一种基于多数据源的本体学习方法与流程
本发明涉及人工智能中语义网领域,特别是一种基于多数据源的本体学习方法。
背景技术:
在语义网中,本体(ontologies)作为形式化的知识表示扮演着重要的角色。本体为不同领域提供共享的词汇,给计算机处理web信息提供了方便。按照gruber的定义,本体是感兴趣领域的共享的概念化的显式规约。作为规约,本体需要通过某种语言表达,例如使用rdfs或者owl。随着owl成为w3c推荐的本体语言标准,越来越多的本体用owl语言来表达。owldl是比较常用的子语言,它在语义上等价于某种描述逻辑(descriptionlogics,dl)语言,并对应着一阶谓词逻辑中可判定的子语言,为语义网提供了坚实的逻辑基础。由于owldl是可判定的(decidable),即拥有在有限时间内可终止的推理机制,而owlfull没有可判定性,一个owldl本体通常是有abox和tbox组成,abox是由一组描述实例之间关系的公理组成,tbox是由一组描述概念和属性间的公理组成,比如包含关系和不交关系。从实体的角度来说,一个owldl本体是由概念、属性和实例组成,其中概念是现实世界中概念的抽象,属性是描述概念之间的关系,而实例则是现实世界中的个体。
本体学习是信息提取的子任务之一,其目标是自动或半自动地从给定的语料库或数据源中提取概念、关系或公理,用来构建本体。本体学习的数据源可以是像数据库之类的结构化数据,像xml之类的半结构化数据,或者像文本之类的非结构化数据。针对不同类型的数据源,人们提出了各种各样的本体学习方法。
随着语义网的不断发展,特别是链接开放数据(linkingopendata,lod)项目的提出,大量的语义数据可供使用。例如,dbpedia的最新版本dbpedia2015-04(英文版)包含了7.37亿个rdf三元组。在此基础上,为了提高搜索质量,谷歌、百度和搜狗等著名搜索引擎公司纷纷构建了各自的知识图谱(knowledgegraph)。另外,还有一些知识库构建工具在源源不断地从web页面中抽取大量的事实,使得语义数据的规模越来越庞大,其中事实就是本体中的断言(assertions)或实例层的信息。例如,nell从2010年1月开始,每天24小时不间断地迭代学习信念(即事实),截止到2015年已经收集了8千多万个信念。
大量的语义数据极大地推动了语义网的实现,使得语义网技术能够得到更为实际的应用。这些语义数据虽然包含了众多的rdf三元组,但往往缺少丰富的模式层信息。拿lod的核心数据集dbpedia为例,虽然它包含了非常多断言,而其本体主要定义了概念(或属性)之间的层次关系以及属性的值域和定义域,缺少了存在量词约束、全称量词约束和数量约束等公理。这些公理的缺失,给语义数据的整合、查询和维护等关键语义网任务带来了不便。
研究者们提出各种方法从语义数据中学习模式层信息,大致可分为基于归纳逻辑编程(inductivelogicprogramming,ilp)的方法、基于关联规则挖掘(associationrulemining,arm)的方法和启发式方法。ilp结合了机器学习和逻辑编程技术,使得人们可以从实例和背景知识中获得逻辑结论。jenslehmann等提出用向下精化算子学习alc的概念定义公理的方法。johannavölker等人介绍了从rdf数据中生成本体的统计方法,该方法通过sparql查询来获取信息,用以构建事务表。在他们的后续工作中,使用负关联规则挖掘技术学习不交公理。为了提高本体学习的伸缩性(scalability),lorenzbühmann等人针对可以通过sparql查询终端进行查询的知识库提出一种轻量级的模式构建方法,该方法需要对每种公理类型(例如不交公理和描述属性的值域的公理)构建相应的sparql查询语句,然后使用统计的方法为每个学到的公理赋予一个分值(score),用来筛选公理。
