基于图像中的显著物体的物体识别方法与流程
本发明涉及一种基于图像中的显著物体的物体识别方法。
背景技术:
近些年来,深度卷积神经网络在物体识别,物体定位和图像分割领域已经取得了重大的进展。通过基于深度卷积神经网络的物体识别算法,在个别任务上,机器的识别准确率甚至已经超过了人类。
另外一些算法,在现有技术中公开的R-CNN算法、Faster R-CNN算法、YOLO(you only look once)算法、SSD算法以及R-FCN算法在物体定位和图像分割领域也取得很大的成功,得到了较高的准确率。
然而这些方法普遍存在识别物体种类较少(20~80类),以及对于新的物体种类,需要大量带标签的训练集,花费大量时间重新训练神经网络,才能达到识别的效果。此外,绝大部分物体定位和识别算法缺乏对同类物品中不同个体的区分能力。
因此存在对如下的物体识别方法的需求,该方法无需重新训练神经网络,只需通过较为简单的步骤,可识别新的物体。此外,该方法需要识别精度高,定位准确,扩展性强,可快速扩展物体种类,区分物体个体差异强的特点。
技术实现要素:
本发明的目的旨在解决现有技术中存在的上述问题和缺陷的至少一个方面。
根据本发明的一个方面,提供一种基于图像中的显著物体的物体识别方法,所述方法包括:
训练过程,所述训练过程用于建立分类数据库,在所述分类数据库中包括用于描述多个物体的第一特征向量,每个物体由至少一个第一特征向量表示;以及
识别过程,所述识别过程包括如下的步骤:
S21:将包含物体的图片输入到深度卷积神经网络中,将图片划分成M*M个网格,每个网格预测N个候选框,并针对整个图片的M*M*N个候选框中的每个候选框,得出每个候选框内存在物体的概率,其中M和N为大于等于1的整数;
S22:当存在物体的概率大于或等于预定阈值时,选取该概率所对应的候选框作为第一有效候选框;
S23:将第一有效候选框的图像输入到分类神经网络中以获取第二特征向量;以及
S24:基于所述第二特征向量、第一特征向量以及分类数据库,执行k最近邻分类算法(KNN)以识别出物体的类别。
在本发明的一个优选实施例中,所述方法还包括如下的步骤:
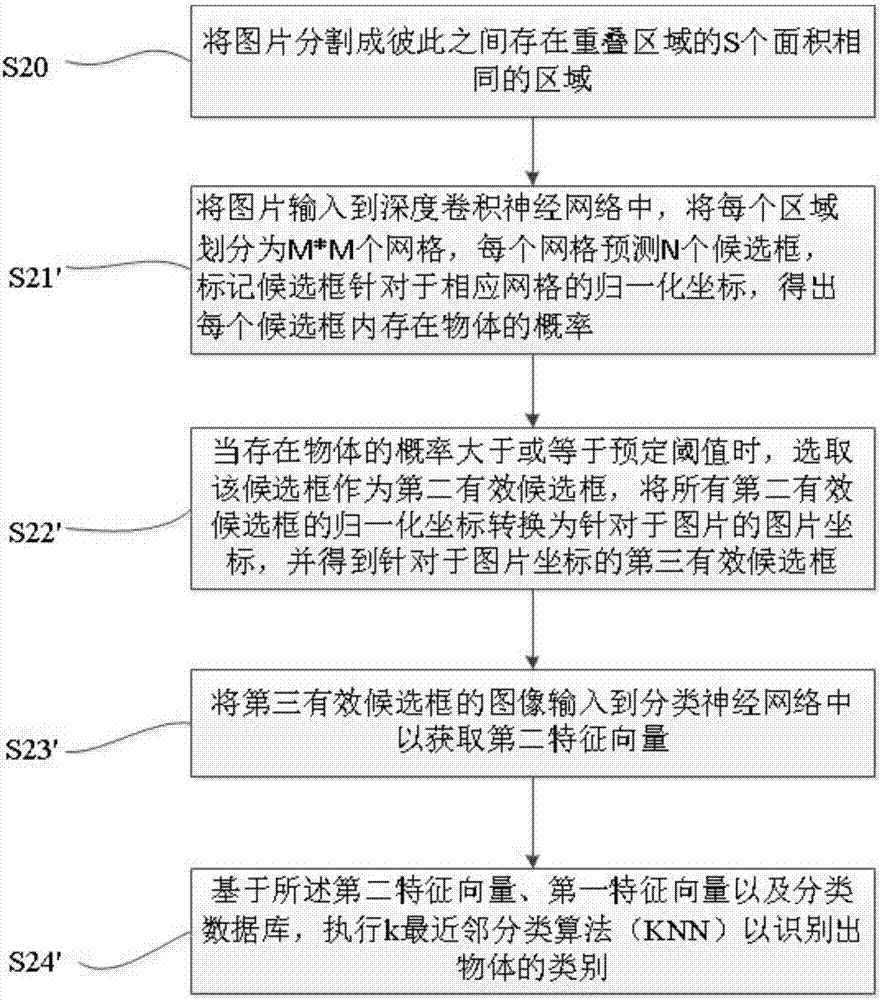
S20:在将包含物体的图片输入到深度卷积神经网络的之前,将图片分割成彼此之间存在重叠区域的S个面积相同的区域,S为大于等于1的整数。
在根据本发明的一个优选实施例中,所述方法在步骤S20之后还包括如下的步骤:
S21’:将包含S个区域的图片输入到深度卷积神经网络中,将S个区域中的每个区域划分成M*M个网格,每个网格预测N个候选框,在每个网格中标记N个候选框针对于相应网格的归一化坐标,并针对于整个图片的M*M*N*S个候选框中的每个候选框,得出每个候选框内存在物体的概率;
S22’:当存在物体的概率大于或等于预定阈值时,选取该概率所对应的候选框作为第二有效候选框,将所有区域中的第二有效候选框的归一化坐标转换为针对于包含物体的图片的图片坐标,并得到针对于图片坐标的第三有效候选框,
S23’:将第三有效候选框的图像输入到分类神经网络中以获取第二特征向量;以及
S24’:基于所述第二特征向量、第一特征向量以及分类数据库,执行k最近邻分类算法(KNN)以识别出物体的类别。
在根据本发明的一个优选实施例中,所述训练过程包括如下的步骤:
S11:以第一角度、第一距离和第一光照对至少一个物体进行拍摄以获取图片;
S12:将图片输入到深度卷积神经网络中以生成至少一个候选框;
S13:手动地确定该目标候选框在图片中的坐标并选取每个物体的目标候选框,并且存储该目标候选框中的图像;
S14:以不同于第一角度、第一距离和第一光照的多个角度、多个距离和多个光照对至少一个物体进行拍摄以获取多个不同的图片;
S15:对获取的多个不同的图片执行上述的步骤S12和S13;
S16:将存储的所有图像使用分类神经网络进行特征提取以得到第一特征向量;
