基于自编码器的人物亲缘关系识别方法与流程
本发明涉及人工智能技术领域,特别地,涉及一种基于自编码器的人物亲缘关系识别方法。
背景技术:
针对人脸图像的研究一直是计算机视觉领域十分重要的内容。人脸图像的研究之所以重要,是因为人脸表达了诸多个人信息,在社会生活的中有着特殊作用。在人工智能领域,模仿人类视觉完成对人脸的认知已经取得了丰硕的成果。如今在人脸识别、身份认证等多个方面,计算机视觉已经可以成功的替代人类。通过人脸图像识别人物的亲缘关系仍是新颖而富有挑战的工作。
从人脸图像中研究人物关系是近几年兴起的课题,近年来,相关的几个数据库和算法相继被提出,然而大多数现有的数据库都规模过小且标准不一。2014年召开了第一届的亲缘关系识别大赛,以统一的衡量体系来评估现下的一些方法,建立了两个关于亲缘关系的数据库KinFaceW-I和KinFaceW-II。
过去的五年在心理学、生物学和计算机视觉领域里,关于基于人脸图像的人物关系识别主要分为两个流派,一种是基于人工设计的描述子,另一种是基于相似性学习。对于基于描述子的方法来说,人们提取了一些重要的特征例如肤色、梯度直方图、Gabor梯度方向金字塔、显著性信息、自相似特征和动态表情等作为常用的人脸表征,还提出了一种基于空间金字塔的特征描述子作为人脸图像的特征,改进了的支撑向量机用以将两个个体间的特征距离予以分类;在基于相似性学习的方法中,子空间和度量学习被用作来学习更好的特征空间来衡量面部样本的相似性。具有代表性的算法包括:子空间学习和邻近空间度量学习,将多特征融合,学习一种区分性度量用以扩大非亲关系距离,缩小亲缘关系距离,以达到识别目的。
然而,当机器视觉试图模拟人类视觉时,往往难以模仿人类的社会经验,现如今的人工智能用以补足这个缺点的方式是大量的人工标注数据,以充分的训练来构造更鲁棒的模式识别算法。人物间的关系识别难度较普通人脸识别大上许多,比较对象从一种容貌和对应的一个身份到一对人脸和某种关系,这种关系是经过人类设定的。而当一个人只拥有一个身份的同时,关系与人物对、人物之间可以是多对多的复杂关系。
针对现有技术只能进行人脸识别、无法进行人物间关系识别的问题,目前尚未有有效的解决方案。
技术实现要素:
有鉴于此,本发明的目的在于提出一种基于自编码器的人物亲缘关系识别方法,能够进行人物间的亲缘关系识别。
基于上述目的,本发明提供的技术方案如下:
根据本发明的一个方面,提供了一种基于自编码器的人物亲缘关系识别方法,包括:
输入人脸图像并进行预处理;
根据人脸图像确定人物的身份特征;
构建自编码器并组成自编码神经网络;
在自编码神经网络中对身份特征反复进行前向传播与反向传播;
更新权重直到代价函数最小化并获得身份特征的关联特征;
根据关联特征识别人脸图像之间的亲缘关系。
在一些实施方式中,所述输入人脸图像并进行预处理包括:
输入待识别的人脸图像;
对人脸图像进行人脸检测与旋转校正;
将人脸图像剪切为指定尺寸的样本。
在一些实施方式中,所述构建自编码器并组成自编码神经网络包括:
根据稀疏因子构建多层稀疏自编码器;
根据逐层贪婪算法训练网络初始值;
根据反向传播算法调整网络参数。
在一些实施方式中,所述根据稀疏因子构建多层稀疏自编码器包括:
根据指定的稀疏性参数与隐藏神经元的平均活跃度确定稀疏因子;
根据稀疏因子与激活函数构建多层稀疏自编码器。
在一些实施方式中,所述根据逐层贪婪算法训练网络初始值包括:
分层训练自编码神经网络各层参数;
将以前每一层训练好的输出作为后一层的输入;
根据训练好的网络各层参数确定网络初始值。
在一些实施方式中,所述根据反向传播算法调整网络参数包括:
根据数据集样本在神经网络中前向传播的结果确定代价函数;
根据代价函数确定神经网络中每层每个神经元的残差;
根据每层每个神经元的残差计算代价函数对每层每个神经元参数的偏导;
根据代价函数对每层每个神经元参数的偏导、网络学习速率调整网络参数。
在一些实施方式中,所述在自编码神经网络中对身份特征反复进行前向传播与反向传播包括:
从输入层开始,根据网络参数计算每一层的激活值;
从输出层开始,根据两身份特征计算一身份特征的输出与另一身份特征的残差;
根据一身份特征的输出与另一身份特征的残差计算代价函数对每层每个神经元参数的偏导;
根据代价函数对每层每个神经元参数的偏导,计算权重系数的变化量;
根据权重系数的变化量更新权重系数。
在一些实施方式中,所述人脸图像之间的亲缘关系包括父子关系、父女关系、母子关系、母女关系。
在一些实施方式中,所述构建自编码神经网络为使用以亲缘关系种类为主要线索的数据集样本构建自编码神经网络;根据人脸图像确定人物的身份特征为人脸图像具有指定特征的概率。
