一种具备多任务驱动能力的多轮对话的方法和系统与流程
本发明涉及人机对话领域,特别涉及一种具备多任务驱动能力的多轮对话的方法和系统。
背景技术
在人机对话领域中,开放域聊天技术和任务型多轮对话技术是其中常见的两种。借助开放域聊天技术,人们可以在与智能机器聊天时不受话题限制且满足自身倾诉、陪伴、娱乐等情感诉求。借助任务型多轮对话技术,人们可以通过与智能机器的多轮对话获得订餐、订票等服务。但传统的开放域聊天和任务型多轮对话技术存在如下问题:
1.两者难以在一个统一的系统架构下同时实现;
2.在任务型多轮对话技术中,智能机器仅能将用户输入信息理解为一个意图,进而基于该意图执行唯一任务,而无法满足用户的多意图诉求。例如,用户对智能机器说“如果我出门时快下雨了,请提醒我带伞”,传统的任务型多轮对话技术仅会将该句子的意图理解为“查询天气”或“提醒带伞”中的一个,而用户的原始意图包含“感知出门时刻”、“查询天气”、“提醒带伞”三个。
技术实现要素:
针对上述开放域聊天技术和任务型多轮对话技术存在的问题,本发明的目的在于在一个统一的系统架构下同时实现开放域聊天及任务型多轮对话,同时可以感知用户的多个意图并向用户提供多个服务,即系统具备多任务驱动能力。
为达到上述发明目的,本发明提供的技术方案如下:
本发明一方面披露了一种具备多任务驱动能力的多轮对话方法,包括:接收用户的输入信息;确定所述输入信息的状态(state);根据所述状态生成一个或多个动作概念(action),其中,所述一个或多个动作概念分别包括生成一句话或调用一个应用程序接口(applicationprogramminginterface,api);以及执行所述一个或多个动作概念。
在本发明中,所述确定所述输入信息的状态,进一步包括:将所述输入信息分为一个或多个词(token);按所述输入信息中所述一个或多个词所在位置的顺序依次对所述一个或多个词进行信息提取,生成对应于所述一个或多个词的一个或多个状态;以及将最后一个词的状态作为所述输入信息的状态。
在本发明中,所述根据所述状态生成一个或多个动作概念基于一个策略模型(policymodel)。
在本发明中,所述策略模型是一个神经网络模型,包括但不限于递归神经网络(rnn)、卷积神经网络(cnn)。
在本发明中,所述神经网络模型基于语料库进行训练。
在本发明中,所述语料库包括对话预料和动作推理的相关数据。
在本发明中,所述一个或多个动作概念可以由名称(name)及一个或多个槽值对(slot-pair)组成。
在本发明中,所述执行所述一个或多个动作概念包括:同时执行所述一个或多个动作概念。
在本发明中,所述执行所述一个或多个动作概念包括:生成所述一个或多个动作概念所对应的一个序列;以及按照所述序列依次执行所述一个或多个动作概念,其中,前一个动作概念作为后一个动作概念的输入。
在本发明中,所述执行所述一个或多个动作概念包括:发送提示信息给用户,提示用户可以进行下一轮对话。
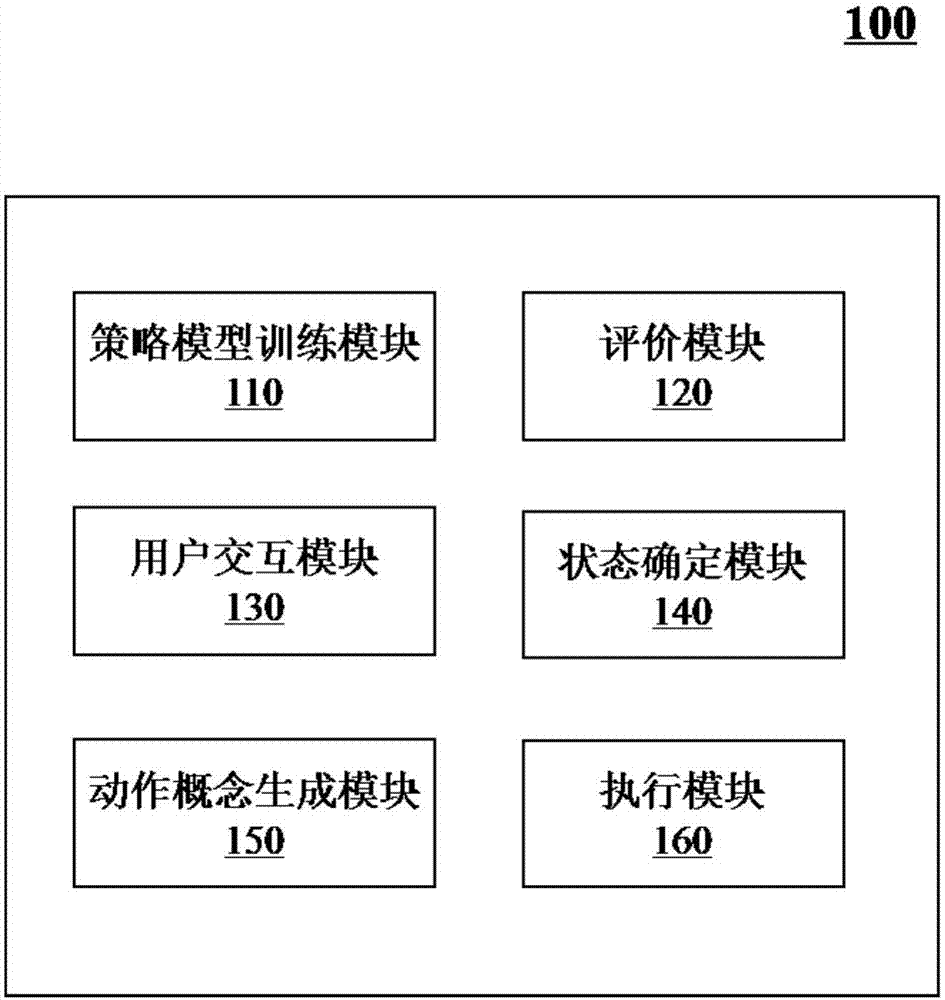
