一种基于关键词匹配的正文抽取方法与流程
本发明涉及文本挖掘技术领域,具体是一种基于关键词匹配的正文抽取方法。
背景技术:
web技术的快速发展,使得网页已经成为信息发布和信息消费的主要载体。因此,在对互联网的舆情监控中,加强对网页的信息过滤至关重要;而在对网页的信息过滤中,网页的信息抽取或正文抽取成为关键。然而,现有网页种类繁多,不同网页结构各异,且网站还会不定期进行改版,同时网页中还掺插了大量广告等噪声,这些问题使得对网页的正文抽取变得困难重重。现有的正文抽取方法主要包括:(1)通过分析dom树节点的文字叶子比率(wlr)和节点层级关系,实现正文抽取,该类方法时间复杂度高,效率低;(2)设计标签路径特征系从不同的角度实现正文和噪音的区分,在特征相似性分析的基础上,基于组合特征选择的特征融合策略,快速高效地实现正文的抽取,但这类方法对网站的结构依赖性强;(3)自动化信息抽取,仅依据网页自身的相关特征对网页进行抽取,这类方法在短正文网页的文本抽取中出错率比较高。
技术实现要素:
在目前的网页制作中,为提高被搜索引擎搜索的成功率,网页被设置了反映其主题信息的关键词,并列入到网页的keywords标签中,网页的各个段落的主题内容也大都围绕关键词展开。针对现有技术的不足,基于该特征,面向新闻和博客类网页,本发明提出一种基于关键词匹配的正文抽取方法,该方法依据网页自带的关键词,从本质上识别正文和噪声,其不需要训练数据,也不需要设置网站模板,脱离了网站结构的限制,从而真正实现对不同来源、不同风格的web新闻类网页的抽取。
本发明一种基于关键词匹配的正文抽取的方法,包括如下步骤:
(1)网页预处理,统计网页源代码keywords标签中的关键词并以关键词建立标准库,对待处理的网页进行预处理,去除明显的噪音文本,获得粗糙网页;
(2)构建dom树,依据获得的粗糙网页建立对应的dom树,按照网页源代码中段落标签的层次,将粗糙网页中的文本段落分别对应到dom树的叶子节点;
(3)统计关键词的数量,层次遍历dom树,统计dom树中所有节点包含关键词的数量,对叶子节点直接统计其所含关键词数量,而非叶子节点的关键词数量为其所有子女节点关键词数量之和;
(4)构建关键词权重kw,其为除根节点外的各节点所含关键词数量与其父节点所含关键词数量的比值;
以cj表示j结点所含关键词的数量,pj表示j节点的父节点i所含关键词的数量,以kwj表示j结点的关键词权重,其计算公式如下:
对每个非叶子节点,找出其所有子女节点中kw的最大值,将该节点及其子女节点的最大kw组成一个最大kw集合u;
(5)计算关键词权重阈值,从不同类型的网站随机选取一定数量的网页,采用基于关键词匹配方法进行正文抽取,计算所抽取正文的recall、precise、f值,具体公式如下:
设置的关键词权重阈值kw_t在区间[0,1]内分别取不同的值,如0.1,0.2,...,0.9,重复计算在不同阈值kw_t下正文抽取的recall、precise和f值,并在坐标系中绘制其变化曲线,横坐标对应阈值kw_t,纵坐标分别对应于recall、precise和f值;当所绘制的recall曲线和precise曲线相交时,f值最大,即达到最好的抽取效果,记录recall曲线和precise曲线相交时的kw_t值;统计针对不同网页进行上述处理时,所记录的在recall曲线和precise曲线相交时的kw_t值,将重复出现最多的kw_t值设置为关键词匹配时的阈值;
(6)关键词匹配,从集合u中查找小于指定的关键词权重阈值kw_t的kw值,确定对应的非叶子节点,并将该非叶子节点下的所有叶子节点当作正文节点输出,完成正文抽取;
