酒店备选池的推荐方法和系统与流程
本发明涉及ota(onlinetravelagent,在线旅游社)技术领域,特别涉及一种酒店备选池的推荐方法和系统。
背景技术:
随着互联网和大数据的技术的快速发展,推荐系统已经被越来越多的应用到各行各业,对于ota行业来说,离线的周边酒店备选池对于整个酒店推荐系统起着至关重要的作用,备选池的准确度直接决定了整个推荐系统模型的性能和效率。
目前酒店推荐系统的备选池推荐算法大多采用协同过滤算法,包括基于用户的方法和基于物品的方法,两种方法采用用户对物品或者信息的偏好,发现用户和用户之间以及物品和物品之间的相似度。由于酒店是一种低频消费的商品,所以构造的用户对物品的评分矩阵就会异常稀疏,很难达到理想的推荐效果。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中ota行业的离线的周边酒店备选池的推荐效果不理想的缺陷,提供一种能够有效地提高酒店备选池的推荐的准确度的酒店备选池的推荐方法和系统。
本发明是通过下述技术方案来解决上述技术问题:
一种酒店备选池的推荐方法,其特点在于,包括以下步骤:s1、根据所有酒店的历史订单采用bow(bagofwords,词袋)模型构建订单字典,所述订单字典包括n个订单字,每个所述订单字包括性别、年龄区间、酒店星级区间和/或酒店价格区间;s2、分别对每家酒店初始化总维数为n、值均为0的直方图,一个维数对应一个所述订单字,分别计算每家酒店中每个历史订单与每个所述订单字的距离,距离所述历史订单最近的所述订单字对应的所述直方图的计数加一;s3、使用酒店的所述直方图分别计算两两酒店之间的相似度;s4、分别为每家酒店选取相似度最高的若干家酒店作为该酒店的酒店备选池。
本方案中,通过所有酒店的历史订单全面综合酒店产品的各种特征及其表达方式,不仅考虑了酒店的星级、价格等因素,还充分利用了订购过酒店的每个用户的信息如性别、年龄等,运用bow模型的方法把它们构建成订单字典,其中处理后的订单相当于bow模型中的words(字),每家酒店可以作为装这些words的bag(袋子)。然后,再对每家酒店使用订单字典中的订单字进行直方图表示,最后对两两酒店的直方图进行相似度的计算,根据相似度的高低来选择酒店的备选池,在此基础上能够向用户推荐符合用户偏好的酒店。与现有的备选池推荐方法相比,本推荐方法对酒店这种低频消费的商品表现出很好的效果,构建的订单字典的准确性和充分性大大优于协同过滤算法的评分矩阵,达到理想的推荐效果,最终有效地提高了酒店备选池选择的准确度。
较佳地,步骤s1包括以下子步骤:s11、设置所述订单字典的大小为n个;s12、采用k-means(一种硬聚类算法)算法对所有酒店的所述历史订单进行聚类,以获取n个聚类中心,所述聚类中心为所述订单字。
本方案中,根据所有历史订单的情况设置适当的订单字典的大小,采用k-means算法对所有的历史订单进行聚类,等k均值收敛时,即得到每一个聚类的聚类中心,也就是订单字,从而完成订单字典的构建。
较佳地,步骤s11中采用直线搜索的方法设置所述订单字典的大小。
本方案中,订单字典的大小n的设置涉及到计算相似度的准确性,如果n设置的太大,每个订单就一个word,又会遇到数据异常稀疏的问题;如果n设置的比较小,又无法区分订单之间的区别(如n设置为2,那么所有的订单都用两个words来表示),因此n的设置对整个推荐方法的有效性影响非常大。本方案中,采用直线搜索的迭代方法,n从1开始,随着n的增大,推荐的准确性越来越高,直到达到一个最高值。
