一种面向纯文本的企业实体分类方法与流程
本发明属于命名实体识别和细粒度实体分类技术领域,具体涉及一种面向纯文本的企业实体分类方法。
背景技术:
近年来,随着“互联网金融”的热潮,越来越多的企业决策者迫切需要利用更先进的信息处理方式来对海量的互联网数据进行抽取和分析,以便做出更好的决策。在这些海量数据之中,法院文书类、新闻舆情类等纯文本数据成为企业获取高价值信息的首要来源。
命名实体识别技术是企业进行实体语义分析,实体关系抽取等工作的基础。目前主流的命名实体识别技术只是将实体分为人名、地名、机构名等,这使得实体的类型缺乏语义。同时,进行实体分类时过多依赖于人工特征和外部数据,使其通用性和健壮性得不到保证。
技术实现要素:
本发明针对目前主流的命名实体识别技术只是将实体分为人名、地名、机构名等,使得实体的类型缺乏语义。此外,进行实体分类时过多依赖于人工特征和外部数据,使其通用性和健壮性得不到保证。为解决上述问题,本发明提出一种面向纯文本的企业实体分类方法,采用企业实体更细粒度的划分方式,并且使用文本本身的语义构建特征,最后进行企业实体的分类。其中,纯文本,即包含企业活动信息的文本,譬如新闻文本、法院文书等。
如图1所示,本发明所公开的面向纯文本的企业实体分类方法,包括如下步骤:
s1、对采集到的纯文本数据中的企业实体进行类别标注,将标注完成的数据作为企业实体识别模块的训练集;对采集到的纯文本数据中的企业实体按照行业性质进行类别标注,将标注完成的数据作为企业实体分类模块的训练样本集;
s2、通过条件随机场模型进行企业实体识别模型训练,并得到企业实体识别模型;
s3、对原始训练集的文本数据进行语义向量化构建;
s4、将经语义向量化后的有类别标注的训练集数据作为训练参数训练出企业实体分类模型;
s5、利用企业实体分类模型对待预测文本中的企业实体进行分类。
进一步的,s1中,将采集到的纯文本数据进行分句、分词和词性标注,采用人工标注的方法对纯文本数据中的企业实体和行业类别进行标注。
进一步的,使用开源的分词和词性标注软件hanlp对纯文本数据进行分句、分词和词性标注。
进一步的,对纯文本数据中的企业实体标注方式为“bio”标记形式,其中,企业实体的起始词标记为“b”,企业实体非起始词的其他部分词语标记为“i”,与企业实体无关的词语标记为“o”。
进一步的,采用人工标注的方法中,对纯文本数据中的企业实体依据上下文内容按照行业性质对其进行类别标注。
进一步的,s2中,通过引入边界特征的条件随机场模型进行企业实体识别模型训练。
进一步的,引入边界特征的条件随机场模型包括:通过hanlp将企业名称分词后整理得到左、右边界词典;使用开源的libsvm训练得到左、右边界的预测模型;依次从训练集中取出词语并通过左、右边界的预测模型来判断该词语是否是左、右边界词;将包括词语本身、词性标注、左右边界标记、实体标注的训练集数据输入开源的条件随机场工具进行企业实体识别模型的训练并得到企业实体的识别模型。
进一步的,s3中,使用词向量计算工具得到训练样本集中所有词的词向量,计算训练样本集中所有词的逆文本频率(idf)值,利用词向量和tf-idf值计算包含有企业实体语句中的企业实体的向量和上下文向量,将企业实体的向量和上下文向量进行拼接,以得到包含上下文语义的企业实体语义向量。
进一步的,使用开源的word2vec工具计算训练集中所有词的词向量。
进一步的,s4中,对已经有类别标注的训练集数据使用softmax模型训练出企业实体的分类模型。
本发明所具有的有益效果如下所述:
1)使用词典规则和svm分类器来预先确定实体的左右边界,之后将判定的左右边界的结果作为新特征引入到条件随机场模型中,本发明改进的方法在召回率和f1值上有很大提升。
2)使用词嵌入加权的方式,对实体及其上下文进行语义向量化表示,从而使得实体之间的语义可以通过语义向量距离来度量。用得到的语义向量作为实体的特征,减少对人工特征和外部数据的依赖。
3)在现有的条件随机场模型中引入实体边界特征,而实体边界特征的引入加强了条件随机场模型对实体边界的控制能力,如识别的召回率有了非常明显的提高,也使其通用性和健壮性得到保证。
附图说明
