基于循环神经网络的大数据轮廓查询处理方法与流程
本发明涉及一种轮廓查询处理技术,尤其是涉及一种面向大数据的轮廓查询处理技术。
背景技术:
轮廓(skyline)查询处理技术是近年来计算机学科的一个研究热点和重点,这主要是因为轮廓查询结果的对象集在许多领域有着广泛的应用,如:智能交通、信息服务、数据可视化以及电子商务等。给定k维数据对象集合D={p1[d1,…,dk],p2[d1,…,dk],…,pn[d1,…,dk]},其中n为对象个数,d1,…,dk为对象的k个维度,每个维度di(1≤i≤k)描述D的一个特征,例如保质期、价格等,轮廓查询skyQ(D)就是获取D上满足如下条件的最大数据子集SD:SD中的每个对象不会在所有k个维度上的取值均差于D中的某一对象。我们把SD称为D的轮廓对象集。显然,对于数据对象集合D,用户只需通过轮廓查询skyQ(D),并考虑其轮廓对象集SD中的数据对象,而不必关心被过滤掉的非轮廓对象,这样用户就可以在小规模的轮廓对象集上对自己感兴趣的数据对象进行定位和选择。
由于在没有任何索引的情况下,对数据对象集合D进行轮廓查询处理是通过两两比较所有n个k维数据对象来实现的,即时间复杂度为O(kn2)。因此,当D的数据规模逐渐增大时,轮廓查询处理的时间代价将是巨大的,从而效率极其低下。因此,近年来学术界和工业界大都通过对D构建多维索引来提高轮廓查询的处理效率,这些多维索引主要包括B树索引、R树索引、Grid网格索引等。然而,我们发现在大数据环境下,通过构建多维索引的方式来处理轮廓查询至少存在三方面的缺陷,第一,在大数据环境下,多维索引需要占用巨大的额外存储空间,因此浪费大量的存储资源;其次,当数据有更新的时候,需要维护多维索引并做相应的动态更新,从而需要大量的额外时间开销;第三,当构建多维索引后,轮廓查询的时间复杂度通常会降低至O(knlogn),不难看出,该复杂度是非线性的,因此,在大数据环境下,这种处理方式也需要巨大的时间开销。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于循环神经网络高效且可扩展性强的大数据轮廓查询处理技术。本发明方法概括为:通过轮廓对象离线学习和轮廓对象在线识别两个步骤来获取大数据上的轮廓对象集。轮廓对象离线学习阶段,首先根据大数据所在领域的数据分布特征生成一定规模的离线学习样本,然后基于离线学习样本构造并优化循环神经网络学习模型。轮廓对象在线识别阶段,针对所要处理大数据的每个对象,使用循环神经网络学习模型,计算出每个对象的模型输出值,并基于模型输出值确定和输出大数据上的所有轮廓对象。本发明具有速度快、可扩展性高以及自适应能力强等优点,能够有效应用于互联网深度信息服务、智能交通、电子商务、和数据可视化等领域。
本发明给出的技术方案具体为:
一种基于循环神经网络的大数据轮廓查询确认方法,其特征在于,包括如下步骤:
步骤1,轮廓对象离线学习,通过两个阶段实现:
在第一阶段中,对于k维大数据对象集合D,首先根据D所在领域的数据分布特征生成规模较小的领域数据对象集合M={s1[d1,…,dk],s2[d1,…,dk],…,sm[d1,…,dk]},其中m为M中的对象个数,进而获取M上的轮廓对象集SM和非轮廓对象集NM,在此基础上,构造离线学习样本集合Ψ={<si[d1,…,dk],w>|1≤i≤m},w为轮廓对象标识符,取值为0或1,如果si[d1,…,dk]是M上的轮廓对象,那么w为1,否则为0。