较佳地,步骤s3中采用余弦距离计算两两酒店之间的相似度,计算公式如下:
其中hi=[wi1,wi2,……,win,hif1,hif2,hif3,……],hi(i=1,2,……,n)用于表示第i个酒店的直方图的值和酒店的属性,wik(k=1,2,……,n)代表每第i个酒店中对应的第k个订单字的计数个数,hifm(m=1,2,……)代表第i个酒店的第m个属性;hj=[wj1,wj2,……,wjn,hjf1,hjf2,hjf3,……],hj(j=1,2,……,n)用于表示第j个酒店的直方图的值和酒店的属性,wjl(k=1,2,……,n)代表每第j个酒店中对应的第l个订单字的计数个数,hjfn(n=1,2,……)代表第j个酒店的第n个属性;similary(hi,hj)表示第i个酒店和第j个酒店的相似度,所述酒店的属性包括星级、订单量和/或评分。
本方案采用余弦距离计算两两酒店的相似度,计算时结合了酒店的直方图的值和酒店的属性两个维度,计算出的相似度更合理,进而能够有效地提高酒店备选池选择的准确度。
较佳地,步骤s1之前还包括以下步骤:获取酒店的历史订单,每张所述历史订单包括用户信息和酒店信息。
本方案中,采用酒店的历史订单中的用户信息和酒店信息,全面综合了酒店产品的各种特征及其表达方式,形成基于bow的酒店产品表征,在此基础上能够向用户推荐符合用户偏好的酒店。
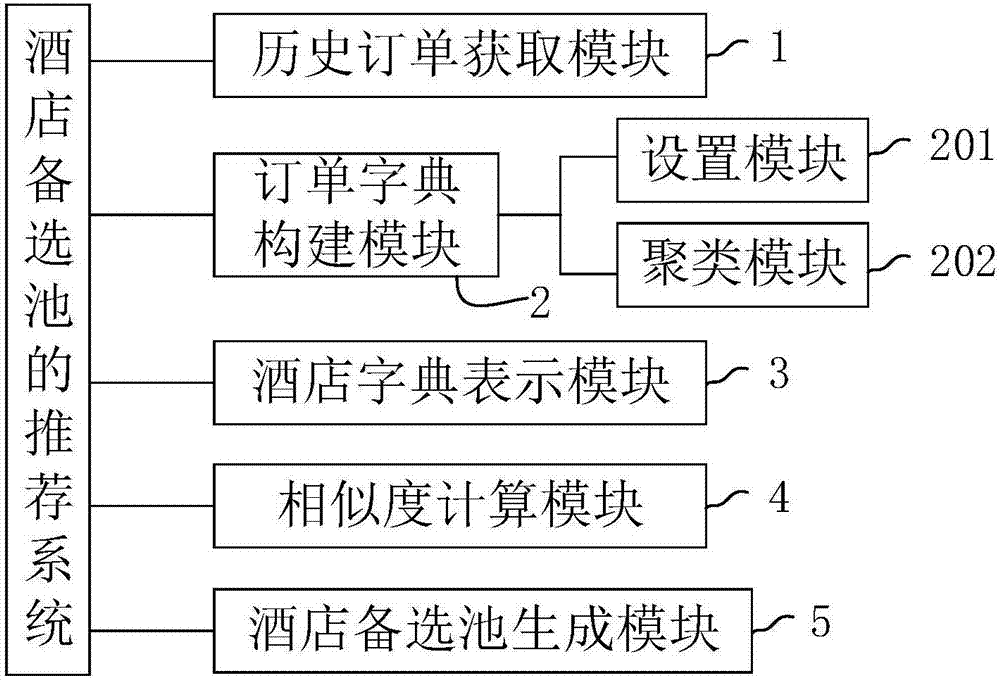
本发明还提供一种酒店备选池的推荐系统,其特点在于,包括:订单字典构建模块,用于根据所有酒店的历史订单采用bow模型构建订单字典,所述订单字典包括n个订单字,每个所述订单字包括性别、年龄区间、酒店星级区间和/或酒店价格区间;酒店字典表示模块,用于分别对每家酒店初始化总维数为n、值均为0的直方图,一个维数对应一个所述订单字,分别计算每家酒店中每个历史订单与每个所述订单字的距离,距离所述历史订单最近的所述订单字对应的所述直方图的计数加一;相似度计算模块,用于使用酒店的所述直方图分别计算两两酒店之间的相似度;酒店备选池生成模块,用于分别为每家酒店选取相似度最高的若干家酒店作为该酒店的酒店备选池。
较佳地,所述订单字典构建模块包括:设置模块,用于设置所述订单字典的大小为n个;聚类模块,用于采用k-means算法对所有酒店的所述历史订单进行聚类,以获取n个聚类中心,所述聚类中心为所述订单字。
较佳地,所述设置模块采用直线搜索的方法设置所述订单字典的大小。
较佳地,所述相似度计算模块中采用余弦距离计算两两酒店之间的相似度,计算公式如下:
其中hi=[wi1,wi2,……,win,hif1,hif2,hif3,……],hi(i=1,2,……,n)用于表示第i个酒店的直方图的值和酒店的属性,wik(k=1,2,……,n)代表每第i个酒店中对应的第k个订单字的计数个数,hifm(m=1,2,……)代表第i个酒店的第m个属性;hj=[wj1,wj2,……,wjn,hjf1,hjf2,hjf3,……],hj(j=1,2,……,n)用于表示第j个酒店的直方图的值和酒店的属性,wjl(k=1,2,……,n)代表每第j个酒店中对应的第l个订单字的计数个数,hjfn(n=1,2,……)代表第j个酒店的第n个属性;similary(hi,hj)表示第i个酒店和第j个酒店的相似度,所述酒店的属性包括星级、订单量和/或评分。