从上面所述可以看出,本发明提供的技术方案通过使用输入人脸图像并进行预处理、根据人脸图像确定人物的身份特征、构建自编码器并组成自编码神经网络、在自编码神经网络中对身份特征反复进行前向传播与反向传播、更新权重直到代价函数最小化并获得身份特征的关联特征、根据关联特征识别人脸图像之间的亲缘关系的技术手段,能够进行人物间的亲缘关系识别。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为根据本发明实施例的一种基于自编码器的人物亲缘关系识别方法的流程图;
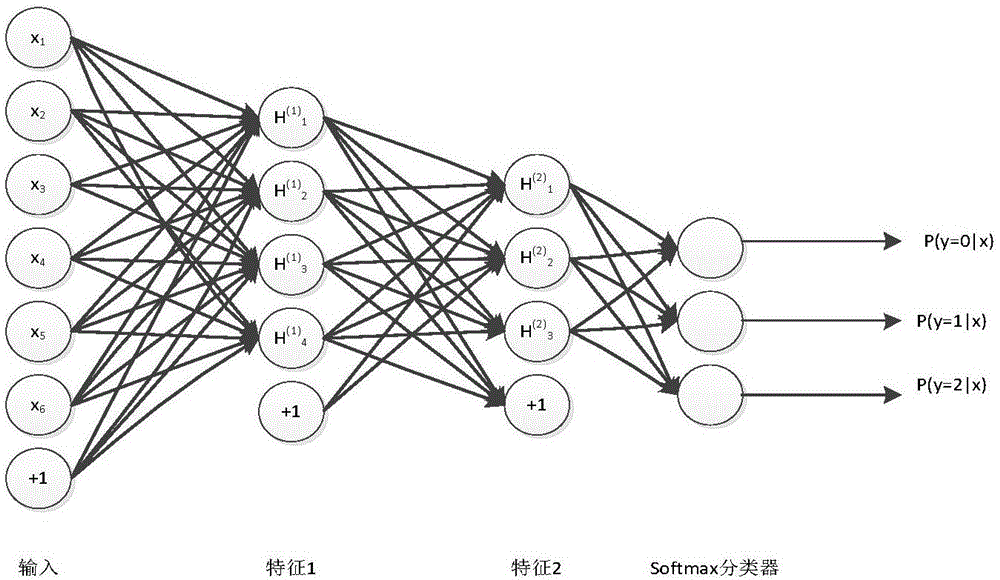
图2为根据本发明实施例的一种基于自编码器的人物亲缘关系识别方法中,深度神经网络的结构图;
图3为根据本发明实施例的一种基于自编码器的人物亲缘关系识别方法中,深度卷积神经网络中多卷积核的卷及区域图;
图4为根据本发明实施例的一种基于自编码器的人物亲缘关系识别方法中,深度卷积神经网络的模型图;
图5为根据本发明实施例的一种基于自编码器的人物亲缘关系识别方法中,深度卷积自编码神经网络的总体结构图;
图6为根据本发明实施例的一种基于自编码器的人物亲缘关系识别方法中,深度身份卷积神经网络的结构图;
图7为根据本发明实施例的一种基于自编码器的人物亲缘关系识别方法中,深度自编码网络的结构图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进一步进行清楚、完整、详细地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
基于上述目的,根据本发明的一个实施例,提供了一种基于自编码器的人物亲缘关系识别方法。
如图1所示,根据本发明实施例提供的基于自编码器的人物亲缘关系识别方法包括:
步骤S101,输入人脸图像并进行预处理;
步骤S103,根据人脸图像确定人物的身份特征;
步骤S105,构建自编码器并组成自编码神经网络;
步骤S107,在自编码神经网络中对身份特征反复进行前向传播与反向传播;
步骤S109,更新权重直到代价函数最小化并获得身份特征的关联特征;
步骤S111,根据关联特征识别人脸图像之间的亲缘关系。
在一些实施方式中,所述输入人脸图像并进行预处理包括:
输入待识别的人脸图像;
对人脸图像进行人脸检测与旋转校正;
将人脸图像剪切为指定尺寸的样本。
在一些实施方式中,所述构建自编码器并组成自编码神经网络包括:
根据稀疏因子构建多层稀疏自编码器;
根据逐层贪婪算法训练网络初始值;
根据反向传播算法调整网络参数。
在一些实施方式中,所述根据稀疏因子构建多层稀疏自编码器包括:
根据指定的稀疏性参数与隐藏神经元的平均活跃度确定稀疏因子;
根据稀疏因子与激活函数构建多层稀疏自编码器。
在一些实施方式中,所述根据逐层贪婪算法训练网络初始值包括:
分层训练自编码神经网络各层参数;
将以前每一层训练好的输出作为后一层的输入;
根据训练好的网络各层参数确定网络初始值。
在一些实施方式中,所述根据反向传播算法调整网络参数包括:
根据数据集样本在神经网络中前向传播的结果确定代价函数;
根据代价函数确定神经网络中每层每个神经元的残差;
根据每层每个神经元的残差计算代价函数对每层每个神经元参数的偏导;
根据代价函数对每层每个神经元参数的偏导、网络学习速率调整网络参数。
在一些实施方式中,所述在自编码神经网络中对身份特征反复进行前向传播与反向传播包括:
从输入层开始,根据网络参数计算每一层的激活值;
从输出层开始,根据两身份特征计算一身份特征的输出与另一身份特征的残差;
根据一身份特征的输出与另一身份特征的残差计算代价函数对每层每个神经元参数的偏导;
根据代价函数对每层每个神经元参数的偏导,计算权重系数的变化量;
根据权重系数的变化量更新权重系数。
在一些实施方式中,所述人脸图像之间的亲缘关系包括父子关系、父女关系、母子关系、母女关系。
在一些实施方式中,所述构建自编码神经网络为使用以亲缘关系种类为主要线索的数据集样本构建自编码神经网络;根据人脸图像确定人物的身份特征为人脸图像具有指定特征的概率。
综上所述,借助于本发明上述的技术方案,通过使用输入人脸图像并进行预处理、根据人脸图像确定人物的身份特征、构建自编码器并组成自编码神经网络、在自编码神经网络中对身份特征反复进行前向传播与反向传播、更新权重直到代价函数最小化并获得身份特征的关联特征、根据关联特征识别人脸图像之间的亲缘关系的技术手段,能够进行人物间的亲缘关系识别。
基于上述目的,根据本发明的第二个实施例,提供了一种基于自编码器的人物亲缘关系识别方法。
机器学习的目的是要通过样本学习到一个函数,通过这个函数来预测将来的样本值。要找到这个函数需要大量工作,建立起深度学习网络是其中一种。在监督学习中,假设有训练样本集(xi,yi),那么神经网络可以用模型hW,b(x)来表示一种非线性函数,其中(w,b)是用来拟合数据的参数。
