文本分类方法及获得的文本分类器与流程
本发明涉及人工智能的文本分类技术领域,具体涉及一种文本分类方法及获得的文本分类器。
背景技术:
随着网络技术的快速发展,对于电子文本信息进行有效地组织和管理,并能快速、准确且全面地从中找到相关信息的要求越来越高。文本分类作为处理和组织大量文本数据的关键技术,在较大程度上解决了信息杂乱的问题,方便用户准确地获取所需的信息,是信息过滤、信息检索、搜索引擎及文本数据库等领域的技术基础。文本分类一般包括对文本的表达、文本分类器的选择及训练、文本分类结果的评价与反馈等过程。现有的文本分类技术通常按照以下步骤实施:(1)确定分类体系;(2)收集待标注语料,形成语料库;(3)用语料库训练分类模型;(4)用训练好的分类模型对新文本进行分类。
但是,对于以下几种应用场景,1)对于文本分类体系不均衡,有的类别范畴很大,有的类别范畴很小,如一个类别是“汽车行业”,而另一个类别是“锂电池”等的应用场景;2)对于易于获得大量的未标注语料,而获得标注语料的成本较高的应用场景;3)对于分类体系经常变化,经常新增类别或删除类别的应用场景,现有的文本分类技术存在有以下的缺陷:(1)在分类体系方面,现有技术都是采用固定的分类体系,即确定分类体系后不能随便改变。如若需要改变分类体系,需要重新收集语料,重新训练所有类别的分类模型,此过程需大量的时间和计算资源。(2)在语料库方面,现有技术需基于一定规模的标注好类别的文本作为训练语料,而对于标注好类别的文本,往往需要花费大量的人工先进行标注处理,从而增加了投入成本。
技术实现要素:
本发明针对现有技术中文本分类技术的分类体系不能随意改变,如需改变分类体系需要耗费较多的时间和计算资源,且语料需人工进行标注,需要投入成本较高且耗时长的缺陷,目的在于提供一种可以灵活改变分类体系且自动进行标注文本的文本分类方法,大大地节省了计算资源、时间和成本。
实现上述目的的技术方案是:
本发明获得用于自动标注语料的文本分类器的方法,该方法包括:
概念确定步骤ⅰ,确定概念集合,概念集合中的每个概念对应具有至少一个概念关键词的概念关键词集合;
语料自动标注步骤ⅱ,利用概念集合中每个概念对应的概念关键词集合中的概念关键词对未标注语料文本集合进行匹配处理,并用相应的概念对未标注语料文本集合中的文本进行关联与自动标注处理,获得标注语料文本集合;
“标注语料文本集合”包括下列2类文本,第1类为:与概念集合中任一概念相关联并用该概念进行标注了的文本;第2类为:与概念集合中任何概念均不相关联的其他文本,但是该类其他文本由于与已经确定的概念均不关联,可以用“其他”进行标注、或者不做任何标注、或者用其他不与概念词语混淆的词语进行标注的文本等等,只要能清晰表明这类文本是能够与第1类文本进行区分的任何词语即可。
分类模型训练步骤ⅲ,对于概念集合中的每个概念,当与该概念关联的标注语料文本集合中文本数量符合阈值条件时,则将与该概念关联的标注语料文本集合中的文本作为文本分类模型的正例,不与该概念关联的标注语料文本集合中的文本作为文本分类模型的负例,对该概念对应的文本分类模型的正例和负例进行训练,得到该概念对应的文本分类器,最终获得所有文本数量符合阈值条件的概念对应的文本分类器。
在本发明的一较佳实施例中,概念确定步骤ⅰ中,确定概念集合x由概念xi组成,其中i=1,2,3,…n,概念集合x中的每个概念xi对应具有至少一个概念关键词组成的概念关键词集合yi。
