一种基于身份替代的隐私保护方法及系统与流程
本发明涉及数据处理技术领域,特别是涉及一种基于身份替代的隐私保护方法及系统。
背景技术:
隐私(privacy):指个人、组织等实体不愿意被外部获取的信息。泄露(disclosure):不希望发布的数据或信息,被明确的发布出来或通过发布的数据可能间接推断出准确度较高的信息,当发生以上情况时称发生了泄露。标识符(Identifier):一张数据记录表中能唯一标识一条记录的属性。例如原始数据表T0(如表1所示)中的病例编号,通过该编号,可以唯一的从所有病例中查找到该条记录,所以病例编号为标识符。数据表的标识符并不唯一,例如表中的身份证号码,也是该记录的标识符。
表1原始数据表T0
准标识符QI(Quasi-Identifier):准标识符是一个数据实体集的属性集合中的一组属性,通过该组属性,可以将一条记录从数据表中查询出来。表1中性别、年龄、身高组成了准标识符,通过三个属性的组合可以从表中查找出一条记录。例如:select*from T0where性别=‘男’and年龄=‘25’and身高=‘175’,就可以查询到病例编号为4533747的整条记录获取该条记录的敏感属性(疾病)为骨折。
抑制与泛化:抑制是指针对标识符做不发布处理,因为标识符和某些属性有很强的查询能力,所以针对这些属性做抑制处理是比较恰当的选择。泛化指降低数据的精度,针对数值数据如年龄35可以泛化为30-40,使得原始数据包含在泛化后的结果中;针对字符串数据,可采用上位词来对数据进行泛化。
去除标识符后的匿名数据表T1(如表2所示),设一外部链接表T2(如表3所示)。
表2去除标识符的匿名数据表T1
表3外部链接数据表T2
链接攻击(Link-Attack):通过准标识符QI将两张或多张数据表链接,提高数据表维度,挖掘数据表中的隐私信息的攻击方式称之为链接攻击。通过对表T1和T2的准标识符的组合(性别、年龄)进行链接操作可以得到连接数据表Tlink(如表4所示),在表中原本被匿名的记录重新被标识,完全失去的匿名效果,造成了隐私泄露。这就是链接攻击的基本原理。
表4通过链接得到的数据表Tlink
表5满足k=2的k匿名数据表Tk
K匿名(K-Anonymity):设一张数据表RT(A1,...,An)的准标识符为QIRT,当每个针对QIRT的查询包含至少K个结果时,称数据表RT满足K匿名。表Tk(如表5所示)是对T1进行k=2的匿名处理后的发布结果。表中每两条记录的准标识符完全相同。针对每组准标识符的查询都会返回至少2条记录,所以表Tk满足2匿名。
背景知识(background knowledge):背景知识是攻击者获取的与攻击目标有关的信息,这些信息来源于方方面面,具有多样性,复杂性,不可预知性等特点,给隐私保护带来了严峻的挑战。
泄露风险(Risk):表示根据发布的数据和背景知识披露隐私造成隐私泄露的概率。记敏感数据为p,背景知识为b,则在背景知识b的帮助下隐私泄露风险Risk(p,b)可以表示为(其中P表示概率):Risk(p,b)=P(p|b)。
随着科技的发展,数字化技术使得全球每时每刻都在产生大量的新数据,据统计2012年全球信息总量达到了2.7ZB,据估计2015年全球信息量将达到8ZB,网络化和物联网技术使得全球的数据能够在网络中共享,但是随之而来的隐私泄露的问题也相当严峻。随着大数据技术的飞速发展,数据收集、数据共享成为时代的主流。大数据意味着价值,但是数据分析,数据挖掘等技术给隐私保护带来了前所未有的挑战。大数据未能妥善处理会对用户的隐私造成极大的侵害。大数据隐私问题已经成为当务之急,隐私问题已经逐渐被公众所重视。多项实际案例说明。即使无害的数据被大量收集后。也会暴露个人隐私。
目前已有方案分别有以下三种::
第一、简单抑制与泛化
具体步骤如图1所示:首先设置泛化和抑制的相关参数,设置哪些参数需要泛化哪些需要抑制;从数据源读取数据;对数据进行泛化抑制处理;把处理后的数据添加到发布数据集中供发布使用。