神经网络由诸多神经元组成,他们彼此相互连接,一个神经元的输出作为下一个神经元的输入。图2示出的是一个典型的深度神经网络示意图。神经网络的参数(W,b),其中是第l层第j单元与第l+1层第i单元之间的联接参数,即连接线上的权重,是第l+1层第i单元的偏置项。用表示第l层第i单元的输出值。对于给定参数集合(W,b),神经网络就可以按照函数hW,b(x)来计算输出结果:
z(i+1)=W(i)x+b(i),a(i+1)=f(z(i+1)) (1)
hW,b(x)=a(n) (2)
将输入数据经由网络参数计算,输出激活值的过程叫做前向传播。其中函数f:被称为“激活函数”。可以选用sigmoid函数作为激活函数f(·)。
虽然深度网络在理论上的简洁性和较强学习特征能力是在十几年前就被发掘的,但真正兴起却是近几年的工作,原因是贪婪算法出现之前的网络训练存在着巨大的困难。本发明实施例将分别阐述两个对深度神经网络十分重要的算法,一个是逐层贪婪算法,另一个是反向传导算法。
逐层贪婪算法:以往深度神经网络的训练方法是对网络参数进行随机设定初始值,计算网络激活值后根据网络输出与标签的差调整参数,直至网络收敛。这导致了以下的问题:随机设定初始值会引发收敛到局部最小值问题,再者,用整体的误差调整参数对低层级的参数影响太小,使得低层级的隐层难以有效的学习。逐层贪婪算法极大地改进了深度神经网络的训练方法,使得网络性能进一步提高。逐层贪婪算法的主要思想为:分层训练各层参数,每次只训练网络中的一层。将已经训练好的前层的输出作为第层的输入;整个网络的初始值设定来自单独训练的各层参数。这种自顶向下的监督学习,根据标签对整个网络进行反向传播算法,调整网络参数。
反向传导算法:对数据集{(x1,y1)…(xm,ym)},通过样本进入神经网络进行前向传播得到结果y=hW,b(x)后,可以定义样本(x,y)的代价函数为:
数据集整体的代价函数为:
公式中第二项的目的在于减小权重的幅度,防止过度拟合。
要求得参数(W,b),使得网络的代价函数最小,不断的迭代优化中,可以使用梯度下降法不断对参数进行更新,其中α是学习速率:
反向传导算法是用来计算偏导数的:
首先,神经网络进行前向传播,对每个j得到第Lj层的输出值。
对一个有着n层的网络来说,计算第n层的每个神经元i残差:
这个残差表示的是,第i个神经元对最终输出值与真实值的误差的贡献。
输出层下的其它层l,都继续计算残差:
δl=(W(l))Tδl+1·f′(z(l)) (8)
反向传导的意义正在以上两步中体现了出来,即从后向前逐次求导。
计算偏导数值,用以更新权重。
计算得到偏导数后,即可根据公式(6)更新网络权重,逐步减小J(W,b)的值,最终得以求解神经网络。
自动编码器(Auto-Encoder,AE)是一种无监督的学习算法,深度自编码器利用了图3所示神经网络已有的深度结构,是一种用输入重构输出的神经网络。即学习的函数为hW,b(x)≈x,网络同样也是应用逐层贪婪算法训练,反向传播算法调整网络参数。输入即会随着层数不同而变换为不同的表示,这些表示就是原始输入的特征。自编码器为了重构原始的输入,就必须学习到数据中隐藏的重要特征。
一个恒等函数的学习看似简单,但假如稀疏的限制就会迫使深度自编码器学到有意义的特征。设定一个向量维度为n作为输入数据,网络的一个隐藏层L2有m个隐藏神经元。AE要完成的是输入在域上的变化,如果此时限制m<n,那么AE就被迫要学习输入的压缩表示。如果输入的数据是完全彼此独立毫无关系的无意义数据,学习结果并没有意义。但如果输入数据里蕴含着一些彼此相关的规律和结构,这时算法就能够学习到比原始数据更有代表性的特征。
加入稀疏性原则来自生物学上的启发,生物学上研究表明,人类视觉对某个输入有所响应时仅有一部分的神经元是被激活的,其余大部分神经元都是被抑制的。稀疏性原则的限制是要使得大部分的神经元都是被抑制的。由于应用了公式(3)中给出的sigmoid函数作为激活函数,所以输出接近0认为是抑制状态,输出靠近1是激活状态。
要加入稀疏性原则,定义稀疏因子为:
其中表示的是隐藏神经元j的平均活跃程度,当稀疏性参数ρ被赋予一个较小的值,即要求接近ρ。KL是相对熵,相对熵运算使得稀疏因子的值随着与ρ的差异增大而单调递增,当两者相差为零,稀疏因子的值也为零。
整个深度自编码器的代价函数为:
其中,J(W,b)如之前公式(4)定义;β是控制稀疏性权重的参数。
卷积神经网络(Convolutional Neural Networks,CNN)受视觉系统的结构启发而产生,是目前解决图像中模式识别问题效果最好的深度模型,在ImageNet上取得了目前的最好成绩。
