一种改进的基于双向传播的评价对象识别方法与流程
本发明涉及意见挖掘领域,具体涉及一种改进的基于双向传播的评价对象识别方法。
背景技术:
互联网已逐步渗透到社会生活的方方面面,伴随着移动互联网的兴起,其渗透方式变得更加多样化,内容也更为丰富。譬如,目前广受关注的社交平台、电子商务、在线支付、互联网金融、博客、bbs等早已通过不同的形式以互联网为载体向广大用户提供产品和服务。与此同时,普通用户不再仅仅单方面地接受产品或服务,其自身的互联网参与度也在不断提升。其中,用户在购物或获得服务之后,针对产品或服务进行在线评论的行为表现得尤为突出。用户对于产品或服务的评论信息反映了其对产品质量或服务水平的意见和态度。这些评论信息无论对于消费者本身还是商家,都具有重要的意义:对于消费者,他们可以通过其他消费者的评论信息客观地得到产品的各维度信息,而商家可以根据客户反馈的评论信息改进产品或制定销售策略。
用户评论信息具有数量庞大和标准不一的特点,所以仅仅依靠传统的人工审阅方法则需要耗费大量的人力和时间,此时就需要借助机器来帮助人类处理这些庞大的用户评论信息,快速地整理成人类可理解的结构化信息,这也是意见挖掘技术的目的。
意见挖掘技术主要以自然语言处理、信息识别和抽取、数据挖掘等为手段,从大量的文本信息中识别和抽取出有价值的观点信息。其中一个重要的任务就是评价对象的抽取。目前的评价对象抽取方法还缺乏一种高准确率和高召回率的方法。
技术实现要素:
本发明的目的是针对上述现有技术的不足,提供了一种改进的基于双向传播的评价对象识别方法,能够有效地从评价语料中提取出评价对象。
本发明的目的可以通过如下技术方案实现:
一种改进的基于双向传播的评价对象识别方法,所述方法包括以下步骤:
s1、获取一类产品的大量评论语料;
s2、使用依存句法工具对每条评论语料进行依存句法分析,并提取所有特定的依存关系对<word_object,word_sentiment>;
s3、利用种子情感词典,使用评价要素迭代识别算法对步骤s2提取的依存关系对<word_object,word_sentiment>进行迭代识别,直到收敛,得到候选评价对象集合co和候选评价词集合cs;
s4、从候选评价对象集合co中提取词频大于阈值λ1的词语作为准确评价对象,从候选评价词集合cs中提取词频大于阈值λ1的词语作为准确评价词,其中所述词频为候选评价对象或候选评价词在依存关系对<word_object,word_sentiment>中出现的次数;
s5、利用word2vec、关联规则和pmi-ir对步骤s4中剩余的候选评价对象进行抽取,得到最后的准确评价对象集合o。
进一步地,步骤s1中,所述一类产品是指电子商务和虚拟产品网站上的产品,步骤s2中,所述依存句法工具为中文处理工具ltp,步骤s3中,所述种子情感词典为正负评价词典。
进一步地,步骤s2中,所述特定的依存关系对是满足sbv、vob、att和cmp四种句法关系的依赖词对<word_object,word_sentiment>。
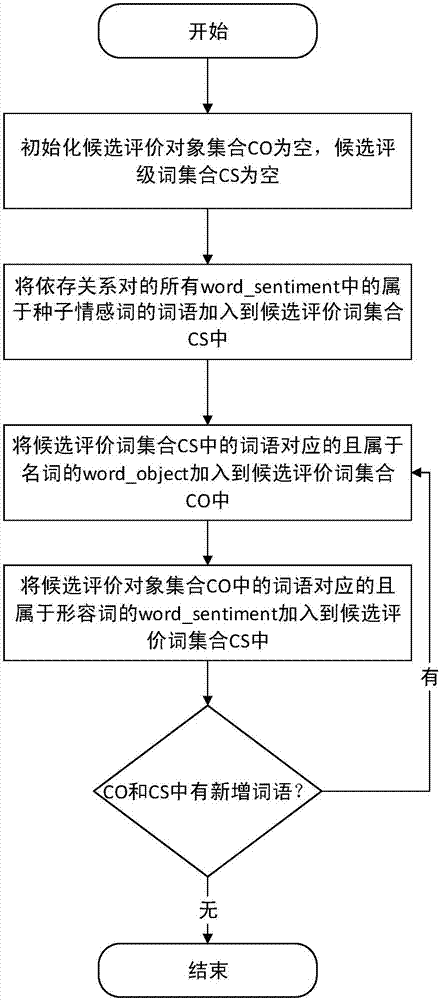
进一步地,所述步骤s3的具体过程为:
步骤s31、初始化候选评价对象集合co为空,候选评价词集合cs为空;
步骤s32、将依存关系对<word_object,word_sentiment>中属于种子情感词典中的词语word_sentiment加入到候选评价词集合cs中;
步骤s33、将候选评价词集合cs中的词语对应的且属于名词的word_object加入到候选评价对象集合co中;
步骤s34、将候选评价对象集合co中的词语对应的且属于形容词的word_sentiment加入到候选评价词集合cs中;
