一种基于稀疏表示字典学习的图像分类方法与流程
本发明属于图像处理及图像分类的
技术领域:
,具体地涉及一种基于稀疏表示字典学习的图像分类方法。
背景技术:
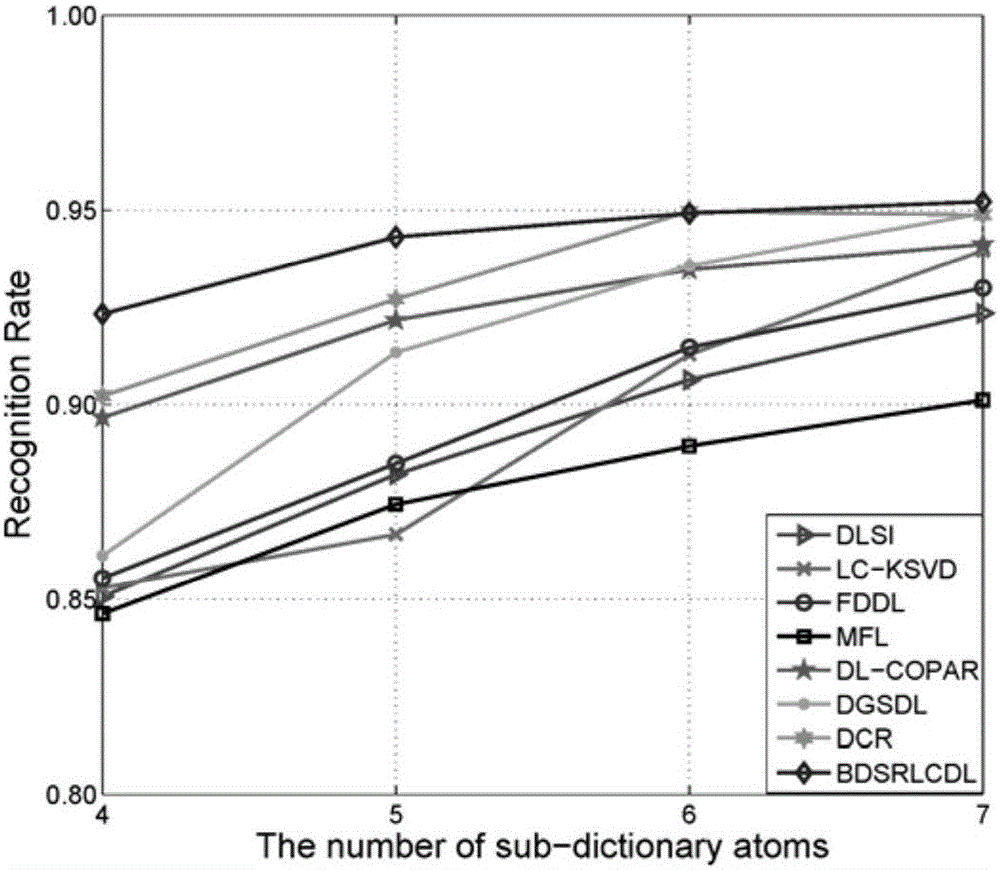
:在过去几年里,稀疏表示已在人脸识别,图像分类,以及人类动作识别等众多应用方面取得了巨大成功。稀疏表示的核心思想是大多数自然信号可以用一个超完备辞典中少量原子来表示。为解决在实际应用中遇到的问题,研究人员陆续提出了许多字典学习方法。其中,一个简单而直接的方法是使用训练样本自身作为字典原子,如稀疏表示分类(SRC)方法。这种自表示方法的成功是建立在子空间理论的基础上的。子空间理论假定大量样本信号可以构成一个线性子空间,并且由子空间衍生的样本可被同一子空间的其他样本来近似表示。尽管这种自表达方法在识别问题中表现出良好的特性,但是它对噪声和离群点十分敏感,在应用中能否成功常依赖于训练样本的质量。因此,学者们采用字典学习方法构建字典原子,用以代替训练样本自身。这类优化学习算法包括经典的MOD和K-SVD算法。在此基础上,Yang等提出的基于SRC的MFL人脸识别方法。传统字典学习方法(如MOD和K-SVD)通常是无监督的,在字典学习过程中没有引入数据的类别特性,而这种类别特性能够增强字典在识别问题中的判别能力。因此,学者们开始研究有监督的字典学习方法,通过结合训练数据的类别信息,即同类数据的一致性以及异类数据的差异性,训练学习得到字典,用以提高字典的分类和识别性能。例如,Zhang等提出了一种判别的K-SVD字典学习方法(D-KSVD)。为了提高稀疏表示模型的判别能力,除了训练样本的标签信息,学者们对稀疏系数矩阵的结构、不同类子字典之间不一致以及同类字典内的一致性等性质进行了探索和研究。针对稀疏系数矩阵的结构属性,Jiang等提出LC-KSVD算法。在此算法中,作者使系数矩阵逼近0-1块对角矩阵以表达样本的标签属性。Yang等将Fisher判别约束加入到字典学习模型中,提出了FDDL算法,用以降低样本系数的类内离散度并提高其类间离散度。针对不同类子字典之间不一致以及同类字典内的一致性,Ramirez等提出的DLSI方法。在此算法中,作者利用不一致约束减少子字典之间的相关性。此外,Kong等提出了DL-COPAR算法,该方法通过训练学习得到一个共性字典以及一组个性字典(即各类相应的子字典)。在这种方法中,共性字典可以用来提取样本之间的共性信息,个性字典可以用来提取各类样本的个性信息。Sun等提出DGSDL算法,在该方法中作者给予样本在共性字典和个性字典上的投影系数不同的权值参数,从而降低了样本中共性信息对分类效果的干扰。与此同时,来自同一类别的样本之间有着高度的相关性,因此同类样本的稀疏表示系数之间也存在着高度相关性。这种特性也能够提高稀疏表示的识别能力。学者们通常采用低秩约束来表达这种内部相关性。Zhang等提出了一种联合低秩和稀疏表示的图像识别算法。Li等提出了一种半监督并结合低秩和块稀疏结构的字典学习方法LR-CBDS。这些研究工作表明,低秩约束表示可以有效表达同类样本的类内一致性,同时能够降低样本中噪声对模型的影响,提高分类效果。技术实现要素:本发明的技术解决问题是:克服现有技术的不足,提供一种基于稀疏表示字典学习的图像分类方法,其可以消除不同类字典之间的相关性从而提高其判别性能,提高字典的表示能力以及字典学习模型的鲁棒性。本发明的技术解决方案是:这种基于稀疏表示字典学习的图像分类方法,该方法采用基于块对角稀疏表示字典学习算法模型,s.t.X=diag(X11,X22,…,Xnn).