卷积神经网络可以学习到一种输入到输出的映射关系,这一过程中可以隐式的学习数据中暗藏的特征,而不需要任何精确数学表达式。卷积神经网络的诸多特点使其在图像问题上有着巨大的优势。CNN的卷积神经元设计使其十分适应图像数据的结构,局部感知和权值共享的特点减少了计算复杂度,也可以得到一定的空间不变性。而不断加深的层次计算,也使得原始数据逐渐成为抽象程度更好的特征。
普通的神经网络采用的计算方式是全连接的方式,如图3所示,全连接的运算方式使得隐含层中每一个神经元需要遍历输入图像的每一个像素,这种方式会直接产生巨大的计算量。
为了降低参数数目,卷积神经网络采用了局部感受的方式。这与人类视觉系统对外界的认知一致,首先感受局部的视野,综合局部来掌握全局信息。实际的自然图像中,由于图像中有意义内容的分布并非全局而是局部,并不需要每个神经元对所有像素进行感知。图3所示的加入卷积核的卷积操作直接减少了所需计算的参数量。
进一步减少参数的操作是权值共享。之所以可以应用权值共享的思想,是因为在自然图像中,并非所有的内容都特征鲜明,不同部分的内容可以共享同样的特征,某一部分的特征可能在另一部分也是适用的。从统计学的角度来看,特征与其所在的位置无关。从某个位置学习到的特征可以作为一种探测器,当这个特征与样本的其它位置做卷积操作,得到的就是整个大尺寸图像对于这个特征的不同激活值。
如果只设置一个大小为10*10的卷积核,会得到100个特征,这样的特征提取并不充分。添加多个卷积核,如图3所示,就可以学习到更多的特征,完成充分的特征提取。每个卷积核都会通过卷积操作生成新图像,称为特征图(Feature Map)。特征图的个数与卷积核的个数一样,如前文所说,将卷积核看作是探测器,特征图实际上反映了原图对某个卷积核所代表的特征的响应。
卷积操作利用下面的公式进行运算:
其中,Mj代表了要进行卷积操作的第j个特征图。
通过卷积操作获取的特征降低了原始数据的维度,但这个数据依旧过于庞大,例如,输入图像是一个100×100的灰度图像,如果定义了100个大小为10×10的卷积核,这一百个卷积核和图像进行卷积操作,得到的特征图大小为:(100-10+1)×(100-10+1)=8,281。由于有100个特征,故所有特征图的大小总共为828,100。如果将这样的特征图应用于训练分类器等任务,仍会面临计算困难和过拟合(over-fitting)的现象。
之所以使用卷积操作和权值共享,依据的是图像相对“静态”的属性,前文已经默认不同位置可能共享相同的特征,为了处理大尺寸图像,可以对不同位置的特征进行聚合统计。用某个区域的平均值(Average-Pooling)或者最大值(Max-Pooling)来替代该区域的值,这种操作叫做池化(Pooling)。池化操作实际上完成了一种空间下采样,不仅仅使得特征的维度有效降低,还会获得一定的空间不变性。最大池化计算如下所示:
在公式中,Ri表示了要进行池化操作的区域,在一个步长为[m,n]的区域里,区域中最大值将成为这个区域的表征。
卷积核的二维设计和空间下采样的操作,十分适用于图像的数据特点。在图像中的连续范围里进行池化,那所下采样的特征实际上来自同一个卷积核,是对同一种特征的响应,这样的池化使得特征具有了平移不变性。卷积神经网络在图像处理方面有着独特优势,总结上述特点如下:
第一,局部感受和权值共享的特殊结构更适应图像数据,布局模仿了生物神经网络,网络复杂性较其它神经网络模型大大降低。
第二,使用CNN所提取的特征来自对数据的学习,而非人工设计,使得特征更加高效,有通用性。CNN可以直接将图像作为输入,融合多层感知器,在提取图像特征的同时直接处理分类、识别等问题。
第三,CNN网络权值共享的特点保证了网络运算支持并行运算,这一点大大提高了网络训练的效率,在大数据时代极为重要。
在实际的CNN构造中,常见的模型均使用多层卷积,卷积层和池化层交替进行,最后加入全连接层。在CNN的底层,学到的特征通常是局部的,特征的全局化是随着层级加深而进行的,最终实现输入数据的特征提取。
图4示出的深度神经网络结构是目前CNN的经典结构,该模型采用2个GPU进行并行计算。第一层、第二层、第四层和第五层的卷积层将参数分为了两个部分,并行训练,相同的数据在两个不同的GPU上进行训练,得到的输出直接连接作为下一层的输入。
输入是224×224×3大小的彩色图像。
第一层为卷积层,共有96个大小为11×11的卷积核,每个GPU上48个。
第二层为池化层,采用最大池化方法(max-pooling),池化核大小为2×2。
第三层为卷积层,共有256个大小为5×5的卷积核,每个GPU上128个。
第四层为池化层,采用最大池化方法(max-pooling),池化核大小为2×2。