图1为本发明所公开的面向纯文本的企业实体分类方法流程框图。
图2为实施例中的训练集构建流程图。
图3为实施例中的基于改进条件随机场的企业实体识别模型训练流程图。
图4为实施例中的基于词向量和tf-idf值加权的实体语义向量构建流程图。
图5为企业实体分类模型训练流程图。
图6为企业实体分类流程图。
具体实施方式
为了更了解本发明的技术内容,特举一具体的面向法院文书的企业实体分类方法实施例并配合所附图式说明如下。
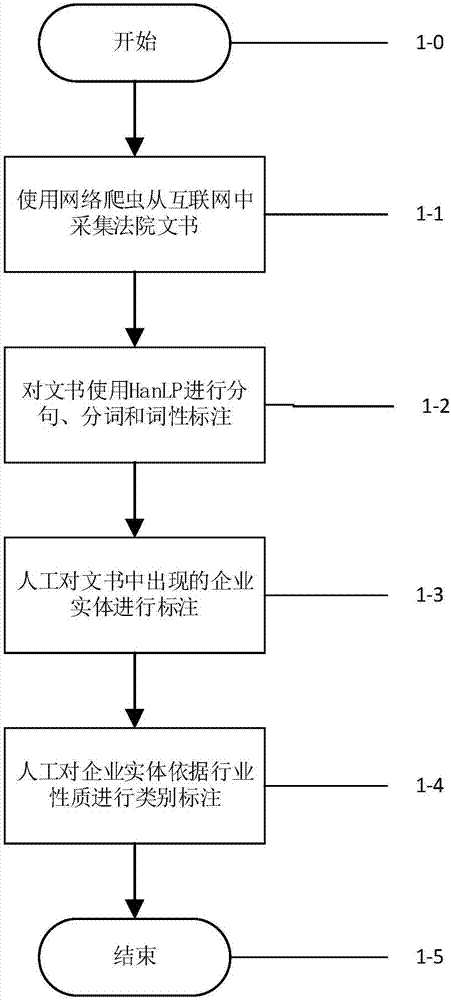
如图2所示,本发明在实施之前先构建训练样本集。实施例中构建训练样本集的过程如下:
步骤1-0、建立训练集的起始状态。
步骤1-1、使用网络爬虫工具从互联网中采集法院文书,作为原始语料库。
步骤1-2、对采集得到的文书数据,使用开源的分词和词性标注软件hanlp对文书文本进行分句、分词和词性标注。当然,一般的开源分词软件都可以使用,譬如中科院分词等等,实施例中选用的hanlp软件相较于目前的开源分词软件来说分词的效果相对更好,并且可以人工定制词典,也更方便。
步骤1-3、由于文本中的企业实体词(即是企业的名称,主要包括全称和简称两种形式)经分词后会切分为多个词,所以需要通过人工标注的方法,将文书文本中的企业实体标注出来,标注的方式为“bio”标记形式,即企业实体的起始词标记为“b”,企业实体非起始词的其他部分词语标记为“i”,与企业实体无关的词语标记为“o”,如“被告(o)江苏(b)欧亚(i)薄膜(i)有限公司(i)”。标注完成的数据作为企业实体识别模型的训练集。
同时,对采集到的文书文本中的企业实体依据上下文内容按照行业性质对其进行类别标注。标注完成的数据作为企业实体分类模型的训练集,标注完成的数据即包括一句包含企业名称的语句和该企业所属行业的类标,而整个训练集就是若干条这样的句子+类标的集合。其中,类别标注的标准可以选用具有准确性和权威性的国民经济行业分类(gb/t4754-2011)中的划分方式。
步骤1-4、建立训练集的结束。
如图3所示,在构建完训练集之后,使用改进的条件随机场方法,即,通过引入边界特征的条件随机场模型进行企业实体识别模型训练。
步骤2-0、企业实体识别模型训练的开始。
步骤2-1、输入经过分句、分词、词性标注和实体标注后的训练集数据(即步骤1-3中的标注完成数据)。
步骤2-2、从互联网中爬取一些企业名录,将这些企业名称通过hanlp分词后整理得到左、右边界词典。左边界词指的是企业名称分词后的第一个词,右边界词指的是企业名称分词后的最后一个词。将所有的左、右边界词整理成为左、右边界词词典。
步骤2-3、使用开源的libsvm训练得到左、右边界的预测模型。左边界预测模型训练过程中选择的特征为:当前词以及后两个词的词语本身和词性;右边界预测模型训练过程中选择的特征为:当前词以及前两个词的词语本身和词性。其中,使用的开源的libsvm具有较好的健壮性和更好的分类边界
步骤2-4、依次从训练集中取出词语并通过左、右边界的预测模型来判断该词语是否是左、右边界词。
当前词语是否是左边界词的判断方法为:如果该词语出现在左边界词典中,且该词语右边两个词窗口内有词语在svm方法下判定为左边界词则为正确的左边界词,否则舍去。当然,每个词在词典方法和svm方法下都有一个判断结果,但是这两个方法都存在缺点,实施例中这一步是综合两个方法的结果,选择出一个更合理的结果。
当前词语是否是右边界词的判断方法为:如果该词语出现在右边界词典中,且该词语左边两个词窗口内有词语在svm方法下判定为右边界词则为正确的右边界词,否则舍去。
步骤2-5、判断是否遍历完所有的词语,如果遍历完成则到步骤2-7,否则到2-6。
步骤2-6、计数器i加1,取出文本中的下一个词语。以上步骤实际就是判断某个词是否为左右边界词。
步骤2-7、将训练集的数据输入开源的条件随机场工具crf++进行企业实体识别模型的训练,输出企业实体的识别模型。训练数据选择的特征为词语本身、词性标注、左右边界标记、实体标注。
步骤2-8、企业实体识别模型训练的结束。