S17:将提取出的所有第一特征向量存储到分类数据库中,其中在该分类数据库中存储用于描述多个物体的第一特征向量。
在根据本发明的一个优选实施例中,所述深度卷积神经网络是基于显著物体的YOLO神经网络,以及所述分类神经网络是卷积神经网络(CNN)。
在根据本发明的一个优选实施例中,所述特定阈值位于0.1至1的范围内。
在根据本发明的一个优选实施例中,所述方法还包括如下的步骤:在步骤S22之后和步骤S23之前,对第一有效候选框执行非极大值抑制算法以进一步筛选第一有效候选框,以将筛选出的有效候选框用在步骤S23中;其中,非极大值抑制所用的阈值位于0至0.6的范围内。
在根据本发明的一个优选实施例中,所述方法还包括如下的步骤:在步骤S22’中,对第二有效候选框执行非极大值抑制算法以进一步筛选第二有效候选框,以将筛选出的有效候选框进行坐标转换;对坐标转换之后的得到第三有效候选框执行非极大值抑制算法以将筛选出的有效候选框用在步骤S23’中;以及其中,非极大值抑制所用的阈值位于0至0.6的范围内。
在根据本发明的一个优选实施例中,CNN网络基于SqueezeNet模型、VGG模型和ResNet模型中的任一种。
在根据本发明的一个优选实施例中,k最近邻分类算法是基于投票委员会机制的k最近邻分类算法。
通过根据本发明的基于图像中的显著物体的物体识别方法,对整个图片划分出了M*M个网格,并且每个网格中预测出N个候选框,针对整个图片的M*M*N个候选框预测每个候选框中存在物体的概率。在该概率小于一阈值的情况下,过滤掉非有效候选框,例如表示背景图像的候选框。然后利用分类功能和物体特征描述功能更加强大的分类神经网络对有效候选框中的物体特征进行分类。在该识别过程中,通过概率阈值筛选和分类网络的二级分类处理可以进行多级特征分类,从而提高分类和物体识别的精度。
附图说明
图1是根据本发明的示例性实施例的基于图像中的显著物体的物体识别方法的一种识别过程的流程图。
图2是根据本发明的示例性实施例的基于图像中的显著物体的物体识别方法的另一种识别过程的流程图。
图3是根据本发明的示例性实施例的基于图像中的显著物体的物体识别方法的训练过程的流程图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。下述参照附图对本发明实施方式的说明旨在对本发明的总体发明构思进行解释,而不应当理解为对本发明的一种限制。
另外,在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本披露实施例的全面理解。然而明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。
在对本发明的方法进行说明之前,首先将介绍现有技术中的基于YOLO(you only look once)神经网络的物体识别方法。YOLO的设计理念遵循端到端训练和实时检测。YOLO将输入图像划分为S*S个网络,如果一个物体的中心落在某网格(cell)内,则相应网格负责检测该物体。在训练和测试时,每个网络预测B个Bounding Boxes,每个Bounding Box对应5个预测参数,即Bounding Box的中心点坐标(x,y),宽高(w,h),和置信度评分。这里的置信度评分(Pr(Object)*IOU(pred|truth))综合反映基于当前模型Bounding Box内存在目标的可能性Pr(Object)和Bounding Box预测目标位置的准确性IOU(pred|truth)。如果Bounding Box内不存在物体,则Pr(Object)=0。如果存在物体,则根据预测的Bounding Box和真实的Bounding Box计算IOU,同时会预测存在物体的情况下该物体属于某一类的后验概率Pr(Class_i|Object)。