从URL中高效提取用户客户端ID的方法和系统与流程
本发明属于计算机系统领域,尤其涉及一种从url中高效提取用户客户端id的方法和系统。
背景技术:
随着internet技术的飞速发展,运行于internet上的各种应用和服务也随之大量涌现,大数据的时代已经来临。每个网站本身都是一个独立的信息系统,这些网站经过网络互联后,使得整个互联网变成了一个巨大的信息系统。客户在浏览网站的过程中会留下它们访问的痕迹,这些痕迹会以web日志文件的形式保存下来。各种系统、程序、运维、交易等得日志变得越来越重要,因为它是系统恢复、错误跟踪、安全检测等操作的重要依据。
由于数据源众多、各个系统的用户繁多、操作频繁,每日会产生tb级甚至pb级的海量web日志数据,而传统数据库由于可扩展性和处理性能的限制,已经不能满足现今动辄数十g、数百g、甚至上t的数据量的存储分析处理的要求。而在一大堆非结构化的日志文件里面,怎样快速检索出数据、怎样快速寻找到有用的数据、怎样对日志进行统计分析,成为亟待解决的问题。现有的大数据查询方法只能简单通过hbase直接进行行键的搜索和借助hive的hql进行检索,检索时延很大,数据分析结果也不准确,不能满足当前需求;且在大数据应用场景下,随着数据海量增加,直接利用本地计算大量用户访问的url地址中客户端id会消耗大量资源和内存,并且效率低下。
为了解决上述技术问题,人们进行了长期的探索,例如中国专利公开了一种海量web日志数据查询与分析方法[申请号:cn201410596395.6],包括如下步骤:步骤1,用hive中的etl对各个数据源的数据进行解析,解析过程包括提取、清洗、转化和加载四个步骤,在对数据进行清洗时,将其中的有用信息用mapreduce程序进行分布式抽取处理;步骤2,将抽取出来的数据装载进数据仓库中;步骤3,hive的部件driver接收hiveql语句;步骤4,针对倾斜数据对接受语句进行优化,进行表连接操作后得到初步的map结果;步骤5,将接收到的hiveql语句转换成mapreduce任务执行并存储查询结果;步骤6,对于海量的web日志数据进行数据分割;步骤7,应用高度并行的全局随机化搜索的遗传算法对数据进行分析挖掘;步骤8,将数据查询与分析部分得出的数据装载进mysql数据库中。
上述方案实现了大数据的数据挖掘,提高数据分析结果的准确度,但是仍然存在不足,例如:1.上述方案只能了解到web的情况,无法对客户端的id进行抽取;2.分布式系统的各台机器之间没法进行流量调配,导致负载不均衡。
技术实现要素:
本发明的目的是针对上述问题,提供一种高效提取客户端id的从url中高效提取用户客户端id的方法;
本发明的另一目的是针对上述问题,提供一种基于从url中高效提取用户客户端id的方法的系统。
为达到上述目的,本发明采用了下列技术方案:
从url中高效提取用户客户端id的方法包括如下步骤:
s1:通过日志文件收集单元收集日志文件的数据并存入文件池;
s2:通过hive中的etl对步骤s1中收集到的数据进行预处理,并将预处理好的数据收集到hadoop集群中以将数据进行结构化处理;
s3:通过hive的udf功能与从url中提取客户端id的功能相结合以提取客户端id。
通过上述技术方案,将hive的udf自适应开发功能与从url中提取客户端id的功能的结合,实现用户客户端id的高效提取。
在上述的从url中高效提取用户客户端id的方法中,在步骤s1中,所述的日志收集单元为能够对分布式的海量日志文件进行采集、聚合和传输的flume系统。
在上述的从url中高效提取用户客户端id的方法中,在步骤s2中,通过以下方法将数据结构化处理:
