一种面向GPDSP的反卷积矩阵的向量化实现方法与流程
本发明主要涉及到向量处理器及机器学习领域,特指一种面向gpdsp的反卷积矩阵的向量化实现方法。
背景技术:
深度学习(deeplearning,dl)是当前机器学习领域的一个重要研究方向。dl通过构造多层感知器(multilayerperception,mlp)来模拟人脑的分层感知方式,mlp能够通过组合低层次特征来表达属性类别或高层的抽象特征,从而成为当前目标识别领域的研究重点。
经典的dl模型主要包括自动编码机模型(autoencode,ae)、深度信念网络模型(deepbeliefnetworks,dbns)及卷积神经网络模型(convolutionalneuralnetworks,cnn)。一般来说,上述模型主要通过编码器从输入图像中提取特征,从底层逐层向上将图像转化到高层特征空间,相应的,使用解码器将高层特征空间的特征通过网络自顶向下重构输入图像。其中,深度学习模型主要分为无监督学习模型和有监督学习模型,自动编码机和深度信念网络就是无监督学习模型的代表,它们可以自底向上地逐层学习丰富的图像特征并为高层次应用,如图像识别、语音识别等。而cnn模型则是有监督的学习模型,通过构建卷积层及池化层来构建多层的卷积神经网络,通过bp(backpropogation)算法反向调整滤波模板,经过多次的正向计算和反向调优来构建具有高识别率的神经网络。
由于cnn模型涉及到大量的矩阵操作,如,矩阵与矩阵乘法、矩阵与向量乘法、向量与向量乘法、矩阵与矩阵卷积、矩阵扩充、矩阵反卷积以及各种超越函数的计算,使得cnn模型需要占用大量的计算资源。通过对cnn模型的深入分析发现,该模型中涉及大量的数据并行性,目前运行cnn模型的硬件平台主要有cpu、gpu、fpga及专用的神经网络处理器,如中科院计算所的寒武纪系列。
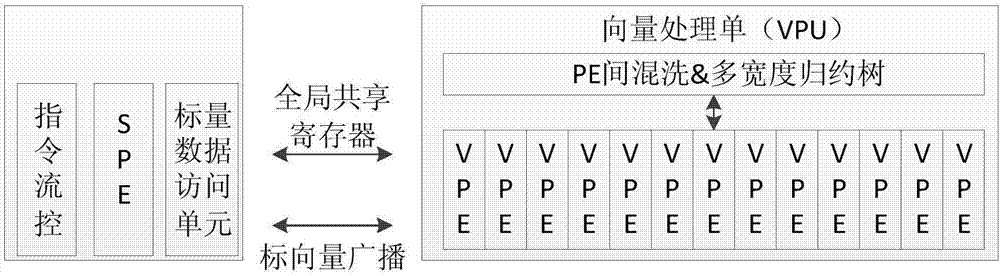
通用计算数字信号处理器(general-purposedigitalsignalprocessor,gpdsp)一般包括cpu核和dsp核,cpu核主要负责包括文件控制、存储管理、进程调度、中断管理任务在内的通用事务管理及对通用操作系统的支持;dsp核主要包含若干具有强大计算能力的浮点或定点向量处理阵列,用于支持高密度的计算任务,向量处理器一般由n个处理单元(pe)组成,每个pe包含若干个功能单元,一般包括alu部件、加法部件、移位部件等,这些部件可以读写一组局部寄存器,每个处理单元包含一组局部寄存器,所有处理单元同一编号的局部寄存器在逻辑上又组成了一个向量寄存器。向量处理器采用simd的方式,n个处理单元在同一条向量指令的控制下同时对各自的局部寄存器进行相同的操作,以开发应用程序的数据级并行性。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种原理简单、操作方便、能充分利用向量处理器完成特殊数据计算、缩短整个算法运行时间、提高算法执行效率的面向gpdsp的反卷积矩阵的向量化实现方法,用以满足计算密集型应用的需求。
为解决上述技术问题,本发明采用以下技术方案:
一种面向gpdsp的反卷积矩阵的向量化实现方法,其特征在于,由gpdsp的cpu核为卷积神经网络中前向传播阶段产生的权值矩阵及反向计算阶段的残差矩阵分配相应的标量存储空间和向量存储空间,其步骤为,
s1:设残差矩阵a(m,m)、权值矩阵b(n,n)及反卷积结果矩阵c(m+n-1,m+n-1),且m>n;