步骤s35、重复步骤s33和步骤s34,直到候选评价对象集合co和候选评价词集合cs不再改变。
进一步地,步骤s4中,所述阈值λ1的取值范围为:λ1∈n,此处取λ1=10。
进一步地,所述步骤s5的具体过程为:
步骤s51、对步骤s1获得的大量评论语料使用开源word2vec工具进行word2vec训练,得到每个词语的词向量,词向量的形式为[wi1,wi2,…wik…,wim],其中wik为第i个词语的词向量第k维的值,m为词向量的维数;
步骤s52、遍历步骤s4中剩余的候选评价对象,基于步骤s51训练得到的词向量,将与准确评价对象的词向量相似度大于阈值λ2的评价对象加入到准确评价对象集合o中;
步骤s53、基于步骤s2得到的依存关系对<word_object,word_sentiment>对步骤s4中剩余的候选评价对象和步骤s52得到的准确评价对象集合o进行关联规则发现,得到关联规则<object,sentiment>集合,将其中的object加入到准确评价对象集合o中;
步骤s54、利用搜索引擎对包含低频候选对象和准确评价词的依存关系对计算pmi-ir值,将pmi-ir值大于阈值λ3的依存关系对<word_object,word_sentiment>中的评价对象加入到准确评价对象集合o中。
进一步地,步骤s52中,所述词向量相似度计算公式为:
其中,vi表示第i个词语的词向量,vj表示第j个词语的词向量,wik表示第i个词语的词向量第k维的值,wjk表示第j个词语的词向量第k维的值,m为词向量的维数。
进一步地,步骤s52中,所述阈值λ2的取值范围为:λ2∈(0,1],此处取λ2=0.7。
进一步地,步骤s54中,所述pmi-ir的公式为:
其中,hit(x)为搜索词x在搜索引擎中的命中数,ε为常数项。
进一步地,步骤s54中,所述阈值λ3的取值范围为:λ3∈(-∞,0],此处取λ3=-6。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明采用了基于双向传播的评价对象识别的技术方案,具体通过依存句法处理中文评论文本,充分挖掘文本中词与词之间的依存关系,从情感词出发,对评价对象和评价词进行迭代识别的手段,从而达到了提高评价对象识别准确率和召回率的效果。
2、本发明采用了基于词向量的评价对象推荐的技术方案,该方案用经过大规模语料训练得到的词向量来度量待评估的评价对象与准确评价对象之间的相似度,并推荐相似度大的评价对象,从而达到了从语义相似度方面提升评价对象识别准确率和召回率的效果。
3、本发明采用了基于关联规则的评价对象推荐的技术方案,该方案具体通过推荐与准确评价词具有强关联性的待评估的评价对象的手段,从而达到了提高评价对象识别召回率的效果。
4、本发明采用了基于搜索引擎pmi-ir信息的评价对象推荐的技术方案,该方案具体通过推荐与准确评价词的pmi-ir值高的待评估的评价对象的手段,从而达到了提高评价对象识别召回率的效果。
附图说明
图1为本发明实施例的整体流程图。
图2为本发明实施例的评价要素迭代识别算法流程图。
图3为本发明实施例利用word2vec、关联规则和pmi-ir进行评价对象推荐的流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例:
本实施例提供了一种改进的基于双向传播的评价对象识别方法,所述方法的流程图如图1所示,包括以下步骤:
s1、获取一类产品的大量评论语料;
s2、使用依存句法工具对每条评论语料进行依存句法分析,并提取所有特定的依存关系对<word_object,word_sentiment>;
s3、利用种子情感词典,使用评价要素迭代识别算法对步骤s2提取的依存关系对<word_object,word_sentiment>进行迭代识别,直到收敛,得到候选评价对象集合co和候选评价词集合cs;