假定一共有C类物体,那么每一个网格只预测一次C类物体的条件类概率Pr(Class_i|Object),i=1,2,...,C;每一个网格预测B个Bounding Box的位置。即这B个Bounding Box共享一套条件类概率Pr(Class_i|Object),i=1,2,...,C。基于计算得到的Pr(Class_i|Object),在测试时可以计算某个Bounding Box类相关置信度:Pr(Class_i|Object)*Pr(Object)*IOU(pred|truth)=Pr(Class_i)*IOU(pred|truth)。如果将输入图像划分为7*7网格(S=7),每个网格预测2个Bounding Box(B=2),有20类待检测的目标(C=20),则相当于最终预测一个长度为S*S*(B*5+C)=7*7*30的向量。
在该传统方法中,在预测Bounding Box位置的同时,还预测该位置出的物体类别。但是基于传统YOLO的物体识别方法存在如下的局限:(1)最终有一个全连接层,所以各单元格能够利用全局信息,但是造成初始图片只能缩放成固定大小;(2)初始图片有缩放,则可能对不同缩放比的物体覆盖不全,造成无法识别极端缩放比的物体;(3)每一个单元格只选择一个物体框来用,并只预测一个类别,所以当多个物体中心落入一个单元格时,YOLO无能为力,表现成不能识别到小物体;(4)但是受限于标注图像训练集成本高,其可检测的物体种类比较少,且可拓展性低。
考虑到上述缺点,本发明提出了一种基于图像中的显著物体的识别方法,在该方法中,在确定Bounding Box时,仅预测该Bounding Box中存在物体的概率而不同时告知该物体的类别,物体类别的确认交由分类神经网络来实现,因此本发明的识别方法是基于发现图像中的显著物体而实现的,而不同时给出该物体的类别。
根据本发明的总的发明构思,本发明提供一种基于图像中的显著物体的物体识别方法,所述方法包括训练过程和识别过程。所述训练过程用于建立分类数据库,在所述分类数据库中包括用于描述多个物体的第一特征向量,每个物体由至少一个第一特征向量表示。
如图1所示,在根据本发明的一个实施例中,所述识别过程包括如下的步骤:
S21:将包含物体的图片输入到深度卷积神经网络中,将图片划分成M*M个网格,每个网格预测N个候选框,并针对整个图片的M*M*N个候选框中的每个候选框,得出每个候选框内存在物体的概率,其中M和N为大于等于1的整数;
S22:当存在物体的概率大于或等于预定阈值时,选取该概率所对应的候选框作为第一有效候选框;
S23:将第一有效候选框的图像输入到分类神经网络中以获取第二特征向量;以及
S24:基于所述第二特征向量、第一特征向量以及分类数据库,执行k最近邻分类算法(KNN)以识别出物体的类别。
在根据本发明的物体识别方法中,在步骤S21中,对整个图片划分出了M*M个网格,并且每个网格中预测出N个候选框,在根据本发明的一个优选实施例中,M是7,N是2。此外,针对整个图片的M*M*N个候选框预测每个候选框中存在物体的概率。在该概率小于一阈值的情况下,过滤掉非有效候选框,例如表示背景图像的候选框。然后利用分类功能和物体特征描述功能更加强大的分类神经网络对有效候选框中的物体特征进行分类。在该识别过程中,通过概率阈值筛选和分类网络的二级分类处理可以进行多级特征分类,从而提高分类的精度。
此外,该物体识别方法不需要在给出Bounding Box的同时告知其中包含物体的种类,只需要告知Bounding Box中是否包含图像中较为显著的物体即可。故在图像标注中,对图像中所有显著物体进行标注。所谓显著物体即为图像中较为明显、突出的物体。在完成模型训练后,实测表明,该方法检测物体的能力大大提高且其具备检测生活中绝大部分的物体。以可乐易拉罐为例,检测距离由50cm提高至100cm。