(1)其中||X||1表示矩阵稀疏约束,||Xii||*表示矩阵低秩约束,表示矩阵正则项,表示训练样本,第i个子块矩阵Yi表示第i类训练样本,第j列向量yj表示第j个训练样本,YW表示基于训练样本的线性组合字典,表示字典组合系数,X表示训练样本Y在字典YW上的稀疏表示系数,Xii表示第i类训练样本在第i类子字典上的稀疏表示系数,m表示样本维度,N表示样本数量,K=K1+K2+...+KC表示字典原子个数,Ki表示第i类子字典的原子个数。本发明针对图像分类识别问题提出了一个全新的基于块对角稀疏表示的字典学习模型,其可以消除不同类字典之间的相关性从而提高其判别性能,提高字典的表示能力以及字典学习模型的鲁棒性。附图说明图1是在ExtendedYaleB人脸库的不同子字典原子个数的识别对比结果。图2是在AR人脸库的不同子字典原子个数的识别对比结果。图3是在KTH-TIPS静态纹理库的不同子字典原子个数的识别对比结果。图4是在DynTex++动态纹理库的不同子字典原子个数的识别对比结果。图5是在15-Scene场景数据库的不同子字典原子个数的识别对比结果。图6是在OxfordFlowers17数据库的不同子字典原子个数的识别对比结果。具体实施方式这种基于稀疏表示字典学习的图像分类方法,该方法采用基于块对角稀疏表示字典学习算法模型,s.t.X=diag(X11,X22,...,Xnn).(1)其中||X||1表示矩阵稀疏约束,||Xii||*表示矩阵低秩约束,表示矩阵正则项,表示训练样本,第i个子块矩阵Yi表示第i类训练样本,第j列向量yj表示第j个训练样本,YW表示基于训练样本的线性组合字典,表示字典组合系数,X表示训练样本Y在字典YW上的稀疏表示系数,Xii表示第i类训练样本在第i类子字典上的稀疏表示系数,m表示样本维度,N表示样本数量,K=K1+K2+...+KC表示字典原子个数,Ki表示第i类子字典的原子个数。本发明针对图像分类识别问题提出了一个全新的基于块对角稀疏表示的字典学习模型,其可以消除不同类字典之间的相关性从而提高其判别性能,提高字典的表示能力以及字典学习模型的鲁棒性。优选地,采用分离变量以及交替迭代ADMM算法对模型进行分解,再根据阈值法对l1范数和核范数进行求解。优选地,分离变量为:首先引入变量序列使得Zii=Xii,则原模型可转变为:s.t.Zii=Xii,i=1,...,CX=diag(X11,X22,...,XCC),再利用增广Lagrange法将上述模型变成无约束模型:其中Fii表示Lagrange乘子,γ表示惩罚系数,<A,B>=trace(ATB)。优选地,利用交替迭代求解方法直接求解,包括:(1)固定W和Xii求解Zii其中U∑VT表示的奇异值分解形式(SVD),表示阈值分割函数,(2)固定W和Zii求解Xii首先定义hi(·)函数如下:求解Xii如下:其中表示hi(·)函数关于Xii的一阶偏导,为:同时则Xii的解析形式为:(3)固定Xii和Zii求解W当固定Xii和Zii时,关于W的求解问题可转换为:令再逐列进行求解:其中表示Xt+1的第k行,表示的第k列,Ek定义如下:求解(4)更新Lagrange乘子Fii和惩罚参数γ6、其中ρ=1.1,γmax=1010关于此模型的收敛条件定义如下:以下对本发明进行更详细的说明。传统的基于稀疏表示字典学习的图像分类算法是对每一类样本训练一个子字典,其训练模型如下所示:s.t.||dj||2=1.其中Yi表示第i类训练样本,Di表示第i类子字典,Xi表示稀疏系数,dj表示字典D中的第j个原子。再将测试样本在每一类子字典上进行稀疏编码,最后根据重建误差进行分类。如下所示:其中表示重构误差。这种字典学习方法没有考虑样本集本身自带的标签信息,会导致各个子字典之间存在交叉信息,从而降低识别结果。针对这个问题,本发明结合样本类别标签信息,提出一种基于块对角稀疏表示字典学习的图像分类算法。