一种基于概率矩阵分解结合相似度的个性化推荐方法与流程
本发明属于数据处理系统和方法领域,具体涉及一种基于概率矩阵分解结合相似度的个性化推荐方法。
背景技术:
随着web2.0技术的飞速发展,信息的创建和分享变得越来越简单,以至于各类信息呈爆炸式增长,互联网的规模也不断扩大,导致了所谓的“信息过载”问题。然而用户在海量的信息中找到自己感兴趣的信息是非常困难的,如何帮助用户在最短的时间内准确获取到对自己有价值的信息,提高信息的使用率,是互联网技术人员所面临的一大挑战。
众所周知,在传统的互联网产品中,门户网站和搜索引擎是不同时期解决信息过载问题的代表性手段。但是它们都有各自的缺点,门户网站通过分类目录的方式整理网站资源,网站的覆盖率低,而且门户网站按照主题逐层点击下去的搜索方式非常耗时;而搜索引擎虽然解决了上述问题,但是也有一些缺陷。首先,用户必须有明确的需求并能够用关键词准确描述自己的意图,这一搜索过程才可以进行下去;其次,当用户难以用关键词描述自己的需求时,就很难通过搜索引擎找到对自己有价值的信息。
为了解决上述问题,个性化推荐系统应运而生。传统的协同过滤算法能够有效地解决上述问题,提高信息的使用率,但是随着用户和物品的大规模增长和加入互联网,而用户对物品的评分又很少,导致了冷启动和稀疏矩阵问题,致使协同过滤算法推荐效率很低;而概率矩阵分解算法有效地解决了冷启动和稀疏矩阵问题,但是其推荐精确度不高。
技术实现要素:
本发明针对基于概率矩阵分解的个性化推荐系统预测评分准确率不高的缺陷,提出了一种基于物品和用户之间的相似度进行调整用户和物品的潜在特征向量,从而很好地提高了预测评分的准确率。
为达到上述目的,本发明的技术方案为一种基于概率矩阵分解结合相似度的个性化推荐方法,具体包含以下步骤:
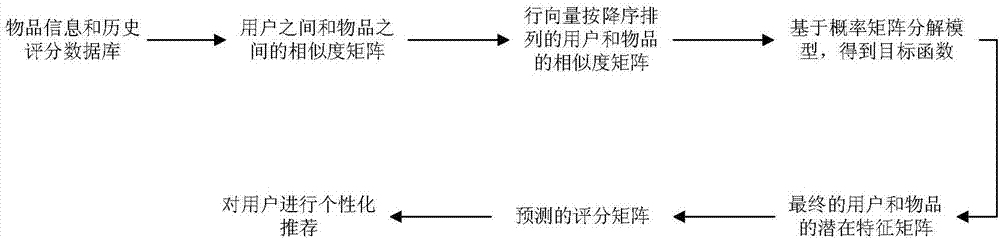
s1:建立物品信息和历史评分数据库;
s2:生成用户之间和物品之间的相似度矩阵;
s3:对上述矩阵的行向量按照降序进行排列;
s4:基于概率矩阵分解模型生成目标函数;
s5:生成最终的用户和物品的潜在特征矩阵;
s6:根据最终的用户和物品的潜在特征矩阵生成预测的评分矩阵;
s7:对用户进行个性化推荐。
进一步,上述物品之间的相似度矩阵的生成过程是首先根据物品信息矩阵,运用lda(lda,lineardiscriminantanalysis,线性判别式分析)算法求出物品的主题分布,然后运用余弦相似方法求出当前物品与其它物品之间的相似度,得到物品相似度矩阵。
上述用户之间的相似度矩阵的生成过程是根据物品的主题分布求出每个用户对每个物品的偏爱程度,进而求出当前用户与每个用户的相似度,得到用户相似度矩阵。
上述生成目标函数的具体步骤为:
s1:在降序排列基础上选取每个用户的k个相似度最高的用户,其潜在特征向量与这k个用户之间有很大的关系,用来约束当前用户的潜在特征向量,得到当前用户基于相似度的先验分布;
s2:选取每个物品的m个相似度最高的物品,其潜在特征向量同样与m个物品有关,用来作为约束当前物品的潜在特征向量,得到当前物品基于相似度的先验分布;
s3:由于用户潜在特征向量服从均值为0的正态分布,再将上述用户基于相似度的先验分布融合在一起,得到带有约束的用户潜在特征向量的先验分布,使正则项防止过拟合的程度更高;
s4:将上述物品基于相似度的先验分布融合在一起,得到带有约束的物品潜在特征向量的先验分布;
s5:根据概率矩阵分解模型,得到用户和物品的潜在特征矩阵的后验分布,经过变换得到最终的目标函数。
上述生成潜在特征矩阵的过程具体为:分别求出对用户和物品的潜在特征向量的梯度,运用梯度下降法训练模型,通过给定用户和物品初始的潜在特征矩阵,运用梯度下降法训练模型,不断更新物品和用户的潜在特征矩阵,得到最终满足条件的潜在特征矩阵。
与现有技术相比,本发明的有益效果:
1,本发明中,可以根据用户的潜在特征向量与相似度高的用户潜在特征向量有关,使得预测评分更加贴近用户的真实评分,从而提高当前推荐系统推荐准确率。
2,通过分别求出对用户和物品的潜在特征向量的梯度,运用梯度下降法训练模型,可以不断更新物品和用户的潜在特征矩阵,得到最终满足条件的潜在特征矩阵。
附图说明
图1为求用户和物品相似度的流程图。
图2为本发明的整体流程图。
具体实施方式
现结合附图对本发明做进一步详细的说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