在本发明的一较佳实施例中,语料自动标注步骤ⅱ包括:
步骤ⅱ1,根据具体实际应用情况收集足够数量n的未标注语料,记未标注语料文本集合为d={dj},其中j=1,2,…,n;
步骤ⅱ2,利用每个概念xi对应的概念关键词集合yi中的概念关键词对未标注语料文本集合d中的每篇文本分别进行匹配处理,当未标注语料文本集合d中的某一篇文本dj与概念xi对应的概念关键词的匹配情况满足匹配条件时,则将该篇文本dj标注为与该概念xi相关联;对未标注语料文本集合d中每篇文本进行匹配处理得到标注语料文本集合c。
在本发明的一较佳实施例中,分类模型训练步骤ⅲ包括:
步骤ⅲ1,将概念集合x划分为两个互为补集的概念子集合xa和概念子集合xb,划分原则是,若标注语料文本集合c中与概念xi相关联的标注语料文本数量大于或等于阈值α时,则将该概念xi划分入概念子集合xa中,与该概念xi相关联的标注语料文本集合记为ai;若小于阈值α时,则将该概念xi划分入概念子集合xb中;
步骤ⅲ2,将概念子集合xa中的概念xi对应的标注语料文本集合ai作为训练分类模型的正例,从标注语料文本集合c中随机抽出k篇不属于标注语料文本集合ai中的文本记为标注语料文本集合ai',作为训练分类模型的负例;
步骤ⅲ3,采用朴素贝叶斯、支持向量机或逻辑回归的文本分类模型对标注语料文本集合ai和ai'训练概念xi对应的文本分类器记为mi;训练出的概念子集合xa中的每个概念xi对应的文本分类器集合记为m0。
在本发明的一较佳实施例中,分类模型训练步骤ⅲ还包括:
步骤ⅲ4,利用文本分类器集合m0中的分别与每个概念xi对应的文本分类器mi对未标注语料文本集合d中的文本进行分类处理即关联与标注处理,得到相应的文本分类结果,该文本分类结果单独存放,不影响标注语料文本集合c;
步骤ⅲ5,对于概念子集合xa中的每个概念xi,用文本分类器mi计算文本对应到概念xi的概率,从文本分类结果中选出对应到概念xi的概率大于阈值β的文本,将其加入到概念xi对应的标注语料文本集合ai中,形成新的标注语料集合ai;
步骤ⅲ6,对于新的标注语料集合ai,重复步骤ⅲ2~ⅲ52~10次,得到符合要求的概念xi对应的文本分类器mi,从而获得最终符合要求的文本分类器集合m;或对于新的标注语料集合ai,人工匹配评估获得符合要求的概念xi对应的文本分类器mi,从而得到最终符合要求的文本分类器集合m。
在本发明的一较佳实施例中,分类模型训练步骤ⅲ3中:
采用支持向量机的文本分类模型对标注语料文本集合ai和ai'训练针对概念xi的文本分类器。
在本发明的一较佳实施例中,分类模型训练步骤ⅲ5中:
步骤ⅲ5中的阈值β取值范围为0.1~0.5;步骤ⅲ6中,重复步骤ⅲ2~ⅲ55~10次。
在本发明的一较佳实施例中,分类模型训练步骤ⅲ6中:
人工匹配评估是指对于概念xi,从标注语料集合ai中随机抽取若干篇文本,再从标注语料文本集合c中随机抽取若干篇不与该概念xi关联的文本,对抽取的所有文本k重新进行人工标注,得到标准分类结果;在步骤ⅲ3每次训练出文本分类器mi后,用文本分类器mi对抽取的所有文本k另行进行分类处理得到临时分类结果,即使用概念xi对应的文本分类器mi计算所有文本k中的每篇文本关联到概念xi的概率,若概率大于阈值β,则将该文本标注为与概念xi关联的文本;将临时分类结果和标准分类结果进行比较,计算临时分类结果的准确率,当准确率大于或等于阈值γ时,则该文本分类器mi为符合要求的文本分类器;
