基于球状鲁棒序列局部二值化模式的序列分类方法与流程
本发明属于图像处理技术领域,特别涉及一种极光序列分类方法,可用于极光序列特征提取、极光序列时间分类及行星际磁场参数研究。
背景技术:
极光是来自磁层的高能粒子沉降到高层大气并与中性成分碰撞激发的一种大气发光现象,是太阳风-磁层-电离层耦合造成的地球高纬活动的重要表现形式之一。人们通过极光形态及其演化的系统观测可以获得磁层和日地空间电磁活动的大量信息,有助于深入研究太阳活动对地球的影响方式与程度,对了解空间天气过程的变化规律具有重要意义。
随着不断深入地研究极光形态特征以及极光光谱学的出现,人们对不同极光的物理特征及其产生机制的研究也越来越关注。早期的极光分类只是单一地依据观察到的极光的各种视觉形式。simmons于1998年在文章“aclassificationofauroraltypes,journalofthebritishastronomicalassociation,108(5),247-257.”中提出了目前不同类型的极光的分类是根据他们的地球物理的特征以及对每一个类型的大多数典型特征的详细描述是特别的参照了地磁的纬度和地磁的时间扇区和极光产生的机制。根据他提供的分类标准可以帮助研究者从地球物理的方面阐明这些极光的各种类型之间的相似和不同,对极光的不同类型都有了清楚的定义。hu等人在文章“synopticdistributionofdaysideaurora:multiple-wavelengthall-skyobservationatyellowriverstationin
过去的很多年中,研究者将机器学习、计算机视觉与极光数据的分类、显著性提取等相结合,并且针对极光数据的特殊性采取了不同的特征提取方式,并在此过程中发现局部二值化模式和序列局部二值化模式对极光数据具有极好的表征性。但是已有的局部二值化模式由于没有考虑时间维度和空间维度上的像素点对当前帧贡献率的不同,造成分类准确率不够高和时间复杂度不够低的不足。
技术实现要素:
本发明的目的在于提出一种基于球状鲁棒序列局部二值化模式的序列分类方法,以提高极光序列的分类准确率,降低时间复杂度。
本发明的技术方案是在原有的序列局部二值化模式vlbp的基础上分别对权值分配和像素点选取方式进行改进,以此获得对极光序列具有更强表征性的特征,进而提高极光序列的分类效果,其实现步骤包括如下:
(1)根据极光形态特征手动从全天空极光数据中选取三种极光数据,即弧状极光数据,辐射状极光数据,帷幔状极光数据,每种数据中的序列长度为15帧到50帧之间,从每类数据中分别随机选取n段序列作为训练数据,其余的作为测试数据,n>=100;
(2)计算训练数据序列的球状鲁棒序列局部二值化编码值v:
2a)选取当前帧和前后帧的邻域像素点,并计算前后帧邻域像素点的均值g′t±1,c;
2b)用当前帧的邻域像素点计算二值化阈值tdc;
2c)用二值化阈值tdc计算当前帧的二值化编码vt,并计算其旋转不变性二值化编码vtrbt;
2d)用二值化阈值tdc对前后帧的像素点均值g′t±1,c计算其二值化编码vt±1;
2e)结合当前帧的旋转不变性二值化编码vtrbt和前后帧的二值化编码vt±1得到球状鲁棒序列局部二值化编码v;
2f)对训练数据球状鲁棒序列局部二值化编码值v进行直方图统计,得到训练数据序列的特征向量fij,其中i是训练数据中的序列标号,j是标签;
