大图数据库中基于集合相似度的子图匹配方法与流程
本发明涉及计算机技术领域,尤其涉及一种大图数据库中基于集合相似度的子图匹配方法。
背景技术:
图作为一种数据结构能够简洁有力地刻画出普遍事物间的联系,因此基于图的数据挖掘与管理技术无论在学术研究还是工业应用上都享有重要的地位。在很多现实应用例如社会网络、语义网、生物网络等中,图数据库已经被广泛用作建模和查询复杂图数据的重要工具。很多学者广泛研究了关于图的各种查询,其中子图匹配是一种基本的图查询类型。子图匹配的数学基础是图论中的经典问题子图同构,一个著名的np问题。给出一个查询图q和一个大图g,一种典型的子图匹配查询将检索g中那些在图结构和顶点标签两方面都准确匹配q的子图。然而,在一些图的应用中,每个顶点往往包含了一系列代表该顶点不同特征属性的元素,而且顶点标签的准确匹配常常是难以实现的。
当下并没有研究工作对同构和运用动态元素权重的集合相似度的语义下的子图匹配文题进行研究。传统的加权集合相似度关注固定元素权重,这其实是动态权重的集合相似度的一种特殊情形。由于顶点的不同匹配语义,以前的精确或近似子图匹配技术并不能直接运用于sms2查询的解决中。运用动态加权集的相似度和结构约束来有效解决sms2查询是具有挑战性的问题。有两个直接的方法对现有的算法进行修改后解决了sms2查询问题。第一种方法是运用已有的子图同构算法进行子图同构,如文(l.p.cordella,p.foggia,c.sansone,andm.vento,“a(sub)graphisomorphismalgorithmformatchinglargegraphs,”ieeetrans.patternanal.mach.intell.,vol.26,no.10,pp.1367–1372,oct.2004.)中所进行的那样,然后通过考察每一对匹配顶点间的加权集合相似度对候选子图进行提炼。第二种方法将步骤顺序进行了颠倒,先通过计算加权集合相似度在数据图中找出与查询图中的顶点有相似集的候选顶点,这一步在计算复杂度上代价高昂,接下来再得到匹配的子图。然而这两种方法通常会造成高查询损耗,尤其是面对大图数据库。这是因为第一种方法忽略了加权集合相似度的限制条件,而第二种方法在过滤候选结果时忽略了结构信息。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种大图数据库中基于集合相似度的子图匹配方法。
本发明解决其技术问题所采用的技术方案是:一种大图数据库中基于集合相似度的子图匹配方法,包括以下步骤:
1)在查询图的多个支配集中选取一个经济的支配集,所述经济的支配集包含最少的支配顶点数,且每个支配顶点的候选点数是最少的;
2)集合相似度剪枝:运用集合相似度剪枝方法得到查询顶点的所有候选点;
3)基于结构的剪枝;根据查询图q同构的结构限制,对查询顶点的所有候选点基于结构剪枝,过滤查询顶点的候选点;
4)基于支配集的子图匹配:
4.1)将查询图q转化为支配查询图;
4.2)在数据图g中找出支配查询图的所有匹配,即qd和g的子图间的映射m(qd);
4.3)找出查询图q的所有子图匹配:将每个支配查询图qd的匹配扩展为查询图q的子图匹配;
如果当前状态m(s)覆盖了q的所有顶点,则按照当前状态m(s)输出映射m(q);
否则,对每个未覆盖的非支配顶点u′,考虑u′的1-hop和2-hop的邻近支配顶点,然后检查是否有候选对(u′,v′)满足集合相似度的子图匹配的条件,若是,则该候选对添加到当前状态中;遍历结束后,按照当前状态m(s)输出映射m(q)。
按上述方案,所述步骤1)中选取一个经济的支配集包括以下步骤:
1.1)运用branchandreduce从未被选择的查询顶点中迭代地选择一个拥有最少候选点数的查询顶点u;
