一种基于递归神经网络的摘要生成方法与流程
本发明涉及神经网络领域,更具体地,涉及一种基于递归神经网络的摘要生成方法。
背景技术:
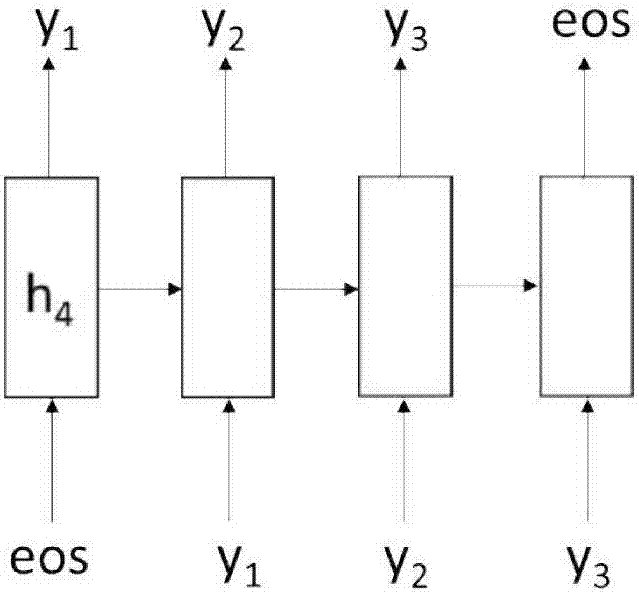
:摘要生成是自然语言处理领域的一个重要问题,它主要有两种不同的形式:一种是生成源文的主旨,另一种是生成源文的标题。前者一般比较长,可能包括数十个字或者词,而后者相对比较短,一般只有十个字左右。摘要是源文的高度性概括,它必须简单明了的表达源文的意思。传统的摘要生成方法可以分为三个步骤:一、根据某个标准(例如分词)将源文分割成很多个小片断;二、根据每个片断的权重(例如tf-idf),从中选择出权重比较大的那些片断;三、根据某种算法将那些权重较大的片断组合成新的句子,作为源文的摘要。现有技术提供了一种基于基于递归神经网络编码器与解码器的摘要生成方法,该方法实际上是一个序列到序列的机器学习过程,它的输入可以是一个句子,一个段落或者一篇文章,它的输出是相应输入的主旨或者标题,因此输入和输出都可以看作是由字或者词组成的时间序列。与传统的摘要生成方法相比,这是一种抽象的摘要生成过程。其根据给定的输入序列,方法通过在整个词表中递归地搜索关键词来从前向后组成一个新的句子作为输出序列,即摘要信息。其中递归神经网络编码器的作用是利用递归神经网络将给定的输入序列转换或者映射成为一个中间表达式,即将输入的段落或者文章转换成一个向量表达式h。假设输入序列为:x={x1,x2,…,xn},其中n表示输入序列的长度。如图1所示,编码器的作用可以用以下表达式来表示:ht=f(xt,ht-1)其中,xt表示输入序列中第t个元素的相应向量,ht表示t时刻编码器的状态向量,f和表示非线性映射函数。h表示输入序列的向量表达式,一般情况下取h=hn即可,即用递归神经网络编码器的最后时刻的状态向量作为输入序列的中间向量表达式。eos是一个特殊标记,表示着输入序列的终止,以及编码器工作的结束和解码器工作的开始。相应的,递归神经网络解码器的作用是利用编码器生成的中间向量表达式h来生成输出序列。假设输出序列为:y={y1,y2,…,ym},其中m表示输出序列的长度。需要注意的是,解码器并不是一次性生成整个输出序列,而是按照从前往后的顺序每个时刻生成输出顺序的一个字或者一个词,直到生成整个输出序列为止。如图2所示,解码器的作用可以用以下表达式来表示:p(yt|y1,...,yt-1,h)=g(st,h)st=f(yt-1,st-1)其中,p(y│x)表示根据输入x得到输入y的概率;yt表示输出序列中第t时刻的解码出的字或词,st表示t时刻解码器的状态向量。f和g表示非线性转换函数,这里g采用softmax函数。上述方案中,基于递归神经网络编码器与解码器的摘要生成方法有一个不足,即输出序列的生成只与编码器的最后时刻的状态向量有关,但与编码器中的其它状态向量无关。当递归神经网络的长度增加的时候,递归神经网络抽取的特征向量往往与输入序列后面的状态关联性增加,但与输入序列前面的状态关联性减少,这就可能会造成信息的衰减。因此只根据编码器的最后状态来解码会造成输出序列与输入序列之间的关联性变弱。技术实现要素:本发明为解决以上现有技术在解码的过程中会造成信息衰减的缺陷,提供了一种基于递归神经网络的摘要生成方法为实现以上发明目的,采用的技术方案是:一种基于递归神经网络的摘要生成方法,在当前时刻t,将递归神经网络解码器的状态向量st与递归神经网络编码器的每个时刻的状态向量进行对比,找出与状态向量st关联性最强的状态向量h,然后利用状态向量h及状态向量h左右两侧的d个状态向量计算得到状态向量ct,利用状态向量ct、状态向量st得到新的状态向量dt,然后根据状态向量dt解码得到输出序列的下一个字或者词,其中d为大于或等于1的整数。上述方案中,当要生成输出序列的下一个字或者词的时候,本发明提供的方法并不直接用解码器当前的状态向量来解码;而是解码器当前的状态向量st与编码器每个时刻的状态向量进行对比,找出和st最相似的编码器的状态向量h,然后由h和它两侧的若干个状态向量计算得到一个状态向量ct,并利用状态向量ct、状态向量st计算得到新的状态向量dt,它反应了当前要生成的字或者词应该与它呈正相关,即它是将要生成的下一个字或词的对齐信息。