当准确率低于阈值γ时,则重新进行概念确定步骤ⅰ,即重新确定概念xi对应的至少一个新的概念关键词,形成新的概念关键词集合yi,和/或,重新确定步骤ⅱ2的匹配条件;当有重新进行概念确定步骤ⅰ时,根据新的概念关键词集合yi进行步骤ⅱ2获得新的标注语料文本集合c;将标注语料文本集合c进行步骤ⅲ1获得新的概念子集合xa和新的概念子集合xb;对新的概念子集合xa和新的概念子集合xb继续进行步骤ⅲ2~ⅲ6,直至当文本分类器mi临时分类结果的准确率大于或等于阈值γ,则该文本分类器mi为符合要求的文本分类器;当仅仅有重新确定步骤ⅱ2的匹配条件时,从步骤ⅱ2开始直至该文本分类器mi为符合要求的文本分类器为止。
在本发明的一较佳实施例中,还包括概念关联步骤ⅳ:
概念关联步骤ⅳ,利用文本分类器集合m中的针对每个概念xi的文本分类器mi对文本d进行分类处理;同时利用概念子集合xb中的每个概念xi对应的概念关键词集合中的概念关键词对该文本d进行匹配处理,获得该文本d与概念集合x中的每一概念xi的最终关联结果。
在本发明的一较佳实施例中,概念关联步骤ⅳ具体包括:
步骤ⅳ1,利用文本分类器集合m中每个文本分类器mi对文本d进行分类处理,并计算文本d对应到概念xi的概率,如若文本d对应到概念xi的概率大于设定阈值β,将文本d标注为与概念子集合xa中的概念xi相关联;
步骤ⅳ2,同时,还要利用概念子集合xb中每个概念xi对应的概念关键词集合yi中的概念关键词对文本d进行匹配处理,当满足匹配条件时,将该文本d标注为与该概念子集合xb中的概念xi相关联;获得该文本d与概念集合x中的每一概念xi的最终关联结果。
在本发明的一较佳实施例中,匹配条件具体是指:
判断该文本中是否有超过25%优选超过30%的段落中出现与该概念xi对应的概念关键词集合yi中的概念关键词,如若超过,则该文本标注为与该概念xi关联;如若不超过,则该文本不标注与该概念xi关联。
在本发明的一较佳实施例中,还包括语料更新步骤ⅴ,
语料更新步骤ⅴ,将文本d与概念集合x中的每一概念xi的最终关联结果加入到标注语料文本集合c中,采用一定的移除方式定期从标注语料文本集合c中移除较旧的标注语料文本,得到更新后的标注语料文本集合c。
在本发明的一较佳实施例中,语料更新步骤ⅴ中移除方式是指:使标注语料文本集合c中每个概念xi对应的文本数量保持在数十到数百之间,如果某概念xi对应的文本数量大于数百,则移除较旧的文本;使不与任何概念xi关联的文本数量保持在数千到数万之间,如若超过数万,则移除较旧的文本。
在本发明的一较佳实施例中,还包括分类器更新步骤ⅵ:
对更新后的标注语料文本集合c重复分类模型训练步骤ⅲ,得到更新的文本分类器集合m。
在本发明的一较佳实施例中,还包括概念新增步骤ⅶ:
步骤ⅶ1,在增加若干新增概念xp后,取概念增集合xp={xp},新增概念xp对应概念关键词集合yp;
步骤ⅶ2,对概念增集合xp={xp}进行语料自动标注步骤ⅱ2,然后按照分类模型训练步骤ⅲ1的划分原则将xp划分为两个互为补集的概念子集合xpa和概念子集合xpb,再进行分类模型训练步骤ⅲ2~ⅲ6;
