一种分布式存储中文件批量读取方法与流程
本发明涉及文件读取技术领域,特别是涉及一种分布式存储中文件批量读取方法。
背景技术:
目前,随着信息技术和互联网技术的飞速发展,企业所需传输、存储的数据也随之剧增。在海量小文件的场景,如,如社交购物网站、广电、网络视频等,系统产生文本、图片、音乐等大量小文件,这些文件具有如下特点:文件数量多,大小一般在1mb以下;文件的读取一般都是顺序读取。
分布式数据存储系统中,文件读取时,客户端首先要向mds端发送请求,获取文件的权限和元数据信息,然后客户端通过获取到的元数据信息,找到对应的存储文件数据osd,从osd中读取文件的数据信息。整个文件读取过程需要经过较长的io流程。当批量读取大量文件时,每个文件都独立经过所有io流程,这样会频繁地向mds请求文件的元数据信息,然后又频繁调用objectcacher中的读接口,从osd中读取数据。文件读取过程中重复请求发送、处理频繁,对系统压力大。
分布式文件系统中,文件读取时每次都需客户端向mds端请求待读取文件的元数据信息,获取元数据信息之后再从osd中获取文件的数据信息。文件读取时需要较长的io流程,读取速度较低。
技术实现要素:
本发明的目的是提供一种分布式存储中文件批量读取方法,以实现减少文件读取的io流程,提高读取速度。
为解决上述技术问题,本发明提供一种分布式存储中文件批量读取方法,应用于客户端,包括:
在文件进行open操作时,向元数据服务器mds发送请求,获取当前文件以及当前文件之后的若干待读文件的元数据信息;
将元数据信息中的索引号ino和目录项dentry存入dentry_map结构中;
依据元数据信息查找到存储文件数据的对应的对象存储设备osd,从osd中读取待读文件的数据;
完成待读文件的数据读取后,根据dentry_map结构中的存储顺序进行文件预读。
优选的,所述将元数据信息中的索引号ino和目录项dentry存入dentry_map结构中,包括:
按照索引号ino递增的方式,将元数据信息中的索引号ino及相应的目录项dentry存放到客户端的dentry_map结构中。
优选的,所述根据dentry_map结构中的存储顺序进行文件预读,包括:
根据dentry目录结构获取相应的inode结构,根据inode结构从相应的osd中读取指定个数的文件。
优选的,所述请求为在当前文件元数据请求中同时获取相邻文件元数据。
优选的,所述元数据信息的数量通过配置项动态配置。
优选的,所述完成待读文件的数据读取后,根据dentry_map结构中的存储顺序进行文件预读之后,还包括:
顺序读取下一个文件,命中客户端缓存,从客户端缓存中获取文件数据。
优选的,所述顺序读取下一个文件,命中客户端缓存,从客户端缓存中获取文件数据之后,还包括:
若待读取的文件没有命中客户端缓存,从osd中预读指定个数的文件到客户端缓存中。
本发明所提供的一种分布式存储中文件批量读取方法,应用于客户端,在文件进行open操作时,向元数据服务器mds发送请求,获取当前文件以及当前文件之后的若干待读文件的元数据信息;将元数据信息中的索引号ino和目录项dentry存入dentry_map结构中;依据元数据信息查找到存储文件数据的对应的对象存储设备osd,从osd中读取待读文件的数据;完成待读文件的数据读取后,根据dentry_map结构中的存储顺序进行文件预读。可见,文件批量读取时,每次从mds端获取文件元数据信息时,一次获取多个文件元数据信息,减少客户端与mds之间的交互次数,减轻mds端的请求处理压力,同时缩短文件读取过程中的io流程。并且,在读取当前待读取文件后,按照dentry_map中存储的顺序,进行文件预读,如此顺序读取场景下,能大概率地命中预读缓存,减少文件读取的io流程,加快读取速度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