通过hive建立数据文件的表结构,并通过mysql将hive和hdfs进行建表关联以将数据结构化处理。
在上述的从url中高效提取用户客户端id的方法中,在步骤s2中,所述的etl的程序部署于hadoop集群中,且etl的程序包括能够对数据进行清洗、合并、上传、高压缩编码和分布式提取的一系列程序。
在上述的从url中高效提取用户客户端id的方法中,所述hadoop的分布式系统通过以下方法构建:
搭建部署有至少一台主机和至少一台从机的hadoop2.7.1的集群环境,对hive和hdfs的环境与配置进行配置,且将hivemetastore、mysql和hiveserver2组建在一台主机上,并对namenodeha和resourcemanagerha进行设置以构建分布式系统。
在上述的从url中高效提取用户客户端id的方法中,在步骤s3中,通过以下方法将udf功能与从url中提取客户端id的功能相结合:
s3-1:通过开发相对应的hive的对ip地址具有正常提取功能的udf函数使hive具有udf功能;
s3-2在本地连接hadoop集群,并在完成基于hive的从url中提取客户端id的程序后,通过udf函数编译完成与从url中提取客户端id的功能相结合。
在上述的从url中高效提取用户客户端id的方法中,在分布式系统的各节点搭建有tomcat分布式集群,并利用nginx对tomcat所在机器的流量进行调配。
在上述的从url中高效提取用户客户端id的方法中,在步骤s3之后,还包括以下步骤:
在对提取的客户端id结果输出后对结果进行进一步分析和/或生成报表。
在上述的从url中高效提取用户客户端id的方法中,输出的结果通过可视化配置进行可视化显示,所述的可视化配置包括数据采集可视化、数据接入可视化、数据计算可视化和数据输出可视化中的任意一种或多种组合的配置。
一种基于从url中高效提取用户客户端id的方法的系统。
本发明从url中高效提取用户客户端id的方法和系统相较于现有技术具有以下优点:
1、利用hive调用hadoop进行分布式计算来完成url中客户端id的提取,效率高且消耗资源低;
2、对各台机器进行流量调配,实现负载均衡;
3、将数据进行结构化处理,以便于客户端id的提取。
附图说明
图1是本发明实施例一的技术架构图;
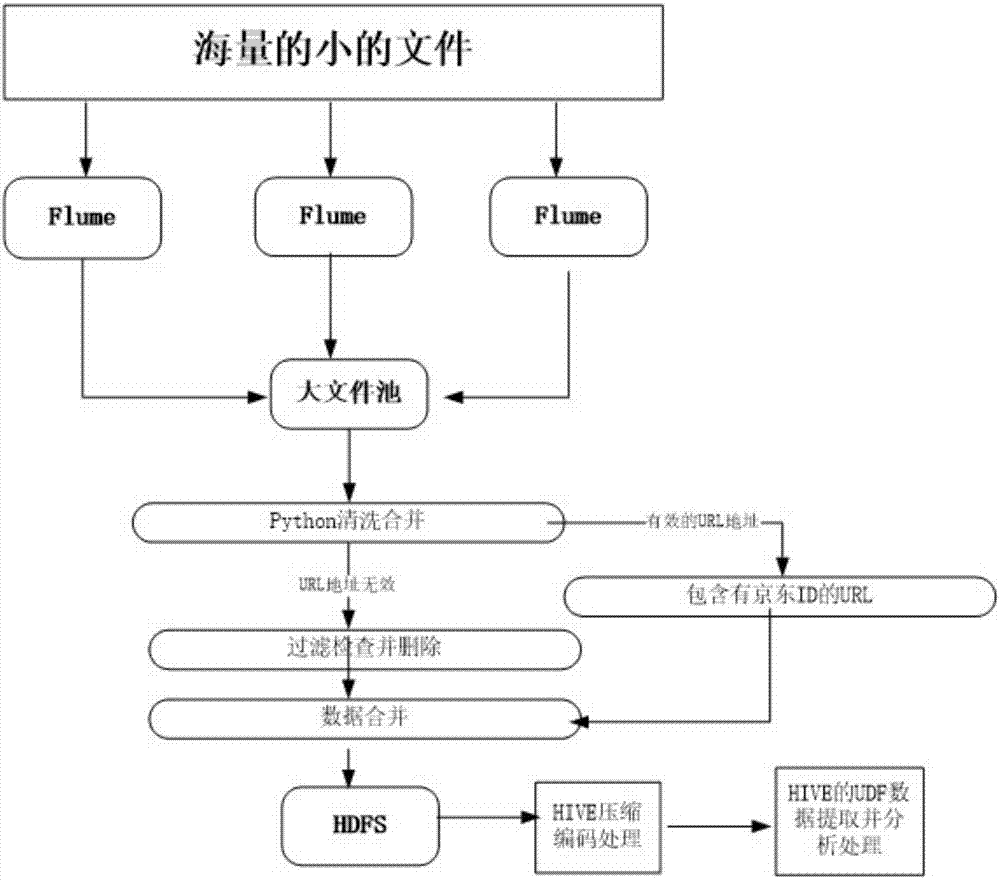
图2是本发明实施例一的数据流程图。
具体实施方式
本发明可用于高效客户端id以精准到用户的区域访问情况,为用户带来更优质的服务,解决了现有技术直接访问客户端id会消耗大量资源和内存且效率低下的问题。
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
实施例一
如图1和图2所示,从url中高效提取用户客户端id的方法包括如下步骤:
s1:通过日志文件收集单元收集日志文件的数据并存入文件池;
其中日志收集单元为能够对分布式的海量日志文件进行采集、聚合和传输的flume系统。
flume系统是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
url:统一资源定位符,是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的url,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
s2:通过hive中的etl对步骤s1中收集到的数据进行预处理,并将预处理好的数据收集到hadoop集群中以将数据进行结构化处理。
