一种基于时间窗口和语义的变体词规范化的方法和系统与流程
本发明涉及社交网络数据分析领域,是一种基于时间窗口和语义的变体词规范化的方法,以实现更有针对性、准确性的社交网络中变体词的规范化的方法和系统。
背景技术:
随着社交网络的飞速发展,每天有亿级的信息发布在社交网络平台中,带来了信息的爆炸式增长。信息的形式多种多样,包括文本、图片、音频、视频等。其中社交网络中的文本具有随意性、非正规性等特点。变体词就是网络语言作为一种不规范语言的显著特色,人们往往处于避免审查、表达情感、讽刺、娱乐等需求将相对严肃、规范、敏感的词用相对不规范、不敏感的词来代替,用来代替原来词的新词就叫做变体词(morph)。变体词和其对应的原来的词(目标实体词)会分别在非规范文本和规范文本中共存,甚至变体词会渗透到规范文本中。变体词使行文更加生动活泼,相关事件、消息也传播得更加广泛。但是因为变体词通常是某种隐喻,已不再是其表面字词的意义了,从而使网络上文体与正式文本(如新闻)具有巨大的差异。由此如何识别出这些变体词所对应的目标实体词,即规范化,对于下游的自然语言处理技术具有重要的意义。进一步,研究变体词的规范化对于舆情分析、热点事件追踪等都有重要意义。
变体词的规范化
变体词规范化指变体词的解析,即找到变体词所对应的目标实体词。
形式化描述如下:已知文档集合d={d1,d2,…,d|d|},文档集合d中唯一词集合为t={t1,t2,…,t|t|},定义候选的变体词m′j是t中的一个唯一词tj。则定义一个候选变体词的提及(morphmention)
这里需要注意如果一个提及的表面形式是与mi相同的,但是如果其指向其原来的含义,那么就不认为是变体词的提及。
例如:如果词语“小马哥”通过上下文获知其指向的是香港电影《英雄本色》里的一角色,则就不是一个变体词的提及;但是如果其指向的是一公司总裁马某某,则认为是一个变体词的提及。
因此变体词规范化任务是针对每一个变体词提及
最终目标是获得变体词对应的目标实体词。
变体词的特点
1)变体词可以看作是一种利用自然语言处理技术来传播秘密消息的一种手段。绝大多数的变体词可以看作是基于深层语义和背景知识的编码,而不是简单的字典式的替换,因此变体词更接近于行话、黑话、术语等。
2)变体词与目标实体词之间的映射关系不是全射关系,也即不是标准的对应关系,多个变体词可以对应一个目标实体词,一个目标实体词也可以对应多个变体词。
3)社交网络平台对变体词的产生和发展起着至关重要的推动作用。社交网络作为一种自媒体,更是激发了广大群众的创造欲望、集成了广大群众的集体智慧。众多流行的变体词都是互联网上普通用户自发创造获得广泛传播的。
4)变体词随着时间的推移迅速演化。根据新的新闻热点、特殊事件,会不断地产生新的变体词,这是变体词的一大特点,也反应到了变体词的生成规律上。有些变体词会逐步消亡,而有些甚至进入了规范的文本中获得更广泛的认可。
变体词规范化的研究现状
明确的变体词概念出现在huang的论文中(参考huang,hongzhao,etal."resolvingentitymorphsincensoreddata."acl(1).2013),但是变体词相关的概念和技术一直在不良文本过滤、社交媒体文本规范化等领域有所体现。下面主要从规范化技术角度详细阐述变体词规范化的发现现状。
1)基于规则的规范化方法
最早与变体词相关的研究主要有网络不良文本的过滤技术,前期主要使用精确匹配、分类器等方法。但是发现变体词的出现会严重影响到过滤的准确度。因此逐步引入了对变体词的处理,如yoon将某特殊字符转化成形状相似的字母,然后再进行检测(参考yoont,parksy,chohg.asmartfilteringsystemfornewlycoinedprofanitiesbyusingapproximatestringalignment[c]//computerandinformationtechnology(cit),2010ieee10thinternationalconference.ieee,2010,643-650.)。例如:将特殊字符“!”转换成字母“i”,遇到“sh!t”词后,将这个词转换成“shit”来处理。