(7)相似度匹配,若集合u中不存在小于阈值kw_t的kw值,采用相似度比较的方法进行正文匹配;遍历整个dom树,获取所有的叶子节点,将各叶子节点的数据采用simhash算法转换成对应的八位二进制数据,并分别与采用simhash算法转换的网页标题数据进行相似度比较,通过海明距离判断各叶子节点与网页标题的相似程度,若相似程度小于指定的阈值,则将该节点确定为正文节点,完成正文抽取;反之,则为噪音丢弃。
通常,噪音文本主要是一些高度格式化、短语、且通常与网页主题信息无关的简短文本。在对网页的预处理中,一方面去除一些明显与正文无关的冗余标签,包括样式块、注释块、脚本、超链接列表等;另一方面采用正则表达式,以标准库中的关键词作为“规则字符串”过滤目标网页中明显的噪音文本。通过预处理,有效缩减网页数据,获得粗糙网页,提高后续的页面转换的效率。
步骤(2)所述的构建dom树,具体步骤如下:
(2-1)使用jsoup工具解析粗糙网页html,获取粗糙网页的数据;
(2-2)构建dom树,dom用一组结构化的节点以及对象来表示文档的结构,即将文档中的每个组成部分都定义为一个节点,从而将网页、脚本语言以及编程语言连接起来。根据粗糙网页的结构,将网页的不同组成部分转换成dom树中的对应节点,而粗糙网页中的文本段落分别对应到dom树的叶子节点。
dom树的建立,能够有效简化对网页的遍历。
在新闻、博客等类型的主题网页结构中,正文内容块通常是由<p>标签构成的段落,关键词分布在由<p>标签构成的不同段落中;在网页不同标签的元素中,所含的关键词数越多,表示该元素是正文内容的可能性越大。通过将网页转换成对应的dom树后,网页中的各元素形成dom树中的各节点。为了有效甄别并定位包含正文文本的正文节点,本发明构建一个关键词权重(keywordweight,kw)概念,以节点与其父节点所含关键词数量的比率关系反映节点是否是正文节点的概率。关键词权重kw定义为除根节点外的各节点所含关键词数量与其父节点所含关键词数量的比值。
计算关键词权重阈值,计算所抽取正文的recall(召回率)、precise(准确率)、f值,这三个数据是信息检索和统计分类领域的度量指标。其中,recall是指算法所抽取出的正文在算法抽取出的总文本中所占的比值;precise是指算法抽取出的正文与标准文本的比值;f值表示的是测度值。
步骤(7)所述的相似度匹配,是对关键词匹配方法的补充,其主要用于解决短文本(在此将一个网页仅包含一个段落的情况也归为短文本)难抽取的问题。关键词匹配中若非叶子节点的子女节点的最大kw_t都大于设置的阈值,这种情况一般表现为非叶子节点的子女节点极少,如仅1个子女节点,此时其kw_t为1;或者非叶子节点的子女节点为短文本,且包含关键词较少。针对这些情况,提出相似度匹配方法,其直接将dom树中的叶子节点与网页标题进行相似度比较,判断节点是否为正文节点,完成正文抽取。
步骤(7)所述的相似度匹配,具体步骤如下:
(7-1)为了提高抽取效率,进行网页清洗并提取其特征词(特征词是文本中去除停用词外能够反映文本主题的词语),遍历整个dom树,抽取所有叶子节点对应的段落文本;去除段落文本中的停用词,通过分词处理,获得多个特征词(featureword,fw);
(7-2)为了让段落中特征词更好地代表段落文本,计算每个特征词的权重,以fwk表示第k个特征词,先统计某网页的文本段落总数,记为n;统计网页中含有fwk的段落数量,记为nk;最后统计fwk在网页中出现的次数,记为tfk;以weight(fwk)表示特征词fwk的权重,计算公式如下:
式(3)中,l是为了防止对数函数的计算值为0而设置的经验常数,取0.01;
(7-3)计算特征词fwk的hash值,采用simhash算法将特征词fwk分别转换成对应的位数为8位的hash值;