目前的本体学习方法往往只局限于从单数据源进行本体学习,而忽略了从日益丰富的现有本体库和知识图谱资源中获取相关信息,对单数据源进行扩充。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足而提供一种基于多数据源的本体学习方法,通过在学习前挖掘多数据源中实体之间的关系,将多个松散的数据源结合起来,变成一个有机的整体,为学习更多有意义的结果提供便利。
本发明为解决上述技术问题采用以下技术方案:
根据本发明提出的一种基于多数据源的本体学习方法,包括以下步骤:
步骤1、从已有本体库和知识图谱中,通过人工选择或本体间相似度计算工具,选择与输入数据源s领域相关的数据源t;
步骤2、使用本体匹配技术计算数据源s与步骤1选择出的数据源t之间的关系,并根据这些关系对数据源s的信息进行扩展;具体如下:
步骤2-1、根据本体匹配技术中的模式匹配技术,获得数据源s与数据源t中概念和属性之间的对应关系;
步骤2-2、如果数据源s中的概念c1对应到数据源t中的概念c2,则在数据源s中声明概念c1等价于概念c2;如果数据源t中概念c2包含某个实例,则在数据源s中声明该实例是概念c1的实例;
步骤2-3、如果数据源s中的属性p1对应到数据源t中的属性p2,则在数据源s中声明属性p1等价于属性p2;如果数据源t中属性p2包含某个实例,则在数据源s中声明该实例是属性p1的实例;
步骤2-4、根据本体匹配技术中的实例匹配技术,获得数据源s与数据源t中实例之间的对应关系;如果数据源s中的实例i1对应到数据源t中实例i2上,则在数据源s中声明实例i1等于实例i2;
步骤3、对扩充后的数据源s的不一致性进行处理,使得数据源s的不一致度低于预设的阈值;
步骤4、挑选一个公理学习工具,将经步骤3处理过的数据源s作为其输入,展开公理学习;
步骤5、对公理学习的结果进行过滤,具体如下:
步骤5-1、根据预设的阈值,删除学习结果中权重小于阈值的公理;
步骤5-2、删除掉包含owl、rdf和rdfs本体语言中专用词汇的公理;
步骤6、根据步骤5中过滤后的结果构建本体,并通过本体调试和修补策略达到本体的一致。
作为本发明所述的一种基于多数据源的本体学习方法进一步优化方案,步骤5中根据预设的阈值,过滤权重小于阈值的学习结果。
作为本发明所述的一种基于多数据源的本体学习方法进一步优化方案,步骤5中根据实体名称的前缀,过滤专用词汇。
作为本发明所述的一种基于多数据源的本体学习方法进一步优化方案,实体名称的前缀为以rdf、rdfs和owl开头。
作为本发明所述的一种基于多数据源的本体学习方法进一步优化方案,步骤3中采用本体调试和修补策略对扩充后的数据源进行不一致性处理。
作为本发明所述的一种基于多数据源的本体学习方法进一步优化方案,步骤6中采用本体调试和修补策略对本体进行不一致性处理。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
(1)本发明更有效地利用数据源中的信息来提高学习的效果,改变传统的针对单个数据源进行逐个学习而忽略数据源之间潜在的关系;
(2)本发明是对已有本体学习方法的一个有意义的扩展,通过挖掘多数据源中概念、属性和实例之间的关系,为本体学习提供更多有用的信息,从而达到提高本体学习召回率的效果。
附图说明
图1是基于多数据源的本体学习过程;
图2是从ntn子本体中获取术语的示例;
图3是从ntn子本体中学习到的不交公理的示例。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明主要考虑从目前比较热门的语义数据进行本体学习,该数据属于半结构化数据,本发明提出的本体学习方法可以很容易地扩展到其他数据源之上的本体学习。
如图1所示,基于多数据源的本体学习过程主要分为数据源的处理、公理的学习和本体的构建三大步。下面具体介绍:
1.数据源的处理
随着语义网的发展,越来越多的本体和知识图谱可以从网上免费下载,涵盖了众多的领域,例如生物、医学、地理和常识知识等。例如,lod的核心数据集dbpedia,该数据集是从维基百科中自动抽取出来的,涵盖了各行各业的数据,并构建了包含概念的层次关系、属性的值域和定义域定义等信息的本体,为其实例层数据的使用提供了约束。从这些现有数据集中,首先需要人工的挑选出同用于学习的单个数据源相关的数据集,然后采用自动的方法寻找多数据源之间的相关性。
