一种基于深度学习的图像融合方法与流程
本发明涉及图像融合方法,具体为一种基于深度学习的图像融合方法。
背景技术:
图像融合是复杂探测系统的关键技术之一,其目的是将同一场景的多幅图像或序列探测图像合成一幅信息更完整、全面的图像,以便后续的图像分析、目标识别和跟踪。多尺度变换域融合是当前采用的主要方法,但往往需要依据先验知识选择合适的多尺度变换方法和融合规则,不利于工程化应用。
新近,深度学习在图像分类、目标跟踪等许多领域均已成功突破了固定状态模型的约束,在图像融合领域也有少些探索性的研究,如首先利用深度支撑值学习网络将遥感图像分解为高低频图像,再分别融合;将多尺度变换和低频自动编码相结合融合多聚焦图像,均获得了较好的融合结果。前者仅实现了支撑值滤波器自适应,对不适用于支持度变换的融合无法做到滤波器自适应,后者虽实现了融合规则自适应,但滤波器需要人工定义。总的来说,这些研究证实深度人工神经网络学习得到的参数更多、更全,可以以全应变做到自适应,降低方法对先验知识的依赖性,但未解决图像融合中各类多尺度变换均须依据先验知识选择滤波器类型、分解层数、方向数等问题。而在实际探测中,以上这些先验知识的获取往往极其困难。
为此,需要有一种新的方法来解决多尺度变换等方法融合图像时依赖先验知识难以工程化的问题。
技术实现要素:
本发明为了解决多尺度变换融合图像时须依据先验知识选择滤波器类型、分解层数、方向数等问题,提出了一种基于深度学习的图像融合方法。
本发明是采用如下的技术方案实现的:一种基于深度学习的图像融合方法,包括以下步骤:
构建深度堆叠卷积神经网络基本单元:基本单元由高频子网、低频子网和融合卷积层构成,高频子网、低频子网又分别由三层卷积层构成,其中,第一层卷积层对输入信息进行限制,第二层卷积层对信息进行组合,第三层卷积层再将这些信息合并为映射图;
先对基本单元进行训练,再将多个基本单元堆叠起来采用端对端的方式训练得到深度堆叠神经网络;
利用该堆叠神经网络分别分解输入图像,在最后一个基本单元的第三层卷积层分别得到各自的高频和低频特征映射图,利用局部方差取大得到融合后的高频特征映射图,利用区域匹配度得到融合后的低频特征映射图;
将高频特征映射图和低频特征映射图放回最后一个基本单元的融合卷积层,得到最终的融合图像。
上述的一种基于深度学习的图像融合方法,高频子网和低频子网第一层卷积层的卷积核分别初始化为高斯拉普拉斯滤波器和高斯滤波器,其余层卷积核用
上述的一种基于深度学习的图像融合方法,深度堆叠神经网络的训练集和测试集由各类型的图像等比例混合组成,所述图像包括可见光图像、红外图像和医学图像,mini-batch取值在22-32之间。mini-batch大小决定误差收敛的稳定性,其值越大越稳定,但占用的内存更多,故取值在22-32之间,学习率决定误差收敛的速度,其值越大收敛速度越快,但越不稳定,取值通常在0.001-0.01之间。
上述的一种基于深度学习的图像融合方法,基本单元第一层卷积层和第二层卷积层的卷积核个数相等且取值范围为4-16,基本单元堆叠个数取值范围为3-6。卷积核个数越多,习得的特征越多,但占用内存越大,取值通常在4-16之间。基本单元堆叠个数越多,网络对图像的分解就越精细,但个数太多却会使边缘等细节的重构能力变差,取值通常在3-6之间。
上述的一种基于深度学习的图像融合方法,卷积层的激活函数选
多尺度变换融合图像的一个优势在于可对同类信息(高频或低频)采用相同的合成规则从而可提高信息利用率,使融合结果更为精确,但其缺点是需要依赖先验知识选择合适的参数;卷积神经网络是一种常用的深度学习模型,通过系列卷积和下采样对图像进行特征提取与抽象,与图像通过卷积和下采样进行多尺度分解思想一致,不同之处在于神经网络学习得到的滤波器更多、更全,这样,当融合不同对象时可以从中自适应选择合适的滤波器;自动编码器也是一种深度学习模型,它能在一定误差内对信号进行编码解码与多尺度变换对图像进行分解重构的思想一致,但该模型不适合处理图像这类二维信号,因此本发明利用卷积神经网络的卷积层替换自动编码器的全连接层构建神经网络来模拟多尺度变换对图像分解重构,利用其可自适应的优势来克服多尺度变换的不足,但若对网络不做限定,它提取的并非图像的高低频特