基于内存对象缓存系统的数据预读方法与流程
本发明涉及数据读取技术领域,尤其涉及一种基于内存对象缓存系统的数据预读方法。
背景技术:
基于内存对象缓存系统,它们可以在传统数据库的垂直方向上,加入一特制的缓存结构,不仅可以改进底层数据库的用户请求和事务执行的响应时间,还能够简化其底层的数据库操作,例如:基于键值的数据访问方式。如此一来,可以在付出较小的系统代价下,使得底层数据库在应付海量数据涌入的同时,扩展性得以大幅度提高,具体表现在:缓解了传统外存设备所带来的性能瓶颈,还能够同时在CPU和存储两个方面带来得天独厚的扩展性优势,使其能够适应大数据的动态性变化,较大的减少了不必要的系统I/O。
目前,基于内存对象缓存系统在国内外大中型企业的数据中心内部得到了较大规模的部署和应用,例如:国内淘宝、京东的抢购系统、滴滴的实时叫车系统、国外的Facebook的图片缓存系统以及Twitter数百TB级的缓存系统等等。它们具体用到的内存对象缓存系统主要是开源的Memcached和Redis两种。
Memcached 是一个高性能的分布式的内存对象的缓存系统 ,通过在内存里维护一个统一的巨大的hash 表,能够存储各种格式的数据。一般使用场景是将其部署在一前端结点之上,通过网络与后端的数据库连接。当系统正常运转之后,每次接收到的用户查询(读方向),都会在该位于前端的内存对象缓存系统里寻找其想要的数据,以尽量减少后端数据库的访问次数,以提高外部的动态 Web 等应用之速度和其用户体验。
Redis 同 Memcached 一样,也是一个 C/S 结构的内存对象缓存系统实现,Redis 在很多方面与 Memcached 具有相同的特征,不同的是 Redis 增加了持久化的功能,并支持更多的数据类型,和事务控制。在缓存方面的应用,Redis和Memcached基本类似。
以上两个系统中都是以被动的方式来填充其内存中的数据,也即根据计算机程序的空间局部性原理,当满足了某个用户请求的数据A之后,系统才将该数据保留至该缓存系统中,以便用于下一次访问的命中,从而避免之后的数据库自身的操作,达到节省开销和提升性能的效果。但是,为之付出的代价是第一次访问数据A的性能为次优,而且接下来大量的访问都是在重复这一过程:大量的数据访问请求需要穿透缓存到达数据库(缓存穿透),之后才将满足用户请求的数据保留到缓存中。在大数据高并发这样的系统中,这种次优的解决方案无疑被放大化,致使资源利用率不够充分,后端数据库的I/O过于频繁。同时,大量的网络I/O会产生许多的次网络I/O,极有可能引发缓存无底洞的问题(当缓存系统性能不佳时,通过增加节点,但是依然没有好转的现象),这会导致一次批量操作会涉及多次网络操作,也就意味着批量操作会随着实例的增多,耗时会不断增大。而且如果在某一时刻同时有大量的请求穿透了缓存,所有请求都去查数据库,在这一瞬间会导致数据库CPU和内存负载过高,甚至宕机(缓存雪崩现象)。
技术实现要素:
有鉴于此,针对减少甚至避免缓存穿透以及缓存无底洞现象的发生,减少次优请求的发生等问题,提供一种基于主动工作方式的内存对象缓存系统数据预读方法,该方法可以提高内存对象缓存系统的性能,会根据用户的请求动态的筛选出用户下次最有可能访问的数据并返回到内存对象缓存系统中,并且根据系统资源的使用情况以及当前缓存的命中率来确定返回数据量的大小,从而达到极大化的利用系统资源。
一种基于内存对象缓存系统的数据预读方法,所述的预读方法为当后端数据库第一次返回用户所需数据发出的访问请求时,提取本次数据访问的数据特性,并根据所述数据特性提取相关联的关联性数据,所述的关联性数据随用户所需数据一次性地返回至前端内存对象缓存系统。
作为优选,为了节省空间,并对本发明提出的数据预测算法的部分预测错误预测进行弥补,所述的关联性数据添加到缓存系统的有效时间为6个小时,如果在6个小时之内该数据未被访问,内存对象缓存系统自动销毁该数据占用的内存并释放相应的空间。
所述的预读方法实现包括以下步骤:
