一种英语在线学习中各种资源的组织与存储方法与流程
本发明涉及一种英语在线学习中各种资源的组织与存储方法,属于计算机软件技术领域,尤其涉及互联网教育技术领域。
背景技术:
在英语口语学习中,涉及到大量的音频、图片、文字等内容,目前通行的做法是将这些内容放到服务器上,每次需要时都从服务器上读取,需要频繁的查找访问,而且因为网络带宽的影响,会带来效率的下降。
现有的课程体系是一个课本包括若干个单元,一个单元包括若干个课程,一个课程又包含若干个段落,而每一段落,又包括若干句文本,并且每个句子有对应的音频,可能含有图片。而我们的组包方式是将这些内容按照一定的格式组织起来,加上版本号,处理成特殊的资源包,供用户下载到本地客户端使用。这样,只要资源包的版本号没有改变,学生只需要下载一次就可以,以后不再需要到服务器取音频、图片等文件,直接从本地读取,大大的提升了效率。
技术实现要素:
针对现有技术中存在的技术问题,本发明的目的在于提供一种英语在线学习中各种资源的组织与存储方法。本发明将所需资源按按照设定的方式组织起来,上传到云端,供学生下载到本地使用。
本发明的技术方案为:
一种英语在线学习中各种资源的组织与存储方法,其步骤为:
1)选取一课本的课本编码、一用于获取该课本所需资源的源目录;
2)根据该课本编码创建一课本目录,然后在服务端查询该课本编码包含的单元;
3)在该课本目录中创建若干子目录,即单元目录;
4)在服务端查询每一单元所包含的课程,再在该单元对应的单元目录中创建若干子目录,即课程目录;
5)在服务端查询每一课程所包含的段落,在每一课程对应的课程目录中创建若干子目录,即段落目录;
6)在服务端查询每一段落所包含的文本以及图片文件,根据文本中的音频文件名称在该源目录中找到对应的音频文件并将其拷贝到该段落对应的段落目录中,将该段落所包含的图片文件拷贝到该段落对应的段落目录中;
7)将该课本所包含的文字内容按照json格式组织起来,并保存到一个文件中,并在该课本目录中创建一子目录存储该文件;
8)对上述处理后的课本目录进行压缩,生成该课本编码对应的资源包并上传到云端。
进一步的,所述资源包的文件头中设置有资源包编码字段和资源包版本号字段。
进一步的,所述资源包编码字段中的资源包编码为该课本编码。
进一步的,所述步骤8)中,采用消息传递接口mpi对上述处理后的课本目录进行并行压缩,其方法为:
1)资源包生成端启动一主进程,根据资源包生成端的cpu数目设置若干个子进程;
2)采用消息传递接口mpi建立该主进程与各子进程之间的通信连接;
3)该主程序查询该课程编码所包含的单元并将其分配给各子进程;
4)各所述子进程对分配到的每一单元包含的文件内容、图像和音频文件进行压缩,生成该单元的压缩流;
5)各所述子进程将分配的单元压缩完成后,依次将各单元的压缩流发送给该主进程;
6)该主进程生成该课本目录对应资源包的文件头,然后接收各子进程的压缩流,每接收处理完一子进程的压缩流后销毁对应的子进程;当处理完各子进程的压缩流后,生成该课本编码对应的资源包。
进一步的,所述资源包的文件头中的文件特征码为一设定值。