根据本发明的一个示例性实施例,在步骤S22中所使用的特定阈值位于0.1至1的范围内。例如,包含物体的概率小于0.1的Bounding Box都被舍弃。
如上所述,现有技术中的YOLO网络无法识别图像中的小物体。在根据本发明的一个示例性实施例中,提供了一种物体识别方法,该方法可以改进上述的缺点,识别出图像中的小物体,如图2所示,该方法包括如下的步骤:
S20:在将包含物体的图片输入到深度卷积神经网络的之前,将图片分割成彼此之间存在重叠区域的S个面积相同的区域;其中S为大于等于1的整数
S21’:将包含S个区域的图片输入到深度卷积神经网络中,将S个区域中的每个区域划分成M*M个网格,每个网格预测N个候选框,在每个网格中标记N个候选框针对于相应网格的归一化坐标,并针对于整个图片的M*M*N*S个候选框中的每个候选框,得出每个候选框内存在物体的概率;
S22’:当存在物体的概率大于或等于预定阈值时,选取该概率所对应的候选框作为第二有效候选框,将所有区域中的第二有效候选框的归一化坐标转换为针对于包含物体的图片的图片坐标,并得到针对于图片坐标的第三有效候选框,
S23’:将第三有效候选框的图像输入到分类神经网络中以获取第二特征向量;以及
S24’:基于所述第二特征向量、第一特征向量以及分类数据库,执行k最近邻分类算法(KNN)以识别出物体的类别。
在本发明的一个示例中,M是7,N是2,S是9。在实际的操作中,为提高YOLO检测小型物体的距离,对图像进行分块处理操作。在根据本发明的物体识别方法中,摄像头采样数据尺寸为640×480,将其分为有彼此之间存在重叠的9块(或其他数字),每块的大小为250×190。其中x轴分段:0到250,195到445,390到640;y轴分段:0到190,145到335,290到480。将分割后的9块图像分别投入YOLO网络,并对每一幅图像得到的98个(7*7*2)Bounding Box进行过滤,即将得分低于0.1的Bounding Box舍弃后以得到有效物体区域。然后,将9块图像中得到的所有的有效区域的坐标变换至原图像坐标,之后再对原图像坐标下有效区域。在这一系列操作完成之后得到的有效区域即为得到的最终有效特征区域。
通过上述的物体识别方法,使得对小物体的检测效率大大提高,检测可乐罐的有效距离可达3.5米,且其具备检测图像中绝大部分显著物体的能力。另外由于网络结构较为简单,尺寸较小,进行多区域检索并不影响其运行效率。
考虑到当前的基于YOLO的神经网络在训练过程中所耗费的时间之长,根据本发明的物体识别方法提出了如下的训练过程,如图3所示,所述训练过程包括:
S11:以第一角度、第一距离和第一光照对至少一个物体进行拍摄以获取图片;
S12:将图片输入到深度卷积神经网络中以生成至少一个候选框;
S13:手动地确定该目标候选框在图片中的坐标并选取每个物体的目标候选框,并且存储该目标候选框中的图像;
S14:以不同于第一角度、第一距离和第一光照的多个角度、多个距离和多个光照对至少一个物体进行拍摄以获取多个不同的图片;
S15:对获取的多个不同的图片执行上述的步骤S12和S13;
S16:将存储的所有图像使用分类神经网络进行特征提取以得到第一特征向量;
S17:将提取出的所有第一特征向量存储到分类数据库中,其中在该分类数据库中存储用于描述多个物体的第一特征向量。
因此,通过如上所述的根据本发明的物体训练过程,可以通过简单的步骤建立分类数据库,并且在这些数据库中,物体特征的可扩展性很强,可以根据用户的需求灵活地设置,并且省去了重新训练神经网络的过程,节省了时间。
考虑到基于显著物体的YOLO神经网络在预测Bounding Box中包含物体的概率方面具有突出的能力。因此在根据本发明的一个示例性实施例中,在步骤S21、S21’和S12中使用的深度卷积神经网络是基于显著物体的YOLO神经网络,以及在步骤S23、S23’和S15中使用的分类神经网络是卷积神经网络(CNN)。
