基于特征的工厂制造流程差别检测方法与流程
本发明属于业务流程管理领域,涉及一种流程间的差别检测方法,特别是一种基于特征的工厂制造流程差别检测方法。
背景技术:
业务流程管理技术涉及流程建模、流程间差别检测、流程间相似度计算、流程重建等,能有效地提高公司的管理效率。由此,越来越多的流程模型被创建出来了。例如,服装制造厂拥有载床生产流程、次品服装入库流程、客供品管理流程、记账后发现采购面料质量问题处理流程、样衣打样面辅料领用流程、生产退辅料处理流程、生产技术准备业务流程、生产计划流程、样衣成本核算流程、设备科业务流程等。这些流程模型是工厂的重要资产,有效地管理它们能给工厂带来很大的效益。
现有流程差别检测工作存在以下几点不足:(1)将流程模型用流程结构树(pst,processstructuretree)来表示。pst采用思想是将流程分解为单入口单出口(sese,single-entry-single-exit)分片,把这些分片按照层次嵌套关系组装一棵树,树中的每个叶子节点代表的是对应流程模型中的边。由于流程中的节点操作是最基本的操作,也是必不可少的,每次我们在进行节点操作时都要从pst中的边解析出节点,这样会浪费时间。另外,节点操作不能很直观地在pst上体现出来,如哪些节点被删除或插入。(2)用自上而下的策略来寻找两个流程对应pst的最大共同子树。若两个pst的根节点不相同,则认为这两个模型是完全不一样的。并且只找到最大共同子树部分,其他相似的部分被忽略了,这在一定程度上会带来额外的差别检测开销,如生成额外的差别操作。
技术实现要素:
为了克服现有技术中采用不合理的树结构来表示流程模型,无法找全两个流程模型间的差别等缺点,本发明提出了一种高效的、不遗漏差别的、不带来额外差别开销的基于特征的工厂制造流程间差别检测算法。
基于特征的工厂制造流程差别检测方法,包括以下步骤:
(1)输入两个待检测差别的工厂制造流程模型;
(2)分别将两个工厂制造流程模型转化为其对应的基于任务节点的流程结构树(taskbasedprocessstructuretree,tpst);
(3)对两个tpst分别进行分片,将每个分片用一个特征向量来表示并计算两个tpst中所有可能匹配的分片对的相似度,得到初始分片匹配表f={(f1,f1’,sim1),(f2,f2’,sim2),…,(fi,fi’,simi)},其中相同类型的分片才有可能匹配;
(4)匹配分片、节点,并将匹配结果加入匹配分片集合m和匹配节点集合n;
(5)判断初始分片匹配表f是否为空,若不为空,则执行步骤(4);否则,执行步骤(6);
(6)生成两个tpst之间的编辑序列;
进一步,步骤(3)具体包括:
(3.1)将两个tpst分别进行分片,其中每个分片用一个由多个特征组成的特征向量来表示;
(3.2)给定来自两个不同tpst的分片,计算它们对应特征向量中最后一个特征之间的相似度;
(3.3)重写两个分片对应的特征向量:将第一个分片对应的特征向量的最后一个特征值替换为1,将第二个分片对应的特征向量的最后一个特征值替换为(3.2)中得到的相似度;
(3.4)计算两个分片之间的相似度,即它们对应的特征向量之间的相似度,将这两个分片及对应的相似度写入初始分片匹配表f;
(3.5)判断两个tpst中是否还有可能匹配但没有计算相似度的分片对,若还有,则跳至步骤(3.2),否则,执行步骤(4);
进一步,步骤(3.1)中,分片对应的特征向量为{type,sequencerate,looprate,xorrate,andrate,nodesequence}。每一个特征描述了分片的一个重要的特点,其中type描述的是分片的类型:无序用0来表示,有序表示成1;sequencerate,looprate,xorrate,andrate分别表示顺序、循环、选择、并行四种类型的路由节点在该分片的子节点中的比率;nodesequence是一个字符串,依次记录了根节点的类型(sequence、loop、xor、and)和从左到右的子节点的标签;
进一步,步骤(3.2)中,两个特征向量中最后一个特征,即两个nodesequence:n1和n2之间的相似度用以下公式来计算:
在公式(1)中,mapnpdes指的是两个nodesequence中匹配的节点,|n1|和|n2|则是两个nodesequence各自的长度。如果n1和n2所对应的分片是无序的,则mapnpdes是n1和n2的交集;否则,n1和n2的最长共同子序列是mapnpdes。
