基于集成学习的软件缺陷重新打开的预测方法与流程
本发明属于软件安全技术领域,具体涉及一种基于语义特征和集成学习的软件缺陷重新打开的预测方法。
背景技术:
随着电信、国防、商业、金融、交通运输、医疗等行业不断向信息化和智能化发展,大规模软件系统逐渐成为大多数人日常生活中不可分割的一部分。而这些软件系统的大部分成本用于这些软件系统的维护。事实上,之前的研究显示,超过90%的软件开发成本用于软件的维护和演化活动。
在软件的开发和维护过程中,软件缺陷修复是其中的一个关键活动。绝大多数的开源和商业软件项目使用软件缺陷追踪系统,如bugzilla,管理他们的软件软件缺陷。这些软件缺陷追踪系统记录关于软件缺陷报告的各种特征,如软件缺陷被发现的时间,软件缺陷出现的组件和所有与该软件缺陷相关的讨论。研究人员利用存储在软件缺陷追踪系统中的信息研究不同的问题,如软件缺陷分派、重复软件缺陷的删除、解决软件缺陷所需要花费的时间。由于软件缺陷的有效管理是一个非常重要的问题,许多研究提出了自动化技术管理软件缺陷分配,如软件缺陷筛选,重复软件缺陷报告的检测。之前许多的研究都是与解决软件软件缺陷相关。例如,使用各种代码、过程、社会结构、地理分布、和组织结构指标预测有软件缺陷的软件的位置(如文化或目录)。其他工作侧重于预测软件缺陷修复所花费的时间。但是,在某些情况下,软件缺陷不得不重新打开。
尽管已有大量的研究文献检测软件缺陷及其预测,但是很少有研究考虑一般的软件缺陷和重新打开软件缺陷的差别。现有的工作通常将所有的软件缺陷一视同仁,很少考虑重新打开的软件缺陷和新软件缺陷的意义、存在的工作的区别。重新出现的软件缺陷是指已被开发人员关闭,但是在稍后的时间重新出现。软件缺陷可能由于各种原因被重新打开。重新打开软件缺陷这样的负面影响已经在开源和商业项目中得到证实。例如,在eclipseplatform3.0项目中,重新打开软件缺陷修复所花费的时间(如从软件缺陷初始打开到最终关闭的时间)是不再重新打开软件缺陷的两倍多(重新打开的软件缺陷371.4天,一次修复的软件缺陷149.3天)。因此,确定影响重新打开软件缺陷的因素非常重要。了解哪些因素会导致软件缺陷重新打开,可以使开发人员在关闭软件缺陷之前三思而后行。例如,如果确定严重程度高的软件缺陷记录经常重新打开,那么开发人员就要特别关注(如执行更彻底的检查)这样的软件缺陷及其修复。另外,准确预测哪些软件缺陷可能会重新打开,是加快软件开发周期、降低软件开发和维护成本的极为关键的任务。
技术实现要素:
本发明的目的在于提供一种基于采样和集成学习的软件缺重新打开的陷预测方法,以克服上述背景技术所述的缺陷,本发明可以解决软件缺陷重新打开预测中由数据不均衡导致的预测效果不理想问题。
为达到上述目的,本发明采用如下技术方案:
基于集成学习的软件缺陷重新打开预测方法,包括以下几个部分:
s1:将从软件的缺陷报告中提取基于lweparagraph2vec的语义向量特征;
s2:将从软件的缺陷报告中提取基于lweparagraph2vec的语义向量特征与其元特征组合作为特征集合;
s3:根据基于不均衡数据处理的集成学习预测算法undersmotebagging方法构造预测模型;
s4:根据s1提取出的特征集合以及s2得到的预测模型获取该实例的类标签,即可判断此软件缺陷是否会被重新打开。
s1具体包括:
s101:首先使用软件缺陷追踪系统bugzilla,从其在线数据库中获取软件的缺陷报告;
s102:从获取到的软件缺陷报告中,获得软件缺陷的描述字段和注释文本字段;
s103:使用word2vec算法,将描述字段和注释文本字段表示为word向量;
s104:选择具有上下文语义分析能力的paragraph2vec算法作为基特征提取算法,将描述文本字段和注释文本字段转化成paragraph语义向量;
s105:按照各注释文本包含信息的多少对其语义向量加权;
s106:将加权后的注释文本向量和描述文本向量线性组合;
s107:得到基于lweparagraph2vec的语义向量特征。
s2具体包括:
s201:首先使用软件缺陷追踪系统bugzilla,从其在线数据库中获取软件的缺陷报告;
s202:从获取到的软件缺陷报告中,提取出每一条软件缺陷实例的元特征集和类标签;
s203:从获取到的软件缺陷报告中,获得软件缺陷的描述字段和注释文本字段;
s204:针对每一条软件缺陷实例,将其元特征和由s1得到的lweparagraph2vec算法语义向量特征组合为一条记录,即得到完整的一条训练数据;
s205:将得到的若干训练数据整合为一个实例集合。
s3具体包括:
s301:构造子集,使得该子集中所有的类的实例个数相同;