在步骤S22之后,即使通过候选框中包含物体的概率必须大于或等于某一阈值过滤掉了一部分不匹配的候选框,但是同一个物体还是可能由多个候选框来标注,这些候选框之间存在一定的重叠,且每个候选框具有不同的置信值,因此在根据本发明的一个示例性实施例中,步骤S22之后和步骤S23之前,对第一有效候选框执行非极大值抑制算法以进一步筛选第一有效候选框,以将筛选出的有效候选框用在步骤S23中。在根据本发明的一个示例性实施例中,在步骤S22’中,对第二有效候选框执行非极大值抑制算法以进一步筛选第二有效候选框,以将筛选出的有效候选框进行坐标转换;对坐标转换之后的得到第三有效候选框执行非极大值抑制算法以将筛选出的有效候选框用在步骤S23’中。在根据本发明的一个示例性实施例中,进行非极大值抑制所用的置信值阈值位于0至0.6的范围内。
在根据本发明的一个示例性实施例中,CNN网络基于SqueezeNet模型、VGG模型和ResNet模型中的任一种。如上仅仅列举出了CNN所采用的分类模型的优选实施例,能够进行分类计算的模型均应落在本发明的保护范围之内。上述两种方案具有相同的特点。SqueezeNet模型和VGG模型的区别在于计算量具有一定的差距,故此对物体的描述能力有强弱之分。二者相较,SqueezeNet的计算量级更低,但相比于VGG描述能力相对较弱。在根据本发明的优选实施例中,考虑到计算速度的原因,选取更加经济合算的SqueezeNet模型。
对于k最近邻分类算法的选择可以采用传统的k最近邻分类算法,其中,传统KNN分类方法的做法是,将数据库中不同的类别形成一个特征空间,每个类别的特征向量单独形成一个独立的区域。当希望对表示某种物体的新得到的特征向量进行分类时,需计算新特征向量到每个类别的特征向量组成的区域的距离(设其距离为Dmin),当新特征向量到A类别的特征向量组成的区域的距离最小时,将该新特征向量所表述的物体归属于A类别。需要对Dmin进行衡量,为此需确定一个阈值,当Dmin大于该阈值时,分类结果将被舍弃,即认为新特征向量不属于原数据库中的任何一种类别。
但是,在数据库中类别较多或特征向量的描述性不够强时,利用基于投票委员会的k最近邻分类算法。在基于投票委员会的k最近邻分类算法,使用Pearson相关系数对特征向量与分类数据库中的所有特征向量进行比对,在得到若干组相关系数后,对每组中的相关系数进行排序。通常,在每组相关系数中,选取相关系数最高的T个值组成投票委员会,因此得到若干组投票委员会,并分别对每组中的T个值进行加权。加权方式可采用线性加权、指数加权、Sigmoid型加权等。
然后,对加权后的值进行归类相加,即把委员会中归属于同一类物体的T个相关系数进行求和得到一个加权和值。此外,设置两个阈值,第一个阈值称为差值阈值,即得分最高的类别的加权和值减去得分次高类别的加权和值的差须大于此阈值,将其设在0.3,但不排除其他值也是可行的。第二个阈值为决定阈值,即最高加权和值必须大于此门限,将其设在2,但不排除其他值也是可行的。当最高加权和值满足此上两个条件时,才认为分类结果真实有效。
本领域的技术人员可以理解,上面所描述的实施例都是示例性的,并且本领域的技术人员可以对其进行改进,各种实施例中所描述的结构在不发生结构或者原理方面的冲突的情况下可以进行自由组合。
虽然结合附图对本发明进行了说明,但是附图中公开的实施例旨在对本发明优选实施方式进行示例性说明,而不能理解为对本发明的一种限制。
虽然本总体发明构思的一些实施例已被显示和说明,本领域普通技术人员将理解,在不背离本总体发明构思的原则和精神的情况下,可对这些实施例做出改变,本发明的范围以权利要求和它们的等同物限定。
应注意,措词“包括”不排除其它元件或步骤,措词“一”或“一个”不排除多个。另外,权利要求的任何元件标号不应理解为限制本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!