慢性病风险评估双曲线模型的构建及应用该模型的疾病预测系统的制作方法
本发明涉及基于医疗大数据的健康管理,尤其涉及慢性病风险评估双曲线模型的构建及应用该模型的疾病预测系统。
背景技术:
随着经济的快速发展,人们的生活节奏也明显加快,并随之产生了一系列的不健康生活方式,进而导致心脑血管疾病、糖尿病和恶性肿瘤等慢性病的发病率、患病率和死亡率持续上升。慢性病是一大类受环境因素和遗传因素共同影响的多因素疾病,是由多种危险因素综合作用产生的结果。慢性病起病隐匿,潜伏期长、病情进展快,很多患者难以及时发现及治疗。另外,由于目前大多数慢性病的病因及发病机制仍不是十分清楚,治疗效果欠佳,因而预防慢性病的发生具有实际意义。
开发准确有效的早期诊断及筛检检测技术,建立完善的疾病普查制度和风险评估、预警体系等是防治慢性病的关键所在。风险评估主要包括一般健康状况风险评估和疾病风险评估两种。一般健康风险评估主要是对危险因素(如吸烟状况、体力活动、膳食状况等)及可能发生疾病的评估,通过评估发现主要健康问题及可能发生的主要疾病,进而对风险因素进行分层管理的过程。疾病风险评估则是指对特定慢性病的发病风险进行评估或预测。目前,健康风险评估的主流是以疾病为基础的危险性评价。
疾病风险评估模型是慢性病风险评估的主要工具,主要用于识别高危人群,进行危险因素干预,以达到较好的卫生经济学效果。建立疾病预测模型可以指导个体,特别是高危人群的生活行为,进而减小患病的风险,是防治慢性病的重要措施之一。疾病风险模型综合考虑各种可能的危险因素,通常根据各种可能危险因素进行风险评分,并以危险总分的高低来判断高危人群;或者以多因素回归模型等预测未来一定时间特定的发病概率,根据概率切点判断高危人群。疾病风险评估一般会对识别出的高危人群进行行为、饮食等干预,以预防未来发病的可能,属于疾病一级预防的范畴。疾病风险预测模型能够告知并预测评估对象在未来一段时间内患病的可能性,为其提供自我健康管理建议,也可为经济学家在医疗资源的合理配置、预测未来疾病负担、帮助政府决策者合理开展卫生服务项目、制定切合实际情况的卫生服务政策等工作中提供依据。近年来国内外有关疾病发病风险模型的研究较多,这些模型能够有效识别高危人群,并通过对高危人群进行饮食和行为干预,对于节约预防疾病的成本、降低未来疾病发病的可能性等均具有重大的公共卫生学意义,受到广大研究者的青睐。
国内外常用的慢性病风险评估建模方法分为两大类:一类是基于大量散在的横断面研究结果所进行的合成研究,统计学方法主要有meta分析方法、合成分析(synthesisanalysis)和哈佛癌症指数等方法;另一类是直接利用流行病学研究结果,主要是基于社区大型纵向队列研究成果,其建模方法主要有logistic回归分析、生存分析法(如cox回归和寿命表分析法)、人工神经网络、多水平模型、线性混合模型及近年来兴起的joint联合模型分析方法等。然而目前多种模型风险评估方法各有自身特点,不同评估模型尤其最后评价时各有自身的评价标准,其风险量化等级和评估方法也呈现多样化,用户难以选择;而且疾病风险评估模型也多以风险等级(或危险总分)、发病概率等来指示风险,缺乏相应参考对象,这对于评估用户来说,往往风险认知不足或较难准确把握自身风险;此外,疾病风险评估中的基准风险(如患病平均风险)和低风险阈值往往是定值(取所有纳入数据的均值),使得用户的风险评估缺乏准确性。
技术实现要素:
针对上述现有技术风险评估模型存在的问题,发明人前期研究建立了多中心纵向监测健康管理队列数据管理系统,在此基础上,本发明依托山东省20多家健康管理中心的纵向健康管理数据构建山东多中心健康管理纵向观察队列,探讨遗传、环境、个人生活方式、健康干预因素等在重大慢性病发生、发展和转归过程中的作用,建立适用于山东省健康体检人群的各种慢性病的风险评估模型,并为慢性病的健康干预提供科学依据。具体的本发明涉及以下技术方案:
首先,本发明提供一种慢性病风险评估双曲线模型的构建方法,具体的步骤为:
(1)、数据处理:对(多中心)纵向健康管理数据进行标准化处理、人员去重、变量对照、疾病对照、结构化审核步骤,最终得到需要的结构化的数据;
(2)、建立队列:根据疾病定义,规定好疾病的结局,获得该疾病的对应队列;
(3)、建立疾病预测模型:利用疾病的对应队列(纵向观察数据队列)构建疾病预测模型
(4)、平均风险线曲线:将步骤(2)队列中的基线数据带入到已经建立好的疾病预测模型
(5)、低风险线曲线:利用弗明翰评分方法,计算步骤(2)队列中的基线数据各指标最优水平xi,将xi结合已经建立好的疾病预测模型
风险评估双曲线模型的构建流程如图1所示。
优选的,步骤(2)中利用sas软件建立并获得该疾病的对应队列。
具体的,步骤(3)中采用cox比例风险回归构建疾病预测模型或采用fine和gray提出的部分分布竞争风险模型(competingriskmodel)构建疾病预测模型。
优选的,步骤(4)中,计算出疾病的发病风险p后,对于每个组中的疾病发病风险(发病概率p)进行正态性检验,如果满足,那么取出这组发病概率p的平均值p_mean作为该年龄人群的平均风险
具体的,步骤(5)中,计算步骤(3)所述疾病预测模型中涉及到的体检指标的1%和99%分位数;然后计算各指标最优水平xi,1)连续性变量,如果βi>0,那么
优选的,本发明所述慢性病选自代谢综合征、糖尿病、高血压、冠心病、慢性肾病、脑卒中、心血管疾病等。
优选的实施方案中,疾病预测模型
本发明通过使用发病风险p随年龄变化趋势这一技术手段,确定了每一年龄组的平均风险阈值和低风险阈值,克服了既有的平均风险阈值和低风险阈值过于宽泛和指示性欠准确的问题。通过该方法建立的慢性病风险评估双曲线模型,疾病风险评估中的基准风险(如患病平均风险)和低风险阈值均与评估个体的年龄相关,评估个体可以根据自身指标带入该模型中,可实现评估个体实际年龄对应下的风险高低的评估,即个体的风险值pi与对应该个体实际年龄的
此外,通过引入风险年龄使得风险通过年龄量化这一比较手段,利用本发明方法建立的慢性病风险评估双曲线模型,评估个体的风险值pi带入模型后,其对应平均风险线曲线的年龄为该个体的风险年龄(风险年龄即为具有该发病概率的人群平均年龄),通过风险年龄和实际年龄的比较,使得风险通过年龄量化,评估个体可以更为直观的认知自身的疾病风险,更便于进行后续的健康管理。
本发明提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上疾病风险评估双曲线模型的构建方法。
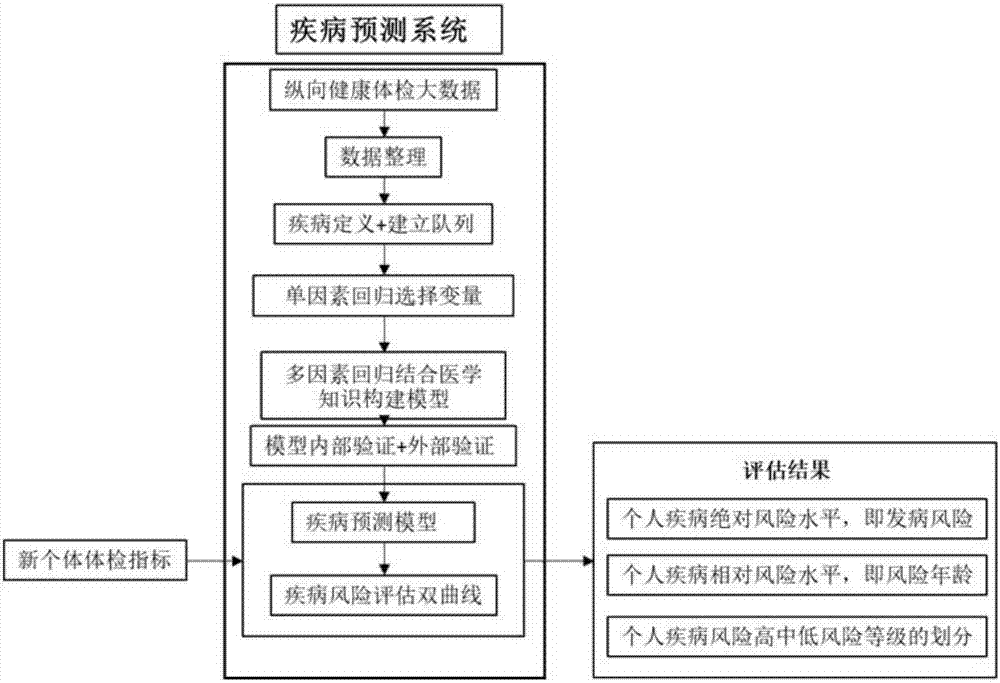
其次,本发明提供一种慢性病疾病预测系统,该系统是包括计算机的根据体检指标预测该慢性病发病风险的装置,所述计算机具有以下部分,
数据库,存储有(多中心)纵向健康管理数据;
存储器,存储有可在处理器上运行的计算机程序;
输入单元,用于输入预测个体的疾病名称和与该疾病对应的体检指标,
处理器,调用数据库中数据,运行存储器中程序,生成慢性病疾病风险评估双曲线模型,并对输入的个体的体检指标进行比对分析获得疾病预测风险结果;
显示处理单元,用于输出预测风险结果并将预测风险结果进行展示,预测风险结果包括个体发病风险的双曲线图、风险等级、风险年龄;
所述处理器生成慢性病疾病风险评估双曲线模型时,实现以下步骤:
调用数据库中的纵向健康管理数据,对纵向健康管理数据进行标准化处理、人员去重、变量对照、疾病对照、结构化审核步骤,得到需要的结构化的数据;根据疾病定义、疾病的结局定义,获得该疾病的对应队列(纵向观察数据队列);
采用可计算发病概率的建模方法生成疾病预测模型
利用纵向观察数据队列中的基线数据结合疾病预测模型