本发明在组织资源包时,先指定课本编码(如rjs-7nx)与待选择文件的源目录(源目录可以是自己机器上的目录,或者本地局域网内其它机器开放的目录),源目录下包括音频文件、图片文件等内容。接着根据课本编码创建一个大目录,然后根据课本编码到服务端进行查询,查询到若干个单元,再对每一单元创建单元一级的单元目录;接着依次轮询各个单元,到服务端查询每一单元所包含的课程,再在该单元对应的单元目录中创建课程一级的课程目录;接着依次轮询各个课程,到服务端查询每一课程所包含的段落,再每一课程对应的课程目录中创建段落一级的段落目录;接着依次轮询各个段落,到服务端查询每一段落所包含的文本以及是否有图片文件,由于在文本记录中包括有对应的音频文件名称,所以再根据文本在源目录下找到对应的音频文件(不管在源目录哪一级),将它拷贝到当前段落目录下,如果还包含有图片,同样拷贝到当前段落的目录下。这样就形成一个比较大的目录树。
另外本发明将一个课本涉及的文字内容及角色、译文、顺序号等其它数据,按照json格式组织起来,并保存到一个文本文件中,形成一个json格式数据文件,放到单元那一级的目录,与各个单元并列。具体说来,一个课本就是一个json数据,有这编码、版本序号、名称等数据元素,并且还有着一个json数组,就是所有的单元形成的,在这个数组中,每个单元就是json单元数组中一个json数据;同理,每个json单元数据又有着一个json数组,就是这个单元的所有课程形成的,在这个数组中,每个课程就是json课程数组中一个json数据;同理,每个json课程数据又有着一个json数组,就是这个课程的所有段落形成的,在这个数组中,每个段落就是json段落数组中一个json数据;再同理,每个json段落数据又有着一个json数组,就是这个段落的所有句子形成的,在这个数组中,每个句子就是json句子数组中一个json数据;这样,要处理某个句子时,可以一级一级的找下来,不再需要另外的映射表。
所有的这些完成后,再以本发明的压缩工具继续处理。本发明的压缩工具是在lzma2算法基础据上做了改进,加入了特征自定义功能和并行压缩的功能,特征自定义,给压缩文件提供比较高的自由度用恰当的方式描述所压缩的数据的类型,说明这个是策腾公司的专有文件,压缩文件内包括有音频mp3文件、图片jpg文件、json格式数据文件,具体的内容包括:
1、修改了整个文件头,原来的文件头共32个字节,其中最前的六个字节是文件特征码,内容是{'7','z',0xbc,0xaf,0x27,0x1c};而本发明把最前六个字节的文件特征码改为了{'c','t',0x0c,0xoe,0x27,0x1c};
2、修改了细目头,新加了两个字段:coursecode,versionno。coursecode是字符串,意思是资源包编码,对应于课本的编码;versionno是整型,表示了资源包内部版本序号。
而并行压缩是现在很多人电脑都具备多核心处理器,能针对多核心进行优化以提升压缩性能,而本发明为了进行并行压缩,采用了mpi(messagepassinginterface消息传递接口)编程实现,mpi提供了一种与平台无关,可以被广泛使用的编写消息传递程序的标准,用它来编写消息传递程序,不仅实用、可移植、高效和灵活,而且可以在集群上使用,也可以在单核/多核cpu上使用,它能协调多台主机间的并行计算,因此并行规模上的可伸缩性很强。其主要流程如下所示:
1、引入并行处理单元mpi.h,准备进行并行处理。
2、运行程序,启动主进程,输入资源包编码,选择源目录。
3、进行并行处理的初始化,检查共有几个cpu,然后根据cpu数目生成若干个子进程。
4、在主进程和若干子进程进行通信检测,确保通信正常。
5、主程序根据课程编码查询所有的单元(即课程体系中的单元),然后把查出来的单元分配给若干个子进程。
6、子进程根据单元编码查找下属的课程编码(分核同时进行)。
