一种通用论坛正文提取方法与流程
本发明涉及网络信息处理技术领域,尤其涉及一种通用论坛正文提取方法。
背景技术:
随着互联网的快速发展,论坛网页数据量越来越庞大,汇聚着人类的知识,反映了社会热点。有效挖掘出论坛网页的有价值信息,能使网页信息得到更充分的利用,提升网页数据的有用性。论坛包含大量有价值信息的同时也包含大量噪声,而且由于不同论坛网页的数据结构各不相同,寻找一种通用的方法从网页中提取有用信息变得更加困难。
若针对某一类型的网站根据其特定的标签和属性来设计爬取算法,则无法满足高效性和普遍性地提取。目前的通用新闻网站爬取算法主要利用新闻网页的字符分布情况、正文字符量大以及内容与主题的相关度等特性来提取信息,但不同论坛网页的正文字符数变化幅度大,且发表和回贴的信息相对比较分散,故新闻网站的通用爬取算法对于论坛网页这些算法难以取得理想的效果。
技术实现要素:
本发明提供一种通用论坛正文提取方法,以解决现有技术无法高效性、普遍性地从不同类型的论坛网页中提取其有用信息的问题。
本发明提供一种通用论坛正文提取方法,包括以下步骤:
a、提取出网站完整的html代码,探测该网页编码格式,并统一编码为utf8格式;
b、解析html标签类型,获得网页的dom树,提取标题信息和包含发表时间信息的div标签内容,过滤无用信息后对已提取信息进行分类并生成列表;
c、计算列表数据长度,以时间为标记分类列表信息并格式化输出。
在本发明的通用论坛正文提取方法中,在步骤a之前还包括以下步骤:
向网站发送请求信息,在请求时添加headers,模仿浏览器请求;
通过浏览器返回的response,读取cookie保存到本地,第二次访问网站时,在请求信息中添加保存在本地的cookie。
在本发明的通用论坛正文提取方法中,所述步骤a具体包括:
使用探测法对html代码进行解码,首先采用utf8进行解码操作,如果成功,就返回解码后的网页内容;否则再分别采用gb2312、gbk解码,并统一编码为utf8格式。
在本发明的通用论坛正文提取方法中,所述步骤b具体包括:
b1、基于已编码为uft8格式的数据,解析获取网页dom树,提取<title>标签内容即为论坛标题;
b2、去掉网页头部和尾部的内容,提取中间部分包含时间的div标签内容;
b3、去除javascript、css代码部分以及a标签内容;
b4、应用正则表达式匹配可能出现的时间格式,从上述步骤处理过的div标签中进一步筛选出包含时间的孩子节点,并提取出所述包含时间的孩子节点中的文本内容,并过滤掉该孩子节点中其余的无用内容和垃圾信息;
b5、以时间标记分割字符串,对已提取的信息粗略分类,并生成列表。
在本发明的通用论坛正文提取方法中,所述步骤b2具体包括:
遍历<body>的孩子节点,去掉头部和尾部的非div标签内容,获取中间部div标签;
应用正则表达式逐个匹配所有可能出现的时间格式,搜索上述获取的中间部分div的标签,提取包含时间的div标签内容。
在本发明的通用论坛正文提取方法中,所述步骤c具体包括:
c1、计算所述列表的数据长度,如果数据长度等于3且只有一条时间信息则转到步骤c2,如果数据长度大于3时则转到步骤c3,如果数据长度等于2则转到步骤c4;
c2、以时间为标记将列表数据分割成三部分,根据字符比重去噪后转到步骤c4;
c3、如果列表数据长度为2的倍数,则转到c4;否则判断列表第一位数据和最后一位数据包含字符所占比重,去除字符所占比重少的一位数据后转到步骤c4;
c4、列表中的数据去除噪声后,根据列表第一位数据是否包含时间内容确定列表格式;
c5、将列表数据转换成字符串并写入文件中,并将已提取的标题和发表时间写入文件。
在本发明的通用论坛正文提取方法中,所述步骤c2具体包括:
以时间为标记将列表数据分割成第一位、第二位以及第三位;
判断第一位数据和第三位数据的字符所占的比重,字符少的则认为是噪声,将它去掉。
在本发明的通用论坛正文提取方法中,所述步骤c4具体包括:
如果第一位数据包含时间内容则列表的格式为时间在前、内容在后;如果第一位数据不包含时间内容则列表的格式为内容在前、时间在后。
本发明的通用论坛正文提取方法至少包括以下有益效果:为有效挖掘出不同论坛网页有用信息,本发明基于论坛网页html文本的结构特点以及网页内容的文字特点,结合网页的dom树,采用解析标签方法对论坛网页进行信息提取和信息去噪,能够准确提取其主贴、回帖、标题和发帖时间的相应数据字段并格式化输出,使论坛信息得到更好的利用。
附图说明
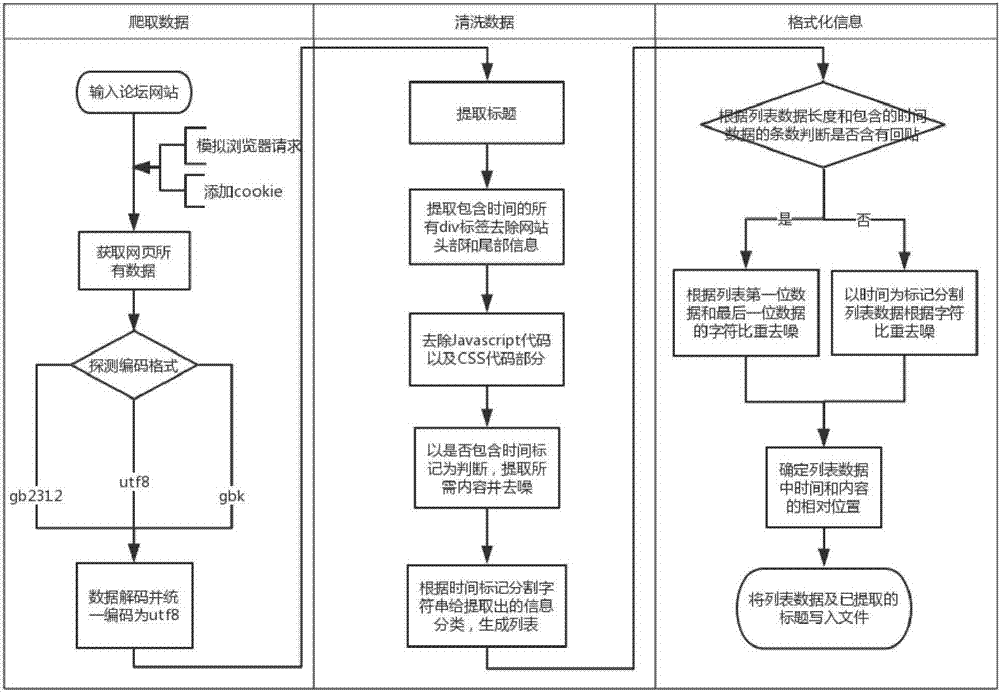
图1是本发明的通用论坛正文提取方法流程图;
图2为本发明实施例论坛网页的dom树简图。
具体实施方式
为使本发明的技术方案更加清晰,下面结合图1所示的通用论坛正文提取方法流程图详细说明本发明的具体实施方式。
本发明的通用论坛正文提取方法包括如下步骤:
a、爬取数据:抓取网站所有信息,即提取出网站完整的html代码,探测该网页编码格式,并统一编码为utf8格式以便于后续处理;
b、清洗数据:基于已编码为uft8格式的数据,应用beautifulsoup解析html标签类型,获得网页的dom树,如图2所示,提取标题信息和包含发表时间信息的div标签内容,过滤无用信息后对已提取信息进行分类并生成列表;
c、格式化信息:计算列表数据长度,以时间为标记分类信息并格式化输出。
由于有些网站设置了反爬虫机制,故在步骤a之前还包括反爬虫处理步骤,针对反爬虫的几种常见情况进行处理,具体包括:
(1)模拟浏览器请求:向网站发送请求信息,在请求时添加headers,headers里面包含user-agent,模仿浏览器请求;
(2)添加cookie:第一次访问时由于没有cookie,浏览器将拒绝访问请求。通过浏览器返回的response,读取cookie保存到本地,第二次访问网站时,在请求信息中添加保存在本地的cookie。
反爬虫处理步骤后开始抓取网站所有信息,具体实施时,步骤a包括数据解码和编码操作:
使用探测法对html代码进行解码,首先尝试使用utf8进行解码操作,如果成功,就返回解码后的网页内容;否则再分别尝试gb2312、gbk解码,并统一编码为utf8格式。已知国内网站大部分编码有utf8、gb2312、gbk三种,故针对这三种编码,对爬取的内容进行解码。
通过以上处理,成功爬取该网页所有html数据,下面进入数据清洗步骤。
具体实施时,步骤b具体包括如下步骤:
b1、提取标题:基于已编码为uft8格式的数据,解析获取网页dom树,提取<title>标签内容即为论坛标题,如图2所示。
根据论坛网页标题与论坛的标题一致的特点,只需提取网页的标题作为论坛内容的标题,且网页主要用<title>标签来显示网站的标题,故用beautifulsoup解析网页dom树,提取<title>标签内容即为论坛标题。经过大量的测试表明,该方法有效可行,噪声小。
b2、初步清洗:去掉网页头部和尾部的内容,提取中间部分包含时间的div标签内容。
通过访问样例网站发现,论坛网站的构成包括头部、中间部和尾部。头部主要是登录、注册和网站模块等信息,尾部为发表回复、相关链接以及法律声明,中间部里面的内容包含了有用信息。通过查看网页代码发现,中间部分都是用div标签分块,论坛网页中需要提取的内容都包含在div标签中,故通过遍历<body>的孩子节点,判断是否为div标签,去掉头部和尾部等非div标签内容,获取中间部div标签的代码,如图2所示。
进一步的,论坛类型网站中每层楼的发表信息都包含发表时间信息,故推断所需内容的div标签中一定包含时间信息。应用正则表达式,逐个匹配所有可能出现的时间格式(如2017/4/24或2017年4月24日等格式),搜索已经获取的中间部div标签,通过判断该div标签是否包含发表时间,提取包含时间的div标签内容。
b3、去除噪声:去除javascript、css代码部分以及a标签内容。
应用正则表达式及beautifulsoup的extract函数,去除javascript、css代码部分以及a标签内容。进一步去除了该网页的在b2步骤中已提取的div标签中的网页设置代码及广告链接部分、相关内容推荐链接等。