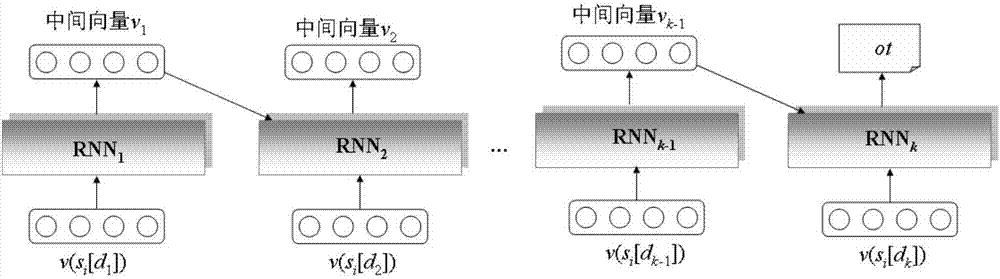
在第二阶段中,首先对于离线学习样本集合Ψ中的每个样本<si[d1,…,dk],w>,将si[d1,…,dk]中的第dj维(1≤j≤k)分量si[dj]转换成一个长度为t的向量v(si[dj]),从而,每个样本<si[d1,…,dk],w>对应k个t维向量v(si[d1]),v(si[d2]),…,v(si[dk]),即Ψ={<(v(si[d1]),v(si[d2]),…,v(si[dk])),w>|1≤i≤m}。然后,基于向量化之后的离线学习样本集合Ψ,构造k步循环神经网络学习模型k-RNN(Recurrent Neural Networks)。k-RNN学习模型顺序链接k个循环神经网络构件RNN1,RNN2,…,RNNk,并迭代处理Ψ中的每个向量化样本<(v(si[d1]),v(si[d2]),…,v(si[dk])),w>,处理过程为:循环神经网络构件RNN1接收t维向量v(si[d1]),并产生中间向量v1,循环神经网络构件RNN2,…,RNNk-1分别接收t维向量v(si[dk-1])和中间向量vk-2,并产生中间向量vk-1,而循环神经网络构件RNNk接收t维向量v(si[dk])和中间向量vk-1,并输出[0,1]区间中的一个数ot;当ot计算出来之后,将w与ot之间的差值w-ot当作本次迭代的误差依次在RNNk,…,RNN2,RNN1中传播来修改它们对应的权重参数。当模型收敛之后,迭代过程终止,并得到最终的k-RNN学习模型。
步骤2,轮廓对象在线识别:
针对待处理的k维大数据对象集合D={p1[d1,…,dk],p2[d1,…,dk],…,pn[d1,…,dk]},并接收用户给出的轮廓度阈值γ,并基于轮廓对象离线学习模块中构造的k-RNN学习模型,依次处理D中的每个数据对象pz[d1,…,dk](1≤z≤n),处理过程为:首先分别将该对象中的k个分量转换成k个t维向量v(pz[d1]),v(pz[d2]),…,v(pz[dk]),然后将这k个t维向量输入到k-RNN学习模型中,并获得[0,1]区间中的一个数otz,接着,判断otz是否大于轮廓度阈值γ,如果otz大于γ,那么识别pz[d1,…,dk]为轮廓对象,否则识别为非轮廓对象。最后将所有识别为轮廓对象的数据对象返回给用户。
本发明具有以下优点:
1、本发明能够在线性时间复杂度内获取所有轮廓对象,从而具有较高的轮廓查询处理效率和较短的用户响应时间。
2、本发明能够快速识别出多个不同数据对象集合上的轮廓对象,因此具有很强的自适应能力。
3、本发明处理的数据对象集合,不仅是数值类型,也可以是字符串、图像等其它数据类型,因此具有很强的扩展性。
附图说明
图1本发明的技术框架图
图2本发明构造的k步循环神经网络学习模型
图3循环神经网络构件RNN1的实施结构图
图4循环神经网络构件RNNi的实施结构图
图5循环神经网络构件RNNk的实施结构图
具体实施方式
对照于本发明技术方案,以下结合附图给予说明。
基于本发明方法技术方案,设计由轮廓对象离线学习和轮廓对象在线识别两个模块实现,技术框架如图1所示,即:
轮廓对象离线学习模块通过两个阶段来实现。在第一阶段中,对于k维大数据对象集合D,本发明首先根据D所在领域的数据分布特征生成规模较小的领域数据对象集合M={s1[d1,…,dk],s2[d1,…,dk],…,sm[d1,…,dk]},其中m为M中的对象个数,进而获取M上的轮廓对象集SM和非轮廓对象集NM,在此基础上,构造离线学习样本集合Ψ={<si[d1,…,dk],w>|1≤i≤m},w为轮廓对象标识符,取值为0或1,如果si[d1,…,dk]是M上的轮廓对象,那么w为1,否则为0。