s4、从候选评价对象集合co中提取词频大于阈值λ1的词语作为准确评价对象,从候选评价词集合cs中提取词频大于阈值λ1的词语作为准确评价词,阈值λ1∈n,此处取λ1=10,其中所述词频为候选评价对象或候选评价词在依存关系对<word_object,word_sentiment>中出现的次数;
s5、利用word2vec、关联规则和pmi-ir对步骤s4中剩余的候选评价对象进行抽取,得到最后的准确评价对象集合o。
上述方法通过对一类产品的所有评论逐条进行依存句法分析,并从中抽取特定关系的词对列表;再利用少量情感词典作为种子,在词对列表中进行评价要素的迭代识别,得到粗糙的候选评价对象集合和评价词集合;再利用高准确率的规则从候选评价对象集合中抽取准确的评价对象;根据准确的评价对象,利用基于词向量的相似度计算、pmi和关联规则对剩余的评价对象进行提取,最后得到完整的评价对象集合。
其中,所述步骤s3的流程图如图2所示,具体过程为:
步骤s31、初始化候选评价对象集合co为空,候选评价词集合cs为空;
步骤s32、将依存关系对<word_object,word_sentiment>中属于种子情感词典中的词语word_sentiment加入到候选评价词集合cs中;
步骤s33、将候选评价词集合cs中的词语对应的且属于名词的word_object加入到候选评价对象集合co中;
步骤s34、将候选评价对象集合co中的词语对应的且属于形容词的word_sentiment加入到候选评价词集合cs中;
步骤s35、重复步骤s33和步骤s34,直到候选评价对象集合co和候选评价词集合cs不再改变。
其中,所述步骤s5的流程图如图3所示,具体过程为:
步骤s51、对步骤s1获得的大量评论语料使用开源word2vec工具进行word2vec训练,得到每个词语的词向量,词向量的形式为[wi1,wi2,…wik…,wim],其中wik为第i个词语的词向量第k维的值,m为词向量的维数;
步骤s52、遍历步骤s4中剩余的候选评价对象,基于步骤s51训练得到的词向量,将与准确评价对象的词向量相似度大于阈值λ2的评价对象加入到准确评价对象集合o中,阈值λ2的取值范围为:λ2∈(0,1],此处取λ2=0.7,其中所述词向量相似度计算公式为:
其中,vi表示第i个词语的词向量,vj表示第j个词语的词向量,wik表示第i个词语的词向量第k维的值,wjk表示第j个词语的词向量第k维的值,m为词向量的维数。;
步骤s53、基于步骤s2得到的依存关系对<word_object,word_sentiment>对步骤s4中剩余的候选评价对象和步骤s52得到的准确评价对象集合o进行关联规则发现,得到关联规则<object,sentiment>集合,将其中的object加入到准确评价对象集合o中;
步骤s54、利用搜索引擎对包含低频候选对象和准确评价词的依存关系对计算pmi-ir值,将pmi-ir值大于阈值λ3的依存关系对<word_object,word_sentiment〉中的评价对象加入到准确评价对象集合o中,所述阈值λ3的取值范围为:λ3∈(-∞,0],此处取λ3=-6,所述pmi-ir的公式为:
其中,hit(x)为搜索词x在搜索引擎中的命中数,ε为常数项。
以上所述,仅为本发明专利较佳的实施例,但本发明专利的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明专利所公开的范围内,根据本发明专利的技术方案及其发明专利构思加以等同替换或改变,都属于本发明专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!