一种基于Apriori算法的学生就业数据分析方法与流程
本发明涉及高校学生就业数据分析领域,尤其涉及一种基于apriori算法的学生就业数据分析方法。
背景技术:
计算机技术与信息技术的快速发展,对人类社会进步与发展产生了巨大影响。它使人类社会由工业化进入到信息化时代,同时随着现代人生活节奏的加快及技术的进步,人们获取信息数据也更容易,进而使数据的存储量急剧增加。然而,面对大量的杂乱数据,人们更加关注的并非数据本身,而是隐藏在数据背后的一些重要信息。面对这一挑战,数据挖掘应运而生。数据挖掘有许多研究方向,关联规则挖掘就是其中之一,它反映了大量数据之间存在的相关联系。
本发明是在针对典型的关联规则挖掘算法apriori算法基础上,并将其关联规则挖掘的技术应用到学生就业数据的分析之中。通过对学生的相关成绩和就业数据的分析及研究,得到相关专业的学生就业与专业课程之间、学生综合测评及技能鉴定等之间存在的关系,以此为学校的学生就业提供参考依据,为学校的专业课程设置提供参考意见。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种基于apriori算法的学生就业数据分析方法。
本发明技术方案一种基于apriori算法的学生就业数据分析方法,其特征在于,包括以下步骤:
1)、为各个高校相关专业学生专业课成绩、学生综合测评成绩、技能鉴定及就业数据提供接口,实现将高校学生就业资源整合到高校学生就业资源联合检索平台上。
2)、将步骤101整合的事务数据库资源采用apriori算法来生成子数据库,即通过挖掘数据之间的关联规则生成分级子数据库,具体步骤为:
a、预先设定最小支持数mincount,扫描事务数据库db并计数得到c1,找出满足最小支持计数的1-频繁项集,记为l1;
b、重新组合l1中的项集产生候选集c2,再次扫描事务数据库,找出满足最小支持计数的2-频繁项集l2;
3)、根据步骤102中得到的频繁项集l2,由apriori_gen(l2)重新组合l2中的项集产生候选集c3,删除候选集c3中不属于l2的候选项集;如此循环下去,直到不能找到新的频繁k-项集,即扫描事务数据库,发现li为空集,则算法结束,最后得到的频集作为主数据库,然后利用所得到的分级子数据库及主数据库进行联合分析。得到相关专业的学生就业与专业课程之间、学生综合测评及技能鉴定等之间存在的关系,以此为学校的学生就业提供参考依据,为学校的专业课程设置提供参考意见。
本发明技术有益效果:
本发明提出一种基于apriori算法的学生就业数据分析方法。通过对各个高校相关专业学生就业资源整合,利用apriori算法,通过对学生的相关的成绩和就业数据的分析及研究,得到相关专业的学生就业与专业课程之间、学生综合测评及技能鉴定等之间存在的关系,以此为学校的学生就业提供参考依据,为学校的专业课程设置提供参考意见。
附图说明
图1为本发明的apriori算法流程图,
图2为本发明的apriori算法生成分级子数据库示意图,
图3为本发明的apriori算法生成主数据库示意图。
具体实施方式
为便于本领域技术人员理解本发明技术方案,现结合说明书附图对本发明技术方案做进一步的说明。
