一种基于分组的全局多查询优化方法与流程
本发明涉及数据库多查询优化技术领域,尤其涉及一种基于分组的全局多查询优化方法。
背景技术:
数据库查询优化(queryoptimization)已经有很久的历史,从几十年前的单机数据库到现在的分布式大数据平台,衍生出了许多查询优化技术。早期的查询优化主要针对单条查询。查询优化器将从所有可能的查询计划中选择一个最有效的方式来执行给定查询。随着使用场景的丰富,各类应用需求的变化,系统需要应付的高并发查询场景急剧增加。面对场景中可能出现的大量相似性查询,系统只能逐一处理,无法通过利用查询间可共享的部分来加速整个过程。这些查询可能出现在同一批输入的查询中,也可能出现在包含相似嵌套子查询的查询语句中。因此,为了适应现代查询场景越来越高的需求,向用户提供更为快速、准确、全面的查询服务,多查询优化(multi-queryoptimization)成为这类场景下加速查询处理的重要方法之一。
多查询优化算法是以最大化重用相似查询计划间的可共享部分和快速求解为目标,通过特定的搜索策略来确定某一种查询共享组合的过程。可以按照处理模型分为两类:基于局部优化处理模型的多查询优化和基于全局优化处理模型的多查询优化。基于局部处理模型的多查询优化分两个阶段进行。第一阶段充分利用本地查询优化器,为每条查询生成各自的最优执行计划。第二阶段通过对各查询执行计划的合并来构建全局计划。这类方法生成的查询计划数量少,只能通过本地查询优化器得到每个查询的最优执行计划。同时,由于生成查询计划的过程中未知其他查询的可共享部分,无法通过控制本地查询优化器的处理过程来生成可共享的计划。全局优化处理模型的输入是未经优化的查询语句集合,通过全局查询优化器,在所有可能的搜索空间内进行选择,根据一定的搜索策略进行代价估算,直接生成全局执行计划。通过将整个多查询优化处理包含在同一个过程中,此类方法能获得丰富的查询计划组合,更可能构建最优全局计划。
近些年,随着大数据时代的带来,高并发查询场景的急剧增加,分布式sql查询系统需要在短时间内处理大量查询。如果能充分利用多查询优化技术,快速高效地利用查询间可共享部分,就能大幅提升系统吞吐量。但是传统多查询优化只适用于强相似性多查询输入的场景,无法应对查询间相似性不确定的情况。因此,如何在这类场景中高效利用多查询优化技术成为亟待解决的问题。
技术实现要素:
本发明为克服上述的不足之处,目的在于提供一种基于分组的全局多查询优化方法,本发明方法对传统多查询优化方法的改进,结合签名方法和分组策略来进行多查询优化,本发明方法首先通过对查询语句进行签名计算,得到每一个查询的精简化表示;其次,对集合中互相之间无法共享任务的查询进行划分,建立查询组;最后,通过采用基于启发式算法的多查询优化算法,为每一组进行计划选择,并将选择的计划进行合并得到多个全局计划。本发明通过在多查询建模时计算查询签名,充分抽象查询语句中的关键信息;同时,结合分组思想,快速判别查询间的可共享性,加速后续的计划选择过程。
本发明是通过以下技术方案达到上述目的:一种基于分组的全局多查询优化方法,包括多查询建模阶段和多查询优化阶段,如下所示:
1)多查询建模阶段:对查询语句进行签名计算,建立签名;
2)多查询优化阶段:根据签名对查询语句进行分组,建立查询组;并采用基于启发式算法的多查询优化算法,对每一分组内的查询计划进行代价估算来进行计划选择,并将每一分组选择的计划进行合并,得到多个全局计划。
作为优选,所述步骤1)对查询语句建立签名的步骤如下:
1.1)对查询语句q={q1,q2,…,qn}进行解析,优选采用jflex和cup对查询语句q={q1,q2,…,qn}进行词法解析和语法解析;
1.2)采用基于火山模型的查询优化器对查询语句q={q1,q2,…,qn}进行计划枚举,得到其所有可能的计划pi={pi1,pi2,…,pij};
1.3)遍历计划集合pi={pi1,pi2,…,pij}中的每一个计划pij,并进行任务切分,得到每一个计划pij对应的所有可能的任务tij={tij1,tij2,…,tijk};
1.4)通过四元组签名ge=[sign;de;se;be;torder]来表示任务,得到任务签名,进而通过任务与计划、计划与查询之间的关系得到计划签名和查询签名。