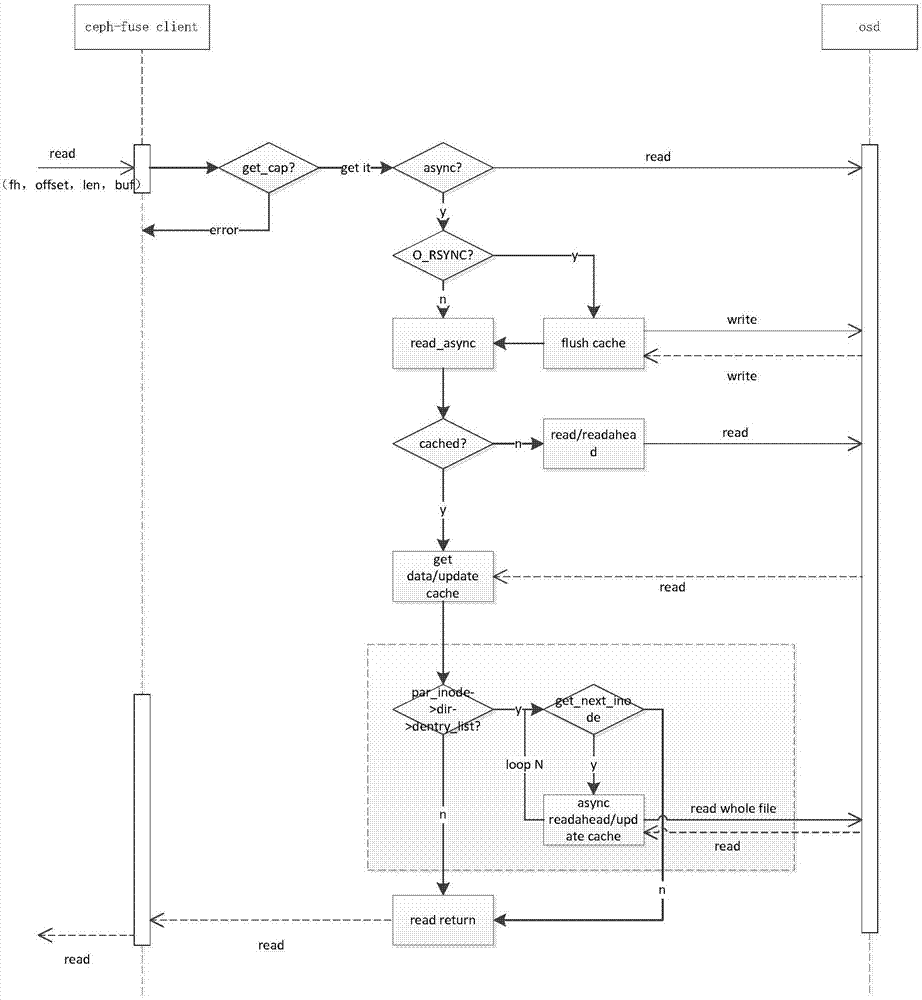
图1为本发明所提供的一种分布式存储中文件批量读取方法的流程图;
图2为文件批量读取流程示意图;
图3为文件读取原理图;
图4为文件批量读取原理图。
具体实施方式
本发明的核心是提供一种分布式存储中文件批量读取方法,以实现减少文件读取的io流程,提高读取速度。
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
术语解释如下:
mds:元数据服务器,用于管理文件元数据信息;
osd:对象存储设备,用于存储数据信息。
请参考图1,图1为本发明所提供的一种分布式存储中文件批量读取方法的流程图,该方法应用于客户端,包括:
步骤s11:在文件进行open操作时,向元数据服务器mds发送请求,获取当前文件以及当前文件之后的若干待读文件的元数据信息;
步骤s12:将元数据信息中的索引号ino和目录项dentry存入dentry_map结构中;
步骤s13:依据元数据信息查找到存储文件数据的对应的对象存储设备osd,从osd中读取待读文件的数据;
步骤s14:完成待读文件的数据读取后,根据dentry_map结构中的存储顺序进行文件预读。
可见,文件批量读取时,每次从mds端获取文件元数据信息时,一次获取多个文件元数据信息,减少客户端与mds之间的交互次数,减轻mds端的请求处理压力,同时缩短文件读取过程中的io流程。并且,在读取当前待读取文件后,按照dentry_map中存储的顺序,进行文件预读,如此顺序读取场景下,能大概率地命中预读缓存,减少文件读取的io流程,加快读取速度。
基于上述方法,进一步的,步骤s12的过程具体包括:按照索引号ino递增的方式,将元数据信息中的索引号ino及相应的目录项dentry存放到客户端的dentry_map结构中。
进一步的,步骤s14中,根据dentry_map结构中的存储顺序进行文件预读的过程具体包括:根据dentry目录结构获取相应的inode结构,根据inode结构从相应的osd中读取指定个数的文件。
其中,步骤s11中,所述请求为在当前文件元数据请求中同时获取相邻文件元数据。
其中,步骤s11中,元数据信息的数量通过配置项动态配置。
其中,步骤s11中,获取到当前文件的元数据信息和当前文件之后的若干待读文件的元数据信息。
进一步的,步骤s14之后,还包括:顺序读取下一个文件,命中客户端缓存,从客户端缓存中获取文件数据。
其中,顺序读取下一个文件,命中客户端缓存,从客户端缓存中获取文件数据之后,还包括:若待读取的文件没有命中客户端缓存,从osd中预读指定个数的文件到客户端缓存中。
小文件场景中,在文件open操作时,从mds端获取当前文件及指定数目的相邻文件的元数据信息。文件读取时,完成当前文件的数据读取之后,根据获取的元数据信息,从osd端读取指定数目的相邻文件。在顺序读取时,能命中客户端缓存,减少文件读取的整体io流程,提高读取速度。本方法每次读取文件时顺序读取其相邻文件到客户端缓存中,当读取文件命中缓存时能缩短文件读取的io流程,提高文件的读取速度。
其中,海量小文件场景中文件的创建一般是批量顺序创建,因此,相邻文件的ino在很大概率上也是相邻的。当顺序批量读取文件时,可认为待读取文件的ino是顺序递增的。