利用弗明翰评分方法,计算疾病预测模型中各指标最优水平xi,将xi结合已经建立好的疾病预测模型
所述处理器对输入的个体的体检指标进行比对分析获得疾病预测风险结果时执行以下程序:利用输入单元输入的预测个体的疾病名称和与该疾病对应的体检指标,结合疾病预测模型
慢性病疾病预测系统如图2所示。
具体的,平均风险线曲线的获得为:纵向观察数据队列中的基线数据带入到已经建立好的疾病预测模型
具体的,低风险线曲线的获得为:计算获得疾病预测模型
所述个体风险等级范围包括高风险、中等风险、低风险。
此外,本发明所述的慢性病疾病预测系统还包括打印设备,打印设备用于打印个体的风险评估报告,所述风险评估报告包括个体发病风险的双曲线图、风险等级、风险年龄,例如打印如图3所示预测个体未来5年高血压的发病风险评估报告内容。
本发明取得了以下有益效果:
(1)本发明首次建立了慢性病风险评估的双曲线模型,(结合个体数据)可实现评估个体实际年龄组对应下的风险高低的评估,摒弃了现有技术所有年龄统计集合或部分年龄段集合的平均风险判定方式,利用本发明评估模型进行风险评估更加准确。
(2)为便于后期更为有效的进行健康管理和健康指导,本发明采用了患者的风险年龄这一量化手段,利用本发明方法建立的慢性病风险评估双曲线模型,评估个体的风险值pi带入模型后,其对应平均风险线曲线的年龄为该个体的风险年龄(风险年龄即为具有该发病概率的人群平均年龄),通过风险年龄和实际年龄的比较,评估个体可以更为直观的认知自身的疾病风险,更便于进行后续的健康管理。
(3)本发明建立了更为简单准确的低风险阈值确定方法,本发明通过比较弗明翰评分方法,经检验使用转化之后的得分模型计算的发病风险与使用公式计算的发病风险非常接近,使用得分模型很容易计算低风险线,即除年龄外各危险因素得分为零。
附图说明
图1风险评估双曲线模型的构建流程
图2慢性病疾病预测系统
图3发病风险评估报告内容示意图
图4各年份新纳入人数及发生代谢综合征人数的队列图
图5男性mets模型(a)和女性mets模型(b)的roc曲线
图6各年龄人群未来5年mets发生平均风险和低风险:图6a女性平均风险线与低风险线图,图6b男性平均风险线与低风险线图
图7各年龄人群未来5年cvd发生平均风险和低风险
图8各年龄人群未来发生心脑血管事件的平均风险和低风险
图9健康管理人群2型糖尿病3年发病风险
具体实施方式
实施例1、山东多中心健康管理纵向观察队列
本发明依托山东省20多家健康管理中心的纵向健康管理数据构建山东多中心健康管理纵向观察队列,探讨遗传、环境、个人生活方式、健康干预因素等在重大慢性病发生、发展和转归过程中的作用,建立适用于山东省健康体检人群的各种慢性病的风险评估模型,并为慢性病的健康干预提供科学依据。
1.1资料来源:本研究队列资料来源于山东多中心健康管理纵向观察队列,队列中的个体为2004年1月至2015年12月间在多中心健康管理队列内的健康体检中心进行体格检查的体检者。从“多中心纵向监测健康管理队列数据管理系统”中选择并导出部分数据,本次研究队列总人数为76368人。人选标准:①具有山东省内常住居民户口;②能够回答问卷;③自愿参加该项目并签署知情同意书。山东大学公共卫生学院伦理委员会批准了此项研究。
1.2调查方法和内容:由经过培训的护理人员完成调查。具体调查包括问卷调查、体格检查、血液样本采集和实验室指标检测等。(具体指标、指标单位及赋值见表1)
1.2.1问卷调查:包括一般的人口学信息(性别、年龄、婚姻、民族)、既往史、家族史、行为生活方式(吸烟、饮酒、饮食、睡眠、体育运动)。
1.2.2体格检查:体格检查项目包括身高、体重、脉搏、收缩压、舒张压、心率、心电图、胸部x射线检查、腹部b超等。①身高、体重测量时需脱去鞋和较重的衣物,并且根据身高和体重计算身高体重指数,身高体重指数=体重/身高2(kg/m2)。②血压的测量由专门护理人员使用欧姆龙电子血压计完成,收缩压和舒张压的值均取两次测量的平均值,两次测量间隔为5-15分钟。