s2:通过控制循环次数,首先计算反卷积结果矩阵c前n-1行元素;
s3:固定循环次数,计算反卷积结果矩阵c第n行至第m行元素;
s4:通过控制循环次数,计算反卷积结果矩阵c倒数第n-1行至倒数第1行元素。
作为本发明的进一步改进:所述权值矩阵b置于标量存储体,反卷积矩阵a置于向量存储体,且权值矩阵b从后至前,倒序来取。
作为本发明的进一步改进:所述步骤s2的详细步骤为:
s2.1取权值矩阵b第n行的最后一个元素,bn-1,n-1,取残差矩阵a第一行元素,将bn-1,n-1广播至标量寄存器中的元素与矩阵a第一行元素对应相乘,累加上将bn-1,n-2向量化后与移位后的残差矩阵a的第一行元素一一对应相乘的结果;重复以上步骤n次,n位权值矩阵b列数,完成反卷积结果矩阵c第一行元素的计算;
s2.2顺移至残差矩阵a的第二行元素,计算过程如步骤2.1,循环n+n次完成反卷积结果矩阵c第二行元素的计算;
s2.3顺移至残差矩阵a的第n-1行元素,计算过程如步骤2.1,循环(n-1)*(n-1)次完成反卷积结果矩阵c第n-1行元素的计算。
作为本发明的进一步改进:所述步骤s3中,反卷积结果矩阵c的第n行至第m行的每一行元素的计算都在步骤s2.3的基础上顺移至残差矩阵a的第n行,计算过程如步骤2.1,循环n*n次完成反卷积结果矩阵c中间某一行行元素的计算。
作为本发明的进一步改进:所述步骤s4的详细步骤为:
s4.1倒数第n-1行元素由权值矩阵b的前n-1行元素参与计算,计算过程如步骤s2.3;
s3.3倒数第2行元素由权值矩阵b的前2行元素参与计算,计算过程如步骤s2.2;
s3.4倒数第1行元素由权值矩阵b的前1行元素参与计算,计算过程如步骤s2.1。
与现有技术相比,本发明的优点在于:
1、本发明的面向gpdsp的反卷积矩阵的向量化实现方法,将卷积神经网络反向计算中涉及到的残差矩阵a(m,m)和权值矩阵b(n,n)反卷积至输入空间,即,反卷积结果矩阵c(m+n-1,m+n-1),不仅避免了数据的搬移、矩阵的扩充,且能充分利用向量处理器中多个并行处理单元能够同时进行相同运算的特点来进行大量的同类型操作,使用特殊的vshufw指令,大大提高数据的复用率,进而大幅度提高反卷积矩阵的计算效率。
2、采用本发明的方法比传统的方法更加简单高效,目标向量处理器实现的硬件代价低,在实现相同功能的情况下,降低了功耗。另外,本发明的方法,实现简单、成本低廉、操作方便、可靠性好。
附图说明
图1是本发明方法的流程示意图。
图2是本发明面向的gpdsp的简化结构模型示意图。
图3是本发明中的反卷积计算流程示意图。
图4是本发明在具体应用实例中反卷积结果矩阵第1行元素计算示意图。
图5是本发明在具体应用实例中反卷积结果矩阵第2行元素计算示意图。
具体实施方式
以下将结合说明书附图和具体实施例对本发明做进一步详细说明。
假设c=a*b,即矩阵a和矩阵b的卷积是c,也就是说已知a和b求c的过程叫做卷积,那么如果已知c和a或者c和b求b或a的过程就叫做反卷积。如图2所示,为本发明所面向的gpdsp的简化结构模型示意图。
如图1和图3所示,本发明的面向gpdsp的反卷积矩阵的向量化实现方法,其步骤为:
s1:反卷积结果矩阵c前n-1行元素的计算;
s1.1由gpdsp的cpu核为卷积神经网络中前向传播阶段产生的权值矩阵及反向计算阶段的残差矩阵分配相应的标量存储空间和向量存储空间;
s1.2设残差矩阵a(m,m)、权值矩阵b(n,n)及反卷积结果矩阵c(m+n-1,m+n-1),且m>n;