判断概念xp对应的标注语料文本集合cp中文本数量是否大于或等于阈值α,如若大于或等于阈值α,则将概念xp分配到概念子集合xa中,将训练出符合要求的文本分类器mp加入到文本分类器集合m中;如若小于阈值α,则将概念xp分配到概念子集合xb中。
在本发明的一较佳实施例中,还包括概念新增后的概念关联步骤ⅷ:利用概念新增步骤ⅶ后得到的文本分类器集合m中的针对每个概念xp的文本分类器mp对文本d进行分类处理;同时利用概念子集合xb中的每个概念xp对应的概念关键词集合中的概念关键词对该文本d进行匹配处理,获得该文本d与概念集合x中的每一概念xp的最终关联结果。
在本发明的一较佳实施例中,步骤ⅱ2中,当未标注语料文本集合d中的某一篇文本dj与多个概念xi对应的概念关键词的匹配情况均满足匹配条件时,则将该篇文本dj标注为与该对应的多个概念xi均相关联。
在本发明的一较佳实施例中,步骤ⅱ2中,当未标注语料文本集合d中的某一篇文本dj与任何概念xi对应的概念关键词的匹配情况均不满足匹配条件时,则将该篇文本dj标注为“其它”或者不作任何标注。
在本发明的一较佳实施例中,在人工标注的方法中,当某一篇文本与任何概念对应的概念关键词的匹配情况均不满足匹配条件时,则将该篇文本标注为“其它”或者不作任何标注。
在本发明的一较佳实施例中,步骤ⅳ2之后,当文本d与任何概念xi对应的概念关键词的匹配情况均不满足匹配条件时,则将该篇文本d标注为“其它”或者不作任何标注,获得该文本d与概念集合x中的每一概念xi的最终关联结果。
在本发明的一较佳实施例中,本发明还包括获得的自动标注语料的文本分类器。
在本发明的一较佳实施例中,本发明还包括获得的标注语料文本集合。
在本发明的一种文本分类方法,包括利用以上所述的方法得到的文本分类器集合m中的针对每个概念xi的文本分类器mi对文本d进行分类处理;同时利用概念子集合xb中的每个概念xi对应的概念关键词集合中的概念关键词对该文本d进行匹配并且分类处理,获得该文本d与概念集合x中的每一概念xi的最终分类结果。
在本发明的一种文本分类方法,具体包括,
第一步,利用文本分类器集合m中每个文本分类器mi对文本d进行分类处理,并计算文本d对应到概念xi的概率,如若文本d对应到概念xi的概率大于设定阈值β,将文本d分为与概念子集合xa中的概念xi相关联;
第二步,同时还要利用概念子集合xb中每个概念xi对应的概念关键词集合yi中的概念关键词对文本d进行匹配处理,当满足匹配条件时,将该文本d与该概念子集合xb中的概念xi相关联。
术语“概念”是若干个上市公司的经营业务的共性。概念的范畴包括:(1)政策,如“一带一路”等;(2)行业,如“食品饮料”等;(3)产品,如“无人机”等;(4)金融方面的特点,如“次新股”等,及其他内容。概念包括但不限于上述范畴。术语“概念关键词”是指每个概念对应若干个能表示概念特点的词。在一句话中如若提到概念关键词,则认为谈论的是对应的概念。文本包括但不限于新闻、证券机构的研报、上市公司的公告等的标题和正文内容。术语“文本和概念相关联”是指当一篇文本的内容较多地涉及和某个概念相关的内容,则称为该文本和该概念相关联。一篇文本可能关联到概念,也可能不关联任何概念;可能关联到一个概念,也可能关联多个概念。从文本分类的角度来看,概念可以认为是类别,文本关联到某个概念,可以认为文本属于某个类别。术语“标注”是指标出文本对应的概念,标注可以是人工标注,也可以通过算法实现自动标注。术语“未标注语料文本集合”是指没有标出文本对应概念的文本集合。术语“标注语料文本集合”是指已经标出文本对应概念的文本集合。