本发明包括两个部分,第一部分是apriori算法生成分级子数据库,即通过挖掘数据之间的关联规则生成分级子数据库。第二部分是apriori算法生成主数据库,即在分级子数据库的基础上再利用apriori算法进行关联规则的挖掘,获得最终的主数据库。
详细方案描述
1、apriori算法生成分级子数据库
apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
apriori算法使用层次顺序搜索的循环方法产生频繁项集,即用频繁k-项集探索产生(k+1)-项集。找出长度为1的频繁项集,记为l1,用于产生频繁2-项集l2的集合,而l2用于产生频繁3-项集l3的,如此循环下去,直到不能找到新的频繁k-项集。
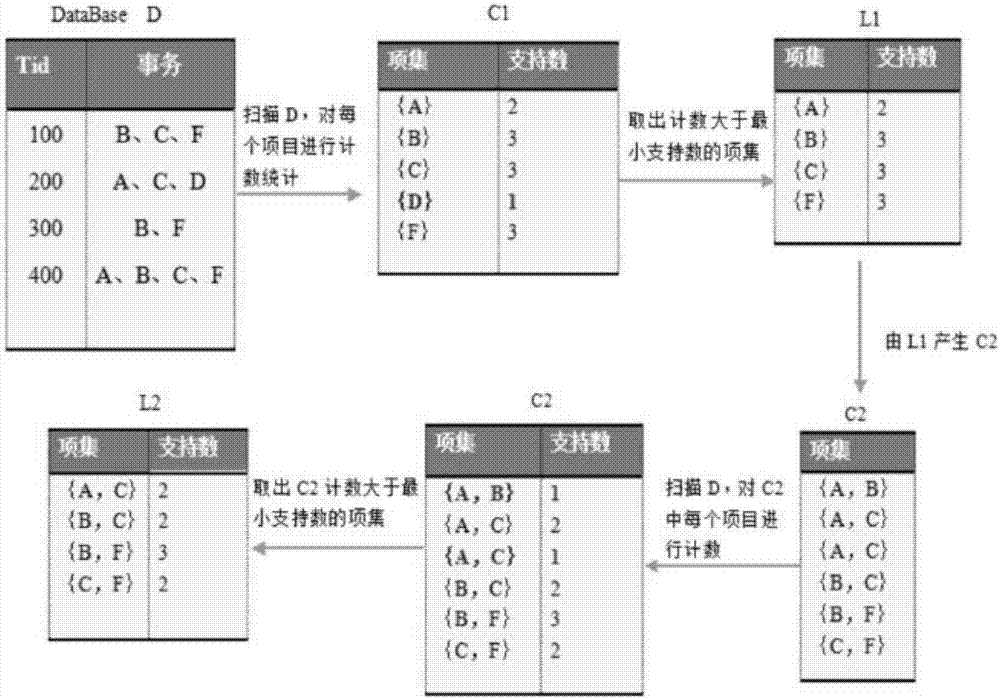
假设图书电子资源事务数据库db中包含4个事务,即|db|=4,最小支持数mincount=2,即最小支持度minsup=2/4=50%。挖掘频繁项目集的具体过程如下所述:
(1)数据过滤
首先对事务数据库db进行扫描并且计数,得到c1,取出计数大于最小支持数的项集(其中项集{d}的支持数为1小于最小支持数2,删除{d}项集),产生l1={{a},{b},{c},{f}}。第一次数据库扫描产生的关联规则会产生冗余数据,继续对数据库进行第二次扫描。
(2)分级子数据库的生成
由apriori_gen(l1)(产生相应的候选项集)生成c2,扫描数据库db,对c2中的每个项集进行计数(其中{a,b},{a,c}支持数为1,小于最小支持数2,删除{a,b},{a,c}两个项集),计算c2中每个候选集得到l2,所得到l2的中的频繁项集{a,c},{b,c},{b,f},{c,f}作为事物数据库的分级子数据库,生成过程如图2所示。
2、apriori算法生成主数据库
根据生成的分级子数据库l2,由apriori_gen(l2)生成c3,扫描事务数据库d,对c3中的每个项目进行计数,取出c3中大于最小支持数的项集(其中{a,b,c},{a,b,f},{a,c,f}三个项集的支持数为1,小于最小支持数2,删除该三项,留下计数大于最小支持数的项集),最终得到l3,其中{b,c,f}是最后得到的频集作为主数据库,生成过程如图3所示。
本发明方案在上面结合附图对发明进行了示例性描述,显然发明具体实现并不受上述方式的限制,只要采用了本发明的方法构思和技术方案进行的各种非实质性改进,或未经改进将发明的构思和技术方案直接应用于其它场合的,均在本发明的保护范围之内。
技术特征:
技术总结
本发明公开了一种基于Apriori算法的学生就业数据分析方法,主要为各个高校相关专业学生专业课成绩、学生综合测评成绩、技能鉴定及就业数据的数据库提供接口,实现将高校学生就业资源整合到高校学生就业资源联合检索平台上。利用Apriori算法,通过对学生的相关成绩和就业数据的分析及研究,得到相关专业的学生就业与专业课程之间、学生综合测评及技能鉴定等之间存在的关系,以此为学校的学生就业提供参考依据,为学校的专业课程设置提供参考意见。
技术研发人员:宋丽萍;韦建国
受保护的技术使用者:阜阳职业技术学院
技术研发日:2017.03.23
技术公布日:2017.07.14
- 还没有人留言评论。精彩留言会获得点赞!