7、子进程根据课程编码查找包含的段落(分核同时进行)。
8、子进程根据段落编码查找所包含的句子文本内容(分核同时进行)。
9、根据句子文本内容,到源目录下查找对应的文件,进行压缩处理,写入压缩流(分核同时进行)。
10、进行下一个单元的处理,直到分配的单元都处理完,依次将结果增添写入压缩流(分核同时进行)。
11、通知主进程,该子进程处理完毕,并提交处理完后的流。
12、主进程开始写文件,先写文件头,然后接收子进程的压缩流,每接收处理完一个压缩流,就销毁对应的子进程。
13、当所有的子进程处理完后,处理整个压缩文件,写入到硬盘;然后释放相关的资源,做程序终止处理。
最终形成设定的dat数据格式,由于本发明已经改写了资源包的文件头,带来的好处有:1、由于已经改写了文件头特征码,其它压缩工具识别不出来,所以用其它的解压缩工具无法打开,极大的提升了安全性;而本发明涉及到资源包解压缩的部分,也已经做了相应的修改,修改的内容有:对应的修改了解压缩的特征码和解压缩的细目头,如前所示,所以在本发明中可以正常打开,学生也不用另外安装解压缩软件。2、由于在文件头中,加上了资源包编码与版本信息,在与服务器进行版本比对时,从服务器查询到该资源包的最新版本序号,再读取本地资源包时的版本序号,如果服务器返回的版本序号是新的,说明有版本更新,需要重新下载替换,如果两者是一致的,就说明不需要替换。在读取本地资源包版本时,由于可以从文件头就读出,不需要读取整个文件,只读前面几十个字节就可以,极大的提升了效率。
与现有技术相比,本发明的积极效果:
1、因为在压缩前是从服务器取数据的,然后搜索相关文件的,所以不再需要一个个加入文件,极大的提高了编辑人员的工作效率。
2、由于采用了并行压缩,可以充分利用多核心处理器的优势,提高了压缩的效率。
3、由于采用了自己有的文件特殊格式,所以保密性、安全性上也大为提高。
附图说明
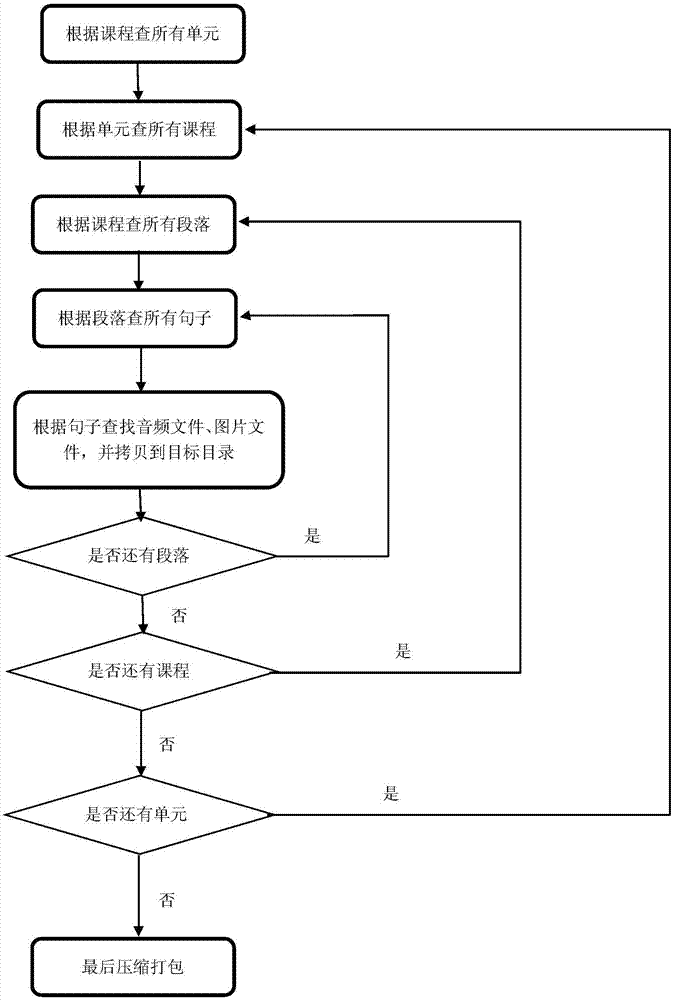
图1为本发明的资源包处理流程图。
具体实施方式
下面结合附图对本发明进行进一步详细描述。
如图1所示,本发明的整个流程为:
1、首先选择要组包的课本,并指定源目录,在本例中是人教社七年级下册,编码为rjs-7nx,系统会自动创建一个目录rjs-7nx。
2、接着根据这个编码rjs-7nx到服务端查询所有的下属单元,查询结果是共包括12个单元,编码从rjs-7nx-001到rjs-7nx-012。
3、再根据单元编码rjs-7nx-001,创建子目录,到服务端查询所有的下属课程,查询结果是该单元共包括7课,编码从rjs-7nx-00101到rjs-7nx-00107.
4、再根据课程编码rjs-7nx-00101,创建子目录,到服务端查询所有的下属段落,查询结果是该课程共包括1个段落,该段落的id是47。
5、再根据段落id47,创建子目录,到服务端查询所有的下属句子,查询结果是该段落共有5句,查询结果包括每句的音频文件名、图片文件名(如果有的话)。
6、然后到源目录下搜索,找到音频文件、图片文件,复制到刚创建段落目录下。
7、如果还有其它段落,重复5。
8、如果还有其它课程,重复4。
9、如果还有其它单元,重复3。
10、以本发明的压缩工具继续处理,在目录rjs-7nx下面,生成设定格式的资源包,名字是rjs-7nx.dat。
这个最后生成的文件就是本发明独有的资源包。
- 还没有人留言评论。精彩留言会获得点赞!