分数据集与注塑机预测评分数据集进行合并;
利用ratesAndPreds.map()计算均方差;
注塑机选型的结果可以以用户id为key,结果为value存入hbase中;
使用predictions.collect.sortB()对注塑机预测选型的结果按预测的评分排序;
对注塑机预测结果按用户进行分组,然后合并选型结果。
本发明相对于现有技术具有如下的优点及效果:
1、本发明运用皮尔逊相关系数聚类算法计算用户的相似度,有效提高了用户相似度的准确性,同时用户的注塑机需求挖掘能力强,不但保留了用户的感兴趣的注塑机,还能通过用户在注塑选型和注塑商城过程中产生的行为数据挖掘潜在注塑机需求。
2、本发明运用交替最小二乘法计算用户对注塑机的评分和最小均方误差,从而对注塑机选型进行有效的预测,大大提高的预测的准确性和有效性。
3、本发明结合运用Spark并行计算框架,结合当前大数据趋势与技术特点,大大提高注塑机选型的选型效率。
附图说明
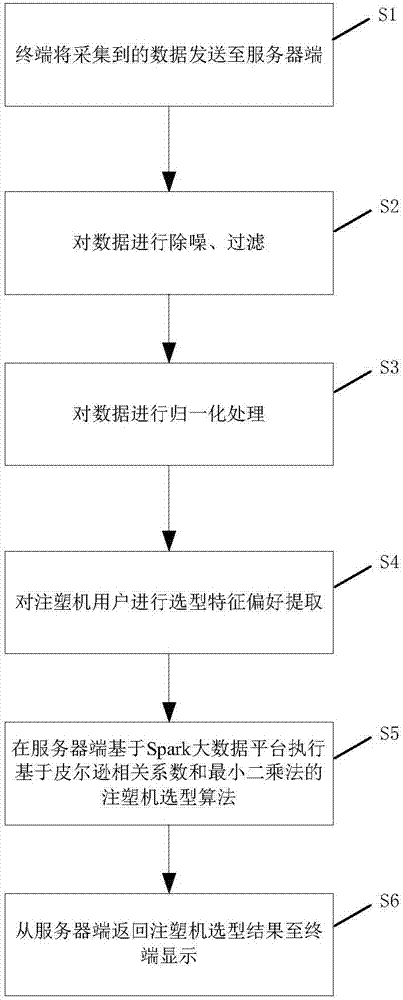
图1是本发明公开的精确的注塑机选型方法的原理图;
图2是本发明公开的精确的注塑机选型方法的流程步骤图;
图3是本发明中基于皮尔逊相关系数和最小二乘法的注塑机选型算法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
本实施例公开了一种基于皮尔逊系数和最小二乘法的精确的注塑机选型方法,流程步骤图参照附图2所示,由附图2可知,该精确的注塑机选型方法具体包括以下步骤:
S1、将终端采集的用户的大量关于注塑机选型和购买的行为数据发送至服务器端;
S2、将采集到的注塑机用户数据中噪声数据进行除噪、过滤;
具体实施方式中,所述的将采集到的注塑机用户数据进行除噪、过滤具体为:
以注塑机用户为键,对应用户关于注塑机选型系统和商城行为记录数为值,进行统计;将注塑机用户提取出来,u的大小代表数据记录的用户个数;利用user.filter(line=>line.contains(a))函数方法将原始数据中的所有关于注塑机用户a的记录筛选出来,并构造关于用户a的键值对;
用户的个人数据和行为数据是在用户使用注塑选型系统和注塑商城的过程中产生的,可能包含大量噪声数据,比如用户的恶意刷单、失误操作等,通过注塑机行为数据记录中的噪声数据进行移除,可以使我们的分析更加精确,避免受到注塑机行为数据噪声的干扰。经过实验分析,将除噪的阈值设为50。
S3、将采集到的注塑机用户数据进行归一化处理;
具体实施方式中,所述的将采集到的注塑机用户数据进行归一化处理具体为:
采用Z-score标准化方法对不同注塑机选型行为和注塑机商城购买行为的数值取值进行归一化处理,具体方法为:
其中,u为所有样本数据的均值,σ为所有样本数据的标准差。
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,能有效将不同注塑机选型行为和注塑机商城购买行为的数据进行归一化。
S4、对注塑机用户数据进行选型特征偏好提取;
具体实施方式中,所述的对注塑机用户数据进行选型特征偏好提取具体为:
将原始数据中的所有关于用户a的注塑机行为记录筛选出来,并构造关于用户a的键值对;
将用户选型参数中选择、浏览、收藏、加购物车、与购买的基础评分分别设置为1、2、3、4、5;
对用户的关于注塑机行为基础评分分别在其基础上加上不同适当权值分数加成,最后得到所有与用户a相关注塑机商品的评价(喜好程度);
循环上述步骤流程,将其他剩余用户的内容提取出来。
S5、在服务端的Spark大数据平台执行基于皮尔逊相关系数和最小二乘法的注塑机选型算法;
具体实施方式中,所述的在服务端的Spark大数据平台执行基于皮尔逊相关系数和最小二乘法的注塑机选型算法包括:
S501、采用皮尔逊相关系数计算注塑机用户之间的相似度。