1.2.3实验室检查:体检者需经12小时以上空腹后采血,在各医院体检中心检测以下各项指标。血常规、尿常规、肝功、肾功、尿肾功、脂代谢、糖代谢、血流变、炎症指标和肝炎六项等(具体指标见表1)。
1.3质量控制:在山东多中心健康管理队列下的各体检中心制定协助调查的护理人员,并且进行统一培训。采用相同的调查表完成个体基本信息的收集。
1.4各种疾病定义及标准为本领域相应疾病定义标准。
1.5多中心纵向监测健康管理队列数据管理系统构建方法参见张茜“大型纵向监测健康管理队列设计及其统计分析策略研究”,该论文一并引入本申请,通过多中心纵向监测健康管理队列数据管理系统可以对多家健康管理中心的纵向健康管理数据进行标准化处理、人员去重、变量对照、疾病对照、结构化审核步骤,最终得到需要的结构化的数据。
1.6统计学分析:根据性别分组,对基线的部分变量进行统计描述,近似正态分布数值变量以
表1队列中个体体检服务包及流行病学调查内容
结果
2.1基线情况山东多中心健康体检队列基线共有76368人,男性43818人,占总人数的57.38%。男性组和女性组均为20-50岁者占总人数的比例最高,男性20-50岁者占男性总数的75.33%,女性20-50岁者占女性总数的74.97%,男性和女性各年龄组的人数及构成比见表2。男性和女性年龄的中位数均为38.00岁,男、女各项体检指标描述结果见表3。
表2基线男性和女性各年龄组人数及构成
表3山东多中心健康管理队列调查对象基线特征
2.2.部分慢性病的累计发病率曲线
高血压、糖尿病、脑卒中和冠心病在随访结束时累计发病率分别为49.40%、23.98%、4.74%和6.28%,其中,男性的累计发病率分别为63.60%、29.01%、5.92%和8.53%,女性的累计发病率分别为34.27%、13.29%、3.20%和4.69%。上述四种疾病累计发病率曲线均为男性最高、总人群居中、女性最低。
实施例2、基于健康管理人群的代谢综合征发病风险预测
1、资料与方法1.1研究资料:资料来源本研究队列资料来源于山东多中心健康管理纵向观察大数据(山东多中心健康管理纵向观察队列)。入选和剔除标准本研究是在山东多中心健康管理纵向观察大数据队列中,选取未患代谢综合征,至少有两次记录,疾病诊断相关指标无缺失,年龄在20-80岁间者作为研究队列人群,研究中剔除了随访时间小于一个月的患病者。
1.2代谢综合征诊断标准代谢综合征的诊断采用2004年中华医学会糖尿病学分会(cds)建议的诊断标准。即:①超重和(或)肥胖:bmi≥25.0(kg/m2);②高血糖:fpg≥6.1mmol/l(110mg/dl)及(或)2hpg≥7.8mmol/l(140mg/dl),及(或)已确诊为糖尿病并治疗者;③高血压:sbp/dbp≥140/90mmhg及(或)已确认为高血压并治疗者;④空腹血tg≥1.7mmol/l(150mg/dl),及(或)空腹血hdl-c<0.9mmol/(35mg/dl)(男)或<1.0mmol/(39mg/dl)(女)。以上4个组分中有3个或以上达到标准即诊断为代谢综合征。
1.3统计学处理本研究统计分析采用sas9.4软件完成。连续性变量以
根据cox比例风险回归模型原理和最大似然原理可以估计代谢综合征累计发病风险,表达式为:
绘制平均风险线和低风险线。平均风险线绘制方法,计算队列中各个体的代谢综合征的发病风险,分年龄agei,i=20,21,……,80求平均发病风险
2结果2.1队列基线特征本研究队列共纳入15872人,平均随访时间为(2.60±1.79)年,随访时间中位数为2.03年,最长随访时间8.28年。队列人群基线特征如表4所示。
表4队列基线特征描述