第五层为卷积层,共有384个大小为3×3的卷积核,每个GPU上192个。与上一层全连接。
第六层为卷积层,共有384个大小为3×3的卷积核,每个GPU上192个。这一层卷积层与上一层之间没有加入池化层。
第七层为卷积层,共有256个大小为5×5的卷积核,每个GPU上128个。
第八层为池化层,采用最大池化方法(max-pooling),池化核大小为2×2。
第九层为全连接层:将第八层经过池化的特征图连接成一个4,096维的向量作为本层的输入。
第十层为全连接层:输入4,096维的向量到Softmax层进行Softmax回归,输出的1,000维向量代表图片属于该类别的概率。
该模型在ImageNet LSVRC中取得2012年的冠军,top-5错误率为15.3%。这个CNN网络的训练集图片数目约127万,验证集约5万,测试集约15万。
如图4所示的深度模型中,最后一层是Softmax层。Softmax回归是一种在深度模型中常用的多分类器。可以通过衡量网络输出的标签与给定真实标签的错误来进行反向传播。当选取分类结果作为网络的输出时,整个深度网络可以被认为是一个分类器。当所需要的不是分类结果,而只是中间值,那么深度神经网络高层级的神经元的激活值即是所需的特征。
事实上,深度神经网络的每一层都是原始数据的另一种特征,只是随着网络层级的加深,网络普遍设计成越深越紧凑的结构,更深隐层的激活值往往更具有表达能力。
本发明实施例认为,要想识别出两人之间是否具有某种关系,一定要首先对两个人物都有所了解。首先提取出分别代表两个人物的身份特征,这一过程需要基于一个深度卷积自编码网络,即图中的Deeep ConvFID Net;在获得各自的身份特征后,再对其之间的关系进行学习,这一过程基于一个深度自编码器,即图中的Deep AEFP。本发明将详细给出需要构建的两种不同深度神经网络的构造和训练过程,并将两个网络有效结合起来,用以提取关联特征。
当前的研究表明,虽然深度卷积网络可以将提取特征和完成分类功能同时实现,但对于人脸图像来说,网络本身对人脸识别的准确率并不高,本发明应用深度卷积网络提取出代表个人身份的身份特征。在得到一对人物的身份特征后,利用多层自编码器探寻两者之间的关系。自编码器的思想是利用输入重构目标值,本发明旨在这个重构过程中找到输入和输出的中间值来代表两者的紧密关系。本发明整合了两种深度网络设计了一个新的深度卷积自编码神经网络(Deep Convolutional Auto-Encoder Networks,CNN-AE Net),这个深度模型如图5所示。本发明所设计的深度卷积自编码神经网络通过输入一对人物,最终学习出人物对之间的关联项特征。
整个深度卷积自编码神经网络定义为CNN-AE。在这个深度模型里,输入图像首先会经过一个卷积神经网络,定义为ConvFID Net(Convolutional networks for Facial ID)。原始输入经过ConvFID网络会被转化更具有身份代表性的FID(Facial ID)。一对人物的FID将作为一个多层自编码器的输入,图5所示的上方箭头表示自编码器前向运算,下方箭头表示自编码网络反向反馈。这个多层自编码器被定义为AE-FP(Auto-Encoder for Face Pairs)。网络高层级的激活值会被取做关联向量RF(Relational Features)。
将输入人物对的人脸图像(Person 1and Person 2)定义为(p1,p2),本发明构建的深度卷积自编码网络将完成以下学习过程:
为了得到有效的FID,必须构建高效的ConvFID。图6中给出了获取身份特征的深度卷积神经网络ConvFID结构。图中展示了深度网络的细节,包括卷积核的大小和个数、卷积后特征图的大小和个数、下采样层的个数和下采样步长。Softmax回归作为最后一层,用以将身份特征与身份标签匹配。最后一个卷积层是全连接层,输入图像最终将被网络置为一个160维的向量,作为其身份特征。
为表示图像的尺寸,本发明全篇使用X×Y×C的形式表示,其中(X,Y)代表图像的尺寸,而C代表图像的通道数。卷积核实际上也可以认为是一个具有二维结构的小图像,故使用同样的表达方法。
如图6所示,输入是一个大小为63×55×3的彩色图像,这里需要注意,在训练中本发明为了得到更好的网络效果,在训练时使用了不同尺寸的输入,在其他尺度的图像作为网络输入时,经过各层卷积核操作输出的特征图的大小会有所变化,会通过改变最后一层卷积层,使得全连接层的大小为160维的向量。
如图6所示,输入数据经过ConvFID后会得到相应的身份特征FID,一对FID即是AEFP深度网络的输入值。图7中给出了学习关联特征的深度AEFP网络结构以及网络进行前向传播和反向反馈的方向。