S1,当用户发出数据请求后,系统首先判断用户请求的数据是否在内存对象缓存系统中,如果在内存对象缓存系统中命中,系统直接从内存对象缓存系统中将数据返回给用户并结束此次访问;
S2,如果请求的数据未在内存对象缓存系统中命中,监控系统会根据当前系统性能判断是否开启预读功能,如果当前系统性能不佳,监控系统关闭预读功能,并直接访问后台数据库,将用户请求的数据添加到内存对象缓存系统后返回用户请求的数据提供给用户;
S3,如果当前系统性能好,开启预读功能,此时,系统根据当前系统运行的状态、缓存命中率以及用户请求的数据量的大小来确定预读窗口的大小,随后系统从数据库中获取用户请求的数据并将其添加到待缓存队列中,接下来,系统会判断加入到队列中的数据量是否小于预读窗口的大小;
S31,如果队列中的数据小于当前系统的预读窗口大小,系统会判断当前待缓存队列中的最新数据是否在数据库中与其他表中数据存在关联,如果存在关联关系,那么系统将会把相关联的数据加入到待缓存队列中,直至队列中的数据大于预读窗口的大小或者队列中的数据已经再无相关联的数据,一旦队列中的数据大于预读窗口的大小,则跳转到S32,如果队列中的数据已经不存在关联关系,但是依然小于预读窗口的大小,那么系统就会从队列中获取最新数据所在表中的最新N条记录并添加到待缓存队列中,如果最新的N条数据在待缓存队列中已经存在,则继续获取次新的记录添加到待缓存队列中;
S32如果待缓存队列中数据已经大于预读窗口的大小,那么系统直接将待缓存队列中的数据添加到缓存中并返回用户请求的数据。
其中,所述当前系统性能判断包括对系统进行分级,可分为不繁忙状态L1、一般繁忙状态L2及繁忙状态L3三级。
所述的不繁忙状态L1可定义为CPU处于用户模式下的时间百分比和系统模式下的时间百分比之和小于百分之七十,内存使用处于空闲内存占系统总内存的百分比小于等于百分之六十,I/O使用处于每秒进行读写操作的次数相对最大读写次数的百分比小于等于百分之六十,当前网络的使用处于使用的带宽占总带宽的百分比小于等于百分之六十,宽带延迟小于50ms。
所述的繁忙状态L3定义为CPU处于用户模式下的时间百分比和系统模式下的时间百分比之和不小于百分之八十五,内存使用处于空闲内存占系统总内存的百分比不小于百分之八十,I/O使用处于每秒进行读写操作的次数相对最大读写次数的百分比大于等于百分之八十,当前网络的使用处于使用的带宽占总带宽的百分比不小于百分之八十,宽带延迟大于100ms。
处于不繁忙状态L1和繁忙状态L3之间的定义为一般繁忙状态L2。
其中,所述的预读窗口大小由以下条件判断:
系统在不繁忙状态下L1: 缓存命中率较低时:R1=R0*4*2;缓存命中率较高时:R1=R0*4;
系统在一般繁忙状态下L2:缓存命中率较低时:R1=R0*2*2;缓存命中率较高时:R1=R0*2;
系统在繁忙状态下L3:关闭数据预读功能,清理不必要的进程,释放内存空间;
其中定义预读窗口的基本单位为数据表中的一条记录,记为R,记路用户请求的数据对应的数据量为R0。
有益效果:通过在内存对象缓存系统中引入预读和监控系统,有效的提高了缓存的命中率以及系统的稳定性,充分的利用了系统的资源,减少了许多不必要的系统I/O以及其他系统资源的浪费,同时使得内存对象缓存系统体现的更加智能和实时,缓存的更新变得更加的主动。
附图说明
图1 基于内存对象缓存系统的数据预读方法技术路线流程图;
图2基于内存对象缓存系统的数据预读方法中预读功能的实现。
具体实施方式
下面结合附图,对本发明的一种基于内存对象缓存系统的数据预读方法做详细说明。
一种基于内存对象缓存系统的数据预读方法,所述的预读方法为当后端数据库第一次返回用户所需数据发出的访问请求时,提取本次数据访问的数据特性,并根据所述数据特性提取相关联的关联性数据,所述的关联性数据随用户所需数据一次性地返回至前端内存对象缓存系统。更具体的来说,当后端数据库返回用户第一次对A数据发出的访问请求时,通过洞悉本次数据访问的数据特性,将此次未被访问的其他数据关联起来(此处标记为B),B并随着A一次性地返回至前端内存对象缓存系统。之后,当用户第一次提出访问B数据时,可以直接在内存对象缓存系统中找到数据B,而无需经历在后端寻找数据的过程,以提高该数据库系统的性能。换句话说,在系统开销可以接受的情况下,为基于内存对象的缓存系统量身定做一种预读(Read-ahead)算法,并且将其应用至现在的缓存系统运行环境中,以提升整个数据库系统(“整个”指的是前端加后端)的吞吐能力。