然而去掉标识符后发布数据,方法简单,也在大数据到来之前起到了一定的隐私保护效果,但是随着大数据的到来,仅仅去掉标识符已经不能起到很好的保护作用。简单抑制与泛化方法在链接攻击下基本起不到任何隐私保护作用,隐私保护强度太差。
第二、k匿名
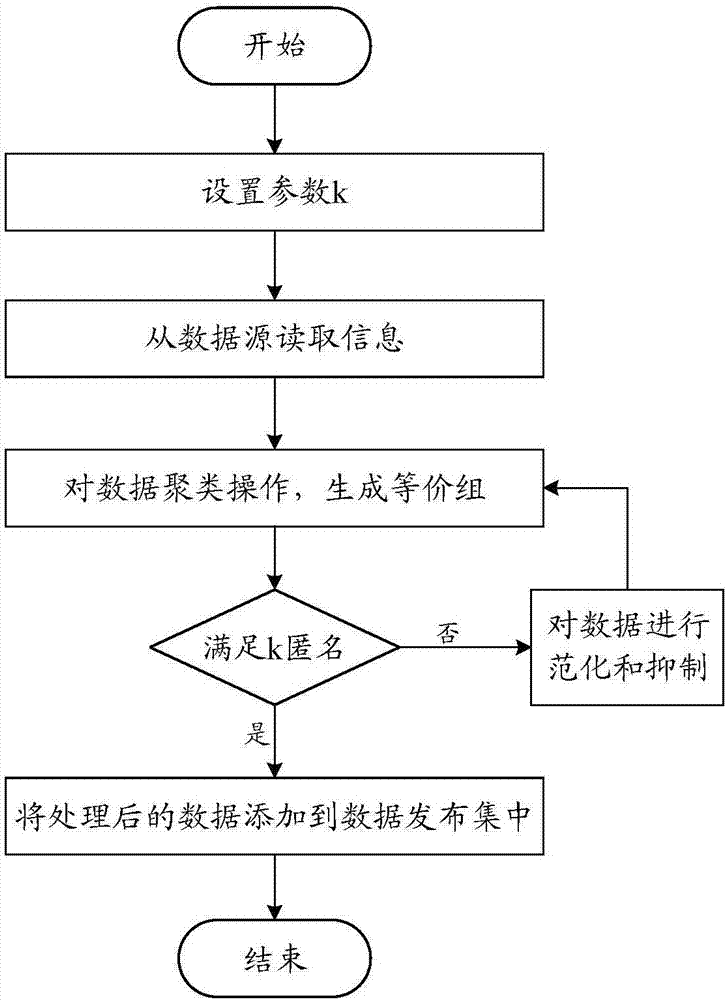
k匿名方法的核心思想就是设法切断准标识符与敏感属性之间的一对一关系来保隐私属性。在一个数据表中,一个记录的准标识符至少有(k-1)个记录的准标识符与之相同。换句话说就是,根据准标识符的查询结果至少包含K条记录,在准标识符上,任意一条与其他k-1条记录无法区分。
具体步骤如图2所示:设置k匿名参数k;从数据源读取数据;对数据进行聚类操作,生成等价组;判断是否已经满足k匿名的要求;如果满足要求就将数据添加到发布数据集中等待发布;如果不满足,就对数据进行泛化和抑制操作后,重新进行聚类操作直至满足k匿名要求。
k匿名最大的优点在于核心思想简单便于理解,但在具体实施过程中参数的选取以及实现算法直接决定了处理结果的好坏,隐私保护效果好并且数据可用性高的算法需要耗费大量的时间在等价组的选取中,效率高的算法不能同时保证保护程度和数据可用性。有时为了达到k匿名的要求,会对原始数据造成过度的抑制和泛化,严重影响到数据的可用性,降低了数据的价值。隐私保护强度较差,过度处理降低数据价值,无法抵御背景知识攻击。
第三、差分隐私
差分意思策略的核心思想是对于一个统计数据库,添加一条给数据库。数据分析者对数据库使用统计函数f(比如计数,求和等),获得f(D)。此时把新添加的记录从D中删除得到数据库D1,对D1使用统计函数f得到f(D1)。如果f(D1)和f(D)的结果非常接近,则可以断定新添加的记录并没有因为将自己的信息提供给研究机构而存在隐私泄露的风险。差分隐私保护就是确保任意一条记录被添加或者删除都不会对分析结果造成影响。
具体步骤如图3所示:差分隐私的相关参数;从数据源读取数据;根据不同的噪音机制向数据集中添加噪音;把处理后的数据添加到发布数据集中,供发布使用。
差分隐私最大的优点在于有严谨的理论论证,并证明了在最严格的攻击模型下,仍然能起到隐私保护的作用。但差分隐私的噪音机制使得添加的噪音与原始数据无关,虽然保证了数据某些方面的统计特性,但这有可能造成单条数据失真比较严重的情况发生。这样就无法保证在提供隐私的保护的同时维持单条数据的数据特性。单条数据处理后失真严重,很难维持数据原有特性。
因此,在对数据处理时,如何保护数据的隐私性的同时确保数据的可用性是目前亟需解决的技术问题。
技术实现要素:
本发明的目的是提供一种基于身份替代的隐私保护方法,可提高处理后处理的隐私性和可用性。
为实现上述目的,本发明提供了如下方案:
一种基于身份替代的隐私保护方法,所述隐私保护方法包括:
根据数据范化参数对高敏感数据的身份属性集进行范化处理,生成虚拟身份集;
根据所述身份属性集和虚拟身份集,确定处理后的身份偏移量和处理后的特征偏移量;
分别判断所述处理后的身份偏移量是否满足身份偏移量阈值的要求以及处理后的特征偏移量是否满足特征偏移量阈值的要求,如果满足,则将处理后的虚拟身份集替换发布数据集中对应的高敏感数据,以进行发布;否则,根据判断结果调整所述数据范化参数。
可选的,所述隐私保护方法还包括:
对收集的原始数据,进行预处理,生成高敏感数据。
可选的,所述预处理的方法包括:
去除原始数据中的错误信息和缺失信息。
可选的,所述确定处理后的身份偏移量和处理后的特征偏移量的方法包括:
根据所述身份属性集V和虚拟身份集Vid确定虚拟身份vidn对应的单属性偏移量δn:
其中,V=v1,v2,...,vN,Vid=vid1,vid2,...,vidN,其中,n表示身份属性vn和虚拟身份vidn的序号,n=1,2,...,N;
根据所述单属性偏移量δn确定单属性相似度λn:
λn=1-δn------------公式(2);