陈儒等人提出了面向中文特定关键词变体的过滤技术(参考:陈儒,张宇,刘挺.面向中文特定信息变异的过滤技术研究[j].高技术通讯,2005,15(9):7-12.),针对中文网络的5种变体方法提出了变异规则:1)对关键词进行同音字替换或拼音替换;2)对关键词进行拆分;3)在关键词中插入无意义的非汉字符合;4)关键词的组合;5)上述4种方法的组合。
sood在对不良文本及其变体信息进行检测的时候,利用了"众包"的思想,使用"众包"来对文本进行标记,采用机器学习的技术来对不良文本信息过滤,通过采用bigram、词干等作为特征值来对文本信息做分类分析,以检测不良信息(参考soods0,antinj,churchillef.usingcrowdsourcingtoimproveprofanitydetection[c]//aaaispringsymposiumseries.2012:69-74.)。
xia和wong考虑中文聊天室等环境下动态非规范语言的规范化问题,以标准汉语语料库为基础建立了汉字的语音映射模型,对信源/信道模型进行扩展(extendedsourcechannelmodel,xscm),然后基于汉字语音之间的相似度进行替换,但需要手工确定相似度的权重(参考yunqingxia,kam-faiwong,andwenjieli.2006.aphonetic-basedapproachtochinesechattextnor-malization.inproceedingsofcoling-acl2006,pages993–1000.;k.f.wongandy.xia.2008.normalizationofchinesechatlanguage.languageresourcesandevaluation,pages219–242)。
2)基于统计和规则的规范化方法
wang从非规范词的规范化角度(参考aobowang,min-yenkan,danielandrade,takashionishi,andkaiishikawa.2013.chineseinformalwordnormalization:anexperimentalstudy.inproceedingsofinternationaljointconferenceonnatu-rallanguageprocessing(ijcnlp2013)),首先提取统计特征和基于规则的特征,通过分类实现中文非规范词的规范化。通过语音建立了汉字-汉字之间的映射关系,通过缩写建立了汉字-词的映射关系,通过意译建立了字-词,词-词的映射关系。
choudhury针对sms文本,提出了一种基于隐马尔可夫模型的文本规范化方法(参考mchoudhury,rsaraf,vjain,et.al.investigationandmodelingofthestructureoftextinglanguage[j].internationjournalofdocumentanalysisandrecognition,2007,10:157-174.),该方法是一对一的规范化方法,通过构造常用缩写和非规范用法的词典,可以部分解决一对多的问题。cook通过引入无监督的噪声信道模型对choudhury提出的模型进行了扩展,模型对常用缩写形式和各种不同的拼写错误类型进行了概率建模。
