一种基于FPGA的全流水粒子群优化算法实现方法与流程
本发明涉及人工智能算法的高速实时信号处理领域,特别涉及一种大规模粒子群优化算法硬件实现方案,具体是一种基于现场可编程门阵列(Field Programmable Gate Array,简称FPGA)硬件全流水粒子群优化算法的实现方法。
背景技术:
粒子群算法(Particles Swarm Optimization,PSO)属于进化类人工智能算法,于1995年由Kennedy和Eberhart两位学者提出,是一种群体智能搜索算法,其原理在于模拟鸟群觅食的过程搜索全局最优解。经过20多年的探索和发展,PSO算法性能趋于完善,与诸如遗传算法、退火算法等进化算法相比,在搜索全局最优值和收敛速度方面的性能更加优越,而且其迭代更新公式的简单数学形式表达,表明其具有易于硬件实现的优势。
目前,PSO算法更多地应用于软件领域,在硬件领域实现的情况少之又少。纵使有少部分学者提出相关实现方案,也仅采用规模很小的种群进行实现,且需耗费大量的硬件资源,而粒子群算法性能与粒子种群大小有着很大的关系,种群越多性能自然越好。因此,原有的小规模种群实现方案完全无法适用于高速实时数字信号处理领域。
FPGA是拥有大规模可编程的门逻辑阵列,具有高度的并行性。近年来,随着FPGA产品性能的快速提升,其在高速实时数字信号处理领域发挥的作用越来越大。从理论上说,采用FPGA非常有利于PSO等并行性搜索算法的实现,但由于传统的并行实现方案是对所有种群粒子采用单独模块的并行实现方式,这样,当PSO的种群规模较大时,这种传统做法需耗费相当多的硬件资源,不适合工程化。
技术实现要素:
本发明要解决的技术问题是:现有的PSO实现方案耗费大量硬件资源,且实时性处理存在困难,针对这些不足之处,本发明利用FPGA全水流信号处理框架,采用多相信号处理方式,在不消耗大量硬件资源的情况下,实现大规模种群的PSO算法,并使其应用到高速实时数字处理领域。
本发明的基本思路是:基于FPGA高速实时运算特性,采用全流水并行实现架构,在FPGA上实现大规模种群PSO算法。本发明的基本原理是:实现PSO算法中一个基本粒子单元的全流水结构,利用全流水特性,采用多相信号处理方式,对特定的相位通道数据给予特定的粒子。这种采用流水线的多相结构方法,完全可以替代多个粒子分别采用独立模块而不得不独占硬件资源的原有方案,这样,便可在不降低工作时钟情况下实现资源的复用。
本发明的技术方案是:一种基于FPGA的全流水粒子群优化算法实现方法,其特征在于,包括以下步骤:
第一步,构建单个种群粒子的流水化处理流程;
第(1)步,描述粒子的处理过程:
为表述方便,记种群规模大小为N,即粒子群数量,种群记为P=(P1,P2,P3,…,PN)T,迭代速度向量记为V=(V1,V2,V3,…,VN)T,种群个体最优值记为Ppbest=(Ppbest1,Ppbest2,...PpbestN)T,种群的全局最优值为Pgbest,对于特定的粒子i在第k次迭代时,其速度和位置的更新过程描述如下等式:
其中,c1,c2是两个常数,取为2;r1,r2是两个范围为[0,1]的随机数;ωk是惯性权重,主要用来平衡算法的局部和全局搜索能力;
其中,1>ωmax>ωmin>0,ωmax,ωmin分别为ω的最大值和最小值,分别取值为0.9和0.4,k为当前迭代次数,K在FPGA实现中记为粒子更新的总次数。
第(2)步,依据更新公式,构建单个粒子硬件流水化实现处理过程;为得到流水化处理结构,其过程可以表示为如图1所示。
首先Ppbest与Pgbest同时与当前的种群粒子位置P作减法,粒子速度矢量V和位置P做相应的延时处理,然后同时做三个乘法器,位置P作相应延时,将乘法之后的结果依次作二输入加法,所得结果再经范围限制判断之后,输出其中一路作为下一次迭代的粒子速度矢量,另一路则与位置P作加法得到的结果共同作为下一次迭代的位置矢量,而位置P在作加法前已作了相应的延时。这样便完成了粒子位置和速度更新过程。
第二步,获取当前种群中的粒子个体最优值和全局最优值;
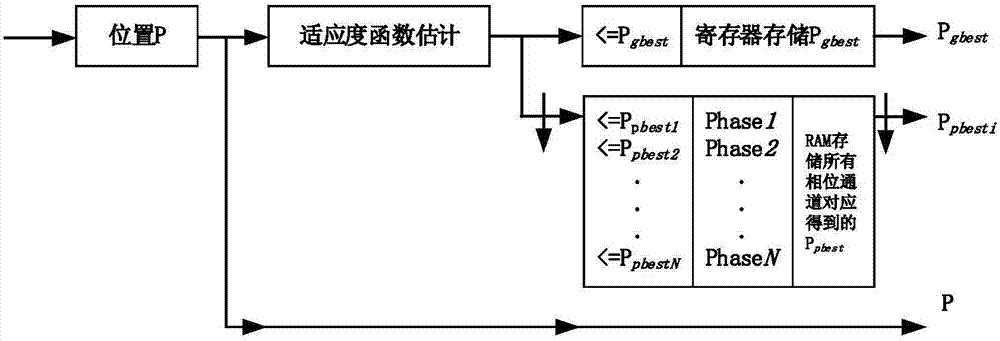
这是采用全流水化多相结构替代并行独立运行的粒子模块的关键步骤,运行流程如图2所示。
