基于Linux系统实现外设数据高速传输与处理的方法与流程
本发明涉及数据采集领域,尤其linux系统中的数据采集领域,具体是指一种基于linux系统实现外设数据高速传输与处理的方法。
背景技术:
随着时代的发展,科技的进步,在数据采集方面,特别是基因测序方面,对计算机外设的数据的高速传输与处理提出了新的要求。目前常规的办法已无法满足科研需求。
目前在linux下对计算机外设数据的高速传输与处理有三种通用方法。
用dsp技术:外设将数据采集到后放入dsp(digitalsignalprocess)模块进行预处理,使数据变小,然后再将数据通过dma(directmemoryaccess)方式传入内核。内核再做进一步处理或将数据通过拷贝的方式送入应用层。这种方式无法保证采集数据的完整性,无法在硬件层对数据做复杂处理。
用fpga+dsp技术:所述fpga即为field-programmablegatearray,且外设将采集到的数据先经过fpga做定制化处理后,再将数据传入dsp,做进一步的处理,然后将数据通过dma技术加中断的方式将数据送入内核,内核再做进一步处理或将数据通过拷贝的方式送入应用层。这种方式,效率较高,成本也非常高。
fgpg处理:在外设模块的fpga中加一个fifo。先将采集的数据放入fifo中做缓存,待fgpg将数据逐步送入内核后,再做下一次传输。此方法无法实现快速实时采集与处理。
msi中断即为messagesignaledinterrupt,msi出现在pci2.2和pcie接口的规范中,是一种内部中断信号机制。传统的中断都有专门的中断pin,当中断信号产生时,中断pin电平产生变化(一般是拉低)。intx就是传统的外部中断触发机制,它使用专门的通道来产生控制信息。然而pcie并没有多根独立的中断pin,它使用特殊的信号来模拟中断pin的置位和复位。msi允许设备向一段指定的mmio(memorymappingi/o即内存映射)地址空间写一小段数据,然后chipset以此产生相应的中断给cpu。
技术实现要素:
本发明的目的是提供一种解决目前linux系统中外设数据传输速率不够高、处理不够快、被传输的数据完整度无法保证的问题的基于linux系统实现外设数据高速传输与处理的方法。
为了实现上述目的,本发明的基于linux系统实现外设数据高速传输与处理的方法具体如下:
该基于linux系统实现外设数据高速传输与处理的方法,其主要特点是,linux系统包括linux内核、gpu、cpu和内存,所述的linux内核包括一kgpu模块,且该linux系统通过外设的接口连接所述的外设,该接口具有块式dma传输能力和msi虚拟中断能力,所述的外设设置有现场可编程门阵列fpga,且所述的方法包括以下步骤:
(1)linux系统对其物理内存以及其连接的外设进行初始化;
(2)所述的外设采集数据并通知所述的现场可编程门阵列fpga对采集到的数据进行预处理;
(3)所述的现场可编程门阵列fpga完成对接收到的数据的预处理,并将预处理后的数据通过块式dma传输加msi中断的方式发送给linux系统;
(4)linux系统中的cpu接收到该msi中断,并通知所述的gpu对该linux系统接收到的数据进行相应处理;
(5)所述的gpu完成数据的转换处理,并通知所述的cpu,由linux内核进一步处理经gpu转换处理的数据,或由linux系统的应用层直接处理经过gpu转换处理的数据。
较佳地,所述的fpga的接口为一pcie接口。
较佳地,所述的步骤(1)中linux系统对该linux系统连接的外设进行初始化具体为:
linux系统对设置有现场可编程门阵列fpga的外设进行初始化,并通过所述的接口将该外设进行dma传输的物理目的地址发送给所述的外设。
较佳地,所述的步骤(3)中现场可编程门阵列fpga完成对接收到的数据的预处理,并将预处理后的数据通过块式dma传输加msi中断的方式发送给linux系统具体为:
所述的现场可编程门阵列fpga将经预处理后的数据通过dma传输加msi中断的方式发送给linux系统中的内存。
较佳地,所述的步骤(4)中cpu接收到该msi中断,并通知所述的gpu对该linux系统接收到的数据进行相应处理具体为:
所述的cpu收到该msi中断,并通过所述的kgpu模块通知所述的gpu对该linux系统接收到的数据进行相应处理。
较佳地,所述的步骤(5)的具体步骤为:
(5.1)所述的gpu完成数据的转换处理,并通过所述的kgpu模块通知所述的cpu该次数据的转换处理已完成;
(5.2)由所述的linux内核进一步处理经所述的gpu转换处理的数据,或所述的cpu通过所述的linux内核与应用层共享内存的方式,由该linux系统的应用层直接处理经过所述的gpu转换处理的数据。
较佳地,所述的步骤(1)前还有一步骤:
(1.0)所述的linux系统启动前,需对linux系统进行定制,预留大块物理内存以满足所述的现场可编程门阵列fpga和gpu的使用需求。
采用该种基于linux系统实现外设数据高速传输与处理的方法,由于其使用fpga+cpu+gpu协同合作,使数据在外设被采集后即可通过fpga进行预处理,并在使用gpu对被采集的数据进行相应处理后,可通过linux内核直接对数据进行进一步的处理,或通过内核与应用层共享内存的方式,使linux的应用层直接对数据进行进一步的处理,整个过程能够保证被采集的数据完整性,同时可以在硬件层对数据进行较为复杂的处理,经济实用、效率高、成本低,适合数据进行高速传输与处理。
附图说明
图1为本发明的基于linux系统实现外设数据高速传输与处理的方法的高速传输流程图。
图2为本发明的基于linux系统实现外设数据高速传输与处理的方法的一种具体实施例中外设数据的传输流程图。
具体实施方式
为了能够更清楚地描述本发明的技术内容,下面结合具体实施例来进行进一步的描述。
该基于linux系统实现外设数据高速传输与处理的方法,其主要特点是,linux系统包括linux内核、gpu、cpu和内存,所述的linux内核包括一kgpu模块,且该linux系统通过外设的接口连接所述的外设,该接口具有块式dma传输能力和msi虚拟中断能力,所述的外设设置有现场可编程门阵列fpga,且所述的方法包括以下步骤:
(1)linux系统对其物理内存以及其连接的外设进行初始化;
(2)所述的外设采集数据并通知所述的现场可编程门阵列fpga对采集到的数据进行预处理;
(3)所述的现场可编程门阵列fpga完成对接收到的数据的预处理,并将预处理后的数据通过块式dma传输加msi中断的方式发送给linux系统;
(4)linux系统中的cpu接收到该msi中断,并通知所述的gpu对该linux系统接收到的数据进行相应处理;
(5)所述的gpu完成数据的转换处理,并通知所述的cpu,由linux内核进一步处理经gpu转换处理的数据,或由linux系统的应用层直接处理经过gpu转换处理的数据。
所述的fpga的接口为一pcie接口。
所述的步骤(1)中linux系统对该linux系统连接的外设进行初始化具体为:
linux系统对设置有现场可编程门阵列fpga的外设进行初始化,并通过所述的接口将该外设进行dma传输的物理目的地址发送给所述的外设。
所述的步骤(3)中现场可编程门阵列fpga完成对接收到的数据的预处理,并将预处理后的数据通过块式dma传输加msi中断的方式发送给linux系统具体为:
所述的现场可编程门阵列fpga将经预处理后的数据通过dma传输加msi中断的方式发送给linux系统中的内存。
所述的步骤(4)中cpu接收到该msi中断,并通知所述的gpu对该linux系统接收到的数据进行相应处理具体为:
所述的cpu收到该msi中断,并通过所述的kgpu模块通知所述的gpu对该linux系统接收到的数据进行相应处理。
所述的步骤(5)的具体步骤为:
(5.1)所述的gpu完成数据的转换处理,并通过所述的kgpu模块通知所述的cpu该次数据的转换处理已完成;