在计算多数据源之间相关性时,本方法使用本体匹配技术。该技术旨在通过计算本体中相关实体间的对应关系来解决语义异构问题,大体上可以分为模式层匹配技术和实例层匹配技术,一般是通过字符串匹配、字典、上下文结构等信息计算概念、属性和实例之间的相似度。通过本体匹配技术计算好实体间的对应关系后,本方法利用本体调试和修补技术对得到的本体映射进行不一致性处理。最终得到的合并后的数据源,便是可以用于本体学习的数据集。
为了便于解释,本发明将一个用于学习的数据源根据其abox拆分成若干个子本体,由此将原本有可能关联的信息给删除掉了。在这种情况下,无需使用本体匹配技术来计算多数据源实体间的关系。在本发明中,选择一个比较著名的ntn本体作为用于学习的数据源,该本体包含了195个tbox公理和3107个abox公理,其实体包含了49个概念、38个属性和724个实例。在共享tbox的情况下,将abox的公理平分成四份,每个子本体包含了原来的tbox和一份分好后的abox公理集。由此,得到了四个新的本体,它们之间互相关联,合并后即得到了最原始的ntn本体。
2.公理的学习
给定一个数据源之后,便可进入公理的学习步骤。在该步骤中,可以使用任意适合该类数据源的本体学习工具,本发明使用基于关联规则挖掘方法的本体学习工具goldminer。该工具是由德国曼海姆大学的知识表示和知识管理研究组研究与开发的,可以处理大规模数据,用于学习各种类型的tbox公理,例如不交公理、概念和属性的层次关系以及属性的值域与定义域。
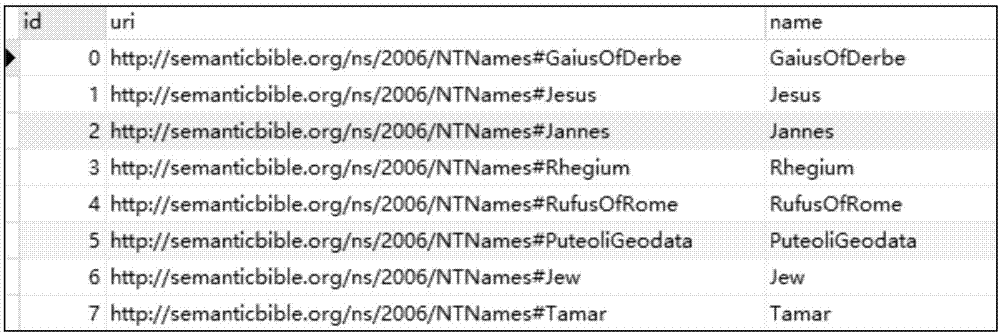
goldminer首先从数据源中获取术语,这些术语指跟最终要学习的公理类型相关的术语,例如数据源中的概念、属性、实例和实例对等,并为这些术语赋予唯一的标识,保存到数据库中,以备后用。图2给出了goldminer从ntn的一个子本体中获取到的实例的部分例子,并为每个实例赋予一个用整数表示的标识。例如,实例jesus的标识为1。
获取到术语后,goldminer建立事务表,然后调用传统的关联规则挖掘算法apriori从每个构建好的事务表中挖掘规则。其中,事务表中每个实体都使用其对应的唯一标识来表示,每个挖掘出的规则都附带了对应的置信度(confidence)和支持度(support)。学习到的规则经过一些策略进行过滤,候选的规则直接转换成公理。图3给出了学习到的部分不交公理。
将ntn的四个子本体分别作为单一数据源时,通过goldminer分别学习得到378、253、171和300个不交公理,将这四个公理集合合并后,得到572个不同的不交公理。而将原本的ntn作为单一数据源进行学习时,得到了666个不交公理。在这多出的94个公理中,70个以上都是正确的。由此可见,本体的拆分而导致信息的丢失使得许多正确的公理不再能学习到,从而影响了学习的效果。同时,也说明了在本体学习前考虑多数据源之间的关系,为单一数据源增添有用的信息,可以提升本体学习的效果。
3.本体的构建
通过公理的学习得到了一个公理集,由此公理集构建本体时,往往会出现本体的不一致性问题。通常情况下,人们会根据公理的权重按照从高到低进行排序,然后逐个将公理添加一个初始为空集的本体里,每次添加如果导致本体出现不一致,则删除该公理。该方法简单直观,效率较高。但是,这类方法往往删除较多的公理,不能保证某种条件下的最小删除原则。为了达到最小删除,可以将学习到的公理集作为一个本体,然后通过本体调试获得最小的不一致公理集,再通过碰集树计算碰集,从碰集里面挑选出权重最小的公理进行删除。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替代,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!