本发明的积极进步效果在于:
本发明的方法提供一种算法结构,具有普适性,可灵活地改变分类体系,例如能够实现定期更新标注语料文本集合和文本分类器,如若需要新增概念,既在概念集合中增加新增概念,只需针对新增概念进行自动标注语料及训练分类器,即可得到新增概念对应的文本分类器,如此一来节约了计算时间和资源,并且本发明提供少量的初始语料文本即可,且自动标注,无需人工标注,进一步节约时间和成本。
附图说明
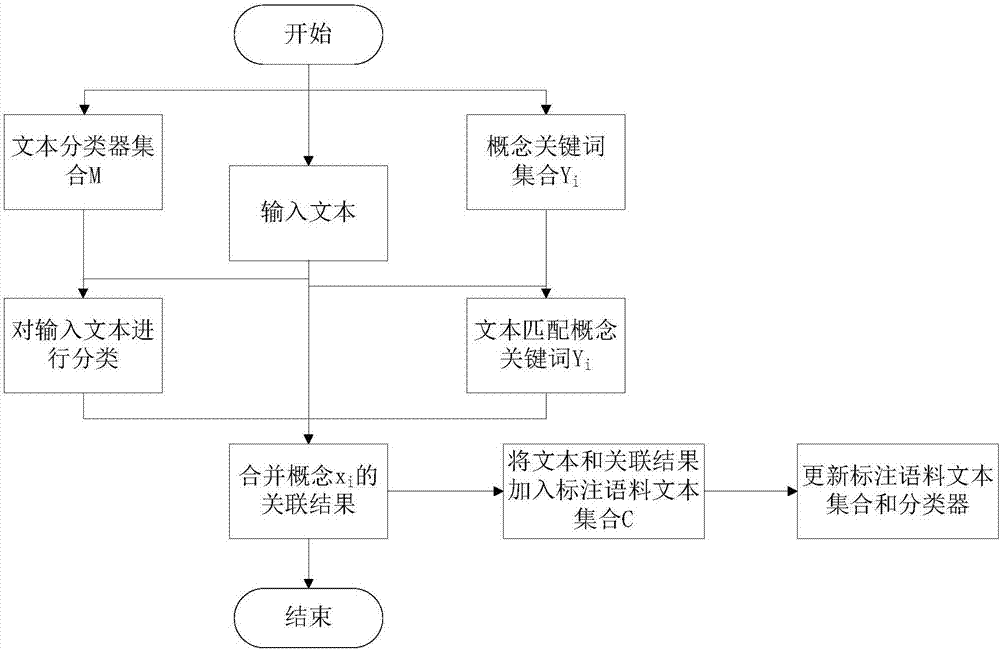
图1为本发明训练文本分类器的流程图;
图2为本发明的文本分类方法的流程图。
具体实施方式
下面举出较佳实施例,并结合图1和图2来更清楚完整地说明本发明获得用于自动标注语料的文本分类器方法及文本分类器的实现过程。
步骤a,概念确定过程包括:
概念集合x由概念xi组成,其中i=1,2,3,…n,概念集合x中的每个概念xi对应具有至少一个概念关键词组成的概念关键词集合yi。一篇文本可能关联到一个或多个概念xi,也可能不关联任何概念xi。如若一篇文本具有较多地与概念集合x中某概念xi相关的内容,则该文本和该概念xi相关联;如若一篇文本的内容与概念集合x中任何概念xi均不相关,称为该文本和该概念相关联。从文本分类的角度来看,概念可以认为是类别,如若文本关联到某概念,可以认为文本属于某概念所属的类别。概念集合用于确定文本要关联到的概念,即确定将文本分为关联到的概念对应的类别。
步骤b,语料自动标注过程包括:
步骤b1,根据具体实际应用情况收集足够数量n的未标注语料,记未标注语料文本集合为d={dj},其中j=1,2,…,n。
步骤b2,利用每个概念xi对应的概念关键词集合yi中的概念关键词对未标注语料文本集合d中的每篇文本分别进行匹配处理,判断当未标注语料文本集合d中的某一篇文本dj与概念xi对应的概念关键词的匹配情况是否满足匹配条件时,本发明的一优选实施例中,匹配条件为即判断该文本dj中是否有超过25%优选超过30%的段落中出现与该概念xi对应的概念关键词集合yi中的概念关键词,如若超过,则将该文本dj与概念xi相关联;如若不超过,则该文本dj不可以与概念xi相关联。当未标注语料文本集合d中的某一篇文本dj与概念xi对应的概念关键词的匹配情况满足匹配条件时,则将该篇文本dj标注为与该概念xi相关联的文本,并将该篇文本dj标注为与该概念xi相关联。对未标注语料文本集合d中每篇文本进行匹配处理得到标注语料文本集合c。
当未标注语料文本集合d中的某一篇文本dj与多个概念xi对应的概念关键词的匹配情况均满足匹配条件时,则将该篇文本dj标注为与该对应的多个概念xi均相关联。当未标注语料文本集合d中的某一篇文本dj与任何概念xi对应的概念关键词的匹配情况均不满足匹配条件时,则将该篇文本dj标注为“其它”或者不作任何标注。
其中,影响匹配条件的主要因素包括:文本中出现的与概念xi的概念关键词集合yi中概念关键词的数量、文本中出现的概念xi的概念关键词集合yi中概念关键词的数量和文本中所有词语数量的比值、文本中出现概念xi的概念关键词集合yi中概念关键词的句子数量、文本中出现概念xi的概念关键词集合yi中概念关键词的句子数量和文本中所有句子数量的比值、文本中出现概念xi的概念关键词集合yi的概念关键词的自然段数量、文本中出现概念xi的概念关键词集合yi的概念关键词的自然段数量和文本自然段总数的比值。