本发明另一方面披露了一种具备多任务驱动能力的多轮对话系统,包括:策略模型训练模块,所述策略模型训练模块被配置为训练一个策略模型;评价模块,所述评价模块被配置为强化或改进所述策略模型;用户交互模块,所述用户交互模块被配置为接收用户输入信息或向用户输出信息;状态确定模块,所述状态确定模块被配置为确定所述用户输入信息的状态;动作概念生成模块,所述动作概念生成模块被配置为调用所述策略模型,以生成一个或多个动作概念;以及执行模块,所述执行模块被配置为执行所述一个或多个动作概念。
附图说明
图1是根据本发明提供的一种具备多任务驱动能力的多轮对话系统的结构示意图;
图2是根据本发明提供的一种具备多任务驱动能力的多轮对话方法的流程示意图;
图1标记:110为策略模型训练模块,120为评价模块,130为用户交互模块,140为状态确定模块,150为动作概念生成模块,160为执行模块。
具体实施方式
下面通过具体实施例并结合附图对本发明做进一步描述。
如图1所示,所述具备多任务驱动能力的多轮对话系统,可以包括策略模型训练模块110,评价模块120,用户交互模块130,状态确定模块140,动作概念生成模块150,执行模块160。
策略模型训练模块110可以训练一个策略模型。所述策略模型可以基于语料库进行训练。在一些实施例中,所述语料库可以是在线的,也可以是离线的。在一些实施例中,所述语料库可以是单语语料库(如中文语料库、或英文语料库等),也是可以是多语语料库(如中英文语料库、中英法语料库等)。在一些实施例中,所述语料库可以包括对话语料和动作推理的相关数据。所述策略模型可以是一个神经网络模型,如递归神经网络(recurrentneuralnetwork,rnn)、卷积神经网络(convolutionalneuralnetwork,cnn)等。所述策略模型可以在每轮对话中被动作概念生成模块150调用。
评价模块120可以在多轮对话结束后.对所述多轮对话进行评价。评价模块120的评价指标可以包括但不仅限于多轮对话系统100是否完成任务(例如是否完成机票预订任务及天气查询任务)、对话过程是否与真人聊天接近(例如对话结束后,询问用户是否满意)。所述评价模块120可以强化或改进由策略模型训练模块110生成的策略模型。所述评价模块120可以是一个神经网络模型,如递归神经网络(recurrentneuralnetwork,rnn)、卷积神经网络(convolutionalneuralnetwork,cnn)等。
在一些实施例中,策略模型训练模块110和评价模块120可以是分开的两个模块。在一些实施例中,策略模型训练模块110和评价模块120可以合成为一个模块。例如,评价模块120可以配置为策略模型训练模块110的一部分,用于强化或改进由策略模型训练模块110生成的策略模型。
用户交互模块130可以与用户进行交互,例如,可以接收、发送数据。在一些实施例中,用户交互模块130可以接收用户的输入信息,发送至状态确定模块140进行进一步处理。所述进一步处理可以包括基于所述用户的输入信息确定所述输入信息的状态。在一些实施例中,用户交互模块130可以接收来自执行模块160的数据,如一句话,进行显示。在一些实施例中,所述用户的输入信息可以是一句简单表达情绪或感受的话(如“我很烦”、“我很累”等),也可以是一句隐含了一个或多个意图的话(如“帮我预订一张到上海的机票”、“如果我出门时快下雨了,请提醒我带伞”等)。在一些实施例中,所述用户的输入信息可以是一句信息明确的话(如“放阿甘正传”、“找附近的活鱼馆”等),也可以是一句信息模糊的话(如“找些好莱坞大片”、“附近好吃的都有哪些”等)。
