一种基于主题实例的电力海量数据存储和查询统计分析方法及其系统与流程
本发明涉及电力海量数据存储查询领域,具体为一种基于主题实例的电力海量数据存储和查询统计分析方法及其系统。
背景技术:
目前大部分电网企业用企业级关系数据库进行数据的集中存储。关系型数据库以及所采用的按行存储模式,能够进行多条件的查询,但支持的数据量规模小,不能满足电网状态监测数据的海量存储需求;当存储的数据量较大时,查询性能下降明显,不能很好的适应状态监测大数据的准实时处理应用需求。
hadoop提供了一个分布式的数据库系统hbase,hbase的目标是存储并处理海量数据,是建立在hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统,能够对海量数据提供随机、实时的读写访问。但是hbase介于nosql和rdbms之间,仅能通过主键(rowkey)和主键的range来检索数据,仅支持单行事务。用户在使用电网设备状态监测系统时,通常需要利用多个条件对监测数据进行综合查询。因此如何采用统一的模型对电网海量数据进行高效、可靠地存储,并快速访问和分析,需要对hbase逻辑存储模式和查询方法进行有效的设计。
技术实现要素:
本发明针对电力海量监测数据的存储查询统计分析需求,基于oracle和hbase提出了一种新的基于主题实例的统一模型的电力海量数据的存储和查询方法及其系统,以支持电力海量监测数据的可靠存储,快速实时查询及其聚合统计分析。
本发明是通过如下技术方案来实现的。
一种基于主题实例的电力海量数据存储和查询统计分析系统,该系统采用监测终端传感器通过消息队列集群分别与websocket数据推送平台、jstorm实时数据处理平台连接,websocket数据推送平台与前端数据展示系统连接;jstorm实时数据处理平台与数据仓库连接,数据仓库分别通过统计分析引擎、实时数据查询引擎与前端数据展示系统连接。
一种根据上述基于主题实例的电力海量数据存储和查询统计的分析方法,本发明特征在于,步骤为:
步骤200监测终端传感器发送数据到消息队列服务器集群;
步骤s201消息队列服务器接收到数据;
步骤202消息队列服务器接收到数据以后,一方面通过websocket数据推送将数据实时推送至系统前端实现数据实时可视化监控;
步骤203另一方面将数据推送到jstorm实时数据分析处理平台进行数据清洗;
步骤204加工之后存入数据仓库;
步骤205组合查询条件实时查询引擎;
步骤206聚合统计分析引擎;
步骤207系统前端展示平台通过组合查询条件实时查询引擎,能够快速访问数据仓库中的数据,或者通过聚合统计分析引擎对数据仓库中的数据进行统计分析。
本发明统计分析方法中,基于主题实例的电力海量数据存储是采用将电力海量数据分成静态数据和电网运行数据,将电网设备台账、设备技术参数、监测终端信息以及终端监测属性等静态数据以结构化的方式建立主题实例模型;将电网运行数据基于列式存储方案存储在hbase列式数据库中。
本发明统计分析方法中,监测终端传感器监测将一组监测数据发送回来的时候就根据监测终端监测属性以及设备台账实例化一个实例,通过md5加密设备id取前两位+主题实例id+(long.max_value-timestamp)作为hbase存储数据的行健rowkey,建立一个列族f1,以电网运行时的监测属性作为列,将电网运行时的监测数据存储在hbase列式数据表中。
本发明统计分析方法中,所述hbase表包括行健、时间戳和列族,列族包括监测主题对应的所有监测属性。