1.2)利用hashsampling方法估算查询顶点u的候选点数;
1.3)根据步骤1.1)和1.2)的结果选出经济的支配集。
按上述方案,所述步骤2)中集合相似度剪枝包括以下步骤:
2.1)从经济的支配集包含的顶点集中挖掘密集频繁模式,基于所有的1-频繁模式和密集k-频繁模式构建格,其中k≥2;首先需要从数据图g的所有顶点元素集中挖掘频繁模式,然后将所有频繁模式组织为一个格。在格中,每个连接点p是一个频繁模式,它是其自身所有下位点的子集。
2.2)根据格中的频繁模式构建倒排模式格;遵循以下原则:倒排模式格中的同一层的频繁模式有相同的规模,且在k层的规模为k;
2.3)运用三种集合相似度剪枝方法得到查询顶点的所有候选点;对查询顶点u,首先运用垂直剪枝和横向剪枝来过滤出位置错误的模式并确定倒排模式格中应当被扫描的点,然后使用广度优先搜索对其进行遍历,对每个被扫描的点p,进行反单调剪枝,获得最终结果。
按上述方案,所述步骤2.1)中将所有密集k-频繁模式p按supp(p)的值倒序排列,并选择前
按上述方案,所述步骤3基于结构的剪枝包括以下步骤:
3.1)设计轻量签名:为所有查询顶点和数据顶点设计轻量签名标记用于过滤候选点。
3.2)设计基于签名的局部敏感散列哈希函数lsh:
使用一组局部敏感散列哈希函数来hash每个数据签名sig(v)进入签名桶,使每个签名桶中的数据签名的最大hamming距离最小化;
步骤3.3:结构化剪枝:
基于sms2查询定义,一个数据顶点v可以被剪掉,只要bv(u)和bv(v)的相似度小于阈值τ,或者不存在bv(vj),满足与bv(ui)的相似度限制,其中vj(j=1,…,n)和ui(i=1,…,m)是分别对应v和u的1-hop邻近;
位向量bv(u)和bv(v)间的相似度定义为:
其中∧表示位与运算,∨表示位或运算,a∈bv(u)∧bv(v)意味着对应a的位为1,w(a)则为a的权重。
对每个bv(ui),我们需要确定是否存在bv(vj)使得sim(bv(ui),bv(vj))≥τ。我们估测bv(ui)和bv∪(v)间的标准相似度上界通过以下方法:
位向量bv(ui)和bv∪(v)间的标准相似度上界表示为:
按上述方案,所述步骤3)中为所有查询顶点和数据顶点设计轻量签名标记分别称为查询签名sig(u)和数据签名sig(v),对应查询顶点u和数据顶点v;具体如下:
查询签名sig(u):
给出查询图q中的一个拥有可变邻近顶点ui(i=1,…,m)的顶点u,其查询签名sig(u)由一个位向量集给出,即sig(u)={bv(u),bv(u1),…,bv(um)},其中bv(u)和bv(ui)是分别为集合s(u)和s(ui)的元素编码表示的位向量;
数据签名sig(v):
给出查询图q中的一个拥有可变邻近顶点vi(i=1,…,m)的顶点v,数据签名sig(v)表示为:
按上述方案,步骤4.2)在数据图g中找出支配查询图的所有匹配,具体如下:初始化m(qd)当下状态s为空集,根据数据图g构建一个包含所有可能候选对(u,v)的候选对集合pa(s),并将其添加到当前状态s中,当候选对(u,v)被添加到当前映射m(s)中时,校验m(s)是否满足保持距离原则,若是,则继续这个过程直到找出一个qd的子图匹配,否则搜索停止,最终输出映射m(s)为m(qd)。
按上述方案,当候选对(u,v)被添加到当前映射m(s)中时,校验m(s)是否满足保持距离原则保持距离原则,所述保持距离原则如下:给出数据图g中支配查询图qd的一个匹配子图xd,qd和xd分别有n个顶点u1,…,un和v1,…,vn,其中,考虑qd中的边(ui,uj),有以下保持距离原则:
(1)如果边权重为1,则vi是vj的邻近;
(2)如果边权重为2,则有|n1(vi)∩n1(vj)|>0;
(3)如果边权重为3,则有|n1(vi)∩n2(vj)|>0或|n2(vi)∩n1(vj)|>0。
本发明产生的有益效果是:
(1)本发明设计了一种新颖的有效解决sms2查询的技术。一个倒排的基于格的索引和一种结构化的基于签名的局部灵敏散列(localitysensitivehashing,简称lsh)都在线下过程中首先被施行,在线上过程中,一系列剪枝技术将被应用和整合,从而更好地减小sms2查询的搜索空间。
(2)本发明提出了一种运用了创新的关于数据顶点的元素集的倒排模式格的集合相似度剪枝技术来度量动态加权的集合相似度。该方法引入一种动态加权的相似度的上界来运用反单调原则得到更好的剪枝效果。
(3)本发明提出了一种结构化的剪枝技术,探索出一种新颖的基于结构化标记的数据组织结构,其中标记被设计用于捕捉集合与相邻集的信息。一种聚集支配(aggregatedominance)原则被设计出来用于引导剪枝过程。
(4)不同于直接的查询和校验查询图中的所有候选顶点,我们设计了一种有效的算法来基于查询图的支配集展开子图匹配过程。当补充完剩余顶点后,距离保持原则被设计出来以裁剪掉那些不能与支配顶点保持距离的候选顶点。
(5)最后我们通过实验证实了本发明可以有效解决大图数据库中的sms2查询问题。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的从dblp中找到匹配查询引证图的引证论文的示例;其中,图1b是本发明实施例的dblp中的引文图g;图1a是本发明实施例的查询图q;
图2是本发明实施例的倒排模式格;
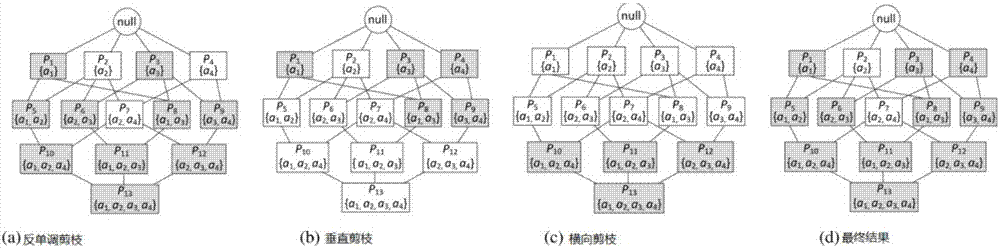
图3是本发明实施例的集合相似度剪枝示例;其中,图3a是本发明实施例的反单调剪枝;图3b是本发明实施例的垂直剪枝;图3c是本发明实施例的横向剪枝;
图4是本发明实施例的邻近支配顶点的可能拓扑结构;
图5是本发明实施例的一个支配查询图的示例。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
实施例:从dblp中找到需要的论文
dblp计算机科学目录提供了一个引文图g如图1b,其中顶点代表论文,边代表论文之间的引证关系。每篇文章包含一个关键词集,其中每个关键词被赋予了一个权重用于测度它在文中的重要性。事实上,一个研究者会基于引证关系和文章内容相似度来从dblp中寻找论文。例如,一名研究人员希望找到同时被社会网络方面和蛋白质相互作用方面的论文引用的子图匹配方面的论文。此外,这名研究人员需要被社会网络方面文章引用的蛋白质相互作用网络研究方面的论文。这样的查询可以建模构成sms2查询问题,其中包含从g中找到匹配查询图q(图1a)的子图。q中的每篇论文即顶点和其在g中的匹配论文应该有相似的关键词集,而且每个引证关系即边应当准确符合研究人员的要求。
实施例具体的实施方案如下:
步骤1:支配集的选择;一个查询图可能有多个支配集,从而产生sms2查询的不同表现,由此,本发明将提出一个支配集选择算法来选出查询图q的一个更为经济的支配集,从而降低解决sms2查询的开支。
步骤2:集合相似度剪枝;本发明构建了一个创新的倒排模式格用于更好地执行基于集合相似度的有效剪枝。
步骤3:基于结构的剪枝;一个匹配的子图应当不仅仅使其顶点与对应查询顶点相似,还要保证与q同构。因此,在集合相似度剪枝完成后,本发明根据结构限制,为所有查询顶点和数据顶点设计了轻量签名标记用于过滤候选点。
步骤4:基于支配集的子图匹配;本发明提出一种有效的基于支配集的子图匹配算法即ds-match,运用一种支配集选择方法加以辅助。