如图1所示,当用户首次访问数据库中某一数据时,通过预读算法,将此次未被访问的其他数据关联起来,并随着被访问的数据一次性地返回至数据库。之后,当用户第一次访问到预读到数据库中的数据时,可以直接在缓存中命中,无需经历在后台寻找数据的过程。以此提高缓存的性能并减少非必要I/O;另一方面,需要对数据库进行动态的预读,通过这种策略来决定将哪些数据,多大的数据量加入到缓存中可以使得内存对象缓存系统达到较好的状态。
当user1访问系统,发出请求A时,由于请求的数据不在内存对象缓存系统中,所以该请求会穿过内存对象缓存系统。此时,性能监控系统检测到系统的性能极佳,所以该请求从数据库中获取了请求A所需要的数据A后,系统将对该数据进行分析,随后该请求将携带数据A与数据A相关联的B,C,D一起返回到内存对象缓存系统中,并将user1请求的数据A发送给用户。
当user2访问系统,发出请求B时,由于请求的数据B已经在内存对象缓存系统中,所以系统会直接从缓存中将数据返回给user2。当user3访问系统,发出请求E时,由于请求的数据不在缓存中,所以该请求会穿透内存对象缓存系统,想后台数据库索取数据。但是由于当前系统性能不佳,所以系统关闭了预读功能,只是将用户请求的数据E添加到缓存中并返回给user3;同时,监控系统会清理不必要的进程,释放内存空间,并去掉不必要的I/O操作来对系统进行优化。
当user4访问系统时,此时系统的性能依然很差,所以依然仅从数据库系统中获取请求的数据后,更新缓存并相应user4的请求。
从这些请求过程中可以看出,内存对象缓存系统因为有了预读和监控,变得更加智能,更加主动。预读和监控的加入,使得整个系统更加的稳定和灵活。
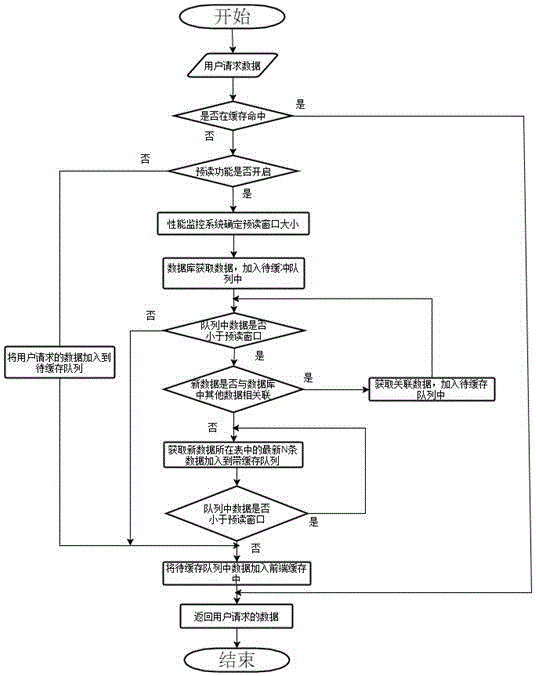
其中预读方法的实现:如图2所示,首先,当一个用户发出数据请求后,系统首先会判断用户请求的数据是否在缓存中,如果在缓存中命中,那么系统直接从内存对象缓存系统中将数据返回给用户并结束此次访问操作;
如果未在内存对象缓存系统中命中,那么此时监控系统会根据当前系统的CPU,内存的使用情况,以及当前发生的I/O情况来判断是否开启预读功能,如果当前系统性能不佳,则监控系统会关闭系统的预读功能,并直接访问后台数据库,将用户请求的数据添加到内存对象缓存系统后返回用户请求的数据给用户;
如果当前系统开启了预读功能,此时,系统会首先根据当前系统运行的状态,缓存命中率以及用户请求的数据量的大小来确定预读窗口的大小,然后,系统从数据库中获取用户请求的数据并将其添加到待缓存队列中,接下来,系统会判断加入到队列中的数据数据量是否小于预读窗口的大小,如果待缓存队列中数据已经大于预读窗口的大小,那么系统直接将待缓存队列中的数据添加到缓存中并返回用户请求的数据。
如果队列中的数据小于当前系统的预读窗口大小,则系统会判断当前待缓存队列中的最新数据是否在数据库中与其他表中数据存在关联,如果存在关联关系,那么系统将会把相关联的数据加入到待缓存队列中。接下来如果加入关联数据后的队列依然小于预读窗口的大小,系统会继续寻找相关联的数据,直至队列中的数据大于预读窗口的大小或者队列中的数据已经再无相关联的数据,一旦队列中的数据大于预读窗口的大小,系统就会将待缓存队列中的数据添加到内存对象缓存系统中,并返回用户需要的数据。如果队列中的数据已经不存在关联关系,但是依然小于预读窗口的大小,那么系统就会从队列中获取最新数据所在表中的最新N条记录并添加到待缓存队列中,如果最新的N条数据在待缓存队列中已经存在,则继续获取次新的记录添加到待缓存队列中。接下来,如此循环,直至待缓存队列中的数据大于预读窗口的大小。