最后根据状态向量dt来解码得到输出序列的下一个字或者词。通过寻找h及利用h生成状态向量ct,并利用状态向量ct、状态向量st计算得到新的状态向量dt,最后利用状态向量dt解码得到输出序列的下一个字或者词,使得方法解决了输出序列和输入序列之间的对齐关系,提高了输出序列的质量和效率,并使输出序列与输入序列之间的关联性从而能够保持在较高的水平。优选地,所述找出与状态向量st关联性最强的状态向量h的具体过程如下:其中pt表示状态向量h在递归神经网络编码器状态向量序列中的位置,n表示输入序列的长度,wp表示需要学习的参数,sigmoid函数具体表示如下:sigmoid(x)=1/(1+e-x)tanh函数表示如下:优选地,所述计算得到状态向量ct的具体过程如下:其中,αti表示权重,hi表示递归神经网络编码器的状态向量。优选地,所述αti的求取过程如下:其中eti表示解码器中状态向量和编码器中状态向量的相关性权重:eti=si*hi。优选地,所述状态向量dt的计算过程如下:dt=sigmoid(ct*st)其中,sigmoid函数具体表示如下:sigmoid(x)=1/(1+e-x)。上述方案中,状态向量dt对于对齐关系的处理其实是一种局部最优的策略,输出序列和输入序列的对齐关系应该是整体相关而不是应该是局部相关的,这就意味着当前时刻的对齐信息不仅对当前时刻的解码有影响,而且应该对后续的解码也会有影响。因此,本发明提供的方法把当前时刻的对齐信息dt作为额外的信息输入到解码器的下一个状态中。优选地,若递归神经网络编码器与解码器为多层结构,则将状态向量ct和/或dt直接输入到解码器的第一层或最后一层,来应用到解码器下一时刻的解码中;若递归神经网络编码器与解码器为单层结构,则将状态向量ct和/或dt直接输入到解码器即可。与现有技术相比,本发明的有益效果是:本发明的方法在生成输出序列的下一个字或者词的时候,本发明提供的方法并不直接用解码器当前的状态向量来解码;而是解码器当前的状态向量st与编码器每个时刻的状态向量进行对比,找出和st最相似的编码器的状态向量h,然后由h和它两侧的若干个状态向量计算得到一个状态向量ct,并利用状态向量ct、状态向量st计算得到新的状态向量dt,它反应了当前要生成的字或者词应该与它呈正相关,即它是将要生成的下一个字或词的对齐信息。最后根据状态向量dt来解码得到输出序列的下一个字或者词。通过寻找h及利用h生成状态向量ct,并利用状态向量ct、状态向量st计算得到新的状态向量dt,最后利用状态向量dt解码得到输出序列的下一个字或者词,使得方法解决了输出序列和输入序列之间的对齐关系,提高了输出序列的质量和效率,并使输出序列与输入序列之间的关联性从而能够保持在较高的水平。附图说明图1为编码器的作用示意图。图2为解码器的作用示意图。图3为attention机制的作用示意图。图4的(a)、(b)、(c)、(d)分别为四种不同feed机制的作用示意图。具体实施方式附图仅用于示例性说明,不能理解为对本专利的限制;以下结合附图和实施例对本发明做进一步的阐述。实施例1本发明提供的方法的主要发明点在于增加了attention机制,如图3所示,其具体如下:在当前时刻t,将递归神经网络解码器的状态向量st与递归神经网络编码器的每个时刻的状态向量进行对比,找出与状态向量st关联性最强的状态向量h,然后利用状态向量h及状态向量h左右两侧的d个状态向量计算得到状态向量ct,利用状态向量ct、状态向量st得到新的状态向量dt,然后根据状态向量dt解码得到输出序列的下一个字或者词,其中d为大于或等于1的整数。上述方案中,当要生成输出序列的下一个字或者词的时候,本发明提供的方法并不直接用解码器当前的状态向量来解码;而是解码器当前的状态向量st与编码器每个时刻的状态向量进行对比,找出和st最相似的编码器的状态向量h,然后由h和它两侧的若干个状态向量计算得到一个状态向量ct,并利用状态向量ct、状态向量st计算得到新的状态向量dt,它反应了当前要生成的字或者词应该与它呈正相关,即它是将要生成的下一个字或词的对齐信息。