不同的粒子位置P依次在对应的相位通道上排好序,数据输入如图3所示。En表示数据有效使能,图3表示种群大小为N的情况,Pij表示第j个相位数据通道的第i个数据,种群大小为N时,有1≤j≤N,位置数据P的处理流程如图2所示,首先通过适应度函数进行值的估计,将输出的一路与Pgbest所对应的估计值进行比较判断,保留最优的Pgbest进行寄存,再在En有效的最后一个时钟周期之后,输出当前迭代种群的全局最优值。而Ppbest则需要用RAM对应的相位通道存储起来,将当前所有粒子对应的Ppbest与RAM特定相位通道存储的Ppbest进行比较并判断后,再保留两者之间较优值作为该粒子当前迭代的个体最优值。如图3中,将P11与P21,P12与P22,P13,P23,…,P1N与P2N作比较判断,并将较优值存储在RAM的Phase1至PhaseN的地址中;图2中的P做相应延时输出作为图1中P的输入数据。
第三步,随机数产生模块的实现;
种群位置和速度初始值以及r1、r2都需要运用随机数产生模块,本发明中均匀伪随机数模块采用LFSR来产生,其产生示意图表示如图4。
其中,在产生伪随机数序列时需要给定初始值,即给定初始01序列,上图产生的是位宽为20的伪随机数。
第四步,连接各个独立模块;
整个算法流程连接如图5所示。
图5中的位置、速度更新模块和Ppbest、Pgbest获取模块分别如图1和图2所示;对于第一个周期内的数据输入,即P11,P12,…,P1N和V11,V12,…,V1N使用初始值,其他情况下使用迭代更新完成后的值。种群粒子位置首先通过Ppbest、Pgbest获取模块,输出当前迭代过程中对应的Ppbest和Pgbest值。同时,把经过延时输出后的P,作为位置、速度更新模块的数据进行输入。为了保证整个算法的流水化过程,速度矢量V,r1,r2,ω都需相应地同时刻输入,这样便可以保证在整个过程中,不同相位通道数据的处理是独立的。
发明附图
图1是种群粒子速度和位置更新流程图;
图2是种群粒子Ppbest和Pgbest获取流程图;
图3是种群粒子位置的输入排序例图;
图4是LFSR产生均匀伪随机数模块图;
图5是总流程图;
图6是128相PSO具体实例中个体和全局最优值获取模块图;
图7是128相PSO具体实例中关键信号时序图。
具体实施方式
下面以一个种群大小是128的PSO算法实现为具体实例说明本发明的实施方式。图4是本发明的总模块流程图,整个流程可以分为四大步骤:
第一步,构建种群粒子位置和速度更新模块;
为表述方便,记种群规模大小为N,即粒子群数量,种群记为P=(P1,P2,P3,…,P128)T,迭代速度向量记为V=(V1,V2,V3,…,V128)T,种群个体最优值记为Ppbest=(Ppbest1,Ppbest2,...Ppbest128)T,种群的全局最优值为Pgbest,对于特定的粒子i在第k次迭代时,其速度和位置的更新过程描述如下等式:
其中,c1,c2是两个常数,取为2;r1,r2是两个范围为[0,1]的随机数;ωk是惯性权重,主要用来平衡算法的局部和全局搜索能力;
其中,1>ωmax>ωmin>0,ωmax,ωmin分别为ω的最大值和最小值,分别取值为0.9和0.4,k为当前迭代次数,K在FPGA实现中记为粒子更新的总次数。K是一个可调节参数,默认值为500。
根据以上等式描述过程,搭建种群粒子位置和速度更新流程如图1所示,
其中i满足1≤i≤128。
第二步,构建个体最优Ppbest和全局最优Pgbest模块。
在构建该模块时,首先需确认目标函数构建,本具体实施方式中,为更好地具体说明,所构建的目标函数如下:
其中,N=128,表示种群大小,该函数的最优值为0,当且仅当
确定好目标函数(适应度估计函数)模块构建之后,Ppbest和Pgbest获取模块的处理流程可以表示如图6所示,其中粒子位置P按对应的相位数据通道排序输入,具体时序表示如图7。
第三步,实现随机数产生模块。
均匀伪随机序列采用LFSR来产生,如图5所示,其产生的位宽为20的伪随机数,针对粒子位置P和速度V以及r1、r2所需要的位宽表示不一致的情况,故构建的LFSR也不一一相同,本实例中,位置P和速度V采用32位宽的伪随机数,而r1、r2则采用25位宽的伪随机数。
第四步,连接各个独立模块,构建整个算法流程。该步骤构建本发明的总流程图,如图2所示。需要注意的是,为完成整个算法流程的流水化,各个环节之间都需要将模块输入和输出对应的时序对齐,如:根据算法的整体延时情况,调节存储粒子位置P和存储粒子速度V的RAM读出延时情况等。这样,使得各个对应相位通道的数据能够对齐输入到粒子位置、速度更新模块中,确保运算结果的正确性。
- 还没有人留言评论。精彩留言会获得点赞!