在这里,充分地利用了数据之间的关联关系,尽可能的将和当前数据相关联的数据放入到缓存中。因为相关联的数据在下次被访问到的概率最大。
类似于微博和微信朋友圈,用户最新发布的消息,近期被查看或者修改的可能性最大,而且当前用户进行的某些操作,在接下来其他用户进行相同操作的可能性也极大,所以在本发明提出的数据预读算法中,充分利用了数据和用户操作的时间局部性原理(时间局部性:如果一个信息项正在被访问,那么在近期它很可能还会被再次访问),主动的获取用户请求的数据所对应的表中的最新数据添加到缓存中。
同时,新添加入到缓存的数据默认有效时间是6个小时,如果在6个小时之内该数据未被访问,内存对象缓存系统会自动销毁该数据占用的内存并释放相应的空间。这样做的目的是为了节省空间,并对数据预测算法的部分预测错误预测进行弥补。
在运行预读算法时,需要考虑前端结点和后端结点的网络负载情况。
在这里优先考虑内存对象缓存系统的缓存命中率和系统的运行状况,监控的目的是在当前系统运行状态下达到较大的缓存命中率,所以当用户请求穿透缓存时,需要马上确定系统CPU,内存,I/O,当前网络的使用情况,以及缓存命中率的大小,并根据这些数据以及用户发来的请求所对应的数据特征来确定当前预读窗口的大小;所以每次用户请求对应的预读窗口大小都是不同的。
经过多次的实验测试,本发明根据系统的使用情况定义了系统的三个性能级别:L1,L2,L3 如下所示:
其中
user%:表示CPU处在用户模式下的时间百分比。
sys%:表示CPU处在系统模式下的时间百分比。
free%:表示空闲内存占系统总内存的百分比。
IOPS: 每秒进行读写(I/O)操作的次数,每个硬盘设备都有一个最大值。
IO%:当前每秒进行读写(I/O)操作的次数相对最大IOPS的百分比。
bandwidth%:指当前系统中使用的带宽占总带宽的百分比。
T :表示网络延迟程度。
定义预读窗口的基本单位为数据表中的一条记录,记为R。比如用户此次请求一共涉及到数据表中的10条记录,那么,用户此次请求的数据量为10R。并记用户请求的数据对应的数据量为R0。
在这里,本专利定义数据预读窗口大小如下:
当系统处于L1时,预读窗口大小为用户请求数据量的4倍;如果命中率较低(低于70%),预读窗口再扩大2倍,即此时的预读窗口大小为 R1 = R0 * 4 * 2;如果命中率较高(高于70%),那么此时预读窗口的大小为R1=R0*4;
当系统性能适中时,即系统处于L2状态下,预读窗口大小为用户请求数据量的2倍;如果命中率较低(低于70%),预读窗口再扩大2倍,即此时的预读窗口大小为 R1 = R0 * 2* 2;如果命中率较高(高于70%),那么此时预读窗口的大小为R1=R0*2;
当系统性能极差时,即系统处于L3状态下,那么系统将关闭预读功能,直接返回用户请求的数据。
所以,预读窗口大小计算公式如下:
L1状态下:
缓存命中率较低时:R1=R0*4*2;
缓存命中率较高时:R1=R0*4;
L2状态下:
缓存命中率较低时:R1=R0*2*2;
缓存命中率较高时:R1=R0*2;
L3状态下:关闭数据预读功能。在L3状态下,监控系统会主动清理不必要的进程,释放内存空间,并去掉不必要的I/O操作来对系统进行优化,以及释放一些网络资源,从而达到可以再次开启预读功能的条件。
由此可见,被用来填充内存对象缓存系统的数据,与系统当前的运行状态,缓存命中率以及用户发出请求所对应的数据量的大小有着极大的关系,用来填充内存对象缓存系统的数据具有极大的动态特性。
基于内存对象的缓存系统的数据预读方法,适用于传统数据库和内存数据库系统的结合场景,而且重点在于引入了数据预读算法后,如何在保持系统较高性能的情况下在内存对象缓存系统达到较高的缓存命中率。本发明的实现方法可以充分的应用于实际系统中,具有较好的前景和实用性。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!