(5.2)由所述的linux内核进一步处理经所述的gpu转换处理的数据,或所述的cpu通过所述的linux内核与应用层共享内存的方式,由该linux系统的应用层直接处理经过所述的gpu转换处理的数据。
所述的步骤(1)前还有一步骤:
(1.0)所述的linux系统启动前,需对linux系统进行定制,预留大块物理内存以满足所述的现场可编程门阵列fpga和gpu的使用需求。
在一种具体实施例中,本发明采用的现场可编程门阵列fpga的接口是pcie接口,优选为pcie3.0接口。且该pcie接口需要有块式dma传输能力和msi虚拟中断的能力。且整个linux系统通过cpu+fpga+gpu实现外设数据高速传输与处理。
整个linux系统需要进行相应定制。具体需要在linuxkernel(内核)启动前预留大块物理内存供现场可编程门阵列fpga和gpu用,如256m,1g内存等。
在该具体实施例中,其实现外设数据高速传输与处理的实现过程如下:
(1)linux启动前,对系统预留大块物理内存;
(2)linux启动时,对大块物理内存进行初始化,同时初始化外设,将该外设进行dma传输的物理目的地址通知给所述的外设;
(3)外设采集到数据后通知所述的现场可编程门阵列fpga;
(4)现场可编程门阵列fpga对采集的数据做预处理后,通过dma传输+msi中断的方式将预处理后的数据传入linux系统的内存中;
(5)所述的linux系统中的cpu收到该msi中断后,通过linux内核中的kgpu模块通知gpu,对数据进行相应处理;
(6)gpu对数据转换处理后,通过kgpu模块通知cpu,再由linux内核直接处理数据或cpu通过linux内核与应用层共享内存的方式,使应用层可以直接处理经过gpu转换处理过的数据。
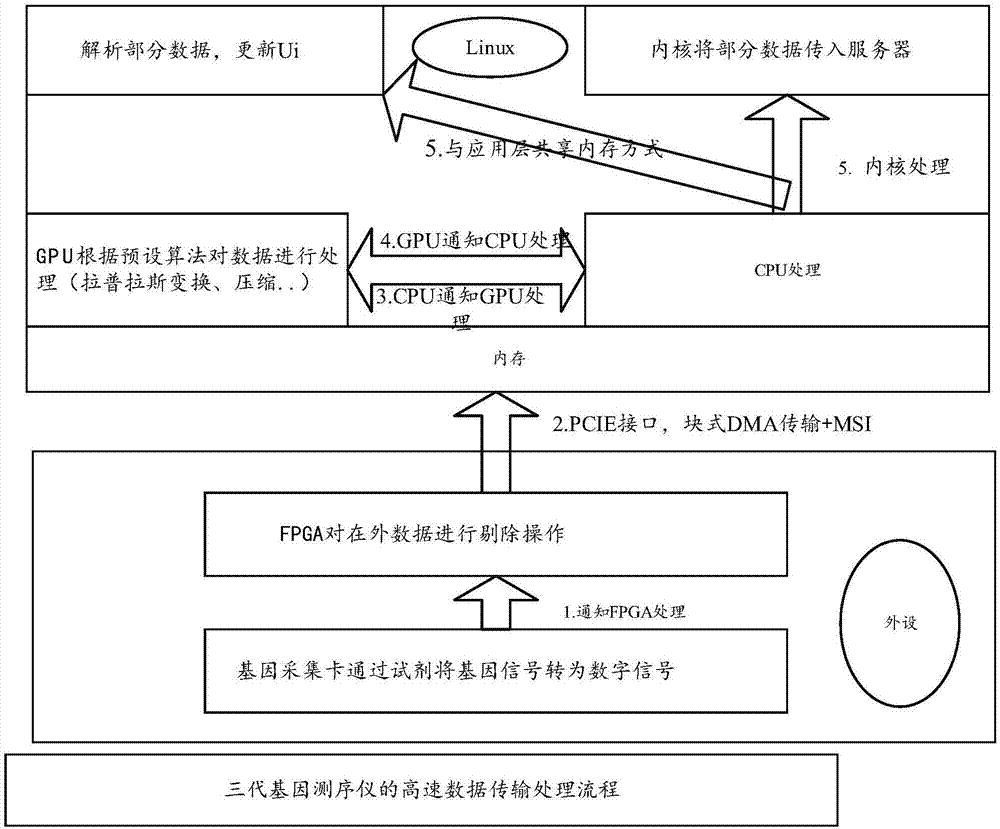
请参阅图2,在一种具体的实施例中,如用于当前流行的基因测序时,由于目前基因测序对数据传输与处理要求很高,基因册数仪一代产品对基因的采集处理要求实时数据传输处理速度为实时连续的300mb/s,二代产品则需要600mb/s,当前最新的三代产品需要的实时数据传输处理速度为实时连续的1200mb/s。而通过本发明中的方法,则只需采用总线位宽为8位的pcie2.0接口,即可以满足当前最新的三代基因测序仪器的实时数据传输处理要求。
首先外设通过试剂将基因信号转化为数字信号,并通过现场可编程门阵列fpga对采集到的数字信号进行预处理,而后通过块式dma传输+msi中断的方式将该经预处理的数字信号传输给所述的linux系统,由linux系统的内存进行保存,所述的linux系统中的cpu接收到该msi中断,并通过linux内核中的kpgu模块通知所述的gpu对该linux系统接收到的数据进行处理,处理包括拉氏变换、压缩等,待处理完成后,所述的gpu通过所述的linux系统中的kgpu模块通知所述的cpu对gpu完成处理后的数据进行进一步的处理,再由linux内核将部分数据传输给服务器或者通过linux内核与应用层共享内存的方式,使应用层直接处理经过gpu处理的数据,解析部分数据,并更新ui。
采用该种基于linux系统实现外设数据高速传输与处理的方法,由于其使用fpga+cpu+gpu协同合作,使数据在外设被采集后即可通过fpga进行预处理,并在使用gpu对被采集的数据进行相应处理后,可通过linux内核直接对数据进行进一步的处理,或通过内核与应用层共享内存的方式,使linux的应用层直接对数据进行进一步的处理,整个过程不存在现有技术中无法保证被采集的数据完整性的问题,同时可以在硬件层对数据进行较为复杂的处理,经济实用、效率高、成本低,适合数据进行高速传输与处理。
在此说明书中,本发明已参照其特定的实施例作了描述。但是,很显然仍可以作出各种修改和变换而不背离本发明的精神和范围。因此,说明书和附图应被认为是说明性的而非限制性的。
- 还没有人留言评论。精彩留言会获得点赞!