进一步,步骤(3.3)的做法是为了体现两个特征离相同还有多少差距;
进一步,步骤(3.4)中,两个特征向量f1,f2的相似度用以下的公式来计算:
公式(2)用于计算两个特征向量之间的距离,基于距离值的公式(3)则计算两个特征向量之间的相似度。在公式(2)中,featurei表示的是特征向量中的第i个特征值,featurei1、featurei2分别指的是第一个、第二个流程模型中对应特征向量第i个特征值;
进一步,步骤(4)具体包括:
(4.1)在初始分片匹配表f中选出当前使得增加两个tpst结构相似度最大的分片对(fa,fb);
(4.2)判断匹配分片fa和fb得到整体结构相似度是否比上一轮的整体结构相似度大,若是,则执行步骤(4.3);否则,则执行步骤(6);
(4.3)在分片匹配集合m中加入(fa,fb)并在f中删除包含已匹配分片的分片对,找出匹配分片对(fa,fb)中的匹配节点并加入匹配节点集合n;
进一步,步骤(6)中的编辑序列是由一系列编辑操作组成的,包括删除分片、插入分片、移动分片、删除节点、插入节点,具体包括:
(6.1)两个tpst中不匹配的分片为删除和插入分片;
(6.2)两个匹配分片的父节点之间没有匹配的话,则该分片对为移动分片;
(6.3)匹配分片对中的非匹配节点为删除和插入节点。
本发明的技术构思是:在检测两个工厂制造流程模型间的差别之前,先将流程模型转换为其对应的树结构,能降低计算复杂度;在检测两个工厂制造流程模型间的差别时,采用分治策略对流程模型对应的树结构进行分片,并将每个分片用一个特征向量来表示,使得算法的设计更为灵活,提高检测的效率。
本发明的优点是:采用合理的树结构来表示流程模型,用特征向量来表示树分片的方式更加灵活,用分治的策略来进行差别检测大大地提高了效率,解决了计算复杂度高的问题。
附图说明
图1为本发明的总的流程图
图2为两个工厂辅料加工流程模型图实例
图3为图2两个流程模型对应的tpst
图4为图3两个tpst用特征向量表示的结果图
图5为图4的分片匹配结果图
具体实施方式
实施例一
参考附图1
基于特征的工厂制造流程差别检测方法,包括以下几个步骤:
(1)输入两个待检测差别的工厂制造流程模型;
(2)分别将两个工厂制造流程模型转化为其对应的基于任务节点的流程结构树(taskbasedprocessstructuretree,tpst);
(3)对两个tpst分别进行分片,并计算两个tpst中所有可能匹配的分片对的相似度,得到初始分片匹配表f={(f1,f1’,sim1),(f2,f2’,sim2),…,(fi,fi’,simi)},其中相同类型的分片才有可能匹配,具体包括:
(3.1)将两个tpst分别进行分片,其中每个分片用一个由多个特征组成的特征向量来表示;
(3.2)给定来自两个不同tpst的分片,计算它们对应特征向量中最后一个特征之间的相似度;
(3.3)重写两个分片对应的特征向量:将第一个分片对应的特征向量的最后一个特征值替换为1,将第二个分片对应的特征向量的最后一个特征值替换为(3.2)中得到的相似度;
(3.4)计算两个分片之间的相似度,即它们对应的特征向量之间的相似度,将这两个分片及对应的相似度写入初始分片匹配表f;
(3.5)判断两个tpst中是否还有可能匹配但没有计算相似度的分片对,若还有,则跳至步骤(3.2),否则,执行步骤(4);
(4)匹配分片、节点,具体包括:
(4.1)在初始分片匹配表f中选出当前使得增加两个tpst结构相似度最大的分片对(fa,fb);
(4.2)判断匹配分片fa和fb得到整体结构相似度是否比上一轮的整体结构相似度大,若是,则执行步骤(4.3);否则,则执行步骤(6);
(4.3)在分片匹配集合m中加入(fa,fb)并在f中删除包含已匹配分片的分片对,找出匹配分片对(fa,fb)中的匹配节点并加入匹配节点集合n;
(5)判断初始分片匹配表f是否为空,若不是,则执行步骤(4.1);否则,执行步骤(6);
(6)生成两个tpst之间的编辑序列,具体包括:
(6.1)两个tpst中不匹配的分片为删除和插入分片;
(6.2)两个匹配分片的父节点之间没有匹配的话,则该分片对为移动分片;
(6.3)匹配分片对中的非匹配节点为删除和插入节点;
实施例二
参考附图2,3,4,5
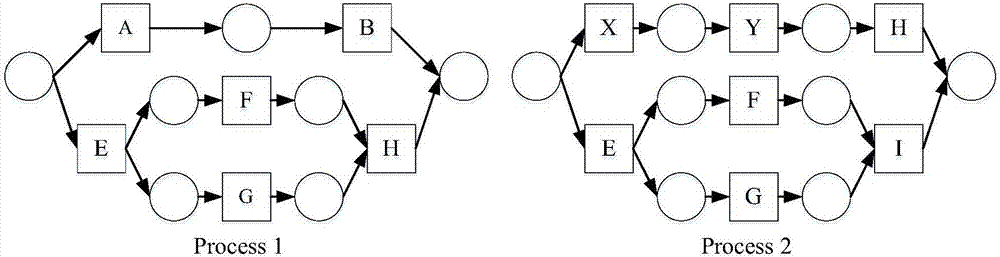