其中,为了将数据结构化处理,需要通过hive建立数据文件的表结构,所以,通过实现hive和hdfs建表关联以完成数据结构化处理,其中hive和hdfs建表关联通过mysql管理完成,将数据保存在不同的表中,以增加速度并提高灵活性。
etl的程序部署于hadoop集群中,且etl的程序包括能够对数据进行清洗、合并、上传、高压缩编码和分布式提取的一系列程序。
hadoop:分布式系统基础构架,提供高吞吐量来访问应用程序的数据,适合有着超大数据集的应用程序;
其最核心的设计:hdfs和mapreduce,hdfs为海量的数据提供存储,则mapreduce为海量的数据提供计算。
hive:是apache开源的技术,数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本身是建立在apachehadoop之上,具体地说,hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为mapreduce任务进行运行。
hive的优点是学习成本低,可以通过类sql语句快速实现简单的mapreduce统计,不必开发专门的mapreduce应用,尤其适合本实施例需要的数据仓库的统计分析。
etl处理:用于描述将数据从源端经过抽取、转换、加载至目的端的过程。
进一步地,hadoop的分布式系统通过以下方法构建:
搭建部署有至少一台主机和至少一台从机的hadoop2.7.1的集群环境,对hive和hdfs的环境与配置进行配置,且将hivemetastore、mysql和hiveserver2组建在一台主机上,并对namenodeha和resourcemanagerha进行设置,设置参数以使分布式系统满足高可用性为准,且优选地,本实施例中部署4台主机和7台从机。
hivemetastore:关系数据库,用于存储表的元数据信息;
mysql:一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有数据放在一个大仓库内以增加速度并提高灵活性。
hiveserver2:hive服务器;
namenodeha:高可用性数据分发服务器;
resourcemanagerha:高配置资源管理器。
s3:通过hive的udf功能与从url中提取客户端id的功能相结合以提取客户端id。
udf:hive用户自定义函数。
本实施例中所说的客户端id主要指京东id,当然还可以是其他客户端的id,客户端包括网页客户端和应用程序客户端,例如百度id、微信id、淘宝id等。
具体地,在步骤s3中,通过以下方法将udf功能与从url中提取客户端id的功能相结合:
s3-1:为了进一步完成数据的提取,开发相对应的hive的对ip地址具有正常提取功能的udf函数使hive具有udf功能,udf函数具有能够正常提取ip地址的功能即可;
s3-2在本地连接hadoop集群,并在完成基于hive的从url中提取客户端id的程序后,通过udf函数编译完成与从url中提取客户端id的功能相结合。
为了添加负载均衡,在分布式系统的各节点搭建有tomcat分布式集群,并利用nginx对tomcat所在机器的流量进行调配,nginx是一种高性能的http和反向代理服务器,通过负载均衡的设计使集群中各台机器,包括主机和从机的流量实现均衡负载,提高各台机器的利用率,同时由于均衡了负载,提高了各台机器的处理速度。
进一步地,在步骤s3之后,还包括以下步骤:
在对提取的客户端id结果输出后对结果进行进一步分析和/或生成报表,例如,以京东id为例的报表格式如下:路由器、用户mac、京东id出现频次
