一种基于深度学习的舆情热点类别划分方法与流程
本发明涉及深度学习和自然语言处理技术领域,尤其是一种基于深度学习的舆情热点类别划分方法,方法是一种具体应用于舆情分析的舆情热点科学类型划分的中文文本分类方法。
背景技术:
在如今信息技术高度发达的年代,社会上某个事件发生后,广大群众可以迅速通过各种途径了解到事情的来龙去脉,随之产生大量的评论。这就是舆情,对于民众舆情的分析对后续如何处理事件起着至关作用。在分析某一舆情热点之前应先对其进行科学的类型界定。比如热点事件一般可以分为突发自然灾害事件、生产安全事故、群体性事件、公共卫生事件、公权力形象、司法事件、经济民生事件、社会思潮、境外涉华突发事件等。类型界定的正确与否,对后续事件的分析比较,应对政策的制定都极为关键。
现有的相关技术有相近专利cn201310072137.3公开了一种网络舆情分析方法,以主题匹配代替简单舆情分析中的词语匹配,分析并判断页面是否属于舆情,属于一个二分类的问题。专利cn201410023154.2涉及一种基于情感分析和隐马尔科夫模型融合的方法,通过利用情感倾向性信息,提高了股市预测的准确性。
通过调查和分析发现,现有技术存在以下问题:
(1)舆情热点信息由于其特殊性,文本的长度不确定,对于较长的文本若采用传统的文本表示方法,对于数据降维处理而言难度较大;
(2)仅考虑数据的情感倾向性信息,对分类判断的特征提取单一,无法提取更深层次的特征,分类的效果不佳;
(3)现有舆情热点的分类技术,大部分是舆情的二分类,缺乏对舆情热点种类划分更细致的解决方案。
技术实现要素:
发明目的:本发明针对来源于舆情热点事件的文本数据,为解决现有技术的分类功能不足,准确率不高的问题,提出一种基于深度学习的舆情热点类别划分方法。
技术方案:为实现上述技术效果,本发明的技术方案为:
一种基于深度学习的舆情热点类别划分方法,该方法包括两个阶段,第一个阶段为训练阶段,第二个阶段为分类阶段;
训练阶段包括步骤:
(1)采集满足需求量的包含舆情热点的文本数据作为训练数据,并根据舆情热点的种类在训练数据中添加标签;对采集到的训练数据进行预处理,将训练数据保存为统一格式并构建训练数据中文词典;
(2)根据训练数据中文词典建立训练数据概率主题模型,并采用gibbs抽样方法学习训练数据概率主题模型,得到训练数据的文档-主题分布矩阵和主题-词汇分布矩阵,并依据文档-主题分布矩阵采集训练数据的分类标签,将主题-词汇分布矩阵作为深度学习模型所需训练矩阵;
(3)建立深度学习模型,所述深度学习模型包括具有多层隐层的dbn神经网络和softmax层,所述dbn神经网络的最后一层隐层的输出数据作为softmax层的输入数据,softmax层作为所述深度学习模型的输出层,对dbn神经网络的输出结果进行归一化处理;
(4)将训练数据、训练数据中文词典、训练数据的分类标签输入深度学习模型进行循环训练,并保存满足预设指标的最优深度学习模型;
分类阶段包括步骤:
(5)采集预测数据,根据舆情热点的种类在预测数据中添加标签;对采集到的预测数据进行预处理,将预测数据保存为统一格式并构建预测数据中文词典;
(6)根据预测数据中文词典建立预测数据概率主题模型,并采用gibbs抽样方法学习预测数据概率主题模型,得到预测数据的文档-主题分布矩阵和主题-词汇分布矩阵,并依据文档-主题分布矩阵采集预测数据的分类标签;
(7)将预测数据,预测数据分类标签和预测数据中文词典输入步骤(4)得到的最优模型,最优模型根据预测数据词典将输入的预测数据映射为输入层大小的矩阵,最优模型的输出层预测数据的多分类的结果进行归一化处理并根据预设阈值选择出预测数据的一种类别或一组类别。
进一步的,所述训练数据和预测数据的采集方法为:从网络公开新闻语料库中直接获取和/或通过网络爬虫从网络新闻中爬取。
进一步的,所述预处理的具体步骤包括:
a、统一数据的格式:将采集到的xml文件去掉尖括号,转存为txt格式;将每个xml文件命名为:舆情热点种类标签+文件编号;
b、将每类文件存为一个txt文件,txt文件中每一行为一条新闻数据,txt文件名为舆情热点种类标签;txt文件的总数目为舆情热点的种类数目;