s302:设置采样率,对每个类进行有放回的随机采样,得到多个均衡的子集;
s303:使用smote方法由均衡的子集生成新的实例子集;
s304:在实例子集上训练基分类器;
s305:将得到的若干基分类模型集训练成为一个分类模型;
s306:每个基分类器为测试实例预测一个类别,将预测实例的类别预测为投票最多的类别。
s102中,在描述文本和评论文本等特征上应用朴素贝叶斯分类器以确定和重新打开的软件缺陷及一般性软件缺陷关联的关键字,来获取软件缺陷相关的描述文本信息和注释文本信息。
s104中paragraph2vec算法使用的模型是distributedmemory(dm)。
s105中paragraph2vec算法的加权指的是,以经过文本预处理之后的描述文本字段所包含的词的个数为基准,将经过文本预处理之后的各评论文本字段所包含的词的个数与该基准的比值作为相应的评论文本字段的权重,其取值范围为[0,1]。
s302中设置初始采样率为重新打开的软件缺陷与一般性软件缺陷的实例个数的比值。
s303中对原始训练集采样构建训练子集,按照不同的采样率,对一般性软件缺陷欠采样,并同时对重新打开的软件缺陷进行smote采样。
s304中选择c4.5作为usmotebpredictor的基分类器,并将基分类器的个数设置为多数类即一般性软件缺陷和少数类即重新打开的软件缺陷的实例个数比值的上界。
与现有技术相比,本发明具有以下有益的技术效果:
针对软件缺陷重新打开数据集的极度不均衡性,本发明创新地将不均衡数据处理方法欠采样和smote方法组合,提出一种新的极度不均衡数据处理方法undersmote算法,该算法不仅对多数类样本进行欠采样还包括对少数类样本的smote采样以合成新的少数类样本,经过undersmote算法采样之后得到的训练集具有均衡性。其次,将undersmote算法与集成学习算法bagging组合,得到一种新的基于不均衡数据处理的集成学习预测算法undersmotebagging,该算法通过设置不同的采样率,使用undersmote方法为bagging的基分类器采样得到不同的均衡子训练集,最后根据在不同子训练集上得到的基分类器的投票,形成usmotebpredictor预测器。为了验证该预测算法的有效性,本文分别在10个大型开源软件项目的软件缺陷数据集进行验证,并与目前已有的预测算法underoverbagging、smotebagging和overadaboosting算法进行对比验证。对比表明,该预测算法与underoverbagging、smotebagging和overadaboosting相比,在f-measure评价指标上均具有显著提升。usmotebpredictor分别比underoverbagging、smotebagging和overadaboosting算法的fmeasure提高2.17%,3.5%和2.45%。
针对当前软件缺陷重新打开预测使用的特征集的有限性,本文提出基于线性加权的paragraph2vec语义特征提取算法lweparagraph2vec,该算法将软件缺陷报告中的描述和注释文本等字段信息转换成相应的语义向量特征,并根据提供有用信息的多寡给予不同的权重,然后将这些语义向量线性加权组成一个新的语义特征向量。增加语义特征向量的预测器比只包含缺陷报告维度特征的预测器在评价指标auc和fmeasure上具有显著提高。
附图说明
图1是本发明提供的根据软件缺陷报告中的描述文本信息和注释文本信息获得paragraph语义向量的lweparagraph2vec模型结构图;
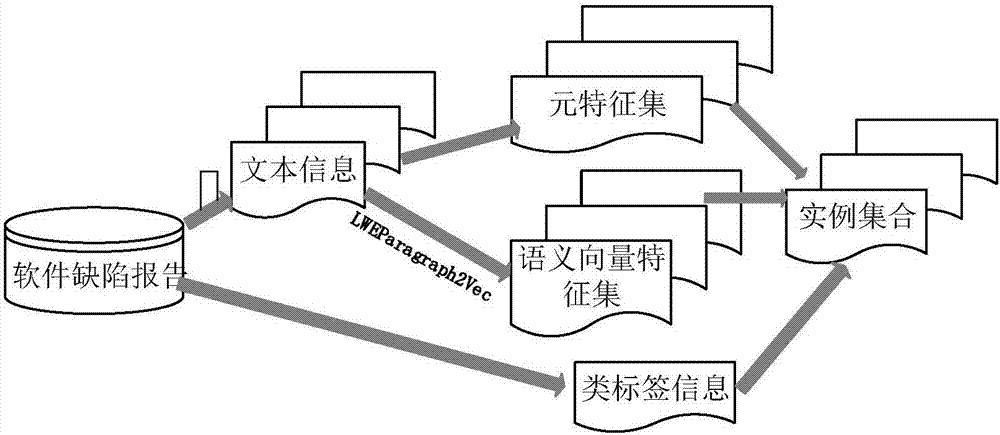
图2是本发明提供的根据软件缺陷报告获取数据集以及提取特征的示意图;
图3是本发明提供的基于lweparagraph2vec算法获得paragraph语义向量的流程图;
图4是本发明提供的将paragraph语义向量和元特征向量进行组合的流程图;
图5是本发明提供的根据分类实例集建立分类模型并对软件缺陷是否会被重新打开进行分类的示意图;
图6是本发明提供的使用undersmotebagging算法预测未知实例是否会被重新打开的流程图。
具体实施方式
下面结合附图对本发明作进一步详细描述:
如图1至图6所示,本发明针对软件缺陷重新打开数据集的极度不均衡性和当前软件缺陷重新打开预测使用的特征集的有限性,采用基于undersmote采样和集成学习的缺陷重新打开预测方法,共分为数据提取、模型训练和预测三个过程。