组成多层自编码神经网络的是多层稀疏自编码器。如图所示,本发明设计的AEFP Net有3个隐层。在下面的公式中,a(i)代表第i层的激活值,当i是第一层输入层时,a(i)即是输入x。W(i,i+1)与b(i,i+1)均代表相邻两个隐层之间的权重与加权项。
z(i+1)=W(i,i+1)a(i)+b(i,i+1),a(i+1)=f(z(i+1)) (14)
在训练网络时,加入深度学习中常用的策略:微调(fine-tune)。基本思想是将整个自编码神经网络当做一个模型,每次迭代的时候对网络的参数进行优化。
微调网络时按照如下的步骤进行:
对网络进行一次前向传播,从输入层开始,计算公式(17),逐步获得每一层的激活值。
对输出层,用nl表示。令残差表示的是网络的输出与目标值FID-2的差:
对接下来的低层次的各个隐层l,令:
δl=(W(l))Tδl+1·f′(z(l)) (16)
计算所需要的偏导数:
计算权重系数的改变值:
更新权重:
重复上述步骤多次迭代来减小代价函数J(W,b;FID(1),FID(2))的值。
自编码器是一种无监督的深度学习构造,本发明通过加深层数、精心设计神经元的个数使得中间隐层的激活值可以再后续的验证中代表FID(1),FID(2)间的特征,称之为关联特征,这个关联特征可以有效的代表在ConvFID中输入的一对人物的关系。
从人脸图像中识别亲缘关系是人脸分析领域的拓展,这项工作可以拓展人工智能的应用。针对一个家族,亲缘关系的识别可以帮助他们建立家谱,甚至找寻庞大的氏族。在社会的热点话题寻找走失儿童中,机器视觉的方法可以迅速辅助人工决策等。
如何从人脸图像中识别出人物之间的亲缘关系是本发明要研究的问题。本发明依次提取出人物的身份特征和关联特征,基于关联特征识别人物的亲缘关系。对验证算法的过程和设置给出详细的说明,对结果进行多方比较和分析。
本发明从数据集KinFaceW-I和KinFaceW-II中选取识别亲缘关系的数据样本,包括父子关系、父女关系、母子关系和母女关系。两个数据库所有家长们和子女们的人脸图像均是来自非限制条件下公开数据的网络采集,并没有限制人物的动作、光照、表情、年龄、人种、背景等方面。两个数据集的不同之处在于,KinFaceW-I中拥有亲缘关系的一对人脸图像是在不同的照片上获取的,而在KinFaceW-II中,大多数的具有亲缘关系的人脸图像是在同一张照片上获取的。
在这两个数据库中,有上文定义过的父子、父女、母子、母女的亲缘关系。在KinFaceW-I数据库中,共有156对父子、134对父女、116对母子、127对母女。在KinFaceW-II数据库中,四种亲缘关系均含有250对人脸图像。
数据库经过了人工的标注,还给出了部分负样本。在KinFaceW-I数据库的验证集中,给出了156对正样本和156对负样本,其中每一种关系大概是27对人脸图像。在KinFaceW-II数据库中,将数据分为五份,其中一份作为测试集。测试集汇中共包含250对正样本和250对负样本,每一种关系有50对正负样本。
在获取KinFaceW-I和KinFaceW-II数据库后,将其尺寸裁剪到63×55×3的尺寸以适应所设计的ConvFID模型。并同样将每一张样本图取样成不同位置的小块,来训练多个ConvFID。
本发明的算法分为两个阶段:提取关联特征和识别关系阶段。在提取关联特征阶段,最主要的部分是提前训练深度模型,使用训练好的模型进行前向传播即可得到特征。在识别关系阶段,又分为训练和测试两个部分。本发明按照步骤顺序陈述算法实现的全部配置。分为训练深度网络部分、提取关联特征部分以及利用关联特征识别亲缘关系部分。
训练深度卷积神经网络ConvFID阶段:
训练数据:YouTubeFace Data Base,共使用47,850张图片进行训练。
训练环境:基于OS X Yosemite系统下的Python2.7&Theano0.7[65]。处理器2.7GHz Intel Core i5,内存8G。
训练时间:共训练6个ConvFID网络,每个网络训练时迭代均为20次,平均每次迭代约480s,训练时间总计约16小时。
训练深度自编码器AEFP阶段:
训练数据:KinFaceW-II数据集中1,000对人脸图像进行训练。
训练环境:基于Windows7系统下的Matlab R2012b[66].处理器IR GPU G2030,内存4G。
训练时间:对网络迭代次数为300次,总计约17分钟。
提取关联特征阶段:
提取数据:提取KinFaceW-I/II数据集中所有图像的关联特征。
提取环境:OS系统Python2.7下提取身份特征FID耗时217s。
Win7系统Matlab下提取关联特征RF。
识别亲缘关系阶段:
训练集与测试集:根据评测规则指向的人脸图像的关联特征RF。
识别环境:Win7系统下的Matlab&LibSVM。