状态确定模块140可以确定用户输入信息的状态。所述输入信息可以通过用户交互模块130输入。所述输入信息的状态可以是一个包含数值的张量。所述包含数值的张量可以包括本轮对话的信息,以及用户与多轮对话系统100对话的上下文信息等。所述本轮对话的信息可以是用户本轮对话的目的,例如订机票、订餐等。所述上下文信息可以是用户与多轮对话系统100的历史对话信息。例如,状态确定模块140在本轮对话中确定用户本轮对话的目的是“订本周六上午到上海的机票”,但在历史对话中,用户曾输入过“本周六晚上7点有同学聚会”的信息。则状态确定模块140确定的输入信息的状态不仅包含订票信息,也包含同学聚会提醒的信息。所述包含了订票信息、同学聚会提醒信息的输入信息的状态会被状态确定模块140发送至动作概念生成模块150进行进一步处理,以确定是否有时间冲突。如果有时间冲突,多轮对话系统100可以取消订票服务或取消聚会提醒服务。如果时间没有冲突,多轮对话系统100可以既完成订票服务也完成聚会提醒服务。
在一些实施例中,所述确定所述用户输入信息的状态,可以进一步包括:将所述输入信息分为一个或多个词;按所述输入信息中所述一个或多个词所在位置的顺序依次对所述一个或多个词进行信息提取,生成对应于所述一个或多个词的一个或多个状态;以及将最后一个词的状态作为所述输入信息的状态。所述一个或多个词可以包含一个字,如雨,也可以包含多个字,如北京。所述对所述一个或多个词进行信息提取包含但不仅限于提取所述一个或多个词的主题信息、行为信息、情绪信息、上下文信息等。在一些实施例中,当前词的状态可以基于上一个词的状态、当前词的信息提取结果和/或对话的上下文信息生成。
动作概念生成模块150可以生成一个或多个动作概念。动作概念生成模块150可以调用策略模型训练模块110生成的策略模型,基于状态确定模块140输出的输入信息的状态.生成所述一个或多个动作概念。所述一个或多个动作概念分别包括生成一句话或调用一个应用程序接口。例如,用户的输入信息为“你好”,则动作概念生成模块150可以基于状态确定模块140输出的输入信息的状态生成一句话,如“您好,请问有什么可以帮您吗”,以对用户的输入信息做出答复。再例如,用户的输入信息为“如果我出门时快下雨了,请提醒我带伞”,则动作概念生成模块150可以基于状态确定模块140输出的输入信息的状态先后生成一个用于调用“感知出门时刻”应用程序的应用程序接口、一个用于调用“查询天气”应用程序的应用程序接口、一个用于调用“提醒带伞”应用程序的应用程序接口。
所述一个或多个动作概念由名称(name)及一个或多个槽值对组成(slot-pair)。作为示例,所述一个或多个动作概念的名称为“表示感谢”;槽为“感谢程度”,槽值为“特别感谢”。作为另一个示例,所述一个或多个动作概念的名称为“机票预订”;槽1为“始发地”,槽值为“北京”;槽2为“目的地”,槽值为“上海”;槽3为“时间”,槽值为“当天中午12点”等。
执行模块160可以执行所述一个或多个动作概念。作为示例,当所述一个或多个动作概念为生成一句或多句话时,执行模块160可以将所述一句或多句话发送至用户交互模块130以答复用户的输入信息。作为另一个示例,当所述一个或多个动作概念为调用一个或多个应用程序接口时,执行模块160可以调用所述一个或多个应用程序接口以完成相应任务(如订餐、订票、购物等)。当所述一个或多个动作概念既有生成一句或多句话又有调用一个或多个应用程序接口时,可以同时或先后的生成一句或多句话以及调用一个或多个应用程序接口。
