一种中文电子病历分词和命名实体识别方法及系统与流程
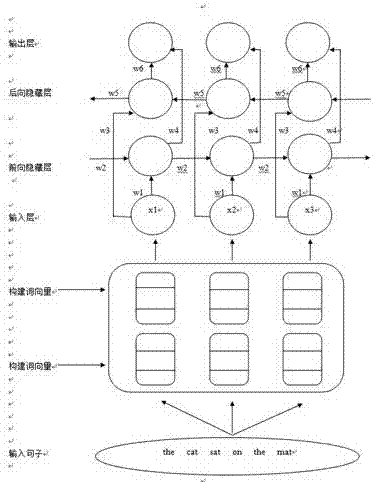
本发明属于自然语言处理,是一种中文电子病历分词和命名实体识别方法及系统。具体是指基于双向长短期记忆网络lstm对实体进行识别及分类预测。
背景技术:
:中文电子病历分词和命名实体识别是指利用生物医学文本挖掘技术对电子病历中具有特定意义的生物医学实体名称,如疾病名称、治疗方案、症状等进行有效的分类与识别。目前生物医学命名实体识别采用的方法主要有:基于规则的方法、基于词典匹配方法、基于统计机器学习的方法、组合分类器等方法。目前使用最广泛的基于机器学习方法过程包括:语料预处理、特征的提取、训练模型并预测。语料预处理过程包括:对电子病历文本的处理,如大小写转换、分词等。运用到的特征主要包括:构造词向量、核心词特征等。机器学习建模的主要方法包括:条件随机场(crf)、最大熵模型(me)、支持向量机(svm)、隐马尔科夫模型(hmm)等。生物医学命名实体识别作为关键而又重要的一步,对于生物医学领域信息抽取的研究具有极大的促进作用。其中半监督的机器学习方法常被应用到命名实体识别中。ando运用此方法在大规模未标注的文本信息中通过原有特征的线性组合产生新的特征将f值提高了2.09%,在biocreativeⅱgm测试集上f值为87.21%,李彦鹏通过特征耦合泛化的方法在biocreativeⅱgm测试集上f值为89.05%。多数有关生物医学领域命名实体识别的研究主要是基于genia数据库。genia数据库是由ohta等。开发的分子生物学领域最大的标注语料库,并且版本3.0x的语料集都是由2000篇medline摘要组成,这些都是以“human’,,“bloodcells’,和“transcriptionfactors”为关键字从medline数据库中挑选出来的。它总共标注了36类实体,包含了超过40万个单词,近乎10万个标注的生物学术语。然而随着相关领域的发展,新词以及众多命名的不规则性导致识别实体名称困难重重,无法构建一个完备的词典。词表示是解决此类困难的有效途径,词表示通常是将词用一种相对应的向量表示,其中每一维度表示一个特征,不同词所属特征不同。常用的词表示方法有one-hotrepresentation、distributedrepresentation等。one-hotrepresentation方法把每个词表示为一个很长的向量,然而这种表示方法存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的,光从这两个向量中无法看出两个词是否有关系。distributedrepresentation表示的一种低维实数向量,这种方法最大的好处就是让相关或者相似的词在距离上更接近了。基于词典匹配的方法是利用字符串完全匹配或部分匹配的方式,从文本中找出最相似的单词或短语完成匹配。crf分词主要考虑的是文字词语出现的频率,结合上下文语句,同时具备较好的学习能力。目前常见的crf分词工具包包括pocketcrf,crf++等。传统递归神经网络(rnn)可以用来连接先前的信息到当前的任务上,具有一定记忆性,然而当处理长句子时,理论上rnn可以处理长期依赖问题。但在实践中,bengio,etal(1994)等人对该问题进行了深入的研究,发现rnn无法成功学习到这些知识。长短期记忆网络lstm是一种特殊的rnn类型,可以学习长期依赖的问题。基于b/s架构的图形交互在线系统,运用特征的机器学习方法对电子病历进行分词和实体识。用户输入电子病历,系统自动完成对单词的分类,具体为,b:实体开始,i:实体中间,o:非实体,di:疾病,sy:症状,te:检查,tr:治疗。输出分好类的单词,并允许用户进行数据分析及打印。技术实现要素:本发明提供了一种基于机器学习以及深度学习的中文电子病历分词和命名实体识别的新方法及系统。一定程度上解决了传统机器学习方法提取特征、识别效率不高等问题,有效提高了对电子病历中命名实体识别的准确度。该发明由三大部分组成:1.