作为优选,所述的任务切分的切分规则如下:
(a)若遇到包含子节点的节点,则将其左子节点切分到单独的任务中,父节点和右子节点切分到单独的任务中,并添加exchange节点作为父节点的新左子节点;
(b)若遇到代表聚合操作的节点,将其切分到两个任务中,分别进行本地聚合操作和最终聚合操作;
(c)在计划树的顶部添加一个只包含一个exchange节点的任务。
作为优选,所述步骤1.4)的具体步骤如下:
1.4.1)输入查询计划的集合,每个查询计划为一棵操作符树,操作符树将按照规则被划分为若干子树,每个子树是一个任务;
1.4.2)对操作符树进行后续遍历,为每一个任务计算对应签名,并判断该任务是否在之前的计算过程中出现过;若出现过,则直接使用对应的任务签名,否则为该任务创建新的任务id,并计算任务签名;
1.4.3)签名是一个四元组ge=[sign;de;se;be;torder],其中sign代表标识,包括该任务归属的查询id、计划id和该任务的id;de代表任务中的数据表集合;se代表任务中的选择谓词集合;be代表任务中的非选择谓词集合;torder代表在后续遍历计划时该任务的顺序编号;
1.4.4)初始化sign和torder的值,sign根据当前处理任务归属的查询id、计划id和该任务的id决定,所有id均是从0开始自增的整数;torder是在后续遍历计划时该任务的顺序编号,编号是从0开始自增的整数;
1.4.5)根据任务内的不同操作符计算对应签名:若节点类型为扫描节点时,将其对应的数据表添加到de中,将其对应的选择谓词添加到se中;若节点类型为连接节点、聚合节点或者排序节点时,将其对应的谓词添加到be中;若节点类型为数据传输节点,跳过并继续;
1.4.6)依次构建计划签名和查询签名:通过计划与任务的一对多关系,将归属于同一计划的任务签名进行组合,得到计划签名pije={tij1e,tij2e,…,tijke};通过查询与计划的一对多关系,将归属于同一查询的计划签名进行组合,得到查询签名qie=(pi1e,pi2e,…,pije}。
作为优选,所述步骤2)的多查询优化阶段的步骤如下:
2.1)初始化查询所在的分组:初始化n个查询q={q1,q2,...,qn},将每个查询分为一组,得到n个分组g1,g2,...,gn;
2.2)建立任务到查询的映射关系,为任务ti所包含的所有mi个查询建立集合
2.3)根据映射关系,利用基于路径压缩的并查集算法进行分组,对n个查询q={q1,q2,...,qn}所代表的n个分组g1,g2,…,gn进行合并;
2.4)为步骤2.3)合并得到的每一个分组创建查询集合容器,并将同组的多个查询逐一加入,得到d个查询分组g={g1,g2,…,gd};
2.5)根据分组结果,利用ha算法为每一组查询进行计划选择:对于每一个分组g1,g2,...,gd,输入所有查询,通过对搜索空间内的计划进行代价估算来选择计划,并引入上界函数h对搜索空间进行剪枝;
2.6)根据步骤2.5)的结果,对每一分组选择的计划进行自底向上的任务合并:将计划
作为优选,所述步骤2.3)的具体步骤如下:
2.3.1)对qg中的k个查询集合q1,q2,...,qk进行顺序遍历,并判断集合
2.3.2)若mi小于1,则不进行合并,继续下一个集合;若mi大于1,则初始化第一个查询qs为新分组的代表,并从第二个查询开始,依次查找查询所在的分组,并与代表所在的分组进行合并;
2.3.3)依次将集合内的其他查询qi所在的分组gi与代表的分组gs合并,即设置qi的分组为gs;
2.3.4)在递归查找查询所在分组的过程中,采用路径压缩算法进行优化,即对于查询qi,判断其的分组是否为gi;如果是,则返回该查询分组gi;否则,递归查找qi的代表所在的分组。
作为优选,所述步骤2.5)利用ha算法进行计划选择的方法如下:
2.5.1)初始化用于代价估算的信息:通过读取配置文件中的各项参数,包括磁盘速率、内存大小;
2.5.2)在输入查询包含的所有任务中查找等价任务集合,等价任务的签名中包含相同id;