在该算法中,致力于学习得到一个具有判别能力的整体字典。此字典由各个子字典Di(i=1,2,...,C)组合而成,如下所示:D=[D1,D2,...,DC]其中C表示类别数。则训练样本Y=[Y1,Y2,...,YC]在字典D上的稀疏系数矩阵可以分解为如下表示:其中每个子块Xij表示第i类训练样本在第j类字典上的稀疏投影系数。如果每个子字典之间具有高度独立性,即各个子字典之间不存在交叉信息,那么训练样本在此整体字典上的投影系数矩阵会形成一个严格的块对角稀疏矩阵,如下所示:可以对系数矩阵加入这种基于训练样本标签信息的块对角稀疏约束来训练字典,使得各个子字典具有高度的独立性。此外,由于在字典学习过程中,训练样本的个数要远远大于总体类别的个数,即在训练样本之间存在高度的相关性,其对应的稀疏系数矩阵也应该具有高度相关性。从数学上可以将这种性质理解为低秩矩阵,因此可以在字典学习模型中加入低秩矩阵的约束来表达这种高度相关性,即对稀疏表示系数矩阵加以核范数||·||*的约束。最后,在传统的基于稀疏表示字典学习的图像分类算法中,训练样本的维度往往远大于训练样本以及字典原子的个数,而这种高维变量求解过程往往会增加计算复杂度,同时会带入计算误差以及随机噪声。因此引入线性组合字典的形式,即将原始字典D分解成训练样本线性组合的形式,如下所示:D=YW,Y∈Rm×N,W∈RN×K.其中m表示样本维度,N表示训练样本个数,K表示字典原子个数,则字典D的训练求解可以转化为对线性组合矩阵W的求解。根据Nguyen等人的证明,YW是字典D的一个优化解。这样可以降低计算复杂度,同时减少随之带来的计算误差以及随机噪声。综上得到最终的基于块对角稀疏表示字典学习算法模型,如下所示:s.t.X=diag(X11,X22,...,Xnn).其中表示正则项,用以保证整个模型的凸性。此模型即为本发明提出的全新模型,称为基于块对角稀疏表示的字典学习模型(Block-DiagonalSparseRepresentationbasedLinearCombinationDictionaryLearningModel,BDSRLCDL)。对于此类复杂的优化模型,无法直接求解。因此采用分离变量以及交替迭代(ADMM)算法对模型进行分解,再根据阈值法对l1范数和核范数进行求解。具体优化算法如下:首先引入变量序列使得Zii=Xii,则原模型可转变为:s.t.Zii=Xii,i=1,...,CX=diag(X11,X22,...,XCC),再利用增广Lagrange法将上述模型变成无约束模型:其中Fii表示Lagrange乘子,γ表示惩罚系数,<A,B>=trace(ATB)。然后利用交替迭代求解方法直接求解,具体过程如下:(1)固定W和Xii求解Zii则有:其中U∑VT表示的奇异值分解形式(SVD),表示阈值分割函数,定义如下:(2)固定W和Zii求解Xii首先定义hi(·)函数如下:从而可以求解Xii如下:其中表示hi(·)函数关于Xii的一阶偏导,具体形式为:同时则Xii的解析形式为:(3)固定Xii和Zii求解W当固定Xii和Zii时,关于W的求解问题可转换为:令再逐列进行求解:其中表示Xt+1的第k行,表示的第k列,Ek定义如下:则可以求解(4)更新Lagrange乘子Fii和惩罚参数γγt+1=min{ργt,γmax}其中ρ=1.1,γmax=1010关于此模型的收敛条件定义如下:在多个图像数据库上进行识别验证,主要包括:两个人脸数据库—ExtendedYaleB人脸库和AR人脸库,两个纹理数据库—KTH-TIPS静态纹理库和DynTex++动态纹理库,一个场景图像库—15-Scene数据库和一个物体数据库—TheOxfordFlower17数据库。涉及比较的算法有:SRC,DLSI,LC-KSVD,FDDL,MFL,DL-COPAR,DGSDL和DCR。