步骤c,分类模型训练过程包括:
步骤c1,将概念集合x划分为两个互为补集的概念子集合xa和概念子集合xb,划分原则是,若标注语料文本集合c中与概念xi相关联的标注语料文本数量大于或等于阈值α时,则将该概念xi划分入概念子集合xa中,与该概念xi相关联的标注语料文本集合记为ai;若小于阈值α时,则将该概念xi划分入概念子集合xb中。一优选实施例中,阈值α取值为100。
步骤c2,将概念子集合xa中的概念xi对应的标注语料文本集合ai中的文本作为训练分类模型的正例,从标注语料文本集合c中随机抽出k篇不属于标注语料文本集合ai中的文本作为训练分类模型的负例,记为标注语料文本集合ai'。
步骤c3,采用朴素贝叶斯、支持向量机或逻辑回归等文本分类模型对标注语料文本集合ai和ai'训练概念xi对应的文本分类器,记为mi。训练出的概念子集合xa中的每个概念xi对应的文本分类器集合记为m0。本发明的一优选实施例中,采用支持向量机(可参考文献:yuan,g.,ho,c.,lin,c.:recentadvancesoflarge-scalelinearclassification.proc.ieee100(9),2584-2603(2012))的文本分类模型对标注语料文本集合ai和ai'训练针对概念xi的文本分类分类器。
步骤c4,利用文本分类器集合m0中的分别与每个概念xi对应的文本分类器mi对未标注语料文本集合d中的文本进行分类处理,得到相应的文本分类结果,该分类结果单独存放,不影响标注语料文本集合c。
步骤c5,对于概念子集合xa中的每个概念xi,用文本分类器mi计算文本对应到概念xi的概率,从文本分类结果中选出对应到概念xi的概率大于阈值β的文本,将其加入到概念xi对应的标注语料文本集合ai中,形成新的标注语料集合ai。其中,β取值范围为0.1~0.5。
步骤c6,对于新的标注语料集合ai,重复步骤c2~c52~10次,得到符合要求的概念xi对应的文本分类器mi,从而获得最终符合要求的文本分类器集合m。一优选实施例中,重复步骤c2~c55~10次。或对于新的标注语料集合ai,人工匹配评估获得符合要求的概念xi对应的文本分类器mi,从而得到最终符合要求的文本分类器集合m。
其中,人工匹配评估是指对于概念xi,从标注语料集合ai中随机抽取若干篇文本,再从标注语料文本集合c中随机抽取若干篇不与该概念xi关联的文本,对抽取的所有文本k重新进行人工标注,得到标准分类结果;在步骤ⅲ3每次训练出文本分类器mi后,用文本分类器mi对抽取的所有文本k另行进行分类处理得到临时分类结果,即使用概念xi对应的文本分类器mi计算所有文本k中的每篇文本关联到概念xi的概率,若概率大于阈值β,则将该文本标注为与概念xi关联的文本;将临时分类结果和标准分类结果进行比较,计算临时分类结果的准确率,当准确率大于或等于阈值γ(通常γ取值范围为0.8~1)时,则该文本分类器mi为符合要求的文本分类器;