2.5.3)初始化代价上界:通过计算每一个任务的代价,可以累加获得每一个计划的代价,通过对每一个查询所有计划中代价最小的计划,即“最优计划”的代价进行累和,得到初始上界upperbound;
2.5.4)递归搜索,通过启发式代价估算来为每一个查询选择计划:为了让ha算法算法快速收敛,引入一个上界函数h对搜索空间进行剪枝,公式如下:
其中,nq表示包含任务t的查询数量;next是一个函数,可以求得在状态s下需要进行计划选择的查询编号;cost是一个代价函数,通过磁盘读取页数来对任务进行代价估算,通过对任务代价求和来对计划进行代价估算;est_cost函数用于计算未选计划的估计代价;函数通过将任务的代价cost(t)平分到每一个包含该任务的查询,获得该任务的估计代价,进而通过求和获得计划的估计代价;
2.5.5)得到为每一个分组内所有查询选择的计划集合,
作为优选,所述步骤2.6)对计划
2.6.1)初始化该分组对应的全局计划
2.6.2)将
2.6.3)依次将各计划
本发明的有益效果在于:(1)通过签名计算充分抽象查询语句,能更好支撑多查询优化过程中的查询分组和计划合并;(2)将计划选择中较大的搜索空间通过查询间的共享性划分为多个子空间,避免重复的代价估算操作,从而降低响应时间,提升多查询优化性能。
附图说明
图1是本发明方法的整体流程图;
图2是本发明实施例的多查询建模方法流程图;
图3是本发明实施例的一条查询生成计划的结果示意图;
图4是本发明实施例的一个计划进行任务切分的结果示意图;
图5是本发明实施例的多查询优化方法流程图。
具体实施方式
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
实施例:如图1所示,一种基于分组的全局多查询优化方法,包括多查询建模、多查询优化两个阶段,具体步骤如下:
多查询建模阶段:
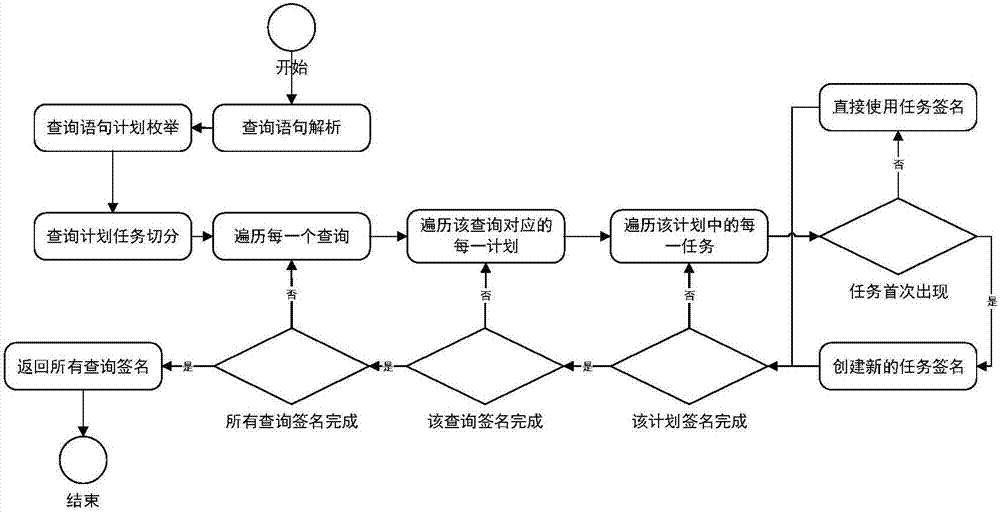
多查询建模的流程图如图2所示,主要步骤包括:
步骤1,对查询语句进行解析,包括词法解析、语法解析。
使用成熟的词法解析和语法解析工具jflex和cup对输入的查询语句q={q1,q2,...,qn}进行词法解析和语法解析。
步骤2,对查询语句进行计划枚举。根据输入的查询语句q={q1,q2,...,qn},得到其所有可能的计划pi={pi1,pi2,...,pij}。
对查询进行计划枚举,用基于火山模型的查询优化器为每一个查询qi枚举出其所有可能的计划pi={pi1,pi2,...,pij}。如图3所示,对于sql语句“select*fromr1,r2,r3wherer1.a=r2.aandr2.c=r3.c;”,可以得到6种不同的查询计划。
步骤3,对查询计划进行任务切分。根据步骤2得到的计划集合pi={pi1,pi2,...,pij}。得到每一个计划pij对应的所有可能的任务tij={tij1,tij2,…,tijk}。
后序遍历每一个计划pij,并进行任务切分,最终得到tij={tij1,tij2,...,tijk}。如图4所示,对于图3的sql语句,可以通过切分得到4个任务。切分规则包括:
a)若遇到包含子节点的节点,则将其左子节点切分到单独的任务中,父节点和右子节点切分到单独的任务中,并添加exchange节点作为父节点的新左子节点;
b)若遇到代表聚合操作的节点,将其切分到两个任务中,分别进行本地聚合操作和最终聚合操作;
c)在计划树的顶部添加一个只包含一个exchange节点的任务。
步骤4,为查询计算签名。通过一种四元组签名ge=[sign;de;se;be;torder]来表示任务,得到任务签名。进而通过任务与计划、计划与查询之间的关系得到计划签名和查询签名。
a)输入是查询计划的集合。每个查询计划都是一棵操作符树,操作符树将按照一定规则被划分为若干子树,每个子树是一个任务。
b)对操作符树进行后续遍历,为每一个任务计算对应签名。判断该任务是否在之前的计算过程中出现过。若出现过,则直接使用对应的任务签名。否则为该任务创建新的任务id,并计算任务签名。