还有通过构建规范化词典用于文本规范化任务。例如,han首先训练分类器用于识别非规范词候选,然后使用词音相似度得到规范化候选,最后利用字面相似度和上下文特征找出最佳的规范化候选(参考bhan,pcook,tbaldwin.automaticallyconstructinganormalizationdictionaryformicroblogs[c]//proceedingsofthe2012jointconferenceonempiricalmethodsinnaturallanguageprocessingandcomputationalnaturallanguagelearning,2012:421-432)。han又提出基于上下文相似性和字面相似性构建规范化词典进行推特文本的规范化,使用词袋模型表示上下文分布,然后两两之间计算上下文分布相似度(参考bhan,tbaldwin.lexicalnormalizationofshorttextmessages:maknsensa#twitter[c]//proceedingsofthe49thannualmeetingoftheassociationforcomputationallinguistics:humanlanguagetechnologies,2011,1:368-378.)。
li提出了一个基于规则和数据驱动的对数线性模型从互联网语料中对规范与非规范中文短语的关系进行挖掘和建模(参考zhifeilianddavidyarowsky.2008.miningandmodelingrelationsbetweenformalandinformalchinesephrasesfromwebcorpora.inproceedingsofconferenceonempiricalmethodsinnaturallanguageprocessing(emnlp2008),pages1031–1040.)。他们主要针对同音异形异义词、缩略语、首字母缩写词、音译等。
他们注意到一个现象,在非规范短语附近有时可以发现对应的规范短语,他们分为直接定义和间接定义。1)直接定义,如:“gf就是女朋友的意思”;2)间接的定义,如在聊天室中:a:“对不起,我先下线了。”b:“拜拜”。a:“88”。
li提出的非规范词规范化的bootstrapping算法步骤如下:给定一个非规范词,利用搜索引擎搜索含有此非规范词的非规范文本(如博客、社交网络上的文本)。产生候选规范化词集,在含有非规范词的一定长度窗口内提取n-gram。基于正则化条件对数似然对候选集进行打分排序。规则驱动提取的特征包括:两者拼音之间的levenshtein距离;两者拼音之间不同字符数;非规范词是否是规范词的拼音缩写;非规范词是否是规范词的汉字缩写。数据驱动提取的特征包括:两者共现频率;两者共现是否符合某一模式;搜索引擎搜索同时含有两者的网页数目。
li主要是通过搜索引擎来发现非规范词-规范词对。此方法对于定义良好和高频的词效果比较好,而且严重依赖于搜索引擎返回的结果。
3)基于语义表示的识别和规范化方法
现有从语义角度入手变体词的识别与规范化的主要是基于分布假设和语义组合假设。1954年,harris提出分布假说(distributionalhypothesis),即“上下文相似的词,其语义也相似”(参考zelligsharris.distributionalstructure.word,1954.)。德国数学家弗雷格(gottlobfrege)在1892年提出:一段话的语义由其各组成部分的语义以及它们之间的组合方法所确定(参考gottlobfrege.
基于分布假设,给定一个变体词,如果另一个词与之上下文相似,则可以初步推断这个词很可能就是变体词的目标实体词。而上下文语义的获取则可以基于语义组合的方式。