可见,本发明在现有的条件随机场模型中引入实体边界特征,在使用条件随机场模型之前判断一下这个词是否是左右边界词,将这个结果作为特征,之后使用条件随机场模型,而实体边界特征的引入加强了条件随机场模型对实体边界的控制能力,具体体现为识别的召回率有了明显提高。
如图4所示,对原始训练集的文本数据进行语义向量化构建的流程图。
步骤3-0、训练集文本语义向量构建的开始。
步骤3-1、输入已经完成分句、分词、词性标注和类别标注的训练集文本集合。
步骤3-2、使用开源的word2vec工具计算训练集中所有词的词向量。值得注意的是,word2vec是google开源的计算词向量的工具,目前此类的工具很多,word2vec比较知名,可替代的工具也有很多比如java的word2vec4j等等。
步骤3-3、计算训练集中所有词的逆文本频率(idf)值,其计算的公式如下:
其中,对数函数内的分数,分子表示整个文档中文档的总数,分母表示包含某个词语的文档数再加1,取两者的比值。
步骤3-4、从训练集中的第一句文本开始依次取出文档中的每一句文本。
步骤3-5、利用企业实体识别模型判断取出的这一句文本中是否有企业实体的存在,如果有则到步骤3-6,否则到步骤3-10。
步骤3-6、在步骤3-5中判断出文本中包含企业实体之后,对实体部分的语义向量进行计算,假设一个实体的向量表示为vm,构成它的词组其向量表示分别为:w1,w2,...,wn,则vm的计算公式如下:
步骤3-7、在步骤3-6计算实体的语义向量之后,对实体的上下文部分计算语义向量,其计算方式如下:
其中,v(context)是上下文的的向量表征形式,tf·idf(wi)表示词语wi的tf-idf值,v(wi)为词语wi的词向量,k为词窗口大小(即取上下文中靠近中心实体的前k个词)。词语的tf值为文本中出现该词语的频次,词语的tf-idf值即为词语的tf值与idf值的乘积。
步骤3-8、对步骤3-6和步骤3-7中得到的实体和上下文的语义向量进行拼接,具体操作为对k维的实体向量和k维的上下文向量,以实体向量在前,上下文向量在后的方式拼接得到一个2k维的向量。
步骤3-9、判断是否遍历完训练集文本中所有的语句,如果遍历完成则到步骤3-11,否则到步骤3-10。
步骤3-10、计数器i加1,取出训练集文本中的下一条语句。
步骤3-11、将得到的融合上下文语义的实体向量输出,作为企业实体分类模型的训练数据。值得注意的是,步骤1-3标注后的数据是一个纯文本+类标的数据,在这里之前的步骤是将文本转变为向量,因而这里的数据是向量+类标的数据。
步骤3-12、训练集文本语义构建的结束。
如图5所示,在对原始语料(即是步骤1-3之后得到的数据集)进行语义向量化构建之后,使用softmax多分类算法进行企业实体分类模型的训练。softmax多分类算法是一种常用的方法,相比其它方法而言,它的计算速度快,占用空间小,并且可以得到测试样本在每个类别上的概率
步骤4-0、企业实体分类模型训练的开始。
步骤4-1、将经过语义向量化之后的有类别标注的训练集数据输入到softmax分类模型中,作为训练参数。
步骤4-2、采用softmax算法进行多分类模型训练,输出经过训练后的softmax多分类模型,用以后续的分类预测。
步骤4-3、企业实体分类模型训练的结束。
如图6所示,在得到企业实体分类模型之后,利用该分类模型进行分类的流程图。
步骤5-0、企业实体分类的开始。
步骤5-1、向企业实体分类模型输入待预测实体类别的文本。
步骤5-2、利用企业实体识别模型判断输入文本中是否有企业实体,如果有则转到步骤5-3,否则转到步骤5-5。
步骤5-3、对包含有企业实体文本利用步骤3-1至步骤3-12进行实体语义向量构建,之后将得到的向量输入训练好的企业实体分类模型中,得到文本中实体的分类结果。
步骤5-4、输出5-3步骤的分类结果。
步骤5-5、企业实体分类的结束。
综上所述,本发明提出的利用词向量技术和文档词语的tf-idf值得到包含上下文语义的企业实体向量表示形式之后再进行分类的方法,能够解决目前对企业实体分类方法中类型较少且缺乏语义的问题,使企业实体的类型具有更细的粒度和更强的语义特征。
本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!