基于本方法,详细的,在文件open操作时,向mds发送请求,获取当前open文件之后的若干文件的元数据信息。通过一次获取元数据请求,得到批量元数据信息。每次元数据请求获取元数据数量可通过配置项动态配置。
然后,在获取当前目录下待读取文件的元数据信息后,按照ino递增的方式,将文件ino及其相应的dentry存放到一个map结构:dentry_map中。在客户端目录结构中存储当前目录下的文件信息。
接着,文件读取时,如果待读取文件未命中客户端缓存,需要调用objectcacher中的读接口从osd中读取文件的数据信息时,在读取当前待读取文件后,按照dentry_map中存储的顺序,进行文件预读,从osd中读取指定数目的文件。顺序读取场景下,能大概率地命中预读缓存,减少文件读取的io流程,加快读取速度。参考图2,图2为文件批量读取流程示意图。
本方法在文件读取中,减少客户端与mds端交互次数,减轻大量读取文件时mds端元数据请求处理压力,并且缩短文件读取的io流程,提高客户端缓存命中率,提升文件读取速度。
如图3所示,文件读取过程中,每个文件都需先向mds请求元数据信息,mds成功处理,回复请求后,客户端根据获取的元数据信息,找到存储数据的相应osd,从osd中读取数据信息。整个过程中客户端需同mds和osd交互。当文件数量较多时,客户端同mds和osd的交互次数剧增。造成系统请求处理压力大。
如图4所示,文件批量读取时,每次从mds端获取文件元数据信息时,一次获取多个文件元数据信息,减少client与mds之间的交互次数,减轻mds端的请求处理压力,同时缩短文件读取过程中的io流程。从osd中读取文件时,每次成功读完当前指定的待读取文件时,根据从mds端获取的元数据信息,依次预读后续指定数目文件。顺序读取场景中,指定预读数目为n时,从osd中批量读取文件一次,可在后续文件读取中命中n次客户端缓存。
在海量小文件场景中,文件具有数量多,大小较小,一般进行顺序操作的特点。这对这些特点提出小文件读取过程中进行批量读取,减少客户端与mds之间的请求交互,缩短文件读取过程的io流程,提高文件读取速度。基于本方法,具体实施步骤如下:
1、客户端读取文件时,需要先获取文件元数据信息,客户端向mds发送元数据请求;mds从osd中读取文件的元数据信息,向客户端返回;客户端获取元数据信息后open文件;
2、在open操作中,客户端向mds发送当前文件的元数据信息请求,从mds端获取批量元数据信息,包含当前文件及当前文件之后的若干待读文件的元数据信息;
3、将从mds端获取的元数据信息中的ino和相应dentry存入客户端dentry_map结构中;
4、根据文件的元数据信息,找到存储文件数据对应的osd,从osd中读取待读文件的数据;
5、完成待读文件的数据读取之后,根据dentry_map中的存储顺序进行文件预读;
其中,根据dentry结构获取相应的inode,根据inode结构从相应的osd中读取指定个数的文件;
6、顺序读取下一个文件时,由于已经进行文件预读,因此命中客户端缓存,从缓存中获取文件数据;
其中,直到待读取的文件未命中客户端缓存时再从osd中预读指定个数的文件到客户端缓存中。
本方法主要在海量小文建场景中,大量顺序读取文件时,在一次读请求中批量从mds获取相邻文件元数据信息,并从osd中读取文件相邻的文件,通过文件预读的方式加快文件读取速度。
以上对本发明所提供的一种分布式存储中文件批量读取方法进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!