huang等人研究在给定变体词的情况下,挖掘跨数据源可比较语料的时空限制,找到对应的目标实体词。其基本框架如图1所示。给定一个变体词查询,获取多数据源的数据,进行对比分析,基于语义标注找到候选目标词集,然后根据:表面特征(surfacefeatures)、语义特征(semanticfeatures)、社交特征(socialfeatures)等对候选目标词集进行打分,最终获得目标实体词。
其中表面特征包括:字符串编辑距离,正则化字符串编辑距离,最长公共子串。语义特征指构建了信息网络(informationnetwork)。其中节点代表变体词(m);实体(e),包括候选的目标实体词;事件(ev);非实体名词(np);边代表两者共现,边权重为其在所有推文中的共现频率。基于meta-path进行语义相似性比较。社会特征:对用户的行为建模,用社交行为的相关性来辅助语义相似性测量。因为观察发现变体词和对应目标实体词的用户往往具有相似兴趣和观点意见。
huang的主要贡献在于:根据一定时间窗口内变体词和目标实体词是相关;根据社交媒体的动态特性提取变体词和目标实体词的时空分布;对多个数据源数据进行对比分析;对用户的行为建模,用社交行为的相关性来辅助语义相似性测量。其不足主要在于:此方法是在给定变体词的情况下,并且使用了大量的标注数据。此方法做到了语料级别,但是不是提及级别。此方法严重依赖于变体词的多个实例的聚合上下文和时空信息。
zhang等人采用无监督的方法(参考zhang,boliang,etal."context-awareentitymorphdecoding."proc.annualmeetingoftheassociationforcomputationallinguistics(acl2015).2015),基于深度学习实现对变体词及其目标实体词的映射关系的发现。文章把变体词的识别和规范化分成如下步骤:
1.先初筛出单个变体词提及(metion)的候选集。
a)潜在变体词的发现:基于4类特征(基本特征、特征字典、语音、语言模型)的分类问题来发现潜在的变体词。
b)潜在变体词的验证:基于2个假设:1)如果2个提及是共指的,则2者要么都是变体词的提及,要么都不是;2)高度相关的提及要么都是变体词的提及,要么就都不是。基于上述2个假设提出了一个半监督的学习方法利用小规模已标注数据集对大规模未标注数据集的变体词提及进行验证。
2.变体词的规范化(发现其目标实体词)。主要通过深度学习技术来捕捉比较一个变体词和它的候选目标实体词语义表示。
a)候选目标实体词的识别:主要是基于huang的时空分布假设:变体词及其目标实体词应该有相似的时空分布。文章采用的标准:在变体词出现的7天之内应该可以找到变体词的目标实体词;
b)候选目标实体词的打分排序:基于深度学习技术习得变体词及其目标实体词的语义表示,文章提出了2种算法,并且比较两者的效果。
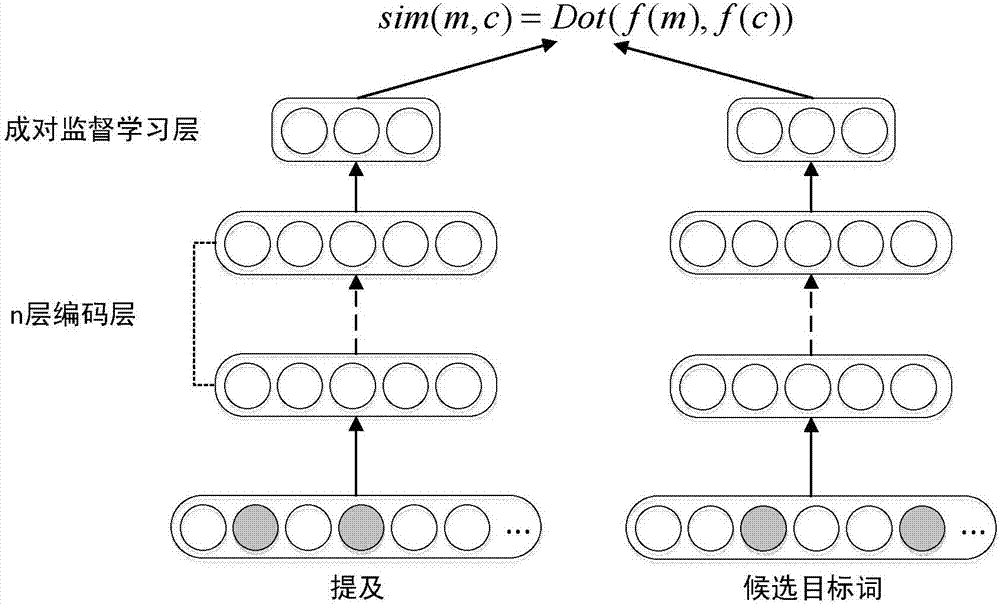
首先是基于多数据源的监督学习,如图2所示。但是效果不好,因为建立词向量的时候主要是采用wikipedia的数据进行训练,但是wikipedia和含有变体词的社交媒体文本有很大的不同。
第2个模型采用的如图3所示的连续词袋模型。利用连续词袋模型训练推文,获得变体词和实体词的语义表示,比较两者的相似度。
变体词规范化的评测标准
一个社区发现算法的效果如何,需要在具体的网络上进行测试。当前,社区发现算法的测试网络主要有人工构造的网络和真实的网络。