数据提取过程的输入为软件所对应的软件缺陷报告和开发控制版本的git库,输出为提取的可以用于训练模型的分类实例集。本发明通过对软件缺陷管理系统bugzilla的在线数据库中软件缺陷报告的爬取、整理与分析,得到表1中的特征集合,该表展示了提取的特征的类型、解释及原理等。本文共有27个特征涵盖四个不同的维度。本节将详细地描述每个维度及其所覆盖的特征。
1)工作习惯维度
软件开发人员经常超量工作,额外增加的工作会影响这些开发人员的效率。例如,sliwerski等人研究发现,周五完成的代码更改更有可能发生软件缺陷;anbalagan和vouk表明,修复缺陷所需的时间与报告缺陷的时间段有关;hassan和zhang使用各种工作习惯特征来预测软件缺陷产生的可能性。根据这些已有的研究结果,本文将工作习惯维度纳入软件缺陷重新打开预测的研究。工作习惯维度由表1中time、weekday、monthday及month四个不同的特征组成。
2)缺陷报告维度
当发现软件缺陷时,开发人员需要提交该缺陷相关的描述信息,以便后续的缺陷修复人员使用该信息了解和定位缺陷。一些研究使用这些信息来研究修复缺陷所需要的时间。例如,hooimeijer和weimer的研究显示,附加到软件缺陷报告中的注释的数量影响着修复该缺陷所需要的时间。本文认为可以利用软件缺陷报告中包含的特征来确定软件缺陷重新打开的可能性。例如,简短的缺陷描述可能会造成该缺陷的重新打开,因为开发人员可能无法了解或复制该缺陷。总共15个不同的特征组成了软件缺陷报告维度,详情请参见表1。
3)缺陷修复维度
一些软件缺陷比其他的软件缺陷更难修复。在某些情况下,对该软件缺陷的初始修复可能不足即没有完全修复该缺陷,因此该软件缺陷会重新打开。本文推测更复杂的软件缺陷更有可能重新打开。有几种方法金额已测量缺陷修复的复杂性,例如,如果缺陷修复需要更改许多文件,这可能成为一个软件缺陷复杂性度量的指标。本文的缺陷修复维度由三个特征组成,即缺陷修复所花费的时间、缺陷重新打开之前的状态及修复缺陷所修改的文件数目。
4)人员维度
在许多情况下,涉及缺陷报告或缺陷修复放入人员是缺陷重新打开的原因。缺陷报告人员没有注明足够的重要信息或者缺乏经验,比如,他们之前从未报告过软件缺陷。另一方面,缺陷修复人员缺乏修复或验证缺陷的经验或技术专长,从而导致缺陷的重新打开。表1中列出的人员维度由四个特征组成,涵盖了缺陷报告人员、缺陷修复人员和其经验。
表1提取的27个特征
本发明提取27个不同的特征的详细描述见表1,其中大部分特征可以直接从缺陷或代码数据库中提取。但是,来自软件缺陷报告的两个基本文本的特征需要特殊处理。本文在描述文本和评论文本等特征上应用朴素贝叶斯分类器以确定和重新打开的软件缺陷及一般性软件缺陷关联的关键字。为此,本文随机选择2/3的软件缺陷报告组成训练集。使用从训练集中导出的两个语料库训练贝叶斯分类器。一个语料库包含重新打开的软件缺陷报告中的描述和评论文本,另一个语料库包含的是一般性软件缺陷报告中的描述和评论文本。计算每个单词出现的次数,并分别为其分配软件缺陷重新打开的概率和一般性软件缺陷的概率,这些概率都是基于训练集语料库。分配给单词的概率用于衡量与中性概率0.5的距离。将首次出现的单词概率设置为0.4。概率最高的15个单词合并成一个分数,该值用于评估软件缺陷是否会重新打开,比如分数值越接近1表明该软件缺陷越容易重新打开,反之亦然。
模型训练过程的输入是数据提取过程得到的实例集,输出是通过结合采样和集成学习的方法获得的预测模型,模型结构如图5所示。首先应用undersmote采样方法,获得类分布均衡的实例子集。之后使用每个实例子集在基分类器上构建一个子分类模型,最后将得到的若干个子分类模型以投票的策略集成为一个最终的分类模型,最终分类模型的预测结果根据各个子分类器的预测结果投票决定。
应用预测过程的输入是待预测的软件缺陷以及模型训练阶段获得的预测模型。过程是通过使用模型训练阶段获得的预测模型对待预测的软件缺陷进行预测,输出是软件缺陷的类标签,即是否会被重新打开。
如图2和图3所示,本发明基于lweparagraph2vec的语义向量特征与集成学习的软件缺陷重新打开的undersmotebagging预测方法的数据获取及特征提取阶段包括以下步骤:
对于每条训练数据,该实例的语义向量特征的获取过程如下:
s101:首先使用软件缺陷追踪系统bugzilla,从其在线数据库中获取软件的缺陷报告,并从开发控制版本的git库中获取实施软件缺陷修复所更改的文件数目等信息,具体如表3所示;
s102:从获取到的软件缺陷报告中,获得软件缺陷的描述字段和注释文本字段;