c)签名是一个四元组ge=[sign;de;se;be;torder],其中sign代表标识,包括该任务归属的查询id、计划id和该任务的id;de代表任务中的数据表集合;se代表任务中的选择谓词集合;be代表任务中的非选择谓词集合;torder代表在后续遍历计划时该任务的顺序编号。
d)初始化sign和torder的值。sign根据当前处理任务归属的查询id、计划id和该任务的id决定,所有id均是从0开始自增的整数;torder是在后续遍历计划时该任务的顺序编号,编号是从0开始自增的整数。
e)根据任务内的不同操作符计算对应签名。若节点类型为扫描节点时,将其对应的数据表添加到de中,将其对应的选择谓词添加到se中;若节点类型为连接节点、聚合节点或者排序节点时,将其对应的谓词添加到be中;若节点类型为数据传输节点,跳过并继续。
f)依次构建计划签名和查询签名。通过计划与任务的一对多关系,将归属于同一计划的任务签名进行组合,得到计划签名pije={tij1e,tij2e,...,tijke}。通过查询与计划的一对多关系,将归属于同一查询的计划签名进行组合,得到查询签名qie={pi1e,pi2e,...,pije}。
多查询优化阶段:
多查询优化流程如图5所示,主要包括以下步骤:
步骤1,初始化查询所在的分组。
初始化所有输入的n个查询q={q1,q2,...,qn},将每个查询分为一组,得到n个分组g1,g2,...,gn。
步骤2,建立任务(指包含原始数据表的任务)到查询的映射关系。为任务ti所包含的所有mi个查询建立集合
为任务ti所包含的所有mi个查询建立集合,即查询集合
步骤3,根据步骤2得到的映射关系,利用基于路径压缩的并查集算法进行分组。通过不断对n个查询q={q1,q2,...,qn}所代表的n个分组g1,g2,...,gn进行合并。具体步骤包括:
a)顺序遍历qg中的每一个查询集合qi,并判断集合中的查询数量是否大于1。即对qg中的k个查询集合q1,q2,...,qk进行顺序遍历。
b)判断
c)依次将集合内的其他查询qi所在的分组gi与代表的分组gs合并,即设置qi的分组为gs。
d)在递归查找查询所在分组的过程中,采用路径压缩算法进行优化,即对于查询qi,判断其的分组是否为gi。如果是,则返回该查询分组gi;否则,递归查找qi的代表所在的分组。
步骤4,为步骤3得到的每一个分组的查询建立新的集合容器。
为每一个分组gi创建查询集合容器,并将同组的ci个查询逐一加入,由此可得
步骤5,根据分组结果,利用ha算法为每一组查询进行计划选择。对每一个分组g1,g2,...,gd,输入所有查询,通过对搜索空间内的计划进行代价估算来选择计划,同时引入上界函数h对搜索空间进行剪枝。
依次将每一分组g1,g2,...,gd作为输入,然后进行计划选择。具体执行步骤如下:
a)初始化用于代价估算的信息。通过读取配置文件中的各项参数,包括磁盘速率、内存大小等。
b)在输入查询包含的所有任务中查找等价任务集合。在签名计算时已经发现了所有等价任务,等价任务的签名中包含相同id。
c)初始化代价上界。通过计算每一个任务的代价,可以累加获得每一个计划的代价。通过对每一个查询所有计划中代价最小的计划,即“最优计划”的代价进行累和,得到初始上界upperbound。
d)递归搜索,通过启发式代价估算来为每一个查询选择计划。为了让ha算法快速收敛,需要引入一个上界函数h对搜索空间进行剪枝,公式如下:
其中,nq表示包含任务t的查询数量;next是一个函数,可以求得在状态s下需要进行计划选择的查询编号;cost是一个代价函数,通过磁盘读取页数来对任务进行代价估算,通过对任务代价求和来对计划进行代价估算;est_cost函数用于计算未选计划的估计代价。函数通过将任务的代价cost(t)平分到每一个包含该任务的查询,获得该任务的估计代价,进而通过求和获得计划的估计代价。
e)最终得到为每一个分组内所有查询选择的计划集合,
步骤6,根据步骤5的结果,对每一分组选择的计划进行自底向上的任务合并。将计划
对
a)初始化该分组对应的全局计划
b)将
c)依次将各计划
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!