2.2队列动态变化情况,mets健康管理人群的队列图如图4所示,年份上方数字为每年新进入队列的人数,下方数字为该年份新发生代谢综合征的人数。随访期间共确诊1591例新发代谢综合征病例(男性:1273例,女性:318例),发病密度为35.87‰。
2.3多因素cox比例风险模型鉴于代谢综合征的发病机理、患病率和危险因素在不同性别间均存在一定差异,本研究分别建立男性和女性的cox回归模型,结果见表5和表6。可见,纳入男性mets模型的变量包括年龄、体质指数、空腹血糖、甘油三酯、高密度脂蛋白胆固醇、血尿酸、是否高血压和总胆固醇;纳入女性mets模型的变量有年龄、体质指数、空腹血糖、甘油三酯、血尿酸和是否高血压。
表5多因素cox回归分析结果(男性mets模型)
表6多因素cox回归分析结果(女性mets模型)
2.4模型预测能力与效度检验男性mets模型和女性mets模型的roc曲线如图5所示,roc曲线下面积分别为0.751(95%ci:0.742-0.759)(图5a)和0.745(95%ci:0.734-0.756)(图5b);oe比分别为1.03和1.01;最佳cut-off值分别为37.88%和38.95%;男性模型的灵敏度和特异度分别67.32%和70.56%,女性模型的灵敏度和特异度分别为64.78%和74.17%;十折交叉验证auc平均值分别为0.749和0.746。
2.5mets健康管理双曲线如图6所示(图6a女性平均风险线与低风险线图,图6b男性平均风险线与低风险线图)。
例,某体检者,62岁,女性,bmi为19.33kg/m2、空腹血糖为5.2mmol/l、甘油三酯为1.02mmol/l、血尿酸为203umol/l、未患高血压,经计算其未来发生代谢综合征的风险为9.69%,风险年龄为小于52岁,风险等级为低风险。
实施例3基于社区2型糖尿病患者的心脑血管事件5年风险预测
1资料与方法
1.1资料:资料来源本研究中用于构建模型的训练样本数据来源于青岛市黄岛区疾病预防控制中心的慢性病管理系统。该系统于2009年启动,以社区服务中心为管理单位、以社区医生和乡村医生为管理实施者,截止2015年7月,共有20个社区中心、15062名2型糖尿病患者。验证样本来源于“山东多中心健康管理纵向观察大数据库”,有2次以上体检记录的2型糖尿患者。入选、剔除标准为防止由于随访时间短而造成的估计偏差,本研究训练样本选择2009年1月至2011年12月期间诊断为2型糖尿病、年龄为35岁以上、录入系统且无重要信息缺失的患者3319人;剔除406名在诊断2型糖尿病前有心脑血管病史的患者、以及随访过程中失访的14名患者,最终纳入2899人。验证样本中,35岁以上、无重要变量缺失且诊断糖尿病前未发生心脑血管病的2型糖尿病患者共有1016名。1.2方法:调查内容与方法包括人体测量指标、实验室指标以及问诊情况。以上3部分调查内容均由医务人员测量或询问。cvd诊断方法黄岛地区心脑血管数据库中记录的、由心电图或造影确诊的cvd事件,包括冠心病(icd10编码:i20-i25)和脑卒中(icd10编码:i60,i61,,i63,i64)或由于心脑血管事件导致的死亡(icd10编码:r96.0-1)。
1.3统计学处理采用sas9.4统计分析软件。连续型变量以
为方便使用,利用弗明翰评分方法将该cox模型转化为评分模型,主要包括以下几个步骤:(1)应用cox回归模型得到每个变量的回归系数;(2)将连续型变量离散化后转化为分类型变量,并以每一段的中位数为该段的参考值wij;(3)在每个分类变量中选择一个参考值作为风险参考因子wiref;(4)计算每一类参考值与参考风险因子的距离(wij-wiref);(5)设定一个评分常数b=5*βage;(6)设定评分pointi=int{βi(wij-wiref)/b};(7)估计总分对应风险