当准确率低于阈值γ时,则重新进行概念确定步骤ⅰ,即重新确定概念xi对应的至少一个新的概念关键词,形成新的概念关键词集合yi,和/或,重新确定步骤b2的匹配条件;当有重新进行概念确定步骤ⅰ时,根据新的概念关键词集合yi进行步骤b2获得新的标注语料文本集合c;将标注语料文本集合c进行步骤c1获得新的概念子集合xa和新的概念子集合xb;对新的概念子集合xa和新的概念子集合xb继续进行步骤c2~c6,直至当文本分类器mi临时分类结果的准确率大于或等于阈值γ,则该文本分类器mi为符合要求的文本分类器;当仅仅有重新确定步骤b2的匹配条件时,从步骤b2开始直至该文本分类器mi为符合要求的文本分类器为止。
步骤d,概念关联过程包括:
步骤d1,利用文本分类器集合m中的针对每个概念xi的文本分类器mi对文本d进行分类处理,用文本分类器mi计算文本d对应到概念xi的概率,如若文本d对应到概念xi的概率大于设定阈值β,将文本d标注为与关联到概念子集合xa中的概念xi相关联;
步骤d2,同时还要利用概念子集合xb中每个概念xi对应的概念关键词集合yi中的概念关键词对文本d进行匹配处理,当满足匹配条件时,将该文本d标注为与该概念子集合xb中的概念xi相关联;获得该文本d与概念集合x中的每一概念xi的最终关联结果。当文本d与任何概念xi对应的概念关键词的匹配情况均不满足匹配条件时,则将该篇文本d标注为“其它”或者不作任何标注,获得该文本d与概念集合x中的每一概念xi的最终关联结果。
步骤e,更新标注语料文本集合包括:
将文本d与概念集合x中的每一概念xi的最终关联结果加入到标注语料文本集合c中,采用一定的移除方式定期从标注语料文本集合c中移除较旧的标注语料文本,得到更新后的标注语料文本集合c。其中,移除方式是指:使标注语料文本集合c中每个概念xi对应的文本数量保持在数十到数百之间,如果某概念xi对应的文本数量大于数百,则移除较旧的文本;使不与任何概念xi关联的文本数量保持在数千到数万之间,如若超过数万,则移除较旧的文本。
步骤f,更新分类器过程包括:
对更新后的标注语料文本集合c重复分类模型训练步骤ⅲ,得到更新的文本分类器集合m。
步骤g,增加新增概念过程包括:
步骤g1,在增加若干新增概念xp后,取概念增集合xp={xp},新增概念xp对应概念关键词集合yp。
步骤g2,对概念增集合xp={xp}进行语料自动标注处理,然后按照分类模型训练步骤ⅲ1的划分原则将xp划分为两个互为补集的概念子集合xpa和概念子集合xpb,再进行分类模型训练步骤c2~c6。判断概念xp对应的标注语料文本集合cp中文本数量是否大于或等于阈值α,如若大于或等于阈值α,则将概念xp分配到概念子集合xa中,将训练出符合要求的文本分类器mp加入到文本分类器集合m中;如若小于阈值α,则将概念xp分配到概念子集合xb中。
概念新增后的概念关联过程包括:利用概念新增步骤ⅶ后得到的文本分类器集合m中的针对每个概念xp的文本分类器mp对文本d进行分类处理;同时利用概念子集合xb中的每个概念xp对应的概念关键词集合中的概念关键词对该文本d进行匹配处理,获得该文本d与概念集合x中的每一概念xp的最终关联结果。
下面通过一具体实施例对本发明获得用于自动标注语料的文本分类器的方法具体实现过程进行进一步说明:
步骤s1,确定概念:
确定包含三个概念的概念集合x={x1,x2,x3},x1=废气治理,x2=增强现实,x3=钒电池。x1,x2,x3对应的概念关键词集合y1,y2,y3分别为:
y1={废气,废气治理,废气处理,有机废气,工业废气,废气净化};
y2={增强现实,ar};