本发明的步骤1支配集的选择的具体操作流程如下:
一个经济的支配集应当包含最少的支配顶点数,从而保证最小化过滤开支。此外,我们还应当确保每个支配顶点的候选点数是最小的,以减少子图同构过程中的中间结果。找出一个经济的支配集的问题实际上是一个最小支配集问题(mds)。mds问题等价于最小边覆盖问题,该问题是np复杂的。因此,我们运用一个效果最优的branchandreduce算法,该算法从未被选择的查询顶点中迭代地选择一个拥有最少候选点数的顶点u。找出支配集的开支很低,因为查询图通常很小。
由于我们在sms2查询完成之前不知道一个查询顶点u的候选点数,可以利用hashsampling方法来进行快速估算。hashsampling方法可以构建sample
其中
由上,便可以选出一个经济的支配集。
在图1中,可以发现u3有最少的候选点数,因此依据branchandreduce算法,{u1,u3}被选中作为经济的支配集。
本发明的步骤2集合相似度剪枝可以分为如下几个子步骤分别执行:
步骤2.1:频繁模式的选择
用
由于频繁模式数量很多,如果在倒排模式格中一次检索所有的频繁模式,则格无法适用memory。如前所述,频繁模式中元素越多,得到的as上界限制越严格。因此。我们需要选择包含很多元素的频繁模式,这样可以剪掉更多的频繁模式,查询时间也就可以缩短。此外,我们还应该设置每个频繁模式的代表。基于以上内容,我们从顶点集中挖掘密集频繁模式。一个频繁模式p是密集的,如果不存在模式p’使得
步骤2.2:倒排模式格的构建
为了建立一个倒排模式格,我们首先需要将所有频繁模式组织为一个格。在格中,每个连接点p是一个频繁模式,它是其自身所有下位点的子集。将有k个元素的频繁模式表示为k-频繁模式。为了确定索引的复杂度,1-频繁模式被归入格的第一层。对格中每个k-频繁模式p,假定频繁模式p和p′都被s(v)支持且
总之,令{p1,…,pn}为由s(v)支持的频繁模式集合,并假定存在由{p1,…,pn}构造的k条路径。路径是倒排模式格中由从高层向低层的开环连接的点构成的。仅将v插入每条路径最底层处由s(v)支持的频繁模式中,这样就可以有效减少倒排序列的空间开销。
图2是一个倒排模式格的示例,它有图1b中的数据顶点建立。元素a1,a2,a3,a4,分别对应关键词“子图匹配”、“蛋白质相互作用”、“社会网络”、“搜寻”。然后v1={a1},v2={a3,a4},v3={a2,a4},v4={a1,a3},v5={a3},v6={a1}。
步骤2.3:剪枝
本发明将运用三种集合相似度剪枝技术得到查询顶点的所有候选点。首先介绍一下这三种剪枝技术的具体操作流程。
第一种:反单调剪枝
给出查询顶点u,对倒排模式格中的每一个频繁模式p,如果ub(s(u),p)<τ,则倒排序列l(p)和l(p′)中的所有顶点都应该被剪掉,其中p′是p的下位点。
第二种:垂直剪枝
垂直剪枝是基于前缀过滤原则的:如果两个规范化集合是相似的,那么两个集合的前缀应当互相覆盖,因为否则的话两个集合将没有足够的公共元素。
我们将查询集s(u)中的所有元素在支配集的选择过程中按照权重的降序排列进行规范化。排在前面的p个元素则为s(u)的p-前缀。我们找到最大前缀长度p,从而如果有s(u)和s(v)都不覆盖p-前缀,则s(v)可以被剪掉,因为它们没有足够的重叠区域来满足相似度阈值。
为了找出s(u)的p-前缀,每次从s(u)中移动元素时,我们检查剩余元素的集合s‘(u)是否满足相似度阈值条件。将s(u)的l1-范数表示为||s(u)||1=∑a∈s(u)w(a)。如果||s’(u)||1<τ×||s(u)||1,则移动停止。p的值等于|s’(u)|-1,其中|s’(u)|是s’(u)的元素数量。对任意不包含p-前缀元素的集合s(v),有