最后根据状态向量dt来解码得到输出序列的下一个字或者词。通过寻找h及利用h生成状态向量ct,并利用状态向量ct、状态向量st计算得到新的状态向量dt,最后利用状态向量dt解码得到输出序列的下一个字或者词,使得方法解决了输出序列和输入序列之间的对齐关系,提高了输出序列的质量和效率,并使输出序列与输入序列之间的关联性从而能够保持在较高的水平。实施例2attention机制在一定程度上解决了输出序列和输入序列之间的对齐关系,从而提高了输出序列的质量和效率。但attention机制对于对齐关系的处理其实是一种局部最优的策略。为了进一步提高输出序列也就是源文摘要的质量,本实施例使用了一种新的全局最优的策略,即feed机制。在attention机制中其实存在两种对齐信息,一种是直接的对齐信息ct,另一种是间接的对齐信息dt,它们都反应了输出序列中下一字或词应该对齐的位置和内容。输出序列和输入序列的对齐关系应该是整体相关而不是应该是局部相关的,这就意味着当前时刻的对齐信息不仅对当前时刻的解码有影响,而且应该对后续的解码也会有影响。因此,可以把当前时刻的对齐信息作为额外的信息输入到解码器的下一个状态中。基于递归神经网络编码器与解码器可以是单层的,也可以是多层的,如图4所示。本实施例采用了两种分配机制:一是将哪种对齐信息输入到解码器的下一时刻,直接对齐信息还是间接对齐信息。二是将对齐信息输入对解码器的下一时刻的哪一层,最后一层还是最后一层。基于这两种机制,可以得到四种不同feed机制,如图4所示,它们分别是:间接对齐信息输入到最后一层,直接对齐信息输入到最后一层,间接对齐信息输入到第一层,直接对齐信息输入到第一层。实施例3摘要生成的序列到序列的学习方法,从本质上来说属于一种机器学习方法,因此可以采用机器学习通用的训练方法来训练。为了加快训练速度,本实施例采用最小批量梯度下降算法(mini-batchgradientdescent)来训练。由于中文的词表很大,解码过程所需要时间会很长,为了减少解码时间,本实施例采用字表,即只使用最常用的4000个汉字作为字表,对于其它的字,使用特殊的标记来替换。表1和表2为使用测试数据集对生成方法所作的测试与评估表1模型r-1r-2r-lbleu多层rnn30.416.027.39.5多层rnn+attention32.217.828.811.4多层rnn+attention+feed132.217.728.711.3多层rnn+attention+feed233.118.329.512.0多层rnn+attention+feed330.116.727.610.3多层rnn+attention+feed431.117.127.910.9表2模型信息性语法性简洁性多层rnn+attention2.873.953.28多层rnn+attention+feed12.854.012.93多层rnn+attention+feed23.024.233.30多层rnn+attention+feed33.003.933.10多层rnn+attention+feed42.884.033.03人工3.884.423.80表1采用了两种机器指标rouge和bleu来对生成方法进行评估。rouge是从召回率的角度来评估的,而bleu是从精确率的角度来评估的。从表1中可以看出,使用第二种feed策略,即将直接对齐信息输入到解码器的最后一层的时候,测试的结果表现最好,超过只使用attention机制的生成方法,这说明了生成方法的有效性。表2采用了三种人工指标来评估生成方法。其中信息性反映摘要所包涵的信息量,语法性反映摘要合乎语法的程度,简洁性反映摘要的简洁程度,人工模型表示人工生成的摘要信息。根据表2可以得出和表1相似的结论,即feed机制超过了attention机制。同样将直接对齐信息输入到解码器的最后一层这种策略表现得最为出色。通过两个表格的对比,可以得出摘要生成方法具有高效率、高准确性的结论,特别是采用第二种feed机制的时候。显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1