算法按照上述实践依据的评价规则如下:通常来说,对于验证和识别的任务有两种评测标准],在本发明提到的所有识别率中,均采用了Open-set。这是因为希望达到的人物关系识别系统是可以针对未知图像做出判断的,而不需要重新设计系统。
在设置训练集和测试集中,将两个数据库中的各种关系都均分为五份,使得训练集和测试集的数目比约为4:1。值得注意的是,负样本的产生也是源自这两个数据集体,即选取一位家长,随即再选取一位不是他后代的人脸图像,这样的一对数据作为负样本。
在学习人脸图像中亲缘关系的关联特征中,本节以父子关系为例,定义父子关系为F-S关系。数据来自KinFaceW-I和KinFaceW-II数据库中经过预处理的人脸图像。
用来学习关联特征的是多层自编码器,这个网络的输入是父子关系中儿子的身份特征,定义为FIDps,而网络的目标值则是父亲的身份特征,定义为FIDpf.本发明设计的AEFP试图通过不断的计算网络输出与目标值之间的误差,来使得网络深层的激活值能够成为关联特征。这种关联特征不能单独代表输入和输出的任意一方,只是代表了双方存在的关系。
由于经由ConvFID网络提取的身份特征最终都被整合为320维的一维向量,要充分利用这两个具有高效表达能力的特征学习一种关联特征,我们利用自编码器的方法源于以下两点:
第一,自编码器是一种无监督的学习算法,其思想简单,实现高效。可以无监督的学习到数据内部隐含的模式,更加接近人工智能的需求。
第二,使用自动编码器的方式有效的降低了数据的维度,所加入的稀疏性原则可以更有效的提取特征。
由此的到的80维的特征作为所定义的关联特征RF。这个特征将被用于SVM分类器中进行二分类,完成对是否具有父子关系的识别任务。
对算法的整体实现,这里给出一段伪代码说明。
算法:基于深度学习从人脸图像中识别父子亲缘关联特征。
输入:
父亲人脸图像F;儿子人脸图像S;
定义的网络CNNAEW,b(其中包括两部分:ConvFIDW,b与AEFPW,b)
ConvFIDW,b:{input,layer1,layer2,…layer9,FID_layer,Softmax layer};
AEFPW,b:{input,layer1,layer2,RF layer,output},{input,layer1,output};
步骤:
F=P1;S=P2;RF(label)=N;
标记所有人脸,对应的亲缘关系给出相同标签;
前向计算FIDF=ConvFIDW,b(F);FIDS=ConvFIDW,b(S);
无监督的计算:
output_layer_F=AEFPW,b(FIDF);
Minimize(output_layer_S,output_layer_F);
RF(F,S)=AEFPW,blayer3(FIDF,FIDS);
提取训练集和验证集中所有人物关系的RF;
使用SVM分类器进行RF的二分类计算。
选取关联特征时,所选取的隐层是在实验中对比得到。我们比较网络AEFP中的隐层1,隐层2和输出层。在网络进行迭代的过程中,随着迭代次数的增加,在400次的迭代运算时,AEFP网络中提取出的关联特征在经过SVM分类器后,对父子关系的识别中识别率为73.8%。
综上所述,借助于本发明上述的技术方案,通过使用输入人脸图像并进行预处理、根据人脸图像确定人物的身份特征、构建自编码器并组成自编码神经网络、在自编码神经网络中对身份特征反复进行前向传播与反向传播、更新权重直到代价函数最小化并获得身份特征的关联特征、根据关联特征识别人脸图像之间的亲缘关系的技术手段,能够进行人物间的亲缘关系识别。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。所述计算机程序的实施例,可以达到与之对应的前述任意方法实施例相同或者相类似的效果。
此外,典型地,本公开所述的装置、设备等可为各种电子终端设备,例如手机、个人数字助理(PDA)、平板电脑(PAD)、智能电视等,也可以是大型终端设备,如服务器等,因此本公开的保护范围不应限定为某种特定类型的装置、设备。本公开所述的客户端可以是以电子硬件、计算机软件或两者的组合形式应用于上述任意一种电子终端设备中。
此外,根据本公开的方法还可以被实现为由CPU执行的计算机程序,该计算机程序可以存储在计算机可读存储介质中。在该计算机程序被CPU执行时,执行本公开的方法中限定的上述功能。
此外,上述方法步骤以及系统单元也可以利用控制器以及用于存储使得控制器实现上述步骤或单元功能的计算机程序的计算机可读存储介质实现。