以auc评价模型的判别能力,以hosmer-lemeshow检验评价模型的校准能力。分别使用5折交叉验证法和独立的验证样本对模型的稳定性进行内部验证和外部验证。
绘制平均风险线和低风险线。平均风险线绘制方法,计算队列中各个体的未来5年cvd发病风险,分年龄agei,i=35,36,……,80计算平均发病风险
2结果2.1一般特征截止2015年7月,训练样本队列中位随访时间为5.0年,期间共发生心脑血管病228例,发病密度为16.86‰;验证样本队列中位随访时间为2.35年,发生心脑血管事件96例,发病密度为35.4‰。训练样本队列发病密度低于验证样本队列的发病密度(p<0.001)。
训练样本队列发生心脑血管事件和未发生心脑血管事件的2型糖尿病患者基线情况见表7
表7训练样本队列和验证样本队列患者基线情况
2.2cox比例风险模型结果表8展示了逐步选择法后最终入选模型的变量有年龄、性别、低密度脂蛋白、高密度脂蛋白、收缩压和cvd家族史。吸烟、舒张压、bmi、腹型肥胖均未纳入最终模型。入选变量之间未发现有交互作用。模型auc为0.678(95%ci0.660-0.695),hl卡方值为17.94,p=0.022。
表82型糖尿病患者未来5年内发生cvd事件的cox比例风险回归模型结果
2.3评分模型结果表9为经弗明翰评分转换得到的评分模型结果。表10为糖尿病患者总分对应的5年内发生心脑血管事件的风险。评分模型auc为0.663(95%ci:0.648-0.680),hl卡方值为6.69,p=0.57。总分小于5分时,2型糖尿病患者5年内发生cvd事件的概率小于10%,对应粗发病率为1.82%;总分在5~13分时,2型糖尿病患者5年内cvd发病风险为10%~30%,实际粗发病率为6.79%;总分大于13分的2型糖尿病患者5年内cvd的发病风险大于30%,实际粗发病率为12.49%。在该评分模型中,每增加一分,对应风险提高约2.61%(95%ci:2.58%-2.63%)。
表92型糖尿病患者未来5年内发生cvd事件的评分模型结果
表10评分模型总分对应的5年cvd发病风险
2.4模型验证训练样本经5折交叉验证法验证后,cox模型auc为0.676(95%ci:0.659-0.693);评分模型auc为0.619(95%ci:601-0.637)。经过验证队列验证,本研究构建的cox比例风险模型auc为0.643(95%ci:0.608-0.676),hl卡方值为8.71,p=0.37;评分模型外部验证后auc为0.620(95%ci:0.592-0.648),hl卡方值为3.11,p=0.93。
2.5平均风险线和低风险线如图7,例某体检者,年龄57岁,女性,高密度脂蛋白为1.11mmol/l,低密度脂蛋白为3.12mmol/l,收缩压为140mmhg,无cvd家族史,经计算未来五年发生cvd风险为9.97%,风险年龄为62岁,风险等级为高风险等级。
实施例4基于健康管理人群心血管事件风险预测模型及利用该模型进行预测
1资料与方法:1.1资料资料来源本研究数据来源于“山东多中心健康管理纵向观察大数据队列”。研究对象入选标准至少有1次纵向观察记录,年龄20岁以上,且入选时无心脑血管事件记录者。最终共72843名研究对象纳入队列,平均随访时间为(3.81±2.53)年,男性41610人,女性31233人。
1.2方法1.2.1指标测量研究数据包含了研究对象的实验室检测、常规体格检查以及健康问卷调查结果。所有研究对象在空腹状态下采集血样及尿样进行实验室检测,常见的检测项目如血常规、尿常规等;常规体格检查包括身高(m)、体质量(kg)以及血压(mmhg);健康问卷调查包括研究对象的日常饮食、睡眠、运动及吸烟饮酒情况。心电图数据包含研究对象心电图测量结果,并根据《明尼苏达编码》进行分类编码。
