一种基于离散多视图哈希的协同过滤推荐方法与流程
本发明涉及个性化推荐技术,尤其涉及一种基于离散多视图哈希的协同过滤推荐方法。
背景技术:
互联网产业的高速发展,带来了内容的爆炸性增长。为了帮助用户的有效获取信息,个性化推荐系统正发挥着越来越重要的作用。协同过滤技术是在推荐系统中广受关注的一类技术。与传统的基于内容直接过滤分析进行推荐不同,协同过滤利用大量的用户信息,选取与目标用户相似的用户,或是与目标物品相似的物品,来最终推荐当前目标用户的可能感兴趣的物品。
但是在现实的应用环境中,我们往往能够获取到除了评分之外的大量其他信息,包括用户与用户之间的社交关系,物品与物品之间的类别关系等。传统的协同过滤推荐技术往往只能利用单一视图下的用户信息,且需要通过高维向量之间的运算才能够计算出对用户偏好的预测评分,这严重影响了计算和存储效率,其常规解法也造成了大量的信息丢失。
技术实现要素:
本发明的目的是针对现有技术的不足,提供一种基于离散多视图哈希的协同过滤推荐方法。
本发明的目的是通过以下技术方案来实现的:
一种基于离散多视图哈希的协同过滤推荐方法,包括以下步骤:
1)根据不同视图下的数据,构建数据的多视图锚点图表示;
2)结合协同过滤和锚点图,得到学习模型;
3)对得到的学习模型进行求解,得到用户与物品对应的二进制哈希编码;
4)利用得到的哈希编码进行最邻近搜索,计算特定用户对候选物品的偏好程度,返回偏好程度最大的若干个物品作为推荐结果。
上述各步骤可采用如下具体实现方式:
步骤1)包括以下子步骤:
1.1)对于训练数据在第i个视图下的行为数据矩阵
1.2)将不同视图下的训练数据进行水平连接得到矩阵
1.3)对于每个训练数据,搜索其在各视图下最近邻的若干个锚点,组成集合
1.4)对于每个数据点,利用nesterov梯度方法和投影梯度方法求解优化问题
1.5)将数据点到非最近邻锚点的转移概率设定为0,根据得到的各数据点到最近邻锚点的转移概率,得到所有数据点到所有锚点的转移概率矩阵
步骤2)包括以下子步骤:
2.1)计算得到转移概率矩阵p的列和向量
2.2)构造对角矩阵
2.3)计算相似度矩阵s=pλ-1pt;
2.4)计算矩阵s的度矩阵
2.5)得到tr(ulut)s.t.u∈{0,1}k×n,这就是通过锚点图得到的学习函数,其中tr(.)表示迹函数;
2.6)记评分数据w={wij},i=1,2,...,n;j=1,2,...,m,n为用户数量,m为物品数量,wij代表用户i对物品j的评分;
2.7)结合得到最终学习模型
步骤3)包括以下子步骤:
3.1)记x∈[-1,1]r×n,y∈[-1,1]r×m分别为用户和物品对应的连续矩阵,优化函数表示为
3.2)计算
3.3)计算
3.4)计算矩阵
3.5)对矩阵
3.6)计算矩阵
3.7)按
3.8)计算矩阵
3.9)对矩阵
3.10)计算矩阵
3.11)按
3.12)重复步骤3.2)、步骤3.3)、步骤3.7)和步骤3.11),直至二进制编码矩阵b和d收敛。
步骤4)包括以下子步骤:
4.1)根据步骤3)得到的用户和物品的二进制哈希编码矩阵,计算特定用户编码到所有物品编码之间的汉明距离,选取汉明距离最小的若干个物品;
4.2)将特定用户集合对应的偏好物品集合进行归并,忽略目标用户曾经选择过的物品,得到目标用户的偏好物品候选集合i;
4.3)对于偏好物品候选集合中的每一个物品,计算目标用户对物品的偏好评分预测值并排序,将排名前k的候选物品作为最终推荐结果。
本发明的有益效果是:本发明根据个性化推荐中的多视图、大规模数据场景,将多视图哈希学习算法与基于协同过滤的推荐技术相结合,融合了不同来源、不同类型的多视图数据,并一直保持求解过程中编码的离散特性,从而提高了推荐结果的质量;此外,通过将用户和物品表示为对应的二进制哈希编码,实现了快速的相似搜索,极大提高了推荐结果计算的效率。
附图说明
图1是本发明基于离散多视图哈希的协同过滤推荐方法流程图。