根据各所述单属性相似度确定身份相似度α:
其中ξn为身份属性vn的影响因子;
根据所述身份相似度α计算处理后的身份偏移量Δid:
Δid=1-α------------公式(4);
根据所述身份属性集V确定身份属性特征向量根据所述虚拟身份集Vid确定虚拟身份
根据所述身份属性特征向量和虚拟身份确定特征相似度β:
根据所述特征相似度β确定处理后的特征偏移量Δch:
Δch=1-β------------公式(6)。
可选的,ξ1=ξ2=...=ξN=1。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明基于身份替代的隐私保护方法通过对数据处理生成一个虚拟身份,这样可以很大程度上保存数据的原有特征;用虚拟身份将原始数据从发布数据中替换掉,原始数据不出现在发布数据中,原始数据虽然不出现在发布数据中,但是代表原始数据的特征的虚拟身份存在于发布数据中,能够保证数据的可用性,并且提高隐私保护的强度。
本发明的另一目的是提供一种基于身份替代的隐私保护系统,可提高处理后处理的隐私性和可用性。
为实现上述目的,本发明提供了如下方案:
一种基于身份替代的隐私保护系统,所述隐私保护系统包括:
设置模块,用于设置数据范化参数、身份偏移量阈值及特征偏移量阈值;
范化模块,用于根据所述数据范化参数对高敏感数据的身份属性集进行范化处理,生成虚拟身份集;
计算模块,用于根据所述身份属性集和虚拟身份集,确定处理后的身份偏移量和处理后的特征偏移量;
判断模块,用于分别判断所述处理后的身份偏移量是否满足身份偏移量阈值的要求以及处理后的特征偏移量是否满足特征偏移量阈值的要求;
替换模块,分别与所述判断模块和范化模块连接,用于在所述判断模块的判断结果为满足时,将处理后的虚拟身份集替换发布数据集中对应的高敏感数据,以进行发布;
所述判断模块还与所述设置模块连接,所述设置模块用于在所述判断模块的判断结果为不满足时,根据所述判断结果调整所述数据范化参数。
可选的,所述隐私保护系统还包括:
预处理模块,与所述范化模块连接,用于对收集的原始数据,进行预处理,生成高敏感数据,并发送至所述范化模块。
可选的,所述预处理模块对收集的原始数据,进行预处理具包括:去除原始数据中的错误信息和缺失信息。
可选的,所述计算模块包括:
属性偏移量计算单元,用于根据所述身份属性集V和虚拟身份集Vid确定虚拟身份vidn对应的单属性偏移量δn;
属性相似度计算单元,用于根据所述单属性偏移量δn确定单属性相似度λn;
身份相似度计算单元,用于根据各所述单属性相似度确定身份相似度α;
身份偏移量计算单元,用于根据所述身份相似度α计算处理后的身份偏移量Δid;
特征向量确定单元,用于分别根据所述身份属性集V确定身份属性特征向量根据所述虚拟身份集Vid确定虚拟身份
特征相似度计算单元,用于根据所述身份属性特征向量和虚拟身份确定特征相似度β;
特征偏移量计算单元,用于根据所述特征相似度β确定处理后的特征偏移量Δch。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明基于身份替代的隐私保护系统通过设置范化模块、计算模块和判断模块,对数据处理生成一个虚拟身份,这样可以很大程度上保存数据的原有特征;通过设置替换模块,用虚拟身份将原始数据从发布数据中替换掉,原始数据不出现在发布数据中,原始数据虽然不出现在发布数据中,但是代表原始数据的特征的虚拟身份存在于发布数据中,能够保证数据的可用性,并且提高隐私保护的强度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为简单抑制与范化处理流程图;
图2为K匿名处理流程图;
图3为差分隐私处理流程图;
图4为本发明基于身份替代的隐私保护方法的流程图;
图5为本发明基于身份替代的隐私保护系统的模块结构示意图。
符号说明:
设置模块—1、预处理模块—2、范化模块—3、计算模块—4、判断模块—5、替换模块—6。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于身份替代的隐私保护方法,通过对数据处理生成一个虚拟身份,这样可以很大程度上保存数据的原有特征;用虚拟身份将原始数据从发布数据中替换掉,原始数据不出现在发布数据中,原始数据虽然不出现在发布数据中,但是代表原始数据的特征的虚拟身份存在于发布数据中,能够保证数据的可用性,并且提高隐私保护的强度。
其中,虚拟身份(Data identity):基于原始数据生成的替代数据,带有原始数据的特征信息,一定程度的隐藏了原始数据中的隐私信息。数据身份(Data identity):身份信息是描述一条数据区别于其他数据的信息,一条数据的所有属性,都属于数据身份的一部分。数据特征(Data characteristic):特征信息用于描述数据的特征,不同于数据身份,数据的特征是一个更加宽泛的概念,一条数据的身份只有一个,但是该条数据的特征并不唯一。数据分析的过程大部分都要先进行分类处理,对数据进行分类依赖的是数据的特征而不是数据身份。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图4所示,本发明基于身份替代的隐私保护方法包括:
步骤100:对收集的原始数据,进行预处理,生成高敏感数据;步骤200:根据数据范化参数对高敏感数据的身份属性集进行范化处理,生成虚拟身份集;步骤300:根据所述身份属性集和虚拟身份集,确定处理后的身份偏移量和处理后的特征偏移量;步骤400:分别判断所述处理后的身份偏移量是否满足身份偏移量阈值的要求以及处理后的特征偏移量是否满足特征偏移量阈值的要求,如果满足,则执行步骤500,否则,根据判断结果调整所述数据范化参数,重复步骤200;步骤500:将处理后的虚拟身份集替换发布数据集中对应的高敏感数据,以进行发布。
其中,在步骤100中,预处理的方法包括:去除原始数据中的错误信息和缺失信息。
在步骤300中,所述确定处理后的身份偏移量和处理后的特征偏移量的方法包括:
步骤311:根据所述身份属性集V和虚拟身份集Vid确定虚拟身份vidn对应的单属性偏移量δn:
其中,V=v1,v2,...,vN,Vid=vid1,vid2,...,vidN,其中,n表示身份属性vn和虚拟身份vidn的序号,n=1,2,...,N。
步骤312:根据所述单属性偏移量δn确定单属性相似度λn:
λn=1-δn------------公式(2)。
步骤313:根据各所述单属性相似度确定身份相似度α:
其中ξn为身份属性vn的影响因子。实际生活中每个属性的变化对记录身份和特征的影响是不同的,有的对记录的影响比较大,有的影响比较小。为了简化,假设所有身份属性的影响因子ξ1=ξ2=...=ξNN=1。
步骤314:根据所述身份相似度α计算处理后的身份偏移量Δid:
Δid=1-α------------公式(4)。
步骤321:根据所述身份属性集V确定身份属性特征向量根据所述虚拟身份集Vid确定虚拟身份
步骤322:根据所述身份属性特征向量和虚拟身份确定特征相似度β:
步骤323:根据所述特征相似度β确定处理后的特征偏移量Δch:
Δch=1-β------------公式(6)。
在步骤400中,判断所述处理后的身份偏移量是否满足身份偏移量阈值的要求以及处理后的特征偏移量是否满足特征偏移量阈值的要求,进而根据判断结果进行处理,可根据需要灵活设置身份偏移量阈值及特征偏移量阈值,以控制隐私保护程度和数据可用性的高低程度,对于符合阈值范围的添加的发布数据中,不符合阈值范围的返回重新生成虚拟身份。
本发明基于身份替代的隐私保护方法相对于k-匿名处理方法以及差分隐私处理方法有以下优势:
(1)抵御背景知识攻击方面