相关实验结果如下:(1)在人脸识别问题上的实验结果:(1.1)在ExtendedYaleB人脸库的实验结果ExtendedYaleB人脸库包含38类不同身份信息的人脸灰度图像数据,每类人脸有大约60张图像样本。在实验中,对每类人脸随机选取20张图像样本作为训练样本,剩余样本作为测试样本。相关参数设定为:τ=λ=α=0.001。表(1)为每类子字典原子个数为20(Ki=20)时,各类算法的识别结果。其中最佳分类结果加粗表示,次优结果加下划线表示。表1AlgorithmRecognitionRate(%)SRC88.50DLSI94.03LC-KSVD94.42FDDL93.92MFL93.65DL-COPAR95.11DGSDL95.72DCR96.01BDSRLCDL96.76在表1的结果中,本发明提出的算法准确率为96.76%,比次优的DCR算法高出0.75个百分点。同时,针对不同的字典原子个数,同样进行了实验测试。实验结果如图1所示,子字典原子个数选取范围为[8,10,12,14,16,18,20]。其中横坐标表示字典原子个数,纵坐标表示识别准确率。在字典原子数量变化过程中,本发明提出算法的变化幅度较低,变化方差为0.49%,其余算法的变化方差为DLSI1.59%,LC-KSVD1.72%,FDDL1.49%,MFL2.28%,DL-COPAR1.80%,DGSDL1.66%,DCR1.27%。这表明在字典原子变化的过程中,本发明提出的算法具有较高的鲁棒性。(1.2)在AR人脸库的实验结果AR人脸库包含100类不同身份信息的人脸灰度图像数据,每类人脸有14张图像样本。对每类人脸选取前7张图像样本作为训练样本,后7张样本作为测试样本。相关参数设定为:τ=λ=2×10-4,α=1.5×10-4。表2为每类子字典原子个数为7(Ki=7)的识别结果:表2AlgorithmRecognitionRate(%)SRC89.14DLSI89.61LC-KSVD93.96FDDL93.00MFL90.12DL-COPAR94.12DGSDL94.42DCR93.43BDSRLCDL95.22同样地,针对不同的字典原子个数进行了实验测试。实验结果如图2所示,子字典原子个数选取范围为[4,5,6,7]。从以上两个实验结果可以看出本发明提出的算法在人脸识别问题上是可行有效的。相较于其它算法,本方法能够取得更好的分类效果。同时在字典原子变化时体现了本算法的鲁棒性。(2)在纹理识别问题上的识别结果(2.1)在KTH-TIPS静态纹理库上的识别结果KTH-TIPS纹理库由10类不同的纹理图像样本组成,每类样本包含81个图像样本。在测试实验中,提取PRI-CoLBP0特征作为样本特征输入。对于每类样本,随机选取40个样本作为训练样本,剩余样本作为测试样本。相关参数设定为:τ=λ=α=10-6,表3为每类子字典原子个数为7(Ki=7)的识别结果,其中本发明提出的算法效果是最佳的。表3AlgorithmRecognitionRate(%)SRC83.77DLSI96.00LC-KSVD96.21FDDL96.00MFL91.68DL-COPAR92.16DGSDL93.26DCR94.33BDSRLCDL96.37同样地,针对不同的字典原子个数进行了实验测试。实验结果如图3所示,子字典原子个数选取范围为[20,25,30,35,40],其中本发明提出的算法效果都是最佳的。结果表明提出的识别算法是有效的。(2.2)在DynTex++动态纹理库上的实验结果DynTex++数据库包含36类动态纹理视频,每类有100段视频(总共3600段视频),每段视频尺寸为50×50×50。针对每段视频,对其提取LBP-TOP特征作为特征输入进行识别测试。