图2表示两个工厂辅料加工流程模型图实例:process1、process2。由于页面的限制,使用字母来代表任务节点的意义:a表示“成品验收”,b表示“包装”,e表示“配料加工”,f表示“剪裁”,g表示“表面处理”,h表示“分装”,i表示“配送至包装部门”,x表示“成品检验”,y表示“上色”。
为了得到process1和process2的差别,我们需要进行以下几个步骤:
(1)输入两个待检测差别的辅料加工流程模型:process1和process2,这两个流程模型是用petri网建模的,如图2所示;
(2)分别将process1和process2转化为其对应的基于任务节点的流程结构树(tpst):tpst1、tpst2,如图3所示,每一个路由节点除了本身的类型(sequnece、xor、and、loop)之外还有自己的id,如tpst1中xor节点的id为b0;
(3)对两个tpst1、tpst2分别进行分片,并计算两个tpst中所有可能匹配的分片对的相似度,得到初始分片匹配表f={(f1,f1’,sim1),(f2,f2’,sim2),…,(fi,fi’,simi)},其中相同类型的分片才有可能匹配,该步骤具体包括:
(3.1)将tpst1、tpst2分别进行分片,其中每个分片用一个由多个特征组成的特征向量fv={type,sequencerate,looprate,xorrate,andrate,nodesequence}来表示:如图3所示,tpst1分成f1-f4四个分片,其中f1和f4是无序分片,f2和f3是有序分片;tpst2分成g1-g4四个分片,其中g1和g4是无序分片,g2和g3是有序分片;每个分片用其对应的特征向量表示,如图4所示,每一个分片用一个圆形的节点表示,其对应的特征向量与之用一条线进行连接,如f1的特征向量为[0,1,0,0,0,“xor,sequence,sequence”];
(3.2)给定一个tpst1、tpst2的分片对,计算它们对应特征向量中最后一个特征之间的相似度:以f3与g3为例,f3对应特征向量中最后一个特征为“sequence,e,and,h,”g3对应特征向量中最后一个特征为“sequence,e,and,i,则f3与g3对应特征向量中最后一个特征向量之间的相似度为0.8;
(3.3)重写这两个分片对应的特征向量:将tpst1的最后一个特征值替换为1,tpst2替换为(3.2)中得到的相似度,以f3与g3为例,f3的特征向量为[1,0,0,0,1/3,1],g3的特征向量为[1,0,0,0,1/3,0.75];
(3.4)计算这两个分片之间的相似度,即它们对应的特征向量之间的相似度,将这两个分片及对应的相似度写入初始分片匹配表f:以f3与g3为例,它们的相似度为0.8,f={(f3,g3,0.8)};
(3.5)计算所有可能匹配的分片对及其相似度,得到初始分片匹配表,如图5所示,其中“/”表示对应的两个分片类型不相同,不能进行匹配;
(4)匹配分片、节点:如图5所示,首先f1与g1匹配起来能使得整体结构相似度增加最多,则选择匹配f1、g1并将它们加入分片匹配集合m={(f1,g1)},随后将初始匹配表中f1所在列和g1所在行都删除。在这对匹配分片对(f1,g1)中,匹配的节点为xor、sequence、sequence,由此匹配节点集合n为{b0-b2,p0-p2,p1-p3},其中“-”表示匹配关系;接着,f4和g4匹配可以使得第二轮的整体结构相似度增加最多,将它们加入分片匹配集合m={(f1,g1),(f4,g4)},随后将初始匹配表中f4所在列和g4所在行都删除,找到f4和g4的匹配节点并加入n={b0-b2,p0-p2,p1-p3,b1-b3,f-f,g-g};最后,将f3和g3加入m,使得m={(f1,g1),(f4,g4),(f3,g3)},n={b0-b2,p0-p2,p1-p3,b1-b3,f-f,g-g,e-e},在n中不会出现重复的匹配节点对;
(6)生成两个tpst之间的编辑序列,具体包括:
(6.1)tpst1中不匹配的分片为删除分片,tpst2中不匹配的分片为插入分片:f2为删除分片,g2为插入分片;
(6.2)两个匹配分片的父节点之间没有匹配的话,则该分片对为移动分片:此例中,匹配的分片对的父节点都是匹配的,所以都不需要进行移动;
(6.3)匹配分片对中的非匹配节点为删除和插入节点:f3分片中的h节点为删除节点,g3分片中的i节点为插入节点。
由此,tpst1、tpst2之间的差别为:删除分片f2,插入分片g2,删除节点h,插入节点i。
- 还没有人留言评论。精彩留言会获得点赞!