下面是对报表进行原理分析:
不同的路由器地址,对应不同的url地址,通过关联到不同的家庭路由器mac,并计算出在不同路由器下的不同终端的出现次数,这样通过高效的分布式计算,能从海量的用户数据里得到京东用户真正的终端访问的情况,并以此精准到用户的区域访问情况,为用户带来更优质的服务。
进一步地,输出的结果通过可视化配置进行可视化显示,所述的可视化配置包括数据采集可视化、数据接入可视化、数据计算可视化和数据输出可视化中的任意一种或多种组合的配置,且对结果显示保持具有可定制化可视化的功能。
下面结合附图1,对本实施例的技术架构进行具体说明:
日志文件通过现有架构,例如flume系统架构、分布式系统基础构架等进行采集处理后存入本地大文件池,然后对文件进行积累、清洗、合并等预处理操作后上传至hadoop集群的hdfs,且上传至hdfs中的数据已利用hive本身具有的从url中提取客户端id功能对数据进行分布式提取以初步提取客户端id,同时,hive对tez计算框架发起计算请求,达到利用hive调用hadoop进行分布式计算来完成url中京东id的提取,效率高且消耗资源低。
其中,tez是apache最新的支持dag作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升dag作业的性能。tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序,在本实施例中用于扩展udf函数以使hive具有udf的自适应开发供,更精准的提取客户端id。hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合mapreduce,例如机器学习,tez的目的就是帮助hadoop处理这些用例场景。
tez项目的目标是支持高度定制化,这样它就能够满足各种用例的需要,让人们不必借助其他的外部方式就能完成自己的工作,如果hive和pig这样的项目使用tez而不是mapreduce作为其数据处理的骨干,那么将会显著提升它们的响应时间,tez构建在yarn之上,后者是hadoop所使用的新资源管理框架。
下面结合附图2,对本实施例进行具体说明:
分布式的海量的日志的小文件通过flume系统进行采集、聚合,并将其传输到大文件池,然后使用python语言设计的etl程序对数据进行清洗和合并以分筛处有效的url地址和无效的url地址,并对无效的url地址进行过滤检查处理,对不合格的url地址进行删除处理,且有效的url地址是指包含有指定客户端id的url,且将经过处理的无效的url地址与有效的url地址进行数据合并以初步完成数据的提取,之后将初步提取的数据上传至hdfs进行保存,然后通过etl对数据压缩编码处理后采用udf的自适应开发功能对数据进行进一步提取。
本实施例通过hadoop分布式架构,将从url中提取用户客户端id的功能与hive的udf功能相集成,实现完成对用户客户端id的高效提取,能从海量的用户数据里得到指定客户端用户真正的终端访问的情况,并以此精准到用户的区域访问情况,为用户带来更优质的服务。
实施例二
本实施例提出了一种基于从url中高效提取用户客户端id的方法的系统。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
尽管本文较多地使用了hive、udf功能、hadoop集群、mysql等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
- 还没有人留言评论。精彩留言会获得点赞!