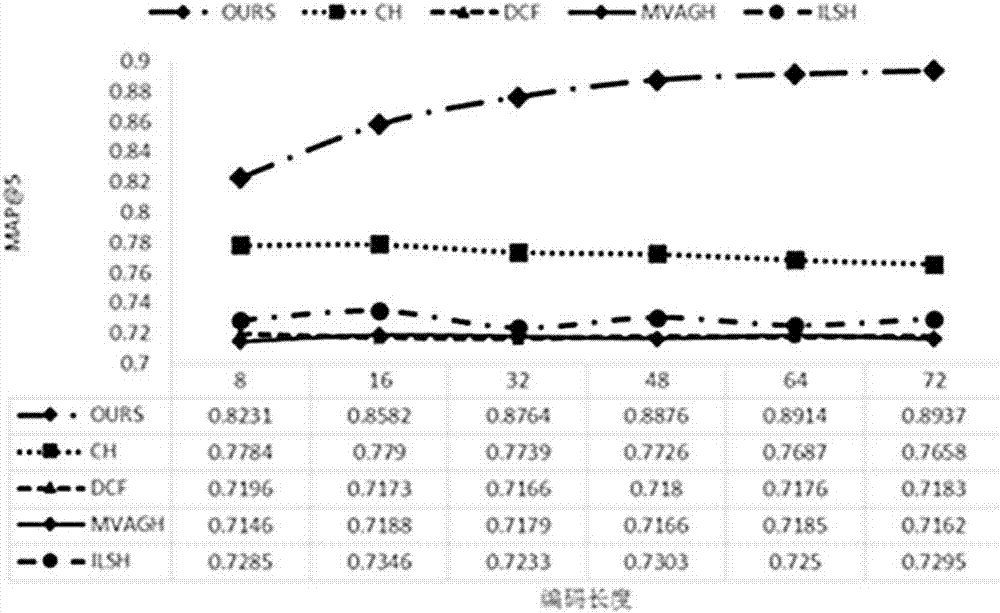
图2是针对数据集movielens-1m时,本发明的与其他哈希推荐算法的结果对比图(map);
图3是针对数据集movielens-1m时,本发明的与其他哈希推荐算法的结果对比图(mndcg);
图4是针对数据集flixster时,本发明的与其他哈希推荐算法的结果对比图(map);
图5是针对数据集flixster时,本发明的与其他哈希推荐算法的结果对比图(mndcg);
具体实施方式
下面结合附图对本发明作进一步详细说明。
如图1所示,本发明一种基于离散多视图哈希的协同过滤推荐方法,包括以下步骤:
1)根据不同视图下的数据,构建数据的多视图锚点图表示;具体包括以下子步骤:
1.1)对于训练数据在第i个视图下的行为数据矩阵
1.2)将不同视图下的训练数据进行水平连接得到矩阵
1.3)对于每个训练数据,搜索其在各视图下最近邻的若干个锚点,组成集合
1.4)对于每个数据点,利用nesterov梯度方法和投影梯度方法求解优化问题
1.5)将数据点到非最近邻锚点的转移概率设定为0,根据得到的各数据点到最近邻锚点的转移概率,得到所有数据点到所有锚点的转移概率矩阵
2)结合协同过滤和锚点图,得到学习模型;具体包括以下子步骤:
2.1)计算得到转移概率矩阵p的列和向量
2.2)构造对角矩阵
2.3)计算相似度矩阵s=pλ-1pt;
2.4)计算矩阵s的度矩阵
2.5)得到tr(ulut)s.t.u∈{0,1}k×n,这就是通过锚点图得到的学习函数,其中tr(.)表示迹函数;
2.6)记评分数据w={wij},i=1,2,...,n;j=1,2,...,m,n为用户数量,m为物品数量,wij代表用户i对物品j的评分;
2.7)结合得到最终学习模型
3)对得到的学习模型进行求解,得到用户与物品对应的二进制哈希编码;具体包括以下子步骤:
3.1)记x∈[-1,1]r×n,y∈[-1,1]r×m分别为用户和物品对应的连续矩阵,优化函数表示为
3.2)计算
3.3)计算
3.4)计算矩阵
3.5)对矩阵
3.6)计算矩阵
3.7)按
3.8)计算矩阵
3.9)对矩阵
3.10)计算矩阵
3.11)按
3.12)重复步骤3.2)、步骤3.3)、步骤3.7)和步骤3.11),直至二进制编码矩阵b和d收敛。
4)利用得到的哈希编码进行最邻近搜索,计算特定用户对候选物品的偏好程度,返回偏好程度最大的若干个物品作为推荐结果。具体包括以下子步骤:
4.1)根据步骤3)得到的用户和物品的二进制哈希编码矩阵,计算特定用户编码到所有物品编码之间的汉明距离,选取汉明距离最小的n个物品;
4.2)将特定用户集合对应的偏好物品集合进行归并,忽略目标用户曾经选择过的物品,得到目标用户的偏好物品候选集合i;
4.3)对于偏好物品候选集合中的每一个物品,计算目标用户对物品的偏好评分预测值并排序,将排名前k的候选物品作为最终推荐结果,在实际应用中,k一般可取5至20左右。
实施例
将上述方法应用于现实数据集movielens-1m和flixster的个性化推荐系统中测试效果,具体步骤不再赘述。同时设置对比指标平均准确率均值(meanaverageprecision,map)和归一化折损累积增益均值(meannormalizeddiscountedcumulativegain,mndcg),对比方法分别采用协同哈希(collaborativehashing,ch),局部敏感哈希(localitysensitivehashing,lsh),多视图锚点图哈希(multi-viewanchorgraphhashing,mvagh)和离散协同过滤(discretecollaborativehashing,dcf)。其结果如图2~5所示,表明在两个数据集的两个指标上,本方法都取得了更好的效果。
- 还没有人留言评论。精彩留言会获得点赞!