在一些实施例中,执行模块160可以发送提示信息给用户,提示用户进行下一轮对话。例如,用户的输入信息为“如果我出门时快下雨了,请提醒我带伞”,执行模块160依次执行调用“感知出门时刻”应用程序接口、“查询天气”应用程序接口两个动作概念,查询到用户的出门时间并查询了该时间的天气状况;执行模块160随后向用户交互模块130输出一句话“查询到您上午11点跟徐先生有约会,此时预报有中雨,请问您会准时出门赴约吗”,以提示用户进行下一轮对话;用户回复“会”;执行模块160则执行调用“提醒带伞”应用程序接口这一动作概念,执行完后再次向用户交互模块130输出一句话“好的,届时会提醒您带伞”;随后,用户可以输入新的语音信息,进入下一个话题的对话或就当前话题进行更详细的对话。
在一些实施例中,可以同时执行所述一个或多个动作概念。在一些实施例中,可以生成所述一个或多个动作概念所对应的一个序列;以及按照所述序列依次执行所述一个或多个动作概念,其中,前一个动作概念作为后一个动作概念的输入。
图2是根据本发明提供的一种具备多任务驱动能力的多轮对话方法的流程示意图。
如图2所示,在步骤210中,可以通过策略模型训练模块110,多轮对话系统100基于语料库预先训练一个策略模型。所述策略模型可以是一个神经网络模型,如递归神经网络(recurrentneuralnetwork,rnn)、卷积神经网络(convolutionalneuralnetwork,cnn)等。在一些实施例中,所述策略模型可以进一步包含一个评价模型。所述评价模型可以强化或改进所述策略模型。所述评价模型也可以是一个神经网络模型,如递归神经网络(recurrentneuralnetwork,rnn)、卷积神经网络(convolutionalneuralnetwork,cnn)等。
在步骤220中,通过用户交互模块130,多轮对话系统100可以接收用户的输入信息。
在步骤230中,通过状态确定模块140,多轮对话系统100可以基于用户的输入信息确定所述输入信息的状态。所述确定所述输入信息的状态,可以包括:将所述输入信息分为一个或多个词;按所述输入信息中所述一个或多个词所在位置的顺序依次对所述一个或多个词进行信息提取,生成对应于所述一个或多个词的一个或多个状态;以及将最后一个词的状态作为所述输入信息的状态。
在步骤240中,通过动作概念生成模块150,多轮对话系统100可以调用策略模型训练模块110训练的策略模型,基于状态确定模块140输出的输入信息的状态,生成一个或多个动作概念。所述一个或多个动作概念分别包括生成一句话或调用一个应用程序接口。所述一个或多个动作概念由名称及一个或多个槽值对组成。
在步骤250中,通过执行模块160,多轮对话系统100可以执行所述一个或多个动作概念。多轮对话系统100还可以通过执行模块160给用户发送提示信息,以提示用户输入新的信息,进入下一轮对话。
以上所述仅为本发明的优选实施而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!