征,不利于针对性地制定融合规则,因此本发明用高斯拉普拉斯滤波器和高斯滤波器分别作为高频子网和低频子网首层网络的初始卷积核,以保证输入图像经过高频子网和低频子网后可得到高频特征映射图和低频特征映射图;由于浅层网络的学习能力较弱,因此本发明通过以该网络为基本单元堆叠形成深度堆叠卷积神经网络用以提高学习能力;使用端对端方式训练提高网络的精度、稳定性和收敛性;利用不同类型图像训练同一深度堆叠卷积神经网络,既保证网络的泛化能力,又方便得到最终融合结果;再对其分解得到的高低频特征分别制定合适的融合规则,本发明可实现对输入图像自适应分解并融合,相比于多尺度变换方法算法简单,融合结果的质量好,运行速度快。
附图4-6为红外/可见光图像的实例,其中,图4为红外图像,图5为可见光图像,图6为本发明融合结果。
附图说明
图1为本发明的流程图。
图2为基本单元结构图。
图3本发明融合图像时的网络结构图。
图4为红外图像。
图5为可见光图像。
图6为本发明的融合图像。
具体实施方式
一种基于深度学习的图像融合方法,包括以下步骤:
1.构建深度堆叠卷积神经网络基本单元
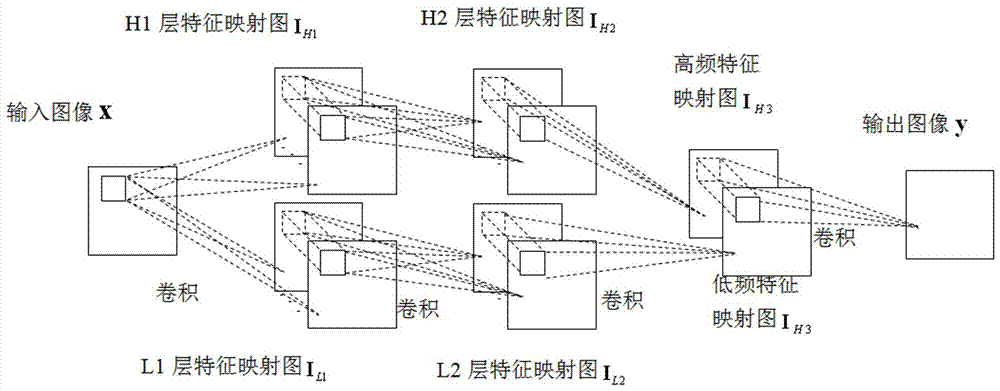
深度堆叠卷积神经网络由多个基本单元堆叠而成,基本单元由高频子网、低频子网和融合卷积层构成,高频子网、低频子网又分别由三层卷积层构成,其中,第一层卷积层对输入信息进行限制,第二层卷积层对信息进行组合,第三层卷积层再将这些信息合并为高频、低频特征映射图各一幅,具体如下:
(1)输入源图像x,经卷积操作得高频子网第一个卷积层h1的特征映射图
(2)ih1再经卷积可得高频子网第二个卷积层h2的特征映射图
(3)ih2再经卷积可得高频子网第三个卷积层h3的特征映射图
(4)高频特征映射图ih3和低频特征映射图il3再经过融合卷积层卷积得到重构图像
2.训练基本单元
(1)在基本单元构建完成后,将其所有的偏置初始化为0;
(2)采用无监督方式训练基本单元,输入训练数据
3.构建并训练堆叠网络
将多个训练好的基本单元首尾相接,将前一个基本单元的输出作为下个基本单元的输入组成堆叠网络,再用和基本单元相同的数据集和目标函数采用端对端的方式同时调整整个网络,最终得到堆叠卷积神经网络;
4.基于深度堆叠卷积神经网络融合图像
(1)输入源图像a和b,经已训练好的深度堆叠卷积神经网络在最后一个基本单元的h3层和l3层分别得到高频特征映射图ah3、bh3和低频特征映射图al3、bl3;
(2)融合高频特征映射图
(3)融合低频特征映射图
低频特征映射图al3(x,y)的局部能量定义为:
低频特征映射图al3(x,y)和bl3(x,y)所对应区域的匹配度为:
设α为匹配度的阈值,匹配度阈值α取值通常在0.7-0.9之间,mab(x,y)<α表明对应区域的差异较大,宜采用取大的合并规则:
(4)将fh3和fl3放回最后一个基本单元的融合卷积层,得到融合结果f。
上述的一种基于深度学习的图像融合方法,高频子网和低频子网第一层卷积层的卷积核分别初始化为高斯拉普拉斯滤波器和高斯滤波器,其余层卷积核用
上述的一种基于深度学习的图像融合方法,深度堆叠神经网络的训练集和测试集由各类型的图像等比例混合组成,所述图像包括可见光图像、红外图像和医学图像,mini-batch取值在22-32之间。mini-batch大小决定误差收敛的稳定性,其值越大越稳定,但占用的内存更多,故取值在22-32之间,学习率决定误差收敛的速度,其值越大收敛速度越快,但越不稳定,取值通常在0.001-0.01之间。
上述的一种基于深度学习的图像融合方法,基本单元第一层卷积层和第二层卷积层的卷积核个数相等且取值范围为4-16,基本单元堆叠个数取值范围为3-6。卷积核个数越多,学习得的特征越多,但占用内存越大,取值通常在4-16之间。基本单元堆叠个数越多,网络对图像的分解就越精细,但个数太多却会使边缘等细节的重构能力变差,取值通常在3-6之间。
上述的一种基于深度学习的图像融合方法,卷积层的激活函数选
反向传播算法、高斯滤波器和高斯拉普拉斯滤波器的实现是本领域技术人员公知的算法,具体流程可在相应的教科书或者技术文献中查阅到。
- 还没有人留言评论。精彩留言会获得点赞!