s1.3取权值矩阵b第n行的最后一个元素,bn-1,n-1,取残差矩阵a第一行元素,将bn-1,n-1广播至标量寄存器中的元素与矩阵a第一行元素对应相乘,累加上将bn-1,n-2向量化后与移位后的残差矩阵a的第一行元素一一对应相乘的结果;重复以上步骤n次(权值矩阵b列数),完成反卷积结果矩阵c第一行元素的计算,计算过程如图4所示;
s1.4顺移至残差矩阵a的第二行元素,计算过程类似步骤1.3,循环n+n次完成反卷积结果矩阵c第二行元素的计算,计算过程如图5所示;
s1.5顺移至残差矩阵a的第n-1行元素,计算过程类似步骤1.3,循环(n-1)*(n-1)次完成反卷积结果矩阵c第n-1行元素的计算。
s2:反卷积矩阵c中间第n行至m行元素的计算;
由于第n行至m行的计算是由残差矩阵a所有行元素都参与运算,因此反卷积结果矩阵c的第n行至第m行的每一行元素的计算都要在步骤s1.5的基础上顺移至残差矩阵a的第n行,计算过程类似步骤s1.3,循环n*n次完成反卷积结果矩阵c中间某一行行元素的计算。
s3:反卷积结果矩阵c后n-1行元素的计算;
s3.1由于步骤s2是由权值矩阵b所有元素参与运算,而步骤s3中是由权值矩阵b的部分行元素参与运算,因此后n-1行元素的计算类似步骤s1,只是和步骤s1中的循环次数有所不同;
s3.2倒数第n-1行元素由权值矩阵b的前n-1行元素参与计算,计算过程类似步骤s1.5;
s3.3倒数第2行元素由权值矩阵b的前2行元素参与计算,计算过程类似步骤s1.4;
s3.4倒数第1行元素由权值矩阵b的前1行元素参与计算,计算过程类似步骤s1.3。
结合图3,本发明在一个具体应用实例中,详细流程为:
s100:设卷积神经网络反向传播计算中残差矩阵a的规模为8×8,权值矩阵b的规模为5×5,则反卷积结果矩阵c的规模为12×12,即(8+5-1),一般地,残差矩阵a放置在向量存储体,权值矩阵b放置在标量存储体。
s200:首先计算反卷积结果矩阵c的第1行元素,计算过程如下;
s2.1b4,4×a0,0…b4,4×a0,7b4,4×0b4,4×0b4,4×0b4,4×0;
s2.2b4,3×0b4,3×a0,0…b4,3×a0,7b4,3×0b4,3×0b4,3×0;
s2.3b4,2×0b4,2×0b4,2×a0,0…b4,2×a0,7b4,2×0b4,2×0;
s2.4b4,1×0b4,1×0b4,1×0b4,1×a0,0…b4,1×a0,7b4,1×0;
s2.5b4,0×0b4,0×0b4,0×0b4,0×0b4,0×a0,0…b4,0×a0,7;
s2.6将步骤2.1至步骤2.5每行的12个乘法结果对应相加,累加4次完成反卷积结果矩阵c第1行元素的计算,即2.7,计算过程如图4所示;
s2.7得出c矩阵第1行元素c0,0c0,1c0,2c0,3c0,4c0,5c0,6c0,7c0,8c0,9c0,10c0,11;
s300:计算反卷积结果矩阵c的第2行元素,由于本次计算涉及到权值矩阵b两行元素的计算,因此,计算过程比步骤s200多5次循环,计算过程如下;
s3.1b4,4×a1,0…b4,4×a1,7b4,4×0b4,4×0b4,4×0b4,4×0;
s3.2b4,3×0b4,3×a1,0…b4,3×a1,7b4,3×0b4,3×0b4,3×0;
s3.3b4,2×0b4,2×0b4,2×a1,0…b4,2×a1,7b4,2×0b4,2×0;
s3.4b4,1×0b4,1×0b4,1×0b4,1×a1,0…b4,1×a1,7b4,1×0;
s3.5b4,0×0b4,0×0b4,0×0b4,0×0b4,0×a1,0…b4,0×a1,7;