第三种:横向剪枝
一个查询元素集s(u)不会与一个规模特别大或特别小的集合的频繁模式相似。频繁模式p的规模|p|即为p中元素的数量。在倒排模式格中,每个频繁模式p是p的倒排序列中数据顶点的一个子集。假定我们可以找到的长度上界lu(u),如果p的规模大于lu(u),则p及其倒排序列可以被剪掉。
由于动态元素权重的缘故,我们需要得到s(u)的长度间隔。我们通过按照元素权重正序向s(u)中加入
处于倒排模式格中的同一层的频繁模式有相同的规模,且在k层的规模为k。因此,得到lu(u)后,可以确定横向上界。所有在lu(u)层以下的频繁模式都会被剪掉。
然后本发明将利用以上所有的集合相似度剪枝技术得到查询顶点的所有候选点。
对查询顶点u,我们首先运用垂直剪枝和横向剪枝来过滤出位置错误的模式并确定倒排模式格中应当被扫描的点。然后使用广度优先搜索对其进行遍历。对每个被扫描的点p,考察是否有ub(s(u),p)<τ,若是,则p及其下位点将会被剪掉。为了优化查询效果,频繁模式格驻留在内存,而频繁模式的倒排表驻留在外存上。
图1a中的查询顶点u3,及其元素集s(u3)={a2,a4}。假设w(a1)=o.5,w(a2)=0.4,w(a3)=0.5,w(a4)=0.2,相似度阈值τ=0.6。正如图3a所展现的,由于ub(s(u3),p6)=0.55<0.6,p6和其所有下位点都应当被剪掉。同样的,p1、p3及其下位点也可以被剪掉。这些模式的倒排序列中的所有顶点也都可以被剪掉。
对查询顶点s(u3)={a2,a4},我们可以确定其集合的p-前缀为{a2}。正如图3b所展现的,我们只需要access和其所有下位点。其他频繁模式的倒排序列里所有的顶点都可以被剪掉。
考虑查询顶点s(u3)={a2,a4},和
本发明的步骤3基于结构的剪枝可以分为如下几个子步骤分别执行:
步骤3.1:设计轻量签名
一个匹配的子图应当不仅仅使其顶点与对应查询顶点相似,还要保证与q同构。本发明将根据结构限制,为所有查询顶点和数据顶点设计轻量签名标记用于过滤候选点。
本发明定义了两种典型的结构化签名,称为查询sig(u)和数据sig(v),分别对应查询顶点u和数据顶点v。
查询签名:
给出查询图q中的一个拥有可变邻近顶点ui(i=1,…,m)的顶点u,其查询签名sig(u)由一个位向量集给出,即sig(u)={bv(u),bv(u1),…,bv(um)},其中bv(u)和bv(ui)是分别为集合s(u)和s(ui)的元素编码表示的位向量。
数据签名:
给出查询图q中的一个拥有可变邻近顶点vi(i=1,…,m)的顶点v,数据签名sig(v)表示为:
为了编码结构化信息,sig(u)/sig(v)应当包含u/v及其周围顶点的元素信息。由于查询图通常很小,我们通过编码每个邻近顶点来生成精确查询签名。相对地,数据图比查询图大得多,所以邻近顶点的聚合可以节省很多空间。限制数据签名的数量,从而可以降低剪枝损耗。先将元素集s(u)和s(v)中的元素按照预先定义的顺序进行排列。基于排列好的元素集,用位向量bv(u)对元素集s(u)进行编码。向量中的每个分量bv(u)[i]对应一个元素aj,其中
步骤3.2:设计基于签名的lsh:
为了实现基于结构化信息上的有效剪枝,我们使用一组局部敏感散列哈希函数(lshhashfunctions)来hash每个数据签名sig(v)进入签名桶,接下来对此过程进行定义。
一个签名桶是很多个存储一组带有相同哈希值的数据签名的哈希表的集合。由于发生在相似签名间发生碰撞的概率比不相似的要高得多,每个签名桶中的数据签名的最大hamming距离需要最小化。此外,我们存储桶签名sig(b),该签名由b里的oring中所有数据签名组成,即有sig(b)=[vbv(vt),vbv∪(vt)],其中t=1,…,n,n是b中所有签名的数量。