s103:使用word2vec算法,将获取到的软件缺陷报告中的描述字段和注释文本字段表示为word向量,word2vec算法有两个任务:对于每一个word,使用该word周围的word来预测当前word生成的概率;对于每一个word,使用该word本身来预测生成其他word的概率。这两个任务共同的限制条件是:对于相同的输入、输出每个word的概率之和为1。两个任务分别对应模型cbow和skip-gram;
s104:选择具有上下文语义分析能力的paragraph2vec算法作为基特征提取算法,将描述文本字段和注释文本字段转化成paragraph语义向量,本发明使用dm方法对paragraph向量进行训练;
s105:按照各注释文本包含信息的多少对其语义向量加权,具体为:以经过文本预处理之后的描述文本字段所包含的词的个数为基准,将经过文本预处理之后的歌评论文本字段所包含的词的个数与该基准的比值作为相应的评论文本字段的权重,取值范围为[0,1];
s106:将加权后的注释文本向量和描述文本向量线性组合;
s107:得到基于lweparagraph2vec的语义向量特征。
如图4所示,对于每条训练数据,将paragraph语义向量和其元特征向量进行组合的具体过程如下:
s201:首先使用软件缺陷追踪系统bugzilla,从其在线数据库中获取软件的缺陷报告;
s202:从获取到的软件缺陷报告中,提取出每一条软件缺陷实例的元特征集和类标签;
s203:从获取到的软件缺陷报告中,获得软件缺陷的描述字段和注释文本字段;
s204:针对每一条软件缺陷实例,将其元特征和由s1得到的lweparagraph2vec算法语义向量特征组合为一条记录,即得到完整的一条训练数据;
s205:将得到的若干训练数据整合为一个实例集合。
接下来结合图5和图6详细说明模型的训练过程。
s301:由于提取出来的实例集中,每个类中往往都具有上万个实例,这在训练基分类器时对机器的性能要求很高。所以需要构造子集,使得该子集中所有的类的实例个数相同;
s302:设置采样率,对每个类进行有放回的随机采样,得到多个均衡的子集;
s303:使用smote方法由均衡的子集生成新的实例子集;
s304:在实例子集上训练基分类器;
s305:将得到的若干基分类模型集训练成为一个分类模型;
s306:每个基分类器为测试实例预测一个类别,将预测实例的类别预测为投票最多的类别。
为了验证该算法的有效性,本发明在多种不同软件的缺陷报告进行实验验证。本发明的软件缺陷原始数据来源于软件缺陷追踪系统bugzilla。提取十个大型开源软件项目及子项目即apache、firefox、gnome、kde、mozilla、linuxkernel、openoffice及eclipse的三个子项目eclipse、modeling和tools。获取的数据集主要来自上述软件项目的不同版本或同一版本的不同子单元。获得的十个软件缺陷报告数据集都具有极度不均衡性,因此能够很好地验证该算法的有效性。实验数据如表2所示。
表2软件缺陷报告数据统计
从smotebpredictor与smotebagging的实验对比与分析中,由表3中auc、fmeasure和precision评价指标的均值可以看出,usmotebpredictor在auc、fmeasure和precision均优于smotebagging;由表3-6中win指标可以看出,usmotebpredictor分别以35:15的绝对优势胜于smotebagging算法。
表3usmotebpredictor与smotebagging实验结果对比
由表3中均值mean可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上的auc、fmeasure和precision的均值分别比smotebagging算法提高1.05%,2.17%和2.0%,而usmotebpredictor的gmean和recall均值仅比smotebagging算法降低了0.48%和0.86%。
由表3中rank排名计算得到的win可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上auc、fmeasure、gmean和precision等评价指标分别以8:2,9:1,6:4和7:3的优势胜于smotebagging算法。
对表3中usmotebpredictor和smotebagging在十个开源项目apache、firefox、gnome、kde、mozilla、linuxkernel、openoffice、eclipse、modeling和tools上的评价指标f-measure进行显著性分析,结果见表3-7,其中sum代表求和,avg代表平均,var代表方差,f是检验统计量,p-value是观察到的显著性水平,f_crit是临界值。