1.2.2心血管事件定义心血管疾病国际疾病分类(internationalclassificationofdiseases-10,icd-10)编码包括i05-i09、i11、i20-i27、i30-i52。脑血管疾病icd编码包括i60~i69。此次研究根据数据库中的疾病诊断进行心血管事件结局判断。心血管事件包括:冠心病、心绞痛、冠状动脉粥样硬化、心肌梗死、冠状动脉供血不足、冠状动脉闭塞、冠状动脉狭窄、急性冠状动脉综合征、冠状动脉血栓形成、脑梗塞、短暂性脑缺血发作(频繁)、脑卒中、脑血栓形成、脑干梗塞、脑血管供血不足、脑出血、脑动脉栓塞、脑血管意外、脑血管破裂、多发性脑梗塞、脑梗死、肺心病(出现右心衰竭者)、充血性心力衰竭、急性左心衰竭、左心衰竭、心功能ⅲ级、心功能ⅳ级、心力衰竭、心肾衰竭等。
1.2.3高血压、糖尿病及血脂异常定义根据《中国高血压防治指南(2010)》高血压定义为收缩压≥120mmhg和(或)舒张压≥90mmhg或医保数据库中有明确诊断者;根据《中国2型糖尿病防治指南(2013)》糖尿病定义为空腹血糖≥7.0mmol/l和(或)葡糖糖负荷后2h血糖≥11.0mmol/l或医保数据库中有明确诊断者。血脂异常通常指血浆中胆固醇和(或)甘油三酯(tg)升高,俗称高脂血症。但实际上高脂血症也泛指包括高密度脂蛋白血症在内的各种血脂异常。1.3统计学处理统计描述及建模采用sas9.4和r3.3.3软件。计算体检队列心血管事件的发病密度,对基线变量进行描述性分析,连续型变量采用
考虑到竞争风险的存在,避免其对终点事件概率的估计偏差,采用fine和gray提出的部分分布竞争风险模型(competingriskmodel)构建心血管事件风险预测模型。本研究中,采用受试者工作特征曲线下面积(areasundertheroccurves,auc)衡量模型的辨别能力。通过r3.3.3软件加载包“cmprsk”和“survival”进行部分分布风险回归分析,加载包“proc”绘制roc并计算auc。随机抽取70%体检人员作为训练组,其余30%体检者作为校验组对其进行组内验证,并使用十折交叉验证法检验模型稳定性。
绘制平均风险线和低风险线。平均风险线绘制方法,计算队列中各个体的心血管事件发病风险,分年龄agei,i=20,21,……,90求平均发病风险
2结果2.1队列情况队列随访期间共发生心脑血管事件2463例,发病密度为88.79/10万人年,死于非心脑血管事件164例。
2.2一般情况2004年5月至2015年9月,共纳入体检队列72843人,平均随访年限为(3.81±2.53)年。对危险因素进行t检验、卡方检验,男女基线特征除年龄、异常q波无统计学差异外,男性的吸烟率、血脂异常率、高血压患病率及糖尿病患病率均高于女性,其中男性血脂异常率高达73.22%。由于心脑血管病的多种危险因素存在性别上的差异,故对体检队列人群分性别构建风险预测模型。见表11。
表11体检队列人群基线特征
2.3竞争风险模型结果纳入男性心血管事件风险预测模型的危险因素有年龄、是否吸烟、高血压、糖尿病、血脂异常、st-t改变、t波改变及异常q波;纳入女性心血管事件风险预测模型的危险因素有:年龄、高血压、糖尿病、血脂异常、st-t改变、心房扑动、心率异常及陈旧性心梗。见表12。
表12部分分布竞争风险模型分析结果
2.4模型预测能力及效度检验十折交叉验证法检验模型的稳定性,男性roc曲线下面积为0.836(95%ci:0.822,0.851),灵敏度为78.70%,特异度为74.80%;女性roc曲线下面积为0.886(95%ci:0.874,0.898),灵敏度为73.60%,特异度为89.10%。男性训练组roc曲线下面积为0.837(95%ci:0.821,0.853),最佳切点为6.3%,灵敏度为77.4%,特异度为76.0%,o/e值为0.984;女性为0.897(95%ci:0.880,0.913),最佳切点为4.1%,灵敏度为83.1%,特异度为82.7%,o/e值为1.11。男性校验组roc曲线下面积为0.838(95%ci:0.813,0.862),最佳切点为6.4%,灵敏度为78.4%,特异度为78.1%;女性为0.893(95%ci:0.872,0.914),最佳切点为3.3%,灵敏度为87.4%,特异度为77.6%。