为了更好的度量两个随机变量的相关程度,引入了皮尔逊相关系数:利用两个注塑机用户之间的协方差和标准差计算皮尔逊系数:
其中,Cov(Xuser1,Xuser2)代表两个注塑机用户之间的协方差,σXuser1和σXuser2分别代表两个注塑机用户的标准差。
容易得出,皮尔逊系数是一个介于-1和1之间的值,当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
若需要对样本的协方差和标准差进行估算,可得到样本相关系数,即样本皮尔逊系数:
其中:
是Xi样本的标准分数,是Yi样本的标准分数;
是Xi的样本平均数,是Yi的样本平均数;
σx是Xi的样本标准差,σy是Yi的样本标准差。
S502、描述用户对注塑机选型需求问题:用户u对注塑机i的兴趣偏好可以表示为:
其中Xu,k是用户u的兴趣和第k个隐类的关系,而Yi,k是第i个物品和第k个隐类直接的关系。
求解X和Y的过程可以转化为求损失函数最小的问题:
其中λ是正则化项的系数,式中右边两项的引入是为了防止过拟合。
S503、采用交替最小二乘法预测用户的注塑机选型需求,具体为:利用最小二乘法求解X,然后固定X,求解Y,如此交替往复直至收敛,即所谓交替最小二乘法。
先固定Y,将Y带入损失函数L(X,Y)并对Xu求偏导,令导数=0,得到:
Xu=(YTY+λI)-1YTru
同理固定X,可得:
Yu=(XTX+λI)-1XTri
迭代步骤,首先随机选取Y,利用固定Y的公式更新得到X,然后利
用固定X的公式更新Y,直到均方根误差很小或达到迭代次数:
S504、在Spark大数据平台实现基于采用交替最小二乘法预测用户的注塑机选型需求:
rank:模型中隐语义因子的个数;
iterations:迭代的次数,推荐值:10-20;
lambda:惩罚函数的因数,是ALS的正则化参数,推荐值:0.01。
通过调整上述参数,从而优化注塑机商品的选型算法,使注塑机选型结果的均方差逐渐变小。在Spark MLlib中实现步骤如下:
使用ALS训练的注塑机行为数据通过函数方法ALS.train()建立注塑机选型模型;
通过model.predict()方法使用注塑机选型模型对用户对注塑机进行预测评分,得到预测评分的数据集;
使用ratings.map{case Rating(user,item,rate)}方法将真实注塑机评分数据集与注塑机预测评分数据集进行合并;
利用ratesAndPreds.map()计算均方差;
注塑机选型的结果可以以用户id为key,结果为value存入hbase中;
使用predictions.collect.sortB()对注塑机预测选型的结果按预测的评分排序
对注塑机预测结果按用户进行分组,然后合并选型结果。
S6、从服务器端返回注塑机选型结果至终端并显示。
实施例二
本实施例将一种基于皮尔逊相关系数和最小二乘法的精确注塑机选型方法应用于具体注塑机选型系统。用Android设备采集用户在使用注塑机时的行为数据和个人信息数据。
附图2给出了该注塑机选型方法进行注塑机选型的流程图,说明整个注塑机选型过程的步骤,而附图3是本发明提出的注塑机选型方法的算法流程图,为了具体介绍整个定位实施通过以下实现进行描述:
步骤S1、将Andorid终端采集到的用户关于注塑机选型行为和个人信息数据发送至服务器端。
S2、将采集到的注塑机用户数据进行除噪、过滤;
S3、将采集到的注塑机用户数据进行归一化处理;
S4、对注塑机用户数据进行选型特征偏好提取;
S5、在服务器端通过基于Spark大数据平台执行基于皮尔逊相关系数和最小二乘法的注塑机选型方法进行个性化的注塑机选型;
S501、采用皮尔逊相关系数计算注塑机用户之间的相似度。
为了更好的度量两个随机变量的相关程度,引入了皮尔逊相关系数:利用两个注塑机用户之间的协方差和标准差计算皮尔逊系数:
其中,Cov(Xuser1,Xuser2)代表两个注塑机用户之间的协方差,σXuser1和σXuser2分别代表两个注塑机用户的标准差。
容易得出,皮尔逊系数是一个介于-1和1之间的值,当两个变量的线性关系增强时,相关系数趋于1或-1;当一个变量增大,另一个变量也增大时,表明它们之间是正相关的,相关系数大于0;如果一个变量增大,另一个变量却减小,表明它们之间是负相关的,相关系数小于0;如果相关系数等于0,表明它们之间不存在线性相关关系。
若需要对样本的协方差和标准差进行估算,可得到样本相关系数,即样本皮尔逊系数:
其中:
是Xi样本的标准分数,是Yi样本的标准分数;
是Xi的样本平均数,是Yi的样本平均数;
σx是Xi的样本标准差,σy是Yi的样本标准差。
S502、描述用户对注塑机选型需求问题:用户u对注塑机i的兴趣偏好可以表示为:
其中Xu,k是用户u的兴趣和第k个隐类的关系,而Yi,k是第i个物品和第k个隐类直接的关系。
求解X和Y的过程可以转化为求损失函数最小的问题:
其中λ是正则化项的系数,式中右边两项的引入是为了防止过拟合。
S503、采用交替最小二乘法预测用户的注塑机选型需求,具体为:利用最小二乘法求解X,然后固定X,求解Y,如此交替往复直至收敛,即所谓交替最小二乘法。
先固定Y,将Y带入损失函数L(X,Y)并对Xu求偏导,令导数=0,得到:
Xu=(YTY+λI)-1YTru
同理固定X,可得:
Yu=(XTX+λI)-1XTri
迭代步骤,首先随机选取Y,利用固定Y的公式更新得到X,然后利
用固定X的公式更新Y,直到均方根误差很小或达到迭代次数:
S504、在Spark大数据平台实现基于采用交替最小二乘法预测用户的注塑机选型需求:
rank:模型中隐语义因子的个数;
iterations:迭代的次数,推荐值:10-20;
lambda:惩罚函数的因数,是ALS的正则化参数,推荐值:0.01。
通过调整上述参数,从而优化注塑机商品的选型算法,使注塑机选型结果的均方差逐渐变小。在Spark MLlib中实现步骤如下:
使用ALS训练的注塑机行为数据通过函数方法ALS.train()建立注塑机选型模型;
通过model.predict()方法使用注塑机选型模型对用户对注塑机进行预测评分,得到预测评分的数据集;
使用ratings.map{case Rating(user,item,rate)}方法将真实注塑机评分数据集与注塑机预测评分数据集进行合并;
利用ratesAndPreds.map()计算均方差;
注塑机选型的结果可以以用户id为key,结果为value存入hbase中;
使用predictions.collect.sortB()对注塑机预测选型的结果按预测的评分排序
对注塑机预测结果按用户进行分组,然后合并选型结果。
S6、从服务器端返回注塑机选型结果至Android终端并显示。
至此实现了注塑机选型的整个过程。
综上所述,该实施例是采用注塑机选型系统工作流程和基于皮尔逊相关系数和最小二乘法的注塑机选型算法执行流程结合的方式全面地描述实施例中注塑机选型的过程。该方法利用皮尔逊相关系数和最小二乘法对注塑机选型进行精确的个性化选型,不仅提高了注塑机选型的匹配效率、节省选型成本,同时实现了根据不同用户对注塑机的不同需求进行个性化注塑机选型。将传统注塑行业与当今互联网和大数据紧密联系在一起,为传统注塑机下游企业在销售、采购、交易决策、后续增值服务等整个产业链条方面提供了有力的支持。同时基于皮尔逊系数和最小二乘法的大数据注塑机选型方法将会使整个注塑行业从产品制造往产品服务转型,提升行业的信息化智能化水平,为注塑机制造行业提供了新的发展点。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!