在第二阶段中,本发明首先对于离线学习样本集合Ψ中的每个样本<si[d1,…,dk],w>,将si[d1,…,dk]中的第dj维(1≤j≤k)分量si[dj]转换成一个长度为t的向量v(si[dj]),从而,每个样本<si[d1,…,dk],w>对应k个t维向量v(si[d1]),v(si[d2]),…,v(si[dk]),即Ψ={<(v(si[d1]),v(si[d2]),…,v(si[dk])),w>|1≤i≤m}。然后,基于向量化之后的离线学习样本集合Ψ,构造如图2所示的k步循环神经网络学习模型k-RNN(Recurrent Neural Networks)。k-RNN学习模型顺序链接k个循环神经网络构件RNN1,RNN2,…,RNNk,并迭代处理Ψ中的每个向量化样本<(v(si[d1]),v(si[d2]),…,v(si[dk])),w>,处理过程为:循环神经网络构件RNN1接收t维向量v(si[d1]),并产生中间向量v1,循环神经网络构件RNN2,…,RNNk-1分别接收t维向量v(si[dk-1])和中间向量vk-2,并产生中间向量vk-1,而循环神经网络构件RNNk接收t维向量v(si[dk])和中间向量vk-1,并输出[0,1]区间中的一个数ot;当ot计算出来之后,将w与ot之间的差值w-ot当作本次迭代的误差依次在RNNk,…,RNN2,RNN1中传播来修改它们对应的权重参数。当模型收敛之后,迭代过程终止,并得到最终的k-RNN学习模型。
轮廓对象在线识别模块针对需要处理的k维大数据对象集合D={p1[d1,…,dk],p2[d1,…,dk],…,pn[d1,…,dk]},并接收用户给出的轮廓度阈值γ,并基于轮廓对象离线学习模块中构造的k-RNN学习模型,依次处理D中的每个数据对象pz[d1,…,dk](1≤z≤n),处理过程为:首先分别将该对象中的k个分量转换成k个t维向量v(pz[d1]),v(pz[d2]),…,v(pz[dk]),然后将这k个t维向量输入到k-RNN学习模型中,并获得[0,1]区间中的一个数otz,接着,判断otz是否大于轮廓度阈值γ,如果otz大于γ,那么识别pz[d1,…,dk]为轮廓对象,否则识别为非轮廓对象。最后将所有识别为轮廓对象的数据对象返回给用户。
本实施方式进一步给出实施例。
实施例1
在轮廓对象离线学习模块的第一阶段中,领域数据对象集合M的生成方式如下:首先利用k维大数据对象集合D所在领域的数据分布特征构建k维直方图,进而通过k维直方图模拟出具有k个随机变量的联合分布函数F(x1,x2,…,xk),然后基于F(x1,x2,…,xk)生成10000个满足该联合分布函数的领域数据对象s1[d1,…,dk],s2[d1,…,dk],…,s10000[d1,…,dk],并组成集合M={s1[d1,…,dk],s2[d1,…,dk],…,s10000[d1,…,dk]}。
M上轮廓对象集SM和非轮廓对象集NM的获取通过4个步骤来具体实施:1)对M中的每个对象si[d1,…,dk](1≤i≤10000),计算该对象的排序算子其中ln(·)为自然对数;2)对M中的对象依据排序算子的大小进行升序排序,并组成有序列表L=<s1’[d1,…,dk],s2’[d1,…,dk],…,s10000’[d1,…,dk]>;3)初始化轮廓对象集SM和非轮廓对象集NM为空;4)顺序访问L中的每个对象si’[d1,…,dk],并检查它是否被排在它前面的i-1个对象s1’[d1,…,dk],s2’[d1,…,dk],…,si-1’[d1,…,dk]中的某一对象所支配,如果被某一对象支配,那么将si’[d1,…,dk]放入NM中,否则将si’[d1,…,dk]放入SM中。
