大规模图片集中基于语义一致性的近似搜索方法与流程
本发明涉及一种在大规模图片数据集中对图片进行近似搜索的方法,属于机器学习技术领域。
背景技术:
近邻查询中一个重要的应用就是图片的近似搜索。在大数据时代,图片数据最明显的特点是数据规模极大,图片本身的特征维度很高。对于海量高维图片高效准确的近邻查询对计算机视觉、机器学习等前沿学科的研究有着极为重要的应用价值。
传统的近邻查询算法,比如基于树的索引结构的搜索算法,这种搜索算法都存在着维度的问题。由于对高维图片数据进行近似近邻搜索时性能急剧下滑,已不适用于当今的大数据时代。现在最为流行的方法是基于哈希技术的近似近邻搜索,经典的近似搜索哈希算法如局部敏感哈希算法(lsh),通过将近邻搜索问题转换为寻找相似的二进制编码来解决。基于哈希技术的近似搜索算法具有更为简单的索引结构和更少的存储空间。但是lsh为了同时保证精度和召回率,需要构建多个哈希表,导致查询时间和存储开销的大幅增加。
随之又出现了可以产生更为高效编码的哈希算法,一种基于图的哈希算法由于可以更好的度量图片样本之间的相似性从而能够获得更好的性能。比如谱哈希(sh)算法,锚哈希(agh)算法。但是这些算法在寻找近邻图片时过于片面,它们只考虑了图片在数据集中的实际存储位置,而没有考虑图片可能具有的语义标记信息,这样使得这些算法在图片近似搜索中的性能较差。在现实的大规模图片数据集中,很多图片具有语义标记信息,不同的类标记信息代表图片属于不同的类别。比如两张图片在数据集中可能实际存储距离较远,但是它们具有相同的类标记“天空”,那么这两张图片也是近似图片。而且目前流行的图片近似搜索算法应用在大规模图片数据集上时往往性能较差,不能很好的解决实际问题。
技术实现要素:
本发明所要解决的技术问题是:提供一种应用于大规模图片数据集中的基于语义一致性的近似图片搜索方法。主要解决图片的近似搜索问题并将相似的图片通过哈希技术映射成相同或相似的二进制编码。
本发明为解决上述技术问题采用以下技术方案:
本发明提出一种在大规模图片集中基于语义一致性的近似搜索方法,所述方法包括如下步骤:
步骤1:输入图片集样本矩阵x,并输入图片集对应的语义类标记矩阵y,其中x是n*d维的矩阵,y是n*c维的矩阵,n是图片样本的个数,d是图片特征的维度,c是类标记的数量;
步骤2:从图片集中随机抽取一部分图片作为抽样图片集;
步骤3:定义图片集与抽样图片集中的图片间的关系矩阵w,结合关系矩阵并引入语义一致性构建目标函数表达式,通过随机梯度下降算法迭代求解优化,待表达式收敛后即得到优化完成的转换矩阵a;
步骤4:对于每一个图片样本x,将转换矩阵a代入步骤3定义的关系矩阵中,得到关系矩阵的各个元素的值;通过关系矩阵构建出相似矩阵z,结合相似矩阵得到编码矩阵,对大规模图片数据集中的各图片利用编码矩阵进行哈希编码,将图片由原始的d维特征压缩映射成k维的二进制编码;
步骤5:对于一个新的查询图片q,通过编码矩阵计算出查询图片的二进制编码,与图片数据集中各图片的二进制编码比较汉明距离,如果汉明距离小于设定的门限阈值r,即认为两图片是近似图片。
进一步,本发明的近似搜索方法,转换矩阵a的计算过程如下:
步骤(1)、定义图片间的关系矩阵w是一个n*n维的矩阵,关系矩阵中的每一个元素定义为:
wij=exp(-||a(xi-uj)||2)(1)
上式中a表示转换矩阵,xi表示图片集中的第i张图片,uj表示抽样图片集中的第j张图片;
步骤(2)、定义目标函数式为:
其中,fi表示第i个图片样本的类标记向量,类标记向量是c维的列向量,向量中元素的值为1或0,分别表示图片属于这个类和不属于这个类,fj表示抽样图片集中图片的类标记向量,||fi-fj||2即是在训练转换矩阵时引入的语义一致性质;
步骤(3)、根据随机梯度下降算法优化转换矩阵a,迭代更新规则如下:
其中,γt是每次迭代过程中的优化步长,转换矩阵的初始值为i/δ,i是d*d维的单位矩阵,δ是图片集中各图片之间欧氏距离的中位数;
步骤(4)、图片集中所有的图片样本遍历结束后,即得到最终优化完成的转换矩阵a。
进一步,本发明的近似搜索方法,步长γt选取以下值中的一种:1*10-5,1*10-4,1*10-3,或者1*10-2。
进一步,本发明的近似搜索方法,步骤4具体如下:
步骤a、得到转换矩阵a后,再通过式(1)计算出每张图片和抽样图片之间的引入语义一致性后的优化相似度,即得到了关系矩阵w的各个元素的值,如果抽样图片集中有m张图片样本,那么通过关系矩阵构建出相似矩阵z,
z矩阵计算公式定义如下:
其中<i>集合代表的是抽样图片集,即只有当图片是属于抽样图片集中的图片时,才计算z矩阵上对应元素的值,否则z矩阵上对应元素值为0;
步骤b、设抽样图片集合中图片的数量为m,构造一个m*m维的m矩阵,m矩阵定义如下:
m=λ-1/2ztzλ-1/2(5)
其中λ=diag(zt1),是一个对角矩阵,计算得到m矩阵前k个最大的特征值组成的k*k维的对角矩阵:∑=diag(δ1,...,δk)∈rk×k和前k个最大的特征值对应的特征向量组成的m*k维的矩阵:v=[v1,...,vk]∈rm×k;
步骤c、由上式得到的各矩阵,构造出最终的编码矩阵y,y矩阵定义如下:
y是一个n*k维的矩阵,n代表图片集中图片的个数,k代表映射到二进制编码时编码的位数,编码矩阵y的每行就是一个编码函数,各图片通过编码函数计算得到一个k维的向量,再对此向量进行二值化分割:sgn(y),就得到了图片集中各图片的二进制编码。
进一步,本发明的近似搜索方法,r选取以下值中的一个:1,2,3,或4。
本发明的关键技术分述如下:
(1)基于语义一致的近似搜索算法
基于语义一致的近似搜索算法是在计算图片数据集中各图片和抽样图片集中图片的相似度时引入语义一致性,构建出包含语义信息的目标函数表达式。然后用随机梯度下降算法迭代求解,表达式收敛后即得到反映图片间内在语义一致特性的转换矩阵。再利用哈希技术把图片映射成k位的二进制编码,并使相似的输入图片映射成汉明距离相近的二进制编码。
(2)随机梯度下降(sgd)算法:
随机梯度下降算法作为梯度下降(gradientdescent,gd)算法的改进算法,其主要针对原始梯度下降算法收敛速度过慢和易陷入局部最优的问题,是一种最小化损失函数或风险函数的迭代求解方法。本发明利用随机梯度下降算法减少了语义一致近似搜索方法中转换矩阵的训练时间。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1.解决了用传统的梯度下降算法收敛速度过慢的问题。