基于机器学习方法条件随机场crf对电子病历进行分词训练。2.基于双向长短期记忆网络lstm模型对词向量进行学习并对实体进行分类预测。3基于b/s架构的图形交互在线系统,输出分类好的单词。本发明采用的技术方案包括如下步骤:(一)基于crf(条件随机场)模型对中文电子病历文本进行分词采用条件随机场crf模型将该识别问题转换为字的词位分类问题,通过crf++工具包进行分词,采用定义字的词位信息如下表示:b:实体开始,i:实体中间,o:非实体。标注中一共采用9种不同的标签,分别为b-di,b-sy,b-te,b-tr,i-di,i-sy,i-tr,o。分类每个单词的词向量是通过word2vec工具所提供的cbow语言模型大规模训练未标记语聊获得表2-1命名实体分类表2-2bio标记实体举例句子bio标记出现左颈淋巴结肿大,无咳嗽,咳痰,无饮食呛咳。出现/o左颈/b-sy淋巴结/i-sy肿大/i-sy,/o无/o咳嗽/b-sy,/o咳痰/b-sy,/o无/o饮食/b-sy呛咳/b-sy。(二)基于双向长短期记忆网络lstm模型对单词特征向量进行深度表示学习,并对实体进行分类预测。双向长短期记忆网络lstm模型包含:输出层、后向隐藏层、前向隐藏层、输入层组成。其中,在每一个时步六个特有的权值被循环利用,其六个权值对应如下:输入层到前向和后向隐藏层(w1,w3),隐藏层到隐藏层自己(w2,w5),前向和后向隐藏层到输出层(w4,w6)隐藏层为lstm模型,lstm模型由三个门(forgetgage、inputgate、outputgate)与一个记忆单元(cell)组成每一个单词的词向量作为双向循环神经网络lstm的输入,并与上一时刻的输出共同得到当前输出。该过程分为三个阶段第一阶段:由forgetgate层通过sigmoid函数来选择性过滤上一时刻的信息,其中,为上一时刻输出,为当前输入,即当前词向量,为0到1的值,用来过滤上一时刻学到的信息;第二阶段:产生需要更新的新信息;首先由inputgate层通过sigmoid来决定更新哪些值接着由一个tanh层来生成新的候选值新信息的候选值进行刷新第三阶段:模型的输出通过sigmoid层得到一个初始输出:然后由tanh函数将行缩放,两者相乘,得到模型的输出:本发明构建了一套基于b/s架构的图形交互在线系统。本发明训练crf模型对中文电子病历进行分词,并基于循环神经网络的深度学习方法对特征进行深度表示,对实体进行分类预测,相较于传统的机器学习方法,一定程度上解决了提取特征、识别效率不高等问题,提高了对电子病历中命名实体识别的准确度,实现对中文电子病历分词、命名实体识别及抽取。附图说明图1双向长短期记忆网络lstm模型。图2双向长短期记忆网络lstm隐藏层主要模块。图3是命名实体分类图。图4是bio标记实体举例图。具体实施方式本发明的系统能够对给定的电子病历文本自动进行词分类以及命名实体识别。该系统基于b/s架构(browser/server,浏览器/服务器模式,主要由js、html、angularjs等技术实现),分为视图层、逻辑层、数据层三部分。系统结构2-3系统结构表(1)用户输入待解析中文电子病历样本中文电子病历文本输入支持用户键盘输入或者上传本地文件两种方式,通过视图层接收用户的数据并提交给逻辑层,由逻辑层进行数据分析后存入数据层;(2)系统对待解析中文电子病历进行解析该功能的实现由逻辑层与数据层协同完成,逻辑层基于条件随机场crf原理对中文电子病历进行断词、分句等处理后,由word2vec工具所提供的cbow语言模型大规模训练未标记语料来获得所有词向量,并依次输入双向长短期记忆网络lstm中进行中文电子病历的实体识别;(3)将(1)、(2)两步实体识别后的结果传入数据层进行存储,同时通过视图层反馈给用户。用户对抽取结果的人工校正当用户提交了数据以后,如果发现该系统返回的结果有明显错误,本系统允许用户对数据进行修正,并可以将修正后的数据存入进数据层中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1