由表4可知:f=5.48>fcrit=5.11,并且p-value=0.044<0.05,则f值在a=0.05的水平上显著。因此,usbpredictor预测算法和smotebagging预测算法在f-measure上存在显著性差异,即usbpredictor预测算法在评价指标f-measure显著性优于smotebagging预测算法。
表4usbp和sb在f-measure的显著性分析结果
由usmotebpredictor与underoverbagging的实验对比与分析,从表5中auc、fmeasure、precision评价指标的均值可以看出,usmotebpredictor在auc、fmeasure和precision均优于underoverbagging;由表5中win指标可以看出,usmotebpredictor分别以35:15的绝对优势胜于underoverbagging算法。
表5usmotebpredictor与underoverbagging实验结果对比
由表5中均值mean可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上的auc、fmeasure和precision的均值分别比smotebagging算法提高0.71%,3.5%和3.39%,而usmotebpredictor的gmean和recall均值仅比underoverbagging算法降低了1.02%和1.52%。
由表5中rank排名计算得到的win可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上auc、fmeasure、gmean和precision等评价指标分别以7:3,10:0,6:4和8:2的优势胜于underoverbagging算法。
由usmotebpredictor与overadaboosting的实验对比与分析,由表6中auc、fmeasure、gmean、recall和precision评价指标的均值可以看出,usmotebpredictor在auc、fmeasure、gmean、recall和precision均优于overadaboosting;由表5中win指标可以看出,usmotebpredictor分别以35:15的绝对优势胜于underoverbagging算法。
表6usmotebpredictor与overadaboosting实验结果对比
由表6中均值mean可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上的auc、fmeasure、gmean、recall和precision的均值分别比adaboosting算法提高0.71%,2.45%,4.51%,0.36%和1.66%。
由表6中rank排名计算得到的win可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上auc、fmeasure、gmean、recall和precision等评价指标分别以7:3,10:0,6:4,6:4和6:4的优势胜于underoverbagging算法。
由表6中均值mean可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上的auc、fmeasure、gmean、recall和precision的均值分别比adaboosting算法提高0.71%,2.45%,4.51%,0.36%和1.66%。
由表4中rank排名计算得到的win可以看出,usmotebpredictor在十个开源软件项目apache、eclipse、modeling、tools、firfox、gnome、kde、linuxkernel、mozilla和openoffice上auc、fmeasure、gmean、recall和precision等评价指标分别以7:3,10:0,6:4,6:4和6:4的优势胜于underoverbagging算法。
实验结果表明,从auc、fmeasure和gmean三方面进行预测精度分析,本章提出的usmotebpredictor预测算法均以绝对优势35:15胜于smotebagging、underoverbagging和overadaboosting预测算法。
以上所述仅为本发明的较佳实例而已,并不用以限制本发明,凡在本发明的精神和原则之内做出的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!