2.使用转换矩阵计算图片之间的优化相似度,解决了使用传统的高斯核函数度量图片相似度时对敏感参数过于依赖的问题。
3.使用哈希技术把d维的原始图片压缩映射成k比特的二进制编码,极大地提高了算法的效率并且极大的缩减了对内存空间的占用。
附图说明
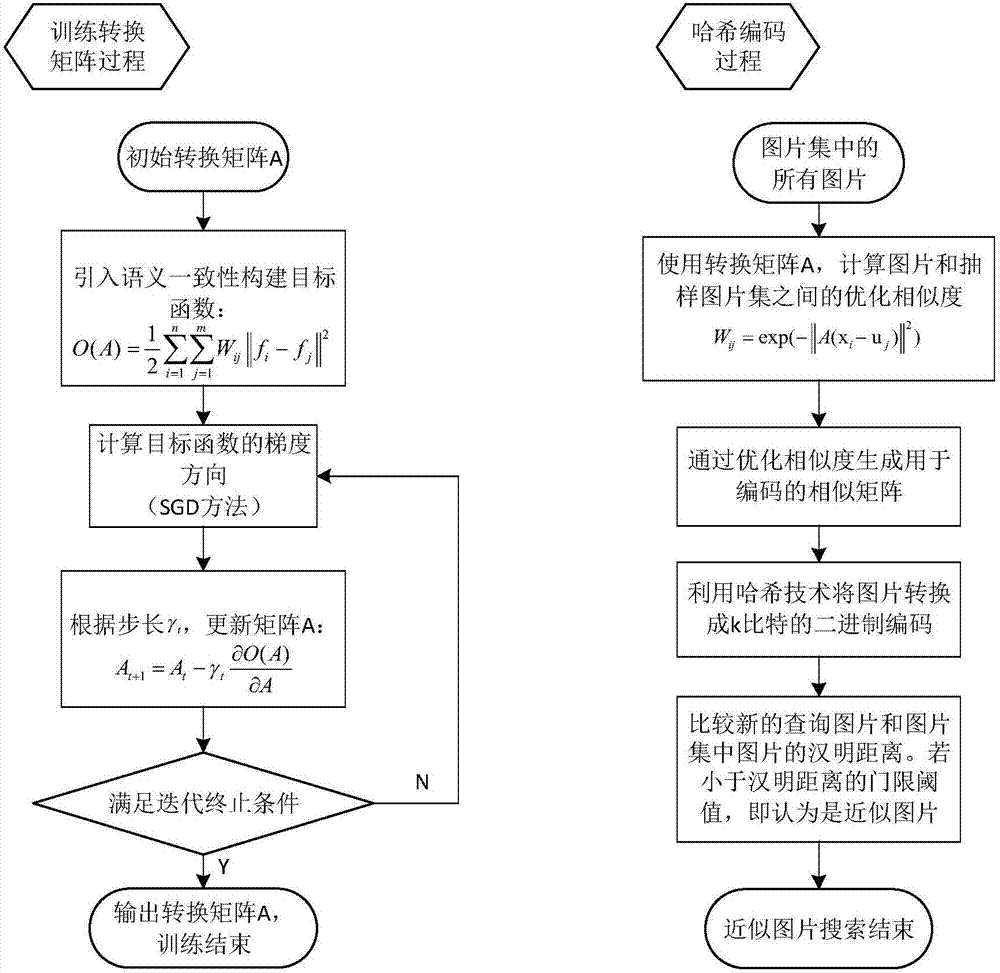
图1是本发明的系统框架图。
图2是本发明的方法流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明在对图片进行相似性度量时引入语义一致特性,可以更为准确的度量图片之间的相似性。并生成抽样图片集计算引入语义一致性后的优化相似度,以及使用随机梯度下降法来减少算法的训练时间,使算法能够有效地应用于大规模的图片数据集中。进而使用哈希编码技术生成高效的二进制编码,在近似图片搜索中可以获得更好的性能。
如图1所示,本发明提供了一种在大规模图片集中基于语义一致性,并利用哈希编码技术把图片进行二进制编码进而通过比较图片编码间的汉明距离来找到近似图片的方法。
本发明主要包括两个部分:训练转换矩阵的过程和哈希编码的过程。
训练转换矩阵的过程主要是在计算图片集中的图片和抽样图片的相似度时引入语义一致性,并获得下一阶段所需的转换矩阵。
哈希编码的过程主要是根据训练过程得到的转换矩阵计算出图片和抽样图片之间的优化相似度,并根据优化相似度构建相似矩阵进而利用哈希编码技术对图片集中的各图片进行二进制编码。然后比较新的查询图片和各图片二进制编码的汉明距离,从而找到查询图片的近邻。
一、训练转换矩阵过程:
训练转换矩阵的过程主要根据语义一致的思想建立模型并获得编码阶段需要的转换矩阵,转换矩阵反映了图片之间内在的语义一致特性。在训练转换矩阵的过程中本发明采用随机梯度下降(sgd)算法减少训练时间。如果图片的特征维度为d维,则经过训练的转换矩阵是d行d列的方阵。
大规模图片集中基于语义一致性的近似搜索方法的基本思想是通过引入语义一致特性,将图片由初始的d维压缩映射成k维的二进制编码。并使相似的输入图片映射成汉明距离相近的二进制编码。
步骤1:在计算优化相似度时,若图片数据集中包含n张图片样本,定义图片间的关系矩阵w是一个n*n维的矩阵,关系矩阵中的每一个元素定义为:
wij=exp(-||a(xi-uj)||2)(1)
上式中a表示转换矩阵,xi表示数据集中的第i张图片,uj表示抽样图片集中的中的第j张图片。
步骤2:训练转换矩阵a的过程中主要引入了语义一致性建立目标函数,并通过随机梯度下降(sgd)算法迭代求解,获得编码阶段所需要的转换矩阵。定义目标函数式为:
上述目标函数中的fi表示第i个图片样本的类标记向量,(类标记向量是c维的列向量,c是类的数目,向量中元素的值为1或0,分别表示图片属于这个类和不属于这个类)。fj表示抽样图片集中图片的类标记向量。||fi-fj||2即是在训练转换矩阵时引入的语义一致性质。它结合图片间的特征相似性可以生成更为准确的二进制编码。