c、采用中文分词工具对采集的文本数据进行分词表示和去除停用词处理,得到文本数据的中文词典;中文词典中,每个中文单词对应一个索引号,中文词典的每一行为:一个单词+该单词的索引号。
进一步的,所述构建训练数据概率主题模型的步骤包括:
1)对采集到的训练数据中的每篇文档中的每个词随机的赋值一个话题编号;
2)重新遍历训练数据,对每篇文档的每个词,按照gibbs采样公式重新采样话题编号,然后对训练数据中的每个词所属的主题编号进行更新,更新即为重新对每个词进行随机赋值;
3)重复步骤2)所述的对训练数据的采样过程,直到采样结果收敛;
4)采样收敛后,统计训练数据中话题词汇频率矩阵,即为主题-词汇分布矩阵。
进一步的,所述得到最优深度学习模型的步骤包括:
(5-1)将训练数据、训练数据中文词典、训练数据的分类标签输入深度学习模型,并根据训练数据中文词典将输入数据映射为深度学习模型输入层形式的矩阵;
(5-2)将读取的训练数据划分为训练数据集和测试数据集,所述训练数据集参与深度学习模型的训练过程,测试数据集用于测试每次训练的准确率;
(5-3)设置每次训练的数据集大小和最大迭代次数,初始化深度学习模型;
(5-4)将训练数据集中的数据分批次送入深度学习模型,计算每次训练的损失函数,所述损失函数用于描述深度学习模型的输出结果与实际期望结果的误差;采用梯度下降的方法来最小化损失函数,每下降n步,就用测试数据集测试训练数据的准确率;
(5-5)循环执行步骤(5-4)直至满足预设的迭代次数或者训练数据的准确率达到预设期望值,此时的深度学习模型为最优深度学习模型。
有益效果:与现有技术相比,本发明具有以下优势:
本发明是针对舆情热点数据的特殊性和现有技术的不足之处,将lda概率主题文本表示方法和dbn神经网络模型相结合,实现了高准确度多分类的效果。本算法的优点可以分为两个方面:
一是可以对不同长度的文本数据进行规格化表示和主题划分,实现了初步的数据降维过程,提供了分类算法的效率。
二是dbn神经网络相较于其他复杂的网络模型简单,“无监督训练+有监督微调”的训练方式,使得在保证分类准确率的前提下,训练阶段的时间花费较少,也降低训练的复杂度。神经网络输出层选择softmax回归模型,将多分类的结果进行归一化处理并根据预设阈值选择出预测的一种类别或一组类别。实现了舆情热点信息的深层特征的自动提取,使得舆情热点多种类划分更加准确。
附图说明
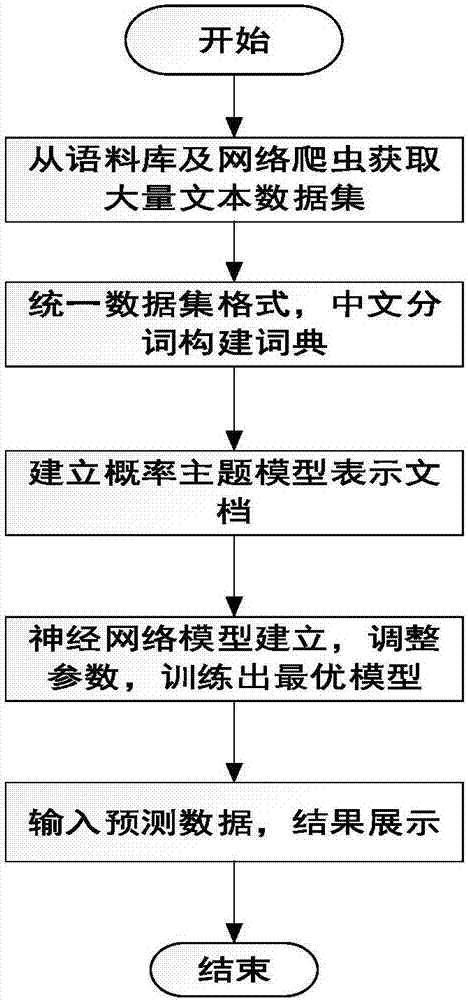
图1是本发明所述基于深度学习的舆情热点类别划分方法的流程图;
图2是lda概率模型示意图;
图3是dbn神经网络模型示意图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
本发明的整个流程划分为两个阶段,前期的模型训练阶段和后期的预测分类阶段。这两个阶段对于数据集的预处理过程和概率主题表示过程相似,也就是说我们读入神经网络中的文本表示在两个阶段是一样,不同的是前期的文本用于模型的训练,后期的文本用于进行结果分类预测。
下面根据附图来进一步的描述本发明的技术方案。
图1是本发明实施流程图,在具体实施的过程中可以分为两个阶段。第一阶段,包括训练数据集的采集、预处理过程、概率主题文本表示和深度学习模型的训练部分。第二阶段,包括预测数据的选取和预处理和概率主题文本表示,读取第一阶段的训练好的模型,进行分类预测。具体为:
(一)第一阶段:
1.训练数据的采集和预处理
(1)数据集采集:
训练数据集的来源有两种,一种是选用网上公布的新闻数据集主要有搜狗实验室的新闻语料和网易新闻语料,根据舆情热点的种类进行人工的划分添加标签。另一种方式采用爬虫程序按照种类从国内各大主流的媒体采集数据,添加标签。两种合一,构成大数据集合。
(2)预处理:
a、统一数据集的格式。将采集到的xml文件去尖括号,转存为txt格式。xml文件文件的名字为舆情热点的种类标签+文件编号;
b、每类文件存为一个txt文件,其中每一行为一条新闻数据;txt文件的文件名为为舆情热点的种类标签,txt文件的数目为舆情热点的种类数目。