2.5平均风险线和低风险线如图8所示,图8a为男性各年龄人群未来发生心脑血管事件的平均风险和低风险,图8b为女性各年龄人群未来发生心脑血管事件的平均风险和低风险。
例,某体检者年龄66岁,有高血压和糖尿病病史,血脂异常,t波改变,吸烟,经计算其未来5年内发生心脑血管时间的风险为5.90%,风险年龄为76,风险等级为高风险。
实施例5健康管理人群2型糖尿病发病风险预测模型
1资料与方法1.1资料:资料来源本研究数据来源于山东多中心健康管理纵向观察队列数据。入选标准选取基线未患糖尿病、至少有2次检查记录、且无重要信息缺失者进入队列,年龄20~75岁。经过筛选共有33445名体检者进入队列,其中男性18963人,女性14482人。
1.2方法1.2.1调查方法及内容体检内容包括常规人体测量指标、实验室检查指标和问卷调查三部分。
1.2.2诊断标准采用世界卫生组织(who)糖尿病诊断标准,空腹血糖≥7.0mmol/l和(或)葡萄糖负荷后2h血糖≥11.1mmol/l,确诊为2型糖尿病,并排除其他类型糖尿病;参照《中国高血压防治指南(2010)》,在未使用降压药的情况下,非同日3次测量血压,收缩压≥140mmhg和(或)舒张压≥90mmhg,确诊为高血压。
1.3统计学处理所有分析采用r3.3.2软件完成。体检队列各个指标的基线情况连续型变量以
绘制平均风险线和低风险线。平均风险线绘制方法,计算队列中各个体的代谢综合征的发病风险,分年龄agei,i=20,21,……,75求平均发病风险
2结果2.1基线特征描述见表13。队列共纳入33445人,男性18963人,女性14482人。入选者平均随访时间为(3.68±2.8)年,男性平均随访时间为(3.67±2.78)年,女性平均随访时间为(3.70±2.82)年。男性吸烟率、饮酒率和高血压患病率均高于女性。
表13队列人群2型糖尿病发病与非发病者基线特征
2.2发病密度随访期间共确诊1624例新发2型糖尿病病例(其中男性1044例,女性580例),总发病密度为13.18‰,男性发病密度为15.00‰,女性发病密度是10.83‰。
2.32型糖尿病风险预测模型见表14。预测模型采用多因素cox比例风险回归。男性预测模型中用于预测t2dm的因素包括年龄、体质量指数、空腹血糖、甘油三酯、谷丙转氨酶、白细胞计数6个指标;女性预测模型纳入的因素包括年龄、空腹血糖、甘油三酯、高密度脂蛋白胆固醇、谷丙转氨酶5个指标。
表14多因素cox回归分析结果
2.4模型的预测能力,男性预测模型的auc为0.795(95%ci:0.764~0.827),最佳切点为6.4%,灵敏度和特异度分别为66.0%、84.0%,十折交叉验证的平均auc为0.796;女性预测模型的auc为0.707(95%ci:0.654~0.759),最佳切点为5.7%,灵敏度和特异度分别为47.3%、90.0%,十折交叉验证的平均auc为0.710。
2.5各年龄人群未来发生2行糖尿病的平均风险和低风险如图9所示,(图9a为女性风险图,图9b为男性风险图)。
举例,某体检者40岁,空腹血糖5.6mmol/l,甘油三酯1.33mmol/l,高密度脂蛋白0.39mmol/l,谷丙转氨酶28.1mmol/l,经计算其未来3年糖尿病的发病风险为8.52%,风险年龄为大于50岁,分割线等级为高风险。
- 还没有人留言评论。精彩留言会获得点赞!