为了提高推荐系统的精确度,本发明提出了结合用户和物品相似度的概率矩阵分解模型,根据历史评分矩阵,先求出用户与用户,物品和物品之间的相似度,进而选出相似度高的一些邻居用户和物品,来对用户和物品的潜在特征向量进行约束,得到目标函数后,再用梯度下降法进行迭代,求出最终的用户和物品的潜在特征矩阵,进而得到预测评分矩阵。
图2所示为本发明的整体流程图,包含以下步骤:
1.首先根据物品信息矩阵,运用lda算法求出物品的主题分布,根据物品的主题分布运用余弦相似方法求出当前物品与其它物品之间的相似度。
2.同样根据物品的主题分布求出每个用户对每个物品的偏爱程度,进而求出当前用户与每个用户的相似度。
3.将当前用户与每个用户的相似度按降序排序,得到了每个用户的与其他用户之间的降序排序序列,同理也得到了每个物品与其它物品之间的降序序列。
4.进一步选取每个用户的k个相似度最高的用户,而它的潜在特征向量这k个用户之间有很大的关系,用来约束当前用户的潜在特征向量,得到当前用户基于相似度的先验分布。
5.同样地,选取每个物品的m个相似度最高的物品,它的潜在特征向量同样与m个物品有关,用来作为约束当前物品的潜在特征向量,得到当前物品基于相似度的先验分布。
6.由于用户潜在特征向量服从均值为0的正态分布,再将上述用户基于相似度的先验分布融合在一起,得到带有约束的用户潜在特征向量的先验分布,使正则项防止过拟合的程度更高。
7.同理将上述物品基于相似度的先验分布融合在一起,得到带有约束的物品潜在特征向量的先验分布。
8.进一步根据概率矩阵分解模型,得到用户和物品的潜在特征矩阵的后验分布,然后经过变换得到最终的目标函数。
9.分别求出对用户和物品的潜在特征向量的梯度,运用梯度下降法训练模型,通过给定用户和物品初始的潜在特征矩阵,运用梯度下降法训练模型,不断更新物品和用户的潜在特征矩阵,就会得到最终满足条件的潜在矩阵。
10.根据最终的用户和物品的潜在特征矩阵,进而得到预测的评分矩阵,从而能为每个用户进行物品个性化推荐。
其中,求用户和物品相似度的流程图如图1所示,包含以下步骤:
1.根据物品信息矩阵,运用lda算法求出每个物品i的主题分布ti
2运用余弦相似度求出物品i与物品j的相似度ci,j如公式(1),得到物品相似度矩阵c
ci,j=sim(ti,tj)(1)
3.求出用户u对物品i的偏爱程度pu(i)如公式(2),求出偏爱程度矩阵p
a(u,i)表示用户u评分过的物品集合,但是不包括物品i,ti表示物品i的主题分布
4.根据公式(3)求出用户u与用户v的相似度wu,v,得到用户相似度矩阵w
a(u)表示用户u评分过的物品集合,a(v)表示用户v评分过的集合。
算法的整体流程图如图2
5.由于用户u的潜在特征向量与相似度高的用户v潜在特征向量有关,选取k个与用户u的相似度最高的用户集合的潜在特征向量来约束用户u的潜在特征向量,其服从高斯先验分布如公式(4)
n(x|μ,σ2)表示均值为μ,方差为σ2的正态分布,fku表示与用户μ相似度最高的k个用户集合。
6.同样,物品i的潜在特征矩阵向量与相似高的物品j的潜在特征向量有关,选取m个与物品i的相似度最高的物品集合的潜在特征向量来约束物品i的潜在特征向量,其服从高斯先验分布,
tmi表示与物品i相似度最高的m个物品集合。
7.同时用户与物品的潜在特征向量服从零均值的高斯分布,如公式(7)、(8)
8.历史评分矩阵的条件概率服从高斯先验分布,如公式(9)
9.由上述可得出用户和物品的潜在特征后验概率如公式(10)
10.对其取对数可的公式(11)
c是一个常数。
11.对上述最大化目标函数相当于最小化下面的目标函数如公式(12)
其中
12.对上述目标函数分别对变量uu,vi求梯度,得到公式(13)和(14)
13.给定用户和物品的初始特征向量为均值为0的正态分布进行采样,利用梯度下降法不断更新用户和物品的特征向量,直到最优。
其算法的逻辑框架如下:
初始值:评分矩阵r,以及k,m的值,ψ(0)=ψ(u(0),v(0))
require:0<步长a<1,t=0
while(t<1000)
找到最优的步长a
由此得到用户和物品的特征矩阵u和v,可以得到预测的评分矩阵
以上所述仅为本发明的优选实施案例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行改进,或者对其中部分技术进行同等替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!