步骤3.3:结构化剪枝:
基于sms2查询定义,一个数据顶点v可以被剪掉,只要bv(u)和bv(v)的相似度小于阈值τ,或者不存在bv(vj),满足与bv(ui)的相似度限制,其中vj(j=1,…,n)和ui(i=1,…,m)是分别对应v和u的1-hop邻近。
位向量bv(u)和bv(v)间的相似度定义为:
其中∧表示位与运算,∨表示位或运算,a∈bv(u)∧bv(v)意味着对应a的位为1,w(a)则为a的权重。
对每个bv(ui),我们需要确定是否存在bv(vj)使得sim(bv(ui),bv(vj))≥τ。我们估测bv(ui)和bv∪(v)间的标准相似度上界通过以下方法:
位向量bv(ui)和bv∪(v)间的标准相似度上界表示为:
下面给出结构化剪枝依据的定理和引理和具体操作流程:
aggregatedominance定理:
给出一个查询签名sig(u)和数据签名sig(v),如果有ub′(bv(ui),bv∪(v))<τ,则对v的每个1-hop邻近vj而言,都有sim(bv(ui),bv(vj))<τ。
引理1:给出一个查询签名sig(u)和一个桶签名sig(b),假定签名桶b包含n个数据签名sig(vt)(t=1,…,n),如果ub′(bv(u),∨bv(vt))<τ或存在u的至少一个邻近顶点ui使得ub′(bv(u),∨bv∪(vt))<τ,则b中所有的数据签名都可以被剪掉。
引理2:给出一个查询签名sig(u)和一个数据签名sig(v),如果有sim(bv(u),bv(v))<τ或存在u的至少一个邻近顶点ui(i=1,…,m)使得ub′(bv(ui),bv∪(v))<τ,则sig(v)可以被剪掉。
具体的结构化剪枝流程如下。首先剪掉那些不包含查询顶点的候选点的签名桶,然后基于引理1将签名桶整体剪掉。对于保留下来的签名桶b中的候选点v,检查sig(u)和sig(v)间的相似度限制,基于引理2剪掉sig(v)。aggregatedominance定理确保了结构化剪枝不会剪掉合法候选点,因此可以得到准确的结果。
考虑图1a中的查询顶点u1的一个one-hop邻近u3,有bv(u3)=0101,以及数据顶点v5的1-hopv2和v4,有bv(v2)=0011,bv(v4)=1010。由于bv∪(v)=bv(v2)∨bv(v4)=1011,ub′(bv(u3),bv∪(v))<0.6=τ。基于aggregatedominance定理,有sim(bv(u3),bv(vj))<τ,其中j=2,4。因此,尽管有s(u1)=s(v5),v5也不是u1的一个候选顶点。
本发明的步骤4基于支配集的子图匹配可以分为如下几个子步骤分别执行:
步骤4.1:找出支配查询图(dqg)
首先给出支配查询图满足的定理。
定理1:假定u是q的支配集ds(q)的一个支配顶点,如果|ds(q)|≥2,则存在至少一个顶点u'∈ds(q)使得hop(u,u')≤3,其中hop()表示两顶点间hops数量的最小值。支配顶点u’被称为支配顶点u的邻近。
定理2:给出一个图q的一个顶点u,u的1-hop邻近集n1(u)和2-hop邻近集n2(u)被定义为:n1(u)={u′|存在连接u和u′的长度为1的路径};n2(u)={u′|存在连接u和u′的长度为2的路径}。邻近支配顶点的可能拓扑结构如图4所示。图4存在两个邻近支配顶点和间的四种可能的最短路径拓扑。
最后我们可以按照以下条件找出支配查询图。
给出一个支配集ds(q),支配查询图qd被定义为<v(qd),e(qd)>,且有e(qd)中的边(ui,uj)成立,当且仅当以下条件中至少一项成立:
(1)ui是查询图q中与uj邻近的点;
(2)|n1(ui)∩n1(uj)|>0;
(3)|n1(ui)∩n2(uj)|>0;
(4)|n2(ui)∩n1(uj)|>0。
在条件1中,边的权重为1;在条件2中,边的权重为2;在条件3和4中,边的权重为3。为了将查询图q转化为支配查询图,首先要得到q的支配集ds(q),然后为ds(q)中的每对顶点ui和uj确定是否存在连接两顶点的边(ui,uj)和边(ui,uj)的权重。
图5展示了一个查询图q的支配查询图qd的示例。q的支配集包括。注意到边(u1,u3)拥有两个权重“1和2”,原因是在q中u1是u3的邻近且有|n1(u1)∩n1(u3)|>0。
步骤4.2:找出支配查询图的匹配
为了找出支配查询图中的匹配,我们提出保持距离原则。
定理3:保持距离(distancepreservation)原则。给出数据图g中支配查询图qd的一个匹配子图xd,qd和xd分别有n个顶点u1,…,un和v1,…,vn,其中。考虑qd中的边(ui,uj),有以下保持距离原则:
(1)如果边权重为1,则vi是vj的邻近;
(2)如果边权重为2,则有|n1(vi)∩n1(vj)|>0;
(3)如果边权重为3,则有|n1(vi)∩n2(vj)|>0或|n2(vi)∩n1(vj)|>0。
接下来提出一种基于保持距离原则的支配查询图匹配算法用于找出支配查询图的所有匹配。一个子图匹配记为一种从v(qd)到v(x)的映射关系m,其中x是qd的一个匹配子图。找出这种映射关系的过程可以用ssr加以描述。每个状态s都与一个映射m(s)相联系。
算法1:dqg-match
在算法1中,当下状态s初始化为空集。构建一个包含所有可能候选对(u,v)的候选对集合pa(s),并将其添加到当前状态s中,如第五行所示。当候选对(u,v)被添加到当前映射m(s)中时,校验m(s)是否满足保持距离原则,若是,则继续这个过程直到找出一个qd的子图匹配,否则搜索停止。例如,给出支配查询图qd,{v2}和{v3}是对应u1和u3的顶点,因此映射m为v3{(u1,v2),(u3,v3)}。
步骤4.3:子图匹配
首先调用算法1来找出映射关系m(qd)。当前状态s的映射关系m(s)被初始化为m(qd)。然后,将每个支配查询图qd的匹配扩展为查询图q的子图匹配。如果m(s)覆盖了q的所有顶点,则输出映射m(q)。否则,对每个非支配顶点u′∈v(q)-v(qd),考虑u’的1-hop和2-hop的邻近支配顶点。注意到对每个支配顶点ui∈n1(u′)和uj∈n2(u′),候选顶点集c(ui)和c(uj)已经在算法1中被找出。基于保持距离原则,u’的每个候选顶点v’必须是c(ui)和c(uj)中顶点的1-hop和2-hop邻近。然后检查是否有候选对(u′,v′)满足定义1中的运用集合相似度的子图匹配的条件,若是,则该候选对可被添加到当前状态中。循环这个过程直到所有的非支配顶点都被考察结束。
算法2:ds-match
图1a中的查询图q的非支配顶点为u2,因此其邻近支配顶点为u1和u3。由于u1和u3的匹配顶点为u2和u3,因而u2的候选顶点为n1(v2)∩n1(v3)=v1。
本发明研究了运用集合相似度的子图匹配问题,该问题应用十分广泛。为了解决这个问题,考虑顶点集合相似度和图拓扑,提出了有效的剪枝技术。设计了一种新颖的倒排模式格和结构化的签名桶来辅助进行剪枝。最后提出了一种有效的基于支配集的子图匹配算法来找出匹配子图。实验证明了本发明方法的有效性和高效性。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!