步骤3:在优化过程中本发明采用随机梯度下降算法以减少训练转换矩阵所用的时间。转换矩阵的初始值为1/δ,i是d*d维的单位矩阵,δ是数据集中各图片之间欧氏距离的中位数。然后根据随机梯度下降算法优化转换矩阵a,迭代更新规则如下:
其中γt是每次迭代过程中的优化步长,步长可选取以下值:(1*10-5,1*10-4,1*10-3,1*10-2)。图片数据集中所有的图片样本遍历结束后,即得到最终优化完成的转换矩阵a。此时转换矩阵训练结束,输出转换矩阵a。
二、哈希编码过程:
如图2所示,哈希编码的过程主要由上一步得到的转换矩阵构建出反映样本和抽样图片集之间优化后的相似性关系的相似矩阵z。然后利用哈希技术对大规模图片数据集中的各图片进行哈希编码。想要查找新的图片在数据集中的近似图片,比较图片间二进制编码的汉明距离,若汉明距离小于设定的门限阈值r,即认为两图片是近似图片。
步骤1:得到转换矩阵a后,再通过式(1)计算出每张图片和抽样图片之间的引入语义一致性后的优化相似度。即得到了关系矩阵w的各个元素的值。如果抽样图片集中有m张图片样本,那么通过关系矩阵可以构建出使用哈希编码技术需要用到的相似矩阵z。z矩阵计算公式定义如下:
其中<i>集合代表的是抽样图片集。即只有当图片是属于抽样图片集中的图片时,才计算z矩阵上对应元素的值,否则z矩阵上对应元素值为0。
步骤2:设抽样图片集合中图片的数量为m,构造一个m*m维的m矩阵。m矩阵定义如下:
m=λ-1/2ztzλ-1/2(5)
其中λ=diag(zt1),是一个对角矩阵。计算得到m矩阵前k个最大的特征值组成的k*k维的对角矩阵:∑=diag(δ1,...,δk)∈rk×k和前k个最大的特征值对应的特征向量组成的m*k维的矩阵:v=[v1,...,vk]∈rm×k。
步骤3:由上式得到的各矩阵,构造出最终的编码矩阵y,y矩阵定义如下:
y是一个n*k维的矩阵,n代表图片集中图片的个数,k代表映射到二进制编码时编码的位数。编码矩阵y的每行就是一个编码函数,各图片通过编码函数计算得到一个k维的向量,再对此向量进行二值化分割:sgn(y)。就得到了图片数据集中各图片的二进制编码。
步骤4:如果有新的查询图片要进行近似图片的搜索,同样使用编码函数计算出查询图片的二进制编码。然后比较查询图片的编码和图片数据集中所有图片编码的汉明距离。定义汉明距离门限阈值r(r可选取以下值:1,2,3,4),如果查询图片和某图片的汉明距离小于阈值r,即认为此图片是查询图片的近似图片。遍历图片数据集,即可找到查询图片的所有近似图片。
本发明的整体方法流程如下:
步骤1:输入图片数据集样本矩阵x(x是n*d维的矩阵,n是图片的个数,n的取值可以很大,d是图片特征的维度),并输入图片集对应的语义类标记矩阵y(y是n*c维的矩阵,n是样本个数,c是类标记的数量)。
步骤2:从图片集中随机抽取一部分图片作为抽样图片集,选取抽样图片集的目的是通过计算图片和抽样图片之间的相似度,可以大大减少计算时间开销,提高算法的效率。
步骤3:对于图片数据集中的每一张图片,引入语义一致性构建目标函数表达式o(a),其中a(a是d*d维的矩阵,d是图片特征的维度)是在编码阶段需要的转换矩阵。通过随机梯度下降算法迭代求解,表达式收敛后即得到优化完成的转换矩阵a。