s3.6b3,4×a0,0…b3,4×a0,7b3,4×0b3,4×0b3,4×0b3,4×0;
s3.7b3,3×0b3,3×a0,0…b3,3×a0,7b3,3×0b3,3×0b3,3×0;
s3.8b3,2×0b3,2×0b3,2×a0,0…b3,2×a0,7b3,2×0b3,2×0;
s3.9b3,1×0b3,1×0b3,1×0b3,1×a0,0…b3,1×a0,7b3,1×0;
s3.10b3,0×0b3,0×0b3,0×0b3,0×0b3,0×a0,0…b3,0×a0,7;
s3.11将步骤s3.1至步骤s3.10每行的12个乘法结果对应相加,累加9次完成反卷积结果矩阵c第2行元素的计算,即3.12,计算过程如图5所示;
s3.12得出c矩阵第2行元素;
c1,0c1,1c1,2c1,3c1,4c1,5c1,6c1,7c1,8c1,9c1,10c1,11;
s400:计算反卷积结果矩阵c的第3行元素,由于本次计算涉及到权值矩阵b三行元素的计算,因此,计算过程比步骤s300多5次循环,计算过程类似步骤s200;
s4.1最终得出c矩阵第3行元素:
c2,0c2,1c2,2c2,3c2,4c2,5c2,6c2,7c2,8c2,9c2,10c2,11;
s500:计算反卷积结果矩阵c的第4行元素,由于本次计算涉及到权值矩阵b四行元素的计算,因此,计算过程比步骤s400多5次循环,计算过程似步骤s200;
s5.1得出c矩阵第4行元素:
c30c31c32c33c34c35c36c37c38c39c310c311;
s600:计算反卷积结果矩阵c的第五行元素,由于本次计算涉及到权值矩阵b五行元素的计算,因此,计算过程比步骤s500多5次循环,计算过程似步骤s200;
s6.1得出c矩阵第5行元素:
c4,0c4,1c4,2c4,3c4,4c4,5c4,6c4,7c4,8c4,9c4,10c4,11;
s700:计算反卷积结果矩阵c的第5—8行元素,由于中间行计算涉及到权值矩阵b五行元素的计算,因此,计算过程如步骤s600;最终计算出反卷积结果矩阵c的第5—8行元素;
s7.1得出c矩阵第5至8行元素:
s800:计算反卷积结果矩阵c的第9行元素,由于权值矩阵b只有前4行参与计算,因此该行计算过程类似步骤s500;
s8.1得出c矩阵第9行元素:
c8,0c8,1c8,2c8,3c8,4c8,5c8,6c8,7c8,8c8,9c8,10c8,11;
s900:计算反卷积结果矩阵c的第10行元素,由于权值矩阵b只有前3行参与计算,因此该行计算过程类似步骤s400;
s9.1得出c矩阵第10行元素:
c9,0c9,1c9,2c9,3c9,4c9,5c9,6c9,7c9,8c9,9c9,10c9,11;
s1000:计算反卷积结果矩阵c的第11行元素,由于权值矩阵b只有前2行参与计算,因此该行计算过程类似步骤s300;
s10.1得出c矩阵第11行元素:
c10,0c10,1c10,2c10,3c10,4c10,5c10,6c10,7c10,8c10,9c10,10c10,11;
s1100:计算反卷积结果矩阵c的第12行元素,由于权值矩阵b只有第1行参与计算,因此该行计算过程类似步骤s200;
s11.1得出c矩阵第12行元素:
c11,0c11,1c11,2c11,3c11,4c11,5c11,6c11,7c11,8c11,9c11,10c11,11。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!