b4、提取正文和发表时间:应用正则表达式匹配可能出现的时间格式,从上述步骤处理过的div标签中进一步筛选出包含时间的孩子节点,并提取出所述包含时间的孩子节点中的文本内容,并过滤掉孩子节点中其余的无用内容和垃圾信息;
通过beautifulsoup遍历经b1、b2、b3步骤处理后的div标签。虽然获取的div标签包含了所需信息,但是也包含大量无用信息。为精确筛选出该网页的有效信息,进一步对已提取的div中包含发表时间的孩子节点进行过滤,在上述处理过的div标签中,提取包含时间的文本内容并过滤掉div标签中其余的无用内容和垃圾信息。具体清洗工作如下:
b5、初步分类:以时间标记分割字符串,对已提取的信息粗略分类,并生成列表。
由于主贴、每条回帖的div都包含时间信息且主帖在前、回帖在后,以时间标记分割字符串,则可分出各楼层的信息,对已提取的信息进行粗略分类,生成列表。
通过前面爬取、清洗、去噪、分类等操作,得到了包括时间和内容的一串内容数据列表,标题内容另外存储。下面介绍将该内容格式化存储到硬盘。在已提取的信息中,标题已提取完毕且无需进一步去噪,但由于程序需要适应所有的网站,在上面的操作中,并没有对特定的网站格式进行区分,即正文内容与发表时间仍未区分,例如有些bbs网页用户发表内容的结构是发表时间在前,接着是发表的内容;而有些网页是发表内容在前,发表时间在后。特别需要注意的是,在去噪过程中,对噪声的处理并不是很完美,而这会给格式化成特定格式提高了难度。进而进一步提出了一种基于字符噪声估计的算法将结果格式化成统一的格式。步骤c具体包括:
c1、计算所述列表的数据长度,如果数据长度等于3且只有一条时间信息,即只有主贴没有回帖,此时转到步骤c2;如果数据长度大于3时,即同时含有主贴和回帖,此时转到步骤c3;如果数据长度等于2,即只有主贴且没有噪声,此时转到步骤c4。
c2、以时间为标记将列表数据分割成三部分,根据字符比重去噪后转到步骤c4;
具体实施时,以时间标记分割列表数据,分割成第一位、第二位以及第三位,如:时间前的内容、时间、时间后的内容。根据字符比重去噪过程如下:
此时时间内容在第二位,则判断第一位数据和第三位数据的字符所占的比重,字符少的则认为是噪声,将它去掉。
c3、如果列表数据长度为2的倍数,则转到c4;否则判断列表第一位数据和最后一位数据包含字符所占比重,去除字符所占比重少的一位数据后转到步骤c4;
前面在形成列表的时候,每层楼的时间、正文依次间隔存储。如果没别的噪声,则恰好是2的倍数。若不是2的倍数,则需清除噪声干扰。判断列表数据长度能否被2整除,如果能则转到c4。否则根据字符比重去噪:判断列表第一位和最后一位数据的字符所占比重,如果第一位字符比较少,我们保留第二位到最后一位数据,去除第一位;否则保留第一位到倒数第二位的数据,去除最后一位数据。
c4、列表中的数据去除噪声后,根据列表第一位数据是否包含时间内容确定列表格式;
有些网站html里面提取出来的正文和时间信息前后顺序不一样,要区分出哪个是时间,哪个是正文,后面才能分类存储。在前面的列表还没有详细判断,故在这一步骤进行判断。去除了头尾不需要的部分,如果列表第一位数据包含时间,则列表格式为时间在前,内容在后;否则列表格式为内容在前,时间在后。
c5、将列表数据转换成字符串并写入文件中,并将已提取的标题和发表时间写入文件。
遍历列表,将列表数据转换成字符串并写入文件中,并将已提取的标题和发表时间写入文件;根据主贴在前回帖在后的原则,前面两个元素内容属于主贴,后面的都分别属于各层楼的回帖。
本发明的提取方法通用性强,能够适用于大多数论坛,能够准确提取其主贴、回帖、标题和发帖时间的相应数据字段并格式化输出,使论坛信息得到更好的利用。
以上所述仅为本发明的较佳实施例,并不用以限制本发明的思想,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!