(3)将训练数据序列的标签j和球状鲁棒序列局部二值化编码值对应的特征向量fij输入到svm中进行训练得到训练模型;
(4)求出测试数据序列的球状鲁棒序列局部二值化编码值h,并进行直方图统计得到测试数据序列的特征向量fm,其中m是测试数据中的序列标号;
(5)将测试数据序列的球状鲁棒序列局部二值化编码值对应的特征向量fm输入到训练好的svm模型中,得到测试数据序列的分类结果。
本发明由于在原有的序列局部二值化模式vlbp的基础上分别对权值分配和像素点选取方式进行改进,即分别对空间维度上相邻像素点对中心像素点的距离h和时间维度上相邻像素点对中心像素点的距离r进行量化,同时对时间维度和空间维度上选取的邻域像素点对中心像素点的表征贡献率进行调整,使其成为更合理的权重优化分配方式,以此获得了对极光序列具有更强表征性的特征,进而提高了极光序列的分类效果。
附图说明
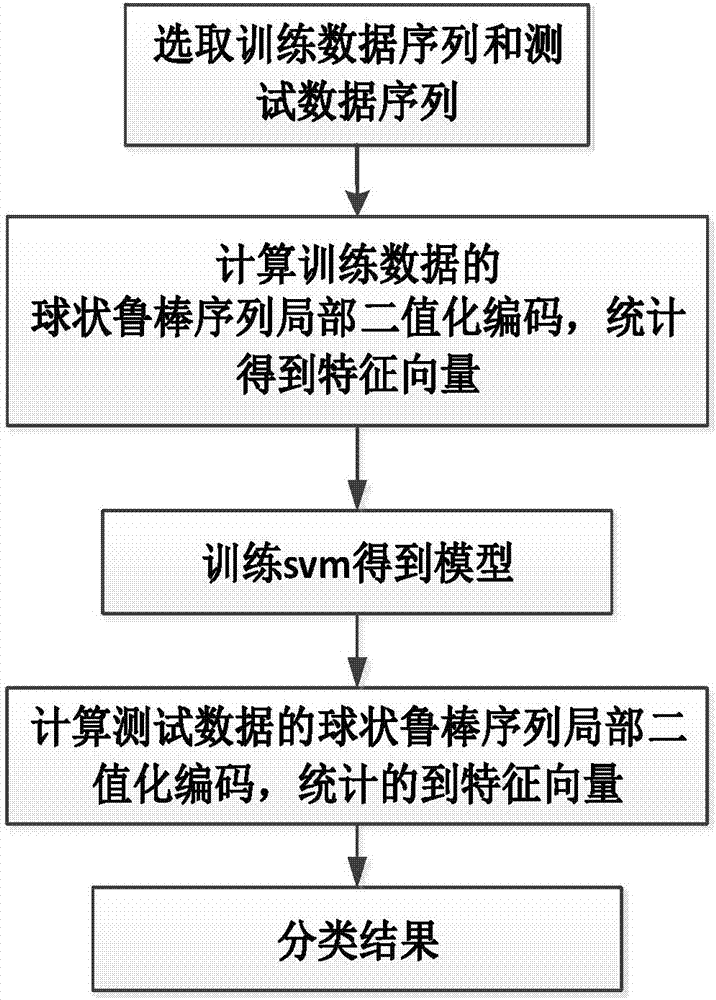
图1是本发明的实现流程图;
图2是本发明中的序列特征提取示意图;
图3是用本发明对取不同权值比重
图4是用本发明对取不同邻域像素点个数f和维度距离比值h/r的分类准确率图。
具体实施方式
以下结合附图对本发明的内容和效果进行进一步描述。
参照图1,本实例的具体实现步骤如下:
步骤1:选取训练数据和测试数据。
根据极光形态特征手动从全天空极光数据中选取三种极光数据,即弧状极光数据,辐射状极光数据,帷幔状极光数据,每种数据中的序列长度为15帧到50帧之间;从每类数据中分别随机选取n段序列作为训练数据,其余的作为测试数据,n>=100。
步骤2:计算训练数据序列的编码值v,获得训练数据序列的特征向量fij。
现有的计算序列的编码值方法有序列局部二值化模式vlbp,本发明采用球状鲁棒序列局部二值化模式。
参照图2,本实现的具体实现如下:
2a)选取当前帧和前后帧的邻域像素点,并计算前后帧邻域像素点的均值gt’±1,c;
2a1)以训练数据序列中第t帧qt中的某个像素点wc为中心像素点,设该中心像素点的像素值为gt,c,坐标为(xc,yc,t);在第t帧qt上围绕中心像素点wc以r为半径的圆上选取f个像素点作为邻域像素点gt,f,坐标为:
((xc+rcos(2πf/f)),(yc+rsin(2πf/f)),t),f=1,2,...,f;
2a2)设第t帧与其之前的第t-1帧和与其之后的第t+1帧之间在时间维度上的距离为h,根据h与空间维度上距离r的大小不同,选取不同个数的邻域像素点gt±1,c和gt±1,f’得到这两种邻域像素点的坐标,即:
gt±1,c的坐标为:(xc,yc,t±1),
gt±1,f坐标为:
其中,
2a3)分别求第t-1帧和第t+1帧上邻域像素点的均值,作为第t-1帧和第t+1帧的像素值g′t±1,c;
2b)根据第t帧中心像素点gt,c和邻域像素点gt,f求二值化阈值tdc:
其中,
2c)用二值化阈值tdc计算当前帧的二值化编码vt,并计算其旋转不变性二值化编码vtrbt;
2c1)用二值化阈值tdc对第t帧f个邻域像素值gt,f进行二值化编码,得到第t帧的二值化编码值vt:
vt=vt(s(gt,1-tdc),...,s(gt,f-tdc),...,s(gt,f-tdc)),f=1,2,...,f
其中s(gt,f-tdc)表示用二值化阈值tdc对像素值gt,f进行二值化编码得到的像素点编码值,