步骤4:对于每一个图片样本x,用转换矩阵a乘上图片样本x和抽样图片之间的相似度。得到了引入语义一致性之后的优化相似度。然后再利用哈希技术进行编码,将图片由原始的d维特征压缩映射成k维的二进制编码。
步骤5:对于一个新的查询图片q,要找到它的近似图片。首先用步骤3中训练得到的转换矩阵a乘上图片q和抽样图片之间的相似度。得到了引入语义一致性之后的优化相似度。再通过编码函数计算出查询图片的二进制编码。与图片数据集中各图片的二进制编码比较汉明距离。如果汉明距离小于设定的门限阈值r,即认为两图片是近似图片。
本发明采用以上技术实施方案,与现有技术相比所解决的问题如下:
(1)传统近似搜索算法训练过程中没有引入语义一致性导致性能不佳的问题:很多传统的用于图片近邻搜索的算法在寻找查询图片近邻的时候过于片面,在寻找查询图片的近邻时没有考虑图片可能具有的语义信息,使得这些算法在图片近似搜索的实际应用中性能不佳。本发明在对图片进行相似性度量时引入语义一致特性,可以更为准确的度量图片之间的相似性。使算法能够有效地应用在现实的图片近似搜索中。
(2)使用抽象图片集计算优化相似度。解决了大规模图片数据集中计算相似度过慢的问题:在大规模图片数据集中,如果使用传统的计算图片和图片两两之间相似度的这种度量方法,会使时间开销非常大,现实应用中不可行。本发明从海量图片集中随机抽取很少的一部分图片作为抽样图片集,只计算图片和抽样图片集之间的优化相似度。大大减少了算法的时间开销,提高了算法效率。
(3)使用随机梯度下降算法解决了目标函数式收敛过慢的问题:原始的梯度下降算法称为批量梯度下降算法,此算法的做法是最小化所有训练数据的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得损失函数值最小的参数。但是批量梯度算法每迭代一步,都要用到训练集所有的数据,如果数据集中图片数量很大,那么使用批量梯度算法是非常慢的。随机梯度下降算法在迭代更新一次时只用到一个数据样本,速度较快。特别是对于大规模图片数据集而言,速度的优势更为明显。而且对目标损失函数来说,使用随机梯度下降算法不需要完遍历整个数据集就可以达到收敛。本发明用随机梯度下降算法取代批量梯度算法来迭代求解算法的目标函数,解决了算法收敛过慢的问题。
综上所述,本发明使用反映了图片间内在语义一致性的转换矩阵来计算图片间的优化相似度。为了提高搜索效率,从大规模图片集中随机选取一部分图片作为抽样图片集来度量图片间的相似性,并在训练转换矩阵时采用随机梯度下降法减少算法的训练时间。通过图片间的优化相似度得到用于编码的相似矩阵后,使用哈希编码技术把原始图片映射为k比特的二进制编码。在搜索新的查询图片的近邻时,首先通过模型的编码函数得到查询图片的二进制编码,再和图片集中的所有图片比较编码间的汉明距离。当某些图片和查询图片的汉明距离小于给定的汉明距离门限阈值时,即认为是查询图片的近似图片。
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!