(7-4)以特征词权重和特征词的哈希值计算特征词fwk的加权向量,将特征词fwk的hash值与其权重值weight(fwk)按位相乘,如果hash值所在位是1,则hash值和权重值按位正相乘;如果是0,则hash值和权重值按位负相乘,生成一个8位的二进制数,即构造出特征词fwk的加权向量;
(7-5)按照(7-2)到(7-4)方法计算网页中所有特征词的加权向量;
(7-6)针对网页中的每一个段落,合并每一个段落中所有特征词的加权向量并降维;按照二进制加法运算合并每一个段落中所有特征值的加权向量,得到对应的合并后的向量,对合并后的向量降维是将向量数值的每一位转换为二进制数据,若向量的某一位数值大于0则为1,反之则为0,得到一个代表相应段落文本的八位simhash值,最终获得多个对应于不同段落的simhash值;
(7-7)采用(7-1)到(7-6)的方法计算网页标题的simhash值;
(7-8)计算网页中每一个文本段落simhash值与网页标题simhash值的海明距离(海明距离是两个合法代码对应位上编码不同的位数,即其对两个位串进行异或(xor)运算),判断相似度;如果两者的海明距离小于设置的海明距离阈值t,t∈[0,8],则对应的段落为正文短文本,完成正文抽取;反之,则为噪音丢弃。
所述海明距离阈值t的选取方法与关键词权重kw_t的选取方法相同,即针对短文本,计算网页标题和网页各段落文本的simhash值,以海明距离进行相似度比较,以t分别取0,1,...,8,计算正文抽取时在不同海明距离阈值t下的recall、precise和f值,记录在不同阈值下的recall曲线和precise曲线相交时的t值,将重复出现次数最多的t值设置为选取的阈值。
本发明针对新闻和博客类网页的信息获取,提出一种基于关键词匹配的正文抽取方法,该方法基于网页制作时所设置的关键词是网页各文本段落的概括和抽象,是各文本段落需要展现的主题这一现象,实现以关键词对网页文本段落的匹配和定位,能够准确地区分噪音和正文,具有较高的准确率;该方法以网页自设置的关键词进行匹配,不需要训练数据,也不需要进行样本学习,脱离了网站结构的限制,具有较好的通用性;关键词权重阈值选取方法以客观计算的结果作为依据,避免了主观因素的影响,这保证了正文抽取的客观性和合理性;而相似度匹配方法作为对关键词匹配正文抽取方法的补充,有效解决了现存短文本和网页单段落难抽取的问题。
附图说明
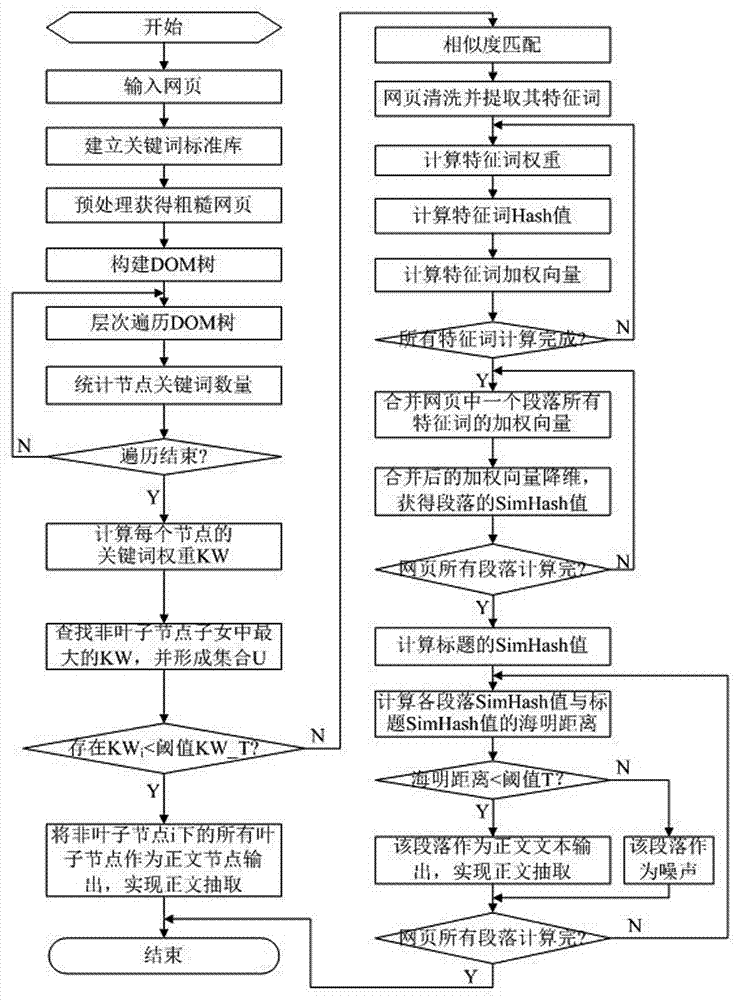
图1为本发明基于关键匹配正文抽取方法的流程图;
图2为dom树结构图;
图3为关键词权重阈值计算方法的流程图。
具体实施方式
以下结合附图对本发明内容做进一步阐述,但不是对本发明的限定。
如图1所示,本发明基于关键词匹配的正文抽取方法,具体包括如下步骤:
(1)网页预处理,统计并提取网页源代码keywords标签中的关键词,并以关键词建立标准库;采用正则表达式对待处理网页进行预处理,去除明显的噪音文本,获得粗糙网页;
(2)构建dom树,使用jsoup工具解析粗糙网页html,获取粗糙网页的数据;dom用一组结构化的节点以及对象来表示文档的结构,即将文档中的每个组成部分都定义为一个节点,从而将网页、脚本语言以及编程语言连接起来;根据粗糙网页的结构,将网页的不同组成部分转换成dom树中的对应节点,而粗糙网页中的文本段落分别对应于dom树的叶子节点,所构建dom树的具体结构如图2所示;
(3)统计关键词的数量,从下往上层次遍历dom树,统计dom树中所有节点包含关键词的数量,对叶子节点直接统计其所含关键词数量,而非叶子节点的关键词数量为其所有子女节点关键词数量之和;
(4)构建关键词权重kw为除根节点外的各节点所含关键词数量与其父节点所含关键词数量的比值;以cj表示j结点所含关键词的数量,pj表示j节点的父节点i所含关键词的数量,以kwj表示j结点的关键词权重,其计算公式如下:
对每个非叶子节点,找出其子女节点中kw的最大值,将该节点及其子女节点的最大kw组成一个最大kw集合u;
(5)计算关键词权重阈值,具体流程如图3所示,为了客观合理选取阈值,从不同类型的网站随机选取一定数量的网页,采用关键词匹配方法进行正文抽取;计算所抽取正文的recall(召回率)、precise(准确率)、f值,具体公式如下:
进行正文抽取时,所设置的关键词权重的阈值kw_t在区间[0,1]内分别取不同的值,如0.1,0.2,...,0.9,重复计算在不同阈值kw_t下正文抽取的recall、precise和f值,并在坐标系中绘制其变化曲线,横坐标对应阈值kw_t,纵坐标分别对应于recall、precise和f值;当所绘制的recall曲线和precise曲线相交时,f值最大,即达到最好的抽取效果,记录recall曲线和precise曲线相交时的kw_t值;统计针对不同网页进行上述处理时,所记录的在recall曲线和precise曲线相交时的kw_t值,将重复出现最多的kw_t值设置为关键词匹配时的阈值;
(6)关键词匹配,采用步骤(5)计算并确定的关键词权重阈值kw_t,从集合u中查找小于kw_t的kw值,确定对应的非叶子节点;针对选出的非叶子节点,定位其所有叶子节点,并将其所有叶子节点作为正文节点进行输出,实现正文抽取,基于关键词匹配的正文抽取方法结束;
(7)若关键词匹配时,集合u中不存在小于kw_t的kw值,则采用相似度匹配进行正文匹配;
(7-1)相似度匹配中,先进行网页清洗并提取特征词,遍历整个dom树,抽取所有叶子节点对应的段落文本;去除段落文本中的停用词,通过分词处理,获得多个特征词(featureword,fw);
(7-2)计算每个特征词的权重,以fwk表示第k个特征词,先统计该网页的文本段落总数,记为n;统计网页中含有fwk的总段数,记为nk;最后统计fwk在网页中出现的次数,记为tfk;以weight(fwk)表示特征词fwk的权重,计算公式如下:
式(3)中,l是为了防止对数函数的计算值为0而设置的经验常数,取0.01;
(7-3)计算特征词fwk的hash值,采用simhash算法将特征词fwk分别转换成对应的位数为8位的hash值;
(7-4)计算特征词fwk的加权向量,将特征词fwk的hash值与其权重值weight(fwk)按位相乘,如果hash值所在位是1,则hash值和权重值按位正相乘;如果是0,则hash值和权重值按位负相乘,生成一个8位的二进制数,即构造出特征词fwk的加权向量;
(7-5)按照(7-2)到(7-4)方法计算网页中所有特征词的加权向量;
(7-6)针对网页中的每一个段落,合并每一个段落中所有特征词的加权向量并降维;按照二进制加法运算合并每一个段落中所有特征值的加权向量,得到对应的合并后的向量,对合并后的向量降维是将向量数值的每一位转换为二进制数据,若向量的某一位数值大于0则为1,反之则为0,得到一个代表相应段落文本的八位simhash值,最终获得多个对应于不同段落的simhash值;
(7-7)采用(7-1)到(7-6)的方法计算网页标题的simhash值;
(7-8)计算网页中每一个文本段落simhash值与网页标题simhash值的海明距离,判断相似度;如果两者的海明距离小于设置的海明距离阈值t,t∈[0,8],则对应的段落为正文短文本,完成正文抽取;反之,则为噪音丢弃;所述海明距离阈值t的选取方法与关键词权重kw_t的选取方法相同。
本实施例方法以网页自设置的关键词进行匹配,不需要训练数据,也不需要进行样本学习,脱离了网站结构的限制,具有较好的通用性。
- 还没有人留言评论。精彩留言会获得点赞!