较佳地,所述推荐系统还包括历史订单获取模块,所述历史订单获取模块用于获取酒店的历史订单,每张所述历史订单包括用户信息和酒店信息。
本发明的积极进步效果在于:本发明提供的酒店备选池的推荐方法和系统通过所有酒店的历史订单全面综合酒店产品的各种特征及其表达方式,不仅考虑了酒店的星级、价格等因素,还充分利用了订购过酒店的每个用户的信息如性别、年龄等,运用bow模型的方法把它们构建成订单字典,对每家酒店使用订单字典中的订单字进行直方图表示,最后对两两酒店的直方图进行相似度的计算,根据相似度的高低来选择酒店的备选池,在此基础上能够向用户推荐符合用户偏好的酒店。与现有的备选池推荐方法相比,本推荐方法对酒店这种低频消费的商品表现出很好的效果,构建的订单字典的准确性和充分性大大优于协同过滤算法的评分矩阵,达到理想的推荐效果,最终有效地提高了酒店备选池选择的准确度。
附图说明
图1为本发明实施例1的酒店备选池的推荐方法的流程图。
图2为本发明实施例2的酒店备选池的推荐系统的示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1
如图1所示,一种酒店备选池的推荐方法,包括以下步骤:
步骤101、获取酒店的历史订单,每张历史订单包括用户信息和酒店信息。
步骤102、根据所有酒店的历史订单采用bow模型构建订单字典,具体步骤为采用直线搜索的方法设置订单字典的大小为n个;采用k-means算法对所有酒店的历史订单进行聚类,以获取n个聚类中心,其中聚类中心为订单字典中的订单字,每个订单字包括性别、年龄区间、酒店星级区间和酒店价格区间。
步骤103、分别对每家酒店初始化总维数为n、值均为0的直方图,一个维数对应一个订单字,分别计算每家酒店中每个历史订单与每个订单字的距离,距离该历史订单最近的订单字对应的直方图的计数加一。
步骤104、使用酒店的直方图分别采用余弦距离计算两两酒店之间的相似度,计算公式如下:
其中hi=[wi1,wi2,……,win,hif1,hif2,hif3,……],hi(i=1,2,……,n)用于表示第i个酒店的直方图的值和酒店的属性,wik(k=1,2,……,n)代表每第i个酒店中对应的第k个订单字的计数个数,hifm(m=1,2,……)代表第i个酒店的第m个属性;hj=[wj1,wj2,……,wjn,hjf1,hjf2,hjf3,……],hj(j=1,2,……,n)用于表示第j个酒店的直方图的值和酒店的属性,wjl(k=1,2,……,n)代表每第j个酒店中对应的第l个订单字的计数个数,hjfn(n=1,2,……)代表第j个酒店的第n个属性;similary(hi,hj)表示第i个酒店和第j个酒店的相似度,所述酒店的属性包括酒店标识、星级、订单量、评分和销量等。
步骤105、分别为每家酒店选取相似度最高的若干家酒店作为该酒店的酒店备选池。
本实施例中,基于bow模型进行酒店备选池推荐,将每个酒店看成一个bag,将历史订单进行聚类后生成字典中的字,也就是words,再对每家酒店的历史订单进行字典表示,生成该酒店的直方图表示,采用直方图结合酒店信息进行两两酒店的相似度计算,根据计算出的相似度的值选出若干家酒店作为酒店备选池,推荐给用户。