人工测试集的典型代表有girvan与newman提出的标准测试集和lancichinetti等人提出的更为严格的测试集。标准测试集是对人工l-分割模型的一种实现,它规定网络中的结点组数l=4,每个组的节点数为32,则顶点总数为128,同时规定节点的平均度<k>=16。通过调整zin和zout的值,可以调整网络社区结构的显著程度。其中zin表示结点连接同一社区内点的平均边数,zout表示连接不同社区的点的边数。显然有zin+zout=<k>。标准测试集里隐含着这样的假设:网络里节点和社区是同质的。这与现实网络的特性是不符合的。因此,lancichinetti等人提出了新的测试集,用于解决节点度和社团规模的异质性问题。在该测试集中,节点度和社团规模都服从幂律分布,混淆参数μ用于控制社区结构的显著程度。
真实的网络测试集是那些根据人们的观察和知识而得到社区结构划分的现实网络。当前,用得比较广泛的有zachary空手道俱乐部网络,lusseau等人提供的宽吻海豚的社会关系网络以及根据美国大学橄榄球队之间的比赛关系构建的网络。真实的网络测试集存在的一个重要问题是:已知的社区结构是根据人们的观察和经验获得,而社区发现算法一般从拓扑结构入手,无法预知两者之间有多大的关联。
有了测试集之后,还需要有相应的方法来度量社区发现算法获得的社区结构和网络已知社区结构之间的相似程度。最简单的方法是以节点正确划分的比例来衡量,而当前使用的最广泛的划分相似度度量方法是归一化互信息、信息变差等。
对于扩展了主题的社区发现,可以采用社区的平均主题相似性作为衡量一个社区内部成员的紧密程度的标准。一个社区的平均主题相似值越大,说明社区中成员的共同兴趣越一致,该社区划分越合理。
技术实现要素:
本发明的目的是提供一种基于时间窗口和语义的变体词规范化的方法和系统。本发明基于时间窗口和语义来对社交网络上的变体词进行规范化操作,使得社交网络的文本变的更加规范,为接下来对于社交网络的舆情分析、热点时间追踪等分析操作做准备。
当前变体词的规范化需要迫切解决的问题主要有:
1)找到高质量的候选目标词集合。
2)提高变体词规范化的准确度。
以上2点其本质问题就是要加深对变体词的理解。这里以往都是强调变体词与目标实体词的相似性,实际上需要从相似性和差异性两个角度进行思考。即首先对变体词的生成规律的理解,需要从相似性和差异性两个方面来对变体词及其目标实体词进行对比分析:
1)变体词和目标实体词的相同之处:只有识别出了变体词和目标实体词的相同之处,才可能找到变体词所对应的目标实体词。
a)首先变体词的语义和目标实体词的语义应该是一致的,这也是变体词能够产生的原因。变体词和目标实体词的语义相似性主要体现在文档级别、句子级别和字的级别。而词级别的应该主要是体现变体词和目标实体词之间的差异性。
b)变体词的字面组合(surfacename)与目标实体词应该也具有一定相似性,其字面组合的意义也可以用来辅助对变体词的目标实体词的发现。既然出现了surfacename,也就是说既然使用了变体词指向目标实体词,则说明surfacename与目标实体词之间有一定相同\相似的特征,因此需要基于语义表示来研究变体词的surfacename与目标实体词之间的共同特征以及在图上、词向量空间上如何展示的。
2)变体词和目标实体词的不同之处:只有识别出变体词和目标实体词的不同之处,才可能在语料中找到变体词。
a)两者之间的差异性应该主要体现在语义表示上的词的级别。这种差异性主要体现在语义上,而上层文档、句子的语义相似性可以提供发现这种差异性的线索,而知识图谱、社交媒体的关系也可以提供辅助信息,加快这种搜索的过程。
以往只强调了变体词和目标实体词的相似性,实际上应该是相似性和差异性的权衡,即“存大同,求小异”,这样才能体现变体词和目标实体词之间的微妙的关系。
因此在充分研究两者相似性和差异性基础上,总结出变体词的特性和使用变体词的规律,然后才能提到识别的方法。因此需要对变体词及其目标实体词的特征进行分析,分析语义表示中各节点之间的相似性和差异性。在获得变体词和目标实体词之间的相似性和差异性之后,进一步依托句子、文档级的语义表示,研究变体词和目标实体词的使用环境的相似性和差异性。