本发明统计分析方法中,统计分析引擎在接收到系统前端或者客户端发送过来的请求是提取查询参数,根据所述主题实例id,监测属性id以及hbase行健生成规则生成行健查询范围,以及列族,版本号和列信息;根据所述过滤查询字段以及协处理器聚合方式创建对应的过滤器;调用hbase的数据访问接口,从与所述表名对应的表内查找所述行健查询范围或者行健以及监测属性id,利用所述聚合函数对对应的行健查询范围内的数据进行聚合统计;将所述过滤器过滤后的聚合统计结果返回给客户端。
本发明的有益效果是,提供统一的模型对电网设备状态监测进行高效、可靠地存储,并快速访问和分析,降低开发成本,提高开发效率。
附图说明
图1为本分系统的整体架构概要图;
图2为本发明系统提供的基于主题实例的电网海量数据存储流程图;
图3为本发明系统提供的基于主题实例的电网海量数据实时查询和聚合统计分析引擎流程图。
具体实施方式
见图1,一种基于主题实例的电力海量数据存储和查询统计分析系统,该系统采用监测终端传感器s200通过消息队列集群s201分别与websocket数据推送平台s203、jstorm实时数据处理平台s202连接,websocket数据推送平台s203与前端数据展示系统s207连接;jstorm实时数据处理平台s202与数据仓库s204连接,数据仓库s204分别通过统计分析引擎s205、实时数据查询引擎s206与前端数据展示系统s207连接。
一种根据上述基于主题实例的电力海量数据存储和查询统计的分析方法,本发明特征在于,步骤为:
步骤200监测终端传感器发送数据到消息队列服务器集群;
步骤s201消息队列服务器接收到数据;
步骤202消息队列服务器接收到数据以后,一方面通过websocket数据推送将数据实时推送至系统前端实现数据实时可视化监控;
步骤203另一方面将数据推送到jstorm实时数据分析处理平台进行数据清洗;
步骤204加工之后存入数据仓库;
步骤205组合查询条件实时查询引擎;
步骤206聚合统计分析引擎;
步骤207系统前端展示平台通过组合查询条件实时查询引擎,能够快速访问数据仓库中的数据,或者通过聚合统计分析引擎对数据仓库中的数据进行统计分析。
本发明统计分析方法中,基于主题实例的电力海量数据存储是采用将电力海量数据分成静态数据和电网运行数据,将电网设备台账、设备技术参数、监测终端信息以及终端监测属性等静态数据以结构化的方式建立主题实例模型;将电网运行数据基于列式存储方案存储在hbase列式数据库中。
本发明统计分析方法中,监测终端传感器监测将一组监测数据发送回来的时候就根据监测终端监测属性以及设备台账实例化一个实例,通过md5加密设备id取前两位+主题实例id+(long.max_value-timestamp)作为hbase存储数据的行健rowkey,建立一个列族f1,以电网运行时的监测属性作为列,将电网运行时的监测数据存储在hbase列式数据表中。
本发明统计分析方法中,所述hbase表包括行健、时间戳和列族,列族包括监测主题对应的所有监测属性。
本发明统计分析方法中,统计分析引擎在接收到系统前端或者客户端发送过来的请求是提取查询参数,根据所述主题实例id,监测属性id以及hbase行健生成规则生成行健查询范围,以及列族,版本号和列信息;根据所述过滤查询字段以及协处理器聚合方式创建对应的过滤器;调用hbase的数据访问接口,从与所述表名对应的表内查找所述行健查询范围或者行健以及监测属性id,利用所述聚合函数对对应的行健查询范围内的数据进行聚合统计;将所述过滤器过滤后的聚合统计结果返回给客户端。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1、图2和图3,本发明提出的基于主题实例模型的电力海量数据存储统计分析系统主要包括以下步骤:
步骤s200:监测终端传感器(步骤200)发送数据到消息队列服务器集群(步骤s201),消息队列服务器接收到数据以后,一方面通过websocket数据推送(步骤202)将数据实时推送至系统前端实现数据实时可视化监控,一方面将数据推送到jstorm实时数据分析处理平台(步骤203)进行数据清洗,加工之后存入数据仓库(步骤204),系统前端展示平台(步骤207)通过组合查询条件实时查询引擎(步骤205)可以快速访问数据仓库中的数据,也可以通过聚合统计分析引擎(步骤206)对数据仓库中的数据进行统计分析。
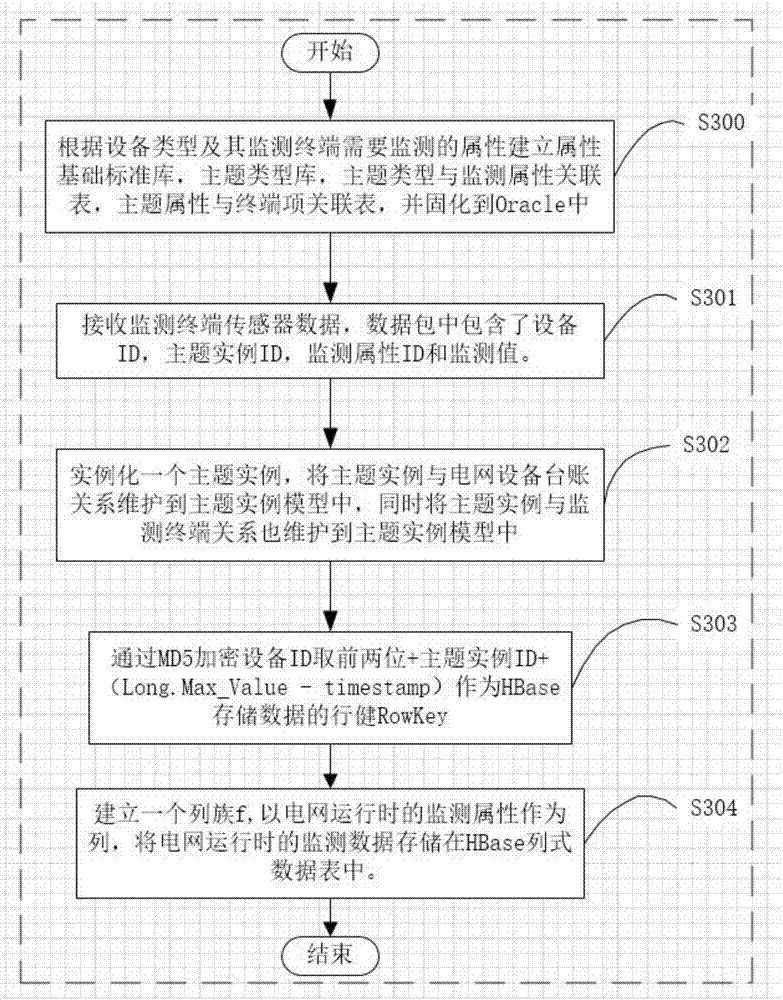
参见图1和图2,本发明提出的基于主题实例模型的电力海量数据存储方法包括以下步骤:
步骤s300:先根据设备类型及其监测终端需要监测的属性建立属性基础标准库,主题类型库,主题类型与监测属性关联表,主题属性与终端项关联表,并固化到oracle中。
步骤s301:接收监测终端传感器数据,数据包中包含了设备id,监测终端id,主题类型id,监测属性id和监测值,
步骤s302:实例化一个主题实例,将主题实例与电网设备台账关系维护到主题实例模型中,同时将主题实例与监测终端关系也维护到主题实例模型中。
步骤s303:通过md5加密设备id取前两位+主题实例id+(long.max_value-timestamp)作为hbase存储数据的行健rowkey,
步骤s304:建立一个列族f,以电网运行时的监测属性作为列,将电网运行时的监测数据存储在hbase列式数据表中。
电网监测数据在hbase数据库中以表的形式存储数据,行健,列族,列,时间戳。行健(rowkey)是用来检索一行记录的主键,是行的唯一标识,在hbase内部,rowkey保存为字节数组,存储时,数据按照rowkey的字典顺序排序存储。时间戳,默认由系统指定,用户也可以显示设置。不同的时间戳用来区分不同的版本,时间戳一般按照版本从新到旧的顺序进行排列,在数据读取的时候优先读取最新版本。
本发明提出的基于主题实例的数据查询引擎包括如下步骤:
步骤s400:提取查询参数,根据所述主题实例id,监测属性id以及hbase行健生成规则生成行健查询范围,以及列族,版本号和列信息。
步骤s401:调用hbase的数据访问接口,从与所述表名对应的表内查找所述行健查询范围或者行健以及监测属性id,从所述行健查询范围中获取预设返回的条数的行健及其列族,列名对应的数据。
步骤s402:将所述预设返回条数的行健对应的数据映射为预设的格式,并将映射后的数据发送至客户端。
本发明提出的基于主题实例的数据统计分析引擎包括如下步骤:
步骤s403:提取查询参数,根据所述主题实例id,监测属性id以及hbase行健生成规则生成行健查询范围,以及列族,版本号和列信息。
步骤s404:根据所述过滤查询字段以及协处理器聚合方式创建对应的过滤器
步骤s405:调用hbase的数据访问接口,从与所述表名对应的表内查找所述行健查询范围或者行健以及监测属性id,利用所述聚合函数对对应的行健查询范围内的数据进行聚合统计。
步骤s406:将所述过滤器过滤后的聚合统计结果返回给客户端。
- 还没有人留言评论。精彩留言会获得点赞!