相较于k-匿名,身份替代利用虚拟身份替代原始身份,当攻击者直接使用背景知识时,虚拟身份可以起到对攻击者进行误导的作用,这很大程度上降低了攻击者获取到目标敏感信息的概率,如果攻击者采用背景知识推理的方法,会增加分析的工作量,这间接降低了隐私泄露的风险。使得攻击者无法直接使用背景知识,能够抵御一定程度的背景知识攻击。
(2)数据可用性维持方面
差分隐私的隐私保护机制从数据的整体出发,添加噪音后的数据集与原始数据集的在分布相似,但是由于添加的噪音是由不同噪音机制产生的随机噪音,虽然能够保证整体分布几乎不变,却无法保证单条数据的特性不变这又可能造成单条数据严重失真。身份替代从单条数据出发,基于数据本身的特征生成虚拟身份,然后利用阈值控制生成的身份确保虚拟数据不会过度失真,假设单条数据的变化被控制在±a范围之内,那么数据集的整体分布S1就一定在原始分布S0的±a范围之内,这样不仅保证单条数据的特性得以保存,也能够保证了处理后的数据集在整体分布上与原始数据集的分布相似。
(3)算法复杂度
空间复杂度方面:身份替代算法在处理过程中需要的内存空间为常数(只需要几个临时变量用于记录各个参数).
时间复杂度方面:最坏情况下,所有生成的虚拟身份均无法通过阈值判断,但最坏情况只有当生成虚拟身份指定的范围和阈值判断条件设计不合适的时候才会发生,适当调整这两个参数即可防止最坏情况的发生,也可以通过设置最大循环次数m来防止发生死循环。对于一条有n个属性的数据,算法平均时间复杂度为O(n),最坏的情况下算法时间复杂度为O(mn),由于m是常数,所以算法的整体时间复杂度为O(n)。
此外,本发明还提供一种基于身份替代的隐私保护系统,可提高处理后处理的隐私性和可用性。如图5所示,本发明基于身份替代的隐私保护系统包括设置模块1、预处理模块2、范化模块3、计算模块4、判断模块5及替换模块6。
其中,所述设置模块1用于设置数据范化参数、身份偏移量阈值及特征偏移量阈值;所述预处理模块2用于对收集的原始数据,进行预处理,生成高敏感数据;所述范化模块3分别与所述预处理模块2和设置模块1连接,用于根据所述数据范化参数对高敏感数据的身份属性集进行范化处理,生成虚拟身份集;所述计算模块4分别与所述预处理模块2和范化模块3连接,用于根据所述身份属性集和虚拟身份集,确定处理后的身份偏移量和处理后的特征偏移量;所述判断模块5与所述计算模块4连接,用于分别判断所述处理后的身份偏移量是否满足身份偏移量阈值的要求以及处理后的特征偏移量是否满足特征偏移量阈值的要求;所述替换模块6分别与所述判断模块5和范化模块3连接,用于在所述判断模块5的判断结果为满足时,将处理后的虚拟身份集替换发布数据集中对应的高敏感数据,以进行发布;所述判断模块5还与所述设置模块1连接,所述设置模块用于在所述判断模块的判断结果为不满足时,根据所述判断结果调整所述数据范化参数。
其中,所述预处理模块2对收集的原始数据,进行预处理具包括:去除原始数据中的错误信息和缺失信息。
优选的,所述计算模块4包括属性偏移量计算单元、属性相似度计算单元、身份相似度计算单元、身份偏移量计算单元、特征向量确定单元、特征相似度计算单元及特征偏移量计算单元。
其中,所述属性偏移量计算单元,用于根据所述身份属性集V和虚拟身份集Vid确定虚拟身份vidn对应的单属性偏移量δn;所述属性相似度计算单元,用于根据所述单属性偏移量δn确定单属性相似度λn;所述身份相似度计算单元,用于根据各所述单属性相似度确定身份相似度α;所述身份偏移量计算单元,用于根据所述身份相似度α计算处理后的身份偏移量Δid;所述特征向量确定单元,用于分别根据所述身份属性集V确定身份属性特征向量根据所述虚拟身份集Vid确定虚拟身份所述特征相似度计算单元,用于根据所述身份属性特征向量和虚拟身份确定特征相似度β;所述特征偏移量计算单元,用于根据所述特征相似度β确定处理后的特征偏移量Δch。
相对于现有技术,本发明基于身份替代的隐私保护系统与上述基于身份替代的隐私保护方法的有益效果相同,在此不再赘述。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!