在此基础上,离线学习样本集合Ψ的构造方式如下:对于SM中的每个对象si’[d1,…,dk],将<si’[d1,…,dk],1>放入Ψ中,并对于NM中的每个对象sj’[d1,…,dk],将<sj’[d1,…,dk],0>放入Ψ中。
在轮廓对象离线学习模块的第二阶段中,获取向量化离线学习样本集合Ψ’的实施方式为:对于离线学习样本集合Ψ中的每个样本<si[d1,…,dk],0|1>,首先使用word2vec或GloVe词嵌套工具,将si[d1,…,dk]中的每维分量si[dj]转换成长度t为20的数值向量v(si[dj]),即v(si[dj])=(aij1,aij2,…,aij20),其中aij1,aij2,…,aij20均为实数,然后把<((ai11,ai12,…,ai120),(ai21,ai22,…,ai220),…,(aik1,aik2,…,aik20)),0|1>放入Ψ’中。
在k-RNN学习模型中,循环神经网络构件RNN1的实施结构图如图3所示:
RNN1的输入层包含20个神经元,分别接收所处理样本第一维分量对应的20维数值向量(a1,a2,…,a20)。隐含层包含10个神经元H1,H2,…,H10,每个神经元Hx(1≤x≤10)的输出值hx表示为:
其中e为自然对数的底数,分别为20个输入神经元的权重参数,从而隐含层具有200个权重参数,对应一个10×20的权重矩阵WH:
本发明初始化这200个权重参数均为0.3。输出层包含20个神经元O1,O2,…,O20,每个神经元Oy(1≤y≤20)的输出值by表示为:
其中分别为10个隐含层神经元的权重参数,从而输出层具有200个权重参数,对应一个20×10的权重矩阵WO:
本发明初始化这200个权重参数均为0.5。
在k-RNN学习模型中,RNN2~RNNk-1这k-2个循环神经网络构件的实施结构图相同,对于其中任意一个循环神经网络构件RNNi(2≤i≤k-1),其实施结构图如图4所示:
RNNi的输入层包含40个神经元,分别接收所处理样本第一维分量对应的20维数值向量(a1,a2,…,a20)以及前一个循环神经网络构件RNNi-1的20维输出向量(c1,c2,…,c20)。隐含层包含5个神经元H1,H2,…,H5,每个神经元Hx(1≤x≤5)的输出值hx表示为:
其中e为自然对数的底数,分别为40个输入神经元的权重参数,从而隐含层具有200个权重参数,对应一个5×40的权重矩阵WH:
本发明初始化这200个权重参数均为0.2。输出层包含20个神经元O1,O2,…,O20,每个神经元Oy(1≤y≤20)的输出值by表示为:
其中分别为5个隐含层神经元的权重参数,从而输出层具有100个权重参数,对应一个20×5的权重矩阵WO:
本发明初始化这100个权重参数均为0.8。
在k-RNN学习模型中,循环神经网络构件RNNk的实施结构图如图5所示:
RNNk的输入层包含40个神经元,分别接收所处理样本第一维分量对应的20维数值向量(a1,a2,…,a20)以及前一个循环神经网络构件RNNk-1的20维输出向量(c1,c2,…,c20)。第一隐含层包含10个神经元H1,H2,…,H10,每个神经元Hx(1≤x≤10)的输出值hx表示为:
其中e为自然对数的底数,分别为40个输入神经元的权重参数,从而第一隐含层具有400个权重参数,对应一个10×40的权重矩阵WH:
本发明初始化这400个权重参数均为0.4。第二隐含层包含5个神经元U1,U2,…,U5,每个神经元Uy(1≤x≤5)的输出值uy表示为:
其中分别为10个第一隐含层神经元的权重参数,从而第二隐含层具有50个权重参数,对应一个10×5的权重矩阵WU:
本发明初始化这100个权重参数均为0.5。输出层包含1个神经元O,其输出值ot表示为:
其中χ1,χ2,…,χ5分别为5个第二隐含层神经元的权重参数,即为输出层所具有的权重参数,本发明初始化这5个权重参数均为0.7。
在RNN1,RNN2,…,RNNk构造完毕之后,k-RNN学习模型顺序链接这k个循环神经网络构件,并基于向量化离线学习样本集合Ψ’,进行迭代优化k-RNN学习模型中的所有权重参数,迭代次数设定为10000。在每次迭代过程中,误差取值为当前样本的轮廓对象标识符w(0或1)与k-RNN学习模型的输出值ot之间的差值w-ot,并基于该误差值,利用Adam(Adaptive Moment Estimation:自适应矩估计)随机优化策略来调整并优化k-RNN学习模型中的所有权重参数。迭代过程终止之后,得到最终的k-RNN学习模型。
给定需要处理的k维大数据对象集合D={p1[d1,…,dk],p2[d1,…,dk],…,pn[d1,…,dk]}以及用户给出的轮廓度阈值γ,轮廓对象在线识别模块顺序取出D中的每个对象pz[d1,…,dk](1≤i≤n),并基于k-RNN学习模型判断pz[d1,…,dk]是否为轮廓对象,最终将所有识别为轮廓对象的数据对象返回给用户。判断过程的具体实施方式如下:
首先使用与轮廓对象离线学习模块中一致的word2vec或GloVe词嵌套工具,将pi[d1,…,dk]中的每维分量pi[dj]转换成20维数值向量v(pi[dj]),即其中均为实数,从而得到pi[d1,…,dk]的向量化形式((εi11,εi12,…,εi120),(εi21,εi22,…,εi220),…,(εik1,εik2,…,εik20))。在此基础上,将第一个向量(εi11,εi12,…,εi120)输入到循环神经网络构件RNN1中,利用公式(1)计算出10个隐含层神经元的输出值h1,h2,…,h10,并根据公式(2)计算出20个输出层神经元的输出值b1,b2,…,b20;接着,对于RNN2至RNNk-1之间的每一个循环神经网络构件RNNz,将第z个向量(εiz1,εiz2,…,εiz20)和前一个循环神经网络构件RNNz-1的20维输出向量(c1,c2,…,c20)输入到循环神经网络构件RNNz中,利用公式(3)计算出5个隐含层神经元的输出值h1,h2,…,h5,并根据公式(4)计算出20个输出层神经元的输出值b1,b2,…,b20;最后,将第k个向量(εik1,εik2,…,εik20)输入到循环神经网络构件RNNk中,利用公式(5)计算出第一隐含层10个神经元的输出值h1,h2,…,h10,使用公式(6)计算出第二隐含层5个神经元的输出值u1,u2,…,u5,并根据公式(7)计算出输出值otz。当获得输出值otz之后,对比otz与轮廓度阈值γ的大小,如果otz>γ,那么识别pz[d1,…,dk]为轮廓对象,否则识别为非轮廓对象。
- 还没有人留言评论。精彩留言会获得点赞!