2c2)求第t帧的二值化编码值vt对应的具有旋转不变性的二进制编码值vtrbt:
vtrbt=min{rot(vt,k)},k=0,1,...,(f-1)
其中,rot(vt,k)表示将第t帧的二进制编码值vt沿顺时针方向旋转了k次后所得到的二进制编码值,min{rot(vt,k)}表示第t帧的二进制编码值vt沿顺时针方向旋转了k,k=0,1,...,(f-1)次后所得到f个二进制编码值的最小值;
2d)用二值化阈值tdc对第t-1帧和第t+1帧的像素值g′t±1,c进行二值化编码,得到前后帧二值化编码值vt±1:
vt±1=vt±1(s(g′t-1,c-tdc),s(g′t+1,c-tdc)),
其中s(g′t±1,c-tdc)表示用二值化阈值tdc对像素值g′t±1,c进行二值化编码得到的像素点编码值,
2e)结合第t帧旋转不变性的二进制编码值vtrbt和其前后帧二值化编码值vt±1得到最终的球状鲁棒序列局部二值化编码值v:
v=v(vtrbt,vt±1)。
2f)对训练数据二值化编码值v进行直方图统计,获得训练数据序列的特征向量fij,其中i是训练数据中的序列标号,j是标签,
步骤3:训练svm分类器。
3a)将步骤2得到的每个训练数据序列的特征向量fij作为列向量,构成训练数据序列的特征矩阵tr,并用fij相应的标签j构成标签列向量r;
3b)将训练数据序列的特征矩阵tr和标签列向量r输入到svm分类器,对svm分类器的参数进行拟合,得到训练好的svm分类器。
步骤4:计算测试数据序列的编码值h,得到特征向量fm。
计算测试数据序列编码值h的过程与步骤2相同,最后得到测试数据序列的特征向量fm,其中m是测试数据中的序列标号。
步骤5:对测试数据序列分类。
5a)将步骤4得到的每个测试数据序列的特征向量fm作为列向量构成一个特征矩阵tr;
5b)将得到的特征矩阵tr输入到训练好的svm分类器,得到测试数据序列的分类结果。
本发明的效果通过以下仿真实验进一步说明:
1.仿真条件与方法:
硬件平台为:intelcorei5、2.93ghz、3.45gbram;
软件平台为:windows7操作系统下的matlabr2012b;
2.仿真内容及结果:
实验仿真1,取不同f和不同
由图3结果可以看出,比重
实验仿真2,取不同h/r和不同f,其中h/r是时间维度上的距离h和空间维度上距离r的比值,f是邻域像素点数,用本发明对极光序列进行分类,分类准确率如图4,其中,图4(a)是取f=4,不同的h/r对应的分类准确率,图(b)是取f=4,8,16时,分类准确率最高对应h/r值,图中h的下标是邻域像素点数f的值。
从图4可以看出,邻域像素点数f越多,时间维度和空间维度的距离比值h/r越小,均值像素点的值融合邻域像素点的信息越多,特征表达性越强,分类准确率越高。
实验仿真3,分别用本发明方法与现有vlbp方法对极光序列进行分类,分类准确率和时间归一化对比结果如表1。
表1本发明与vlbp对比结果
从表1中的实验结果中可以看出,本发明的分类准确率比vlbp有所提高,且在时间复杂度上有很大改善。
实验仿真4,用本发明方法分别对训练集序列个数n为30,60,90,120,150时进行分类,其准确率如表2所示。
表2极光序列分类准确率
从表2可以看出,当训练样本数超过150时,分类准确率为88.5%,本发明分类准确率较高,能够实现计算机对极光序列的自动分类。
- 还没有人留言评论。精彩留言会获得点赞!