为了能够准确地解析出变体词的目标实体词,首先需要对变体词及其目标实体词准确地给出语义上的描述,能体现两者的深层语义联系(这样才能解析出其目标实体词)。因此首先要研究能够体现这种“求大同,存小异”的合适的语义描述,可以通过神经网络分别构建字/词级别、句子级别和文档级别的语义表示来体现这种“大同,小异”。
因此需要在表达能力强的语义表示基础上,充分利用多源多维度的信息,充分利用社交媒体的关系信息,利用相关知识图谱的先验知识,以提高识别的准确度。
基于此,为了实现对社交网络中变体词的有效规范化,本发明提出了一种基于时间窗口和语义的变体词规范化方法和系统。
本发明主要包括两个方面:(1)提出了基于时空分布的候选词提取模型和基于语义相似度的候选词提取模型;(2)提出了一种基于时间窗口和语义的变体词规范化方法和系统。
该发明包括以下内容:
1)社交网络中候选词的发现。在大规模语料库中提取出与给定变体词所匹配的可能的实体词。先是给语料分块。本发明借助变体词的时间分布以及变体词所在句子的语义,在大规模语料库中挑选出合适的语料,然后基于一些分词和词性标注等工具,提取合适的词语加入候选目标实体词集合中。
2)社交网络中候选词的排序。通过计算候选词和变体词字面相似度和上下文语义特征相似度进行排序。对于有监督的机器学习方法,挑选合适的特征,对候选词在当前上下文背景下,计算变体词-候选词得分或相对排序。对于无监督的机器学习方法,利用神经网络在大规模语料库中自主学习词语的上下文语义表示计算得分或相对排序。
3)基于时间窗口和语义的变体词规范化方法和系统。在第一阶段,拟采用基于时空分布并结合文档语义相似度,聚合语料,弥补候选词结合过大或过小的缺点;在第二阶段,拟采用机器学习的算法,挖掘词项上下文中的可用特征,结合词项或字的表面特征,构建候选词排序模型。采取神经网络语言模型,在大规模语料上训练词表示,然后计算相似度排序。
与现有技术相比,本发明的积极效果为:
1、充分利用变体词所在社交网络文本的时间和上下文语义,极大缩小了候选目标词的规模。
2、分析了变体词和目标词之间的异同之处,结合变体词和候选目标词的上下文以及组成词语的字的信息,通过字词联合训练出词语的语义表示,对候选目标词进行排序。
附图说明
图1为变体词的识别与解析流程图;
图2为多数据源的监督学习;
图3为连续词袋模型;
图4为候选词集合提取模块架构图;
图5为候选词排序模块架构图;
图6为变体词规范化架构图;
图7为候选目标词获取框架图;
图8为候选目标词排序框架图。
具体实施方式
本发明的变体词规范化架构如图6所示,具体步骤如下:
(一)社交网络候选词发现。具体可以分为两个步骤:
候选词提取模块的模块架构如图4所示,该实验方案能够弥补前文分析的候选词集合过大或过小的缺点。
实验步骤如下:
1)语料库的划分
a)按时间划分,基于时空分布假设,在变体词出现的时间前7天内,根据语料库每条微博的时间,划分出一个候选语料库集合d1。
b)按语义划分,基于语义相似假设,将候选语料库集合d1中和变体词出现的微博语义较相似的微博加入到候选语料库集合d2。计算相似度的方法是基于lda(latentdirichletallocation)文本相似性计算方法和基于doc2vec的文本相似性计算方法。
2)候选词的识别提取
在候选语料库集合d2中,运用多种工具提取出候选词,如:分词工具、词性标注、名词词组检测、命名实体标注、事件提取等。然后综合上述工具得出的结果,本发明取结果集的并集作为本发明最后的候选词集合。
(二)社交网络候选词的排序
候选词排序即对上述提取出的候选词集合中的所有词进行打分并排序,如图5所示:
1)有监督的方式
对候选词是否是变体词对应的目标词建立分类模型。现有的方法是根据如下4类特征:表面特征(surfacefeatures)、语义特征(semanticfeatures)、社交特征(socialfeatures)等对候选目标词集进行打分,最终获得目标实体词。
2)无监督的方式
现有的方法是在大规模语料库上用word2vector模型学习词语的语义表示,然后计算变体词和候选词的语义相似度,从而根据相似度进行排序。一方面现有的方法没有考虑到词语中的字的表示,但是本发明考虑到大多数变体词和目标词在字的层面上会有共同点,所以在大规模语料库中训练词和字联合表示可能会有所提高。另一方面可以利用其它神经网络模型,比如记忆网络,在候选的语料库中自己学习到目标词。
本发明采用无监督的方式对候选目标词进行排序,考虑到大多数变体词和目标词在字的层面上具有相同字的特点,所以在训练词向量的时候,将一个词语拆分成两部分:词语本身和组成这个词语的汉字。本发明采用cwe模型训练词向量,加入组成词语的字的信息构成这个词语的语义表示。
在变体词候选目标词排序任务中,cwe模型有以下亮点优势:
(1)cwe模型输出的是融合了字向量信息的词向量。一些变体词会基于目标词中的某些字而形成,如变体词“吃省”,它的目标词是“广东省”,此时变体词和目标词有一个共同的“省”字,词向量表示中加入字向量后,在变体词的候选目标词排序中,cwe模型因为能更有效地计算变体词和目标词的相似度而使得排序结果更加准确。
(2)cwe模型单独输出了字向量。我们可以通过组合字的向量来合成未登录词的词向量,然后可以计算新的变体词和候选目标词之间的相似度,而不用重新训练词向量模型,减少了重新训练词向量所带来的时间开销成本。
(三)基于时间窗口和语义的社交网络变体词规范化方法和系统
在时间属性和语义属性上,获取到变体词候选集,且对候选词打分排序的基础上,实现基于时间窗口和语义的社交网络变体词规范化方法和系统。
a)社交网络中变体词规范化方法:根据当前变体词规范化方法的相关研究现状,本方法采用先根据时间和语义属性来划分候选集的方式,来发现并提取候选词、排序候选词来实现变体词的规范化。
b)社交网络中变体词规范化系统:系统由目标候选词发现模块,目标候选词排序模块构成。
由此实现了基于时间窗口和语义的变体词规范化方法和系统。
社交网络变体词规范化方法和系统有两部分组成:1)候选目标词获取框架;2)候选目标词排序框架。
候选目标词获取框架由3部分组成:采集模块,过滤模块和获取模块,如图7所示。各模块主要功能如下:
采集模块:主要负责获取社交网络文本数据,如新浪微博消息数据,twitter中文消息数据和web新闻等。
过滤模块:这是获取框架中的重点部分,分为根据时间窗口过滤和根据话题相似过滤。
获取模块:主要负责对上述过滤后的语料进行分词和词性标注等,提取出需要的候选词。
候选目标词排序框架由3部分组成:分词模块,词向量训练模块和相似度计算模块。
如图8所示,各模块主要功能如下:
分词模块:主要负责给输入的语料(如新浪微博等)进行分词处理,将之作为词向量训练的输入。
词向量训练模块:这是排序框架中的重点部分,其中本文采用了两种字词联合训练方法:融合字信息的词向量法(cwe)模型和融合偏旁信息的词向量法(mge)模型。
相似度计算模块:主要负责对变体词和候选目标词的词向量进行余弦相似度计算,并对候选目标词进行排序操作。
由此实现了基于时间窗口和语义的变体词规范化方法和系统。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者同等替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求所述为准。
- 还没有人留言评论。精彩留言会获得点赞!