本实施例提供的酒店备选池的推荐方法采用所有酒店的历史订单全面综合酒店产品的各种特征及其表达方式,不仅考虑了酒店的星级、价格等因素,还充分利用了订购过酒店的每个用户的信息如性别、年龄等,运用bow模型的方法把它们构建成订单字典,对每家酒店使用订单字典中的订单字进行直方图表示,最后对两两酒店的直方图进行相似度的计算,根据相似度的高低来选择酒店的备选池,在此基础上能够向用户推荐符合用户偏好的酒店。与现有的备选池推荐方法相比,本推荐方法对酒店这种低频消费的商品表现出很好的效果,构建的订单字典的准确性和充分性大大优于协同过滤算法的评分矩阵,达到理想的推荐效果,最终有效地提高了酒店备选池选择的准确度。
实施例2
如图2所示,一种酒店备选池的推荐系统,该系统包括历史订单获取模块1、订单字典构建模块2、酒店字典表示模块3、相似度计算模块4和酒店备选池生成模块5。
其中,历史订单获取模块1用于获取酒店的历史订单,每张历史订单包括用户信息和酒店信息。
订单字典构建模块2用于根据所有酒店的历史订单采用bow模型构建订单字典,订单字典包括n个订单字,每个订单字包括性别、年龄区间、酒店星级区间和酒店价格区间;订单字典构建模块2包括设置模块201和聚类模块202,设置模块201用于采用直线搜索的方法设置订单字典的大小为n个;聚类模块202用于采用k-means算法对所有酒店的所述历史订单进行聚类,以获取n个聚类中心,聚类中心为所述订单字。
酒店字典表示模块3用于分别对每家酒店初始化总维数为n、值均为0的直方图,一个维数对应一个所述订单字,分别计算每家酒店中每个历史订单与每个订单字的距离,距离该历史订单最近的订单字对应的直方图的计数加一。
相似度计算模块4用于使用酒店的直方图采用余弦距离分别计算两两酒店之间的相似度,计算公式如下:
其中hi=[wi1,wi2,……,win,hif1,hif2,hif3,……],hi(i=1,2,……,n)用于表示第i个酒店的直方图的值和酒店的属性,wik(k=1,2,……,n)代表每第i个酒店中对应的第k个订单字的计数个数,hifm(m=1,2,……)代表第i个酒店的第m个属性;hj=[wj1,wj2,……,wjn,hjf1,hjf2,hjf3,……],hj(j=1,2,……,n)用于表示第j个酒店的直方图的值和酒店的属性,wjl(k=1,2,……,n)代表每第j个酒店中对应的第l个订单字的计数个数,hjfn(n=1,2,……)代表第j个酒店的第n个属性;similary(hi,hj)表示第i个酒店和第j个酒店的相似度,酒店的属性包括星级、订单量和/或评分。
酒店备选池生成模块5用于分别为每家酒店选取相似度最高的若干家酒店作为该酒店的酒店备选池。
下面继续通过具体的例子,进一步说明本发明的技术方案和技术效果。
当用户打开ota客户端后,首先会进入主页菜单,此时系统会根据用户相应信息从数据库中获取该用户的信息。用户点击进入酒店模块,在对应的搜索页面中进行相应搜索。酒店推荐系统的周边酒店备选池是一个用于存放着与每家酒店相似度最高的k家酒店的备选集,当一家酒店被推荐为用户的最佳选择时,ota客户端会从本推荐系统离线生成的酒店备选池中提取该酒店相似度最高的k家酒店,作为这家酒店的备选推荐进行展示。本推荐系统对酒店这种低频消费的商品表现出很好的效果,构建的订单字典的准确性和充分性大大优于协同过滤算法的评分矩阵,达到理想的推荐效果,最终有效地提高了酒店备选池选择的准确度。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!