此外,应该明白的是,本发明所述的计算机可读存储介质(例如,存储器)可以是易失性存储器或非易失性存储器,或者可以包括易失性存储器和非易失性存储器两者。作为例子而非限制性的,非易失性存储器可以包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦写可编程ROM(EEPROM)或快闪存储器。易失性存储器可以包括随机存取存储器(RAM),该RAM可以充当外部高速缓存存储器。作为例子而非限制性的,RAM可以以多种形式获得,比如同步RAM(DRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据速率SDRAM(DDR SDRAM)、增强SDRAM(ESDRAM)、同步链路DRAM(SLDRAM)以及直接RambusRAM(DRRAM)。所公开的方面的存储设备意在包括但不限于这些和其它合适类型的存储器。
本领域技术人员还将明白的是,结合这里的公开所描述的各种示例性逻辑块、模块、电路和算法步骤可以被实现为电子硬件、计算机软件或两者的组合。为了清楚地说明硬件和软件的这种可互换性,已经就各种示意性组件、方块、模块、电路和步骤的功能对其进行了一般性的描述。这种功能是被实现为软件还是被实现为硬件取决于具体应用以及施加给整个系统的设计约束。本领域技术人员可以针对每种具体应用以各种方式来实现所述的功能,但是这种实现决定不应被解释为导致脱离本公开的范围。
结合这里的公开所描述的各种示例性逻辑块、模块和电路可以利用被设计成用于执行这里所述功能的下列部件来实现或执行:通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或其它可编程逻辑器件、分立门或晶体管逻辑、分立的硬件组件或者这些部件的任何组合。通用处理器可以是微处理器,但是可替换地,处理器可以是任何传统处理器、控制器、微控制器或状态机。处理器也可以被实现为计算设备的组合,例如,DSP和微处理器的组合、多个微处理器、一个或多个微处理器结合DSP核、或任何其它这种配置。
结合这里的公开所描述的方法或算法的步骤可以直接包含在硬件中、由处理器执行的软件模块中或这两者的组合中。软件模块可以驻留在RAM存储器、快闪存储器、ROM存储器、EPROM存储器、EEPROM存储器、寄存器、硬盘、可移动盘、CD-ROM、或本领域已知的任何其它形式的存储介质中。示例性的存储介质被耦合到处理器,使得处理器能够从该存储介质中读取信息或向该存储介质写入信息。在一个替换方案中,所述存储介质可以与处理器集成在一起。处理器和存储介质可以驻留在ASIC中。ASIC可以驻留在用户终端中。在一个替换方案中,处理器和存储介质可以作为分立组件驻留在用户终端中。
在一个或多个示例性设计中,所述功能可以在硬件、软件、固件或其任意组合中实现。如果在软件中实现,则可以将所述功能作为一个或多个指令或代码存储在计算机可读介质上或通过计算机可读介质来传送。计算机可读介质包括计算机存储介质和通信介质,该通信介质包括有助于将计算机程序从一个位置传送到另一个位置的任何介质。存储介质可以是能够被通用或专用计算机访问的任何可用介质。作为例子而非限制性的,该计算机可读介质可以包括RAM、ROM、EEPROM、CD-ROM或其它光盘存储设备、磁盘存储设备或其它磁性存储设备,或者是可以用于携带或存储形式为指令或数据结构的所需程序代码并且能够被通用或专用计算机或者通用或专用处理器访问的任何其它介质。此外,任何连接都可以适当地称为计算机可读介质。例如,如果使用同轴线缆、光纤线缆、双绞线、数字用户线路(DSL)或诸如红外线、无线电和微波的无线技术来从网站、服务器或其它远程源发送软件,则上述同轴线缆、光纤线缆、双绞线、DSL或诸如红外先、无线电和微波的无线技术均包括在介质的定义。如这里所使用的,磁盘和光盘包括压缩盘(CD)、激光盘、光盘、数字多功能盘(DVD)、软盘、蓝光盘,其中磁盘通常磁性地再现数据,而光盘利用激光光学地再现数据。上述内容的组合也应当包括在计算机可读介质的范围内。
公开的示例性实施例,但是应当注公开的示例性实施例,但是应当注意,在不背离权利要求限定的本公开的范围的前提下,可以进行多种改变和修改。根据这里描述的公开实施例的方法权利要求的功能、步骤和/或动作不需以任何特定顺序执行。此外,尽管本公开的元素可以以个体形式描述或要求,但是也可以设想多个,除非明确限制为单数。
应当理解的是,在本发明中使用的,除非上下文清楚地支持例外情况,单数形式“一个”(“a”、“an”、“the”)旨在也包括复数形式。还应当理解的是,在本发明中使用的“和/或”是指包括一个或者一个以上相关联地列出的项目的任意和所有可能组合。
上述本公开实施例序号仅仅为了描述,不代表实施例的优劣。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
- 还没有人留言评论。精彩留言会获得点赞!