对每类样本,随机选取50个视频段作为训练样本,剩余样本作为测试样本。相关参数设定为:τ=λ=10-6,α=10-4。表4为每类子字典原子个数为50(Ki=50)的识别结果,其中本发明提出的算法效果是最佳的。表4AlgorithmRecognitionRate(%)SRC86.20DLSI90.34LC-KSVD91.29FDDL92.03MFL90.02DL-COPAR91.77DGSDL90.43DCR90.27BDSRLCDL92.35同样地,针对不同字典原子个数进行了测试实验,字典原子个数取值范围为Ki=[25,30,35,40,45,50],实验结果如图4所示。相较于其它算法,提出的算法在字典原子个数变化时都能取得最佳的分类效果。以上两个实验说明本发明提出的方法能够在静态纹理和动态纹理识别问题上取得良好的分类效果。(3)在场景分类问题上的实验结果:选取15-Scene场景数据库来测试本发明算法在场景分类问题上的效果。15-Scene场景数据库包含15类不同场景共4485张图像样本。每类场景包括210张至410张图像样本不等。对于每张图像样本,对其提取空间金字塔和SIFT结合特征。对每类样本,随机选取100个样本作为训练样本,其余样本作为测试样本。相关参数设定为:τ=10-6,λ=α=10-5。表5为每类子字典原子个数为50(Ki=50)的识别结果,其中本发明提出的算法效果是最佳的,相较于次优的DCR算法,本方法将识别准确率提高了2.14%。表5AlgorithmRecognitionRate(%)SRC88.40DLSI94.22LC-KSVD93.17FDDL94.67MFL92.22DL-COPAR93.79DGSDL94.43DCR95.92BDSRLCDL98.06与其它实验类似,针对不同字典原子个数进行了测试实验,字典原子个数取值范围为Ki=[50,60,70,80,90,100],实验结果如图5所示。相较于其它算法,提出的算法在字典原子个数变化时都能取得最佳的分类效果,表明提出的识别算法在此数据库上是可行有效的。(4)在物体分类问题上的实验结果:选取OxfordFlowers17数据库来测试本发明算法在物体图像分类问题上的效果。OxfordFlowers17数据库由17类花朵样本,每类花朵包含80张图像样本。对于每张图像样本,对其提取局部频率直方图算子(FrequentLocalHistogram,FLH)作为输入特征。同时根据OxfordFlowers17数据库提供的数据分配方案来构建训练样本和测试样本(http://www.robots.ox.ac.uk/~vgg/data/flowers/17/index.html)。相关参数设定为:τ=λ=α=10-6。表6为每类子字典原子个数为30(Ki=30)的识别结果,其中本发明提出的算法效果是最佳的。表6AlgorithmRecognitionRate(%)SRC88.40DLSI88.87LC-KSVD90.20FDDL91.72MFL89.07DL-COPAR91.28DGSDL92.75DCR93.41BDSRLCDL96.47与其它实验类似,针对不同字典原子个数进行了测试实验,字典原子个数取值范围为Ki=[30,35,40,45,50,55,60],实验结果如图6所示。相较于其它算法,本发明提出的算法在字典原子个数变化时都能取得最佳的分类效果,表明提出的识别算法在此数据库上是可行有效的。以上所述,仅是本发明的较佳实施例,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属本发明技术方案的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1