c、采用中文分词工具对采集的中文文本数据进行分词表示,去停用词并构建中文词典。
2.概率主题模型的建立
依据经预处理建立的词典将文本表示成文档-主题(doc-topic)的分布和主题-词汇(topic-word)的分布,并依据文档-主题(doc-topic)来进行人工神经网络分类标签采集,主题-词汇(topic-word)矩阵则为神经网络所需训练矩阵。
3.深度学习模型的建立
深度学习训练模型选择深度置信网络(dbn),是由两层受限玻尔兹曼机(rbm)组成的有向图连接模型,其中第一层为可视层(v)也叫作输入层,它由m个可视节点组成,第二层为隐层(h),也就是特征提取层,由n个隐藏节点组成。建立具有三层隐层的dbn神经网络。输出层选择softmax层。
4.输入数据,进行深度学习模型训练,保存最优模型
(1)深度学习模型读取输入数据,输入数据标签和输入数据中文词典,并根据输入数据中文词典将输入数据映射为深度学习模型输入层大小的矩阵。
(2)将读取的训练数据划分为train集和test集,并设置每次训练的数据集大小,按照每批次迭代的数据集大小计算最大迭代次数。
(3)初始化神经网络模型。
(4)将训练数据分批次输入模型,并计算损失,在一定的迭代次数用test数据集测试accuracy。
(5)在迭代次数内,循环训练。直到accuracy达到预期。保存最优模型。
(二)第二阶段:
1.预测数据的在线采集和预处理
利用爬虫程序,在国内主流的网站上采集待分析的文本数据,采取和第一阶段一样的预处理过程。
2.概率主题模型的建立。
3.读取第一阶段的最优模型,输入预测数据,做出预测
读取第一阶段也就是模型训练时的最优模型,读取预测数据,预测数据标签和预测数据词典,并根据预测数据词典将输入的预测数据映射为输入层大小的矩阵。分类输出层softmax回归模型,将多分类的结果进行归一化处理并根据预设阈值选择出预测的一种类别或一组类别。
4.分类结果的展示。
展示有两种选择:a.对输入数据,预测模型给出对应的预测所分某一种种类。b.设置类别数目的阈值,预测模型给出输入数据的一组类别的名称和相应的概率。
图2所示为lda模型的训练细节。假设我们收集的待分类的原始文本数据集中有d篇文档,其中所有的词汇表示为:w=(w1,...,wd)。去词汇对应的主题表示为:z=(z1,...,zd)。其中wm表示的是第m篇文档中的词汇,zm表示为这些词对应的主题的编号。
如图2所示,lda概率模型主要有两个物理过程:
最后根据图3介绍dbn模型的训练细节。
dbn是由两层rbm组成的有向图连接模型,在预训练过程中,左侧x是输入,右边y是输出。当所有层训练结束后,由最上层开始向下有监督的进行微调。如图3所示训练一个具有三个隐藏层的dbn。其中w1,w2,w3即为从特征中学习到的特征计算所得到的权值。
dbn模型是基于受限玻尔兹曼机模型(rbm)作为网络的基本建模单元,rbm网络共有两层,其中第一层为可视层(v)也叫作输入层,它由m个可视节点组成,第二层为隐层(h),也就是特征提取层,由n个隐藏节点组成。如图所示的dbn模型则是在靠近可视层的部分使用有向图连接,在远离可视层的部分使用rbm。
dbn模型的训练包括无监督的预训练和有监督的微调两部分。
在预训练过程中,首先将可视向量值映射给隐藏节点,然后可视节点由隐藏节点重构;这些新的可视节点再次计算隐藏节点的数值,重构激活的隐藏节点,这样就获取新的隐藏节点。隐层和可视层输入之间的重构误差作为权值更新的主要计算依据。
在有监督的微调过程中使用contrastivewake-sleep算法进行优化,除了顶层的rbm,其他层的rbm的权重被分为向上的认知权重和向下的生成权重。
监督的微调过程还包括以下两个阶段:
wake阶段:认知过程中,通过外界的特征和向上的权重(认知权重)产生每一层的抽象表示,并且使用梯度下降修改层间的下行权重(生成权重)。
sleep阶段:生成过程,通过顶层表示和向下权重,生成底层的状态,同时修改层间向上的权重。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!