y3={钒电池}。
步骤s2,自动语料标注:
步骤s21,收集5000篇新闻语料,形成未标注语料文本集合d={dj},其中j=1,2,…,5000;
步骤s22,用每个概念x1,x2,x3对应的概念关键词集合y1,y2,y3对未标注语料文本集合d中的每篇文本分别进行匹配处理。当一篇文本dj与某个概念xi对应的概念关键词yi的匹配情况满足匹配条件时,即判断该文本dj中是否有超过25%优选超过30%的段落中出现与概念xi对应的概念关键词集合yi中的概念关键词,如若超过,则该文本dj可以关联到该概念xi;如若不超过,则该文本dj不可以关联到该概念xi。当未标注语料文本集合d中的某一篇文本dj与概念xi对应的概念关键词的匹配情况满足匹配条件时,则将该篇文本dj标注为与该概念xi相关联的文本,则将该篇文本dj标注为与该概念xi相关联。对未标注语料文本集合d中每篇文本进行标注得到标注语料文本集合c。
步骤s3,分类模型训练:
步骤s31,标注语料文本集合c中标记了与概念x1相关联的文本有208篇,标记了概念x2相关联的文本有154篇,标记了概念x3相关联的文本有34篇;
步骤s32,将概念集合x划分为两个互为补集的概念子集合xa和概念子集合xb。取阈值α=100,则xa={x1,x2},xb={x3}。概念x1,x2相关联的标注语料文本集合ci分别记为a1,a2。
步骤s33,分别将概念子集合xa中的概念x1,x2对应的标注语料文本集合a1中的文本作为训练分类模型的正例,从标注语料文本集合c中随机抽出1000篇不属于标注语料文本集合a1,a2中的文本,作为训练分类模型的负例,记为标注语料文本集合a1',a2'。采用支持向量机对标注语料文本集合a1、a1'和a2、a2'进行训练概念x1,x2对应的文本分类器,分别记为m1,m2。概念子集合xa中的概念x1,x2对应的文本分类器集合记为m0。
步骤s34,利用文本分类器集合m0中的概念x1,x2对应的文本分类器m1,m2对未标注语料文本集合d中的文本进行分类处理,得到相应的文本分类结果。
步骤s35,对于概念子集合xa中的x1,x2,用文本分类器m1,m2计算文本对应到概念x1,x2的概率,从文本分类结果中分别选出对应到概念x1,x2的概率大于阈值β的文本,将其加入到概念x1,x2对应的标注语料文本集合a1,a2中,形成新的标注语料集合a1,a2。
步骤s36,对于新的标注语料集合a1,a2,分别重复步骤s32~s355次,得到符合要求的概念x1,x2对应的文本分类器m1,m2,从而获得最终符合要求的文本分类器集合m。
步骤s4,概念关联处理:
步骤s41,利用文本分类器集合m中概念x1,x2的文本分类器m1,m2对文本d进行分类处理,用文本分类器m1,m2计算文本d对应到概念x1,x2的概率,如若文本d对应到概念x1,x2的概率大于设定阈值β,将文本d标注为与概念子集合xa中的概念x1,x2相关联;
步骤s42,同时,还要利用概念子集合xb中概念x3对应的概念关键词集合yi中的概念关键词对文本d进行匹配处理,当满足匹配条件时,将该文本d标注为与该概念子集合xb中的概念x3相关联;
步骤s43,合并步骤s41和步骤s42获得的该文本d的概念关联结果,得到该文本d与概念集合x中的每一概念x1,x2,x3的最终关联结果。
- 还没有人留言评论。精彩留言会获得点赞!