分布式数据库实现方法及装置与流程
本发明涉及计算机技术领域,尤其涉及一种分布式数据库实现方法及装置。
背景技术:
随着互联网技术的发展和应用软件的成熟,在21世纪开始兴起的一种完全创新的软件应用模式软件即服务(software-as-a-service,简称saas)。它是一种通过internet提供软件的模式,厂商将应用软件统一部署在自己的服务器上,客户可以根据自己实际需求,通过互联网向厂商定购所需的应用软件服务,按定购的服务多少和时间长短向厂商支付费用,并通过互联网获得厂商提供的服务。对于许多小型企业来说,saas是采用先进技术的最好途径,它消除了企业购买、构建和维护基础设施和应用程序的需要。
目前,saas系统将应用业务流程进行了云端化,大量的业务访问及处理集中于saas云平台,基于传统的单应用单数据库,很难支撑海量数据,高并发的业务场景。
因此,亟需一种基于元数据驱动saas的分布式系统架构,以将传统的系统架构拆分成分布式存储及处理。
技术实现要素:
本发明提供一种分布式数据库实现方法及装置,用以解决现有技术中数据访问集中,单应用数据库难以支撑海量数据的技术问题。
本发明一方面提供一种分布式数据库实现方法,包括:
在元数据表中生成第一新增数据,第一新增数据包括已有租户标识和对应的第一存储数据子库的访问地址;分布式数据库包括检索数据库和存储数据库,其中,检索数据库用于存储元数据表;存储数据库用于存储数据,且包括第一存储数据子库;
根据第一存储数据子库的存储容量和已有租户的数量,确定第一剩余租户的数量,其中,第一剩余租户为第一存储数据子库中还能够存储的当前租户的数量;
若第一剩余租户的数量满足预设阈值,则在元数据库表中生成第二新增数据,第二新增数据包括当前租户标识和对应的第一存储数据子库的访问地址;
将当前租户的数据存储到第一存储数据子库中。
进一步的,上述方法还包括:
在元数据表中检索所有有效的第二存储数据子库;存储数据库还包括第二存储数据子库;
分别计算检索出的第二存储数据子库的第二剩余租户的数量;其中,第二剩余租户为检索出的第二存储数据子库中还能够存储的当前租户的数量;
选取第二剩余租户的数量最多的第二存储数据子库作为当前租户的数据存储位置,并在元数据库表中生成第三新增数据,其中,第三新增数据包括当前租户标识和被选中的第二存储数据子库的访问地址;
将当前租户的数据存储到被选中的第二存储数据子库中。
进一步的,上述方法还包括:
根据当前租户标识在元数据表中查找,以获取存储当前租户数据的第三存储数据子库的访问地址;存储数据库还包括第三存储数据子库;
根据获取到的第三存储数据子库的访问地址,对第三存储数据子库进行数据操作,其中,数据操作包括读数据和写数据。
进一步的,根据获取到的第三存储数据子库的访问地址,对第三存储数据子库进行数据操作,具体包括:
根据获取到的第三存储数据子库的访问地址,读取待迁移数据;待迁移数据为第三存储数据子库中存储的数据;
将待迁移数据存储至目标存储数据库中,并将待迁移数据从访问的第三存储数据子库中删除;
将元数据表中与当前租户标识对应的第三存储数据子库的访问地址修改为目标存储数据库的地址。
进一步的,根据获取到的第三存储数据子库的访问地址,对第三存储数据子库进行数据操作,具体包括:
获取当前租户的操作类型,操作类型包括读操作和写操作;第三存储数据子库包括读数据库和写数据库;
根据操作类型对读数据库或者写数据库进行相应操作。
本发明另一方面提供一种分布式数据库实现装置,包括:
第一新增数据添加模块,用于在元数据表中生成第一新增数据,第一新增数据包括已有租户标识和对应的第一存储数据子库的访问地址;分布式数据库包括检索数据库和存储数据库,其中,检索数据库用于存储元数据表;存储数据库用于存储数据,且包括第一存储数据子库;
第一剩余租户计算模块,用于根据第一存储数据子库的存储容量和已有租户的数量,确定第一剩余租户的数量,其中,第一剩余租户为第一存储数据子库中还能够存储的当前租户的数量;
第二新增数据添加模块,用于若第一剩余租户的数量满足预设阈值,则在元数据库表中生成第二新增数据,第二新增数据包括当前租户标识和对应的第一存储数据子库的访问地址;
第一存储模块,用于将当前租户的数据存储到第一存储数据子库中。
进一步的,上述装置还包括:
检索模块,用于在元数据表中检索所有有效的第二存储数据子库;存储数据库还包括第二存储数据子库;
第二剩余租户计算模块,用于分别计算检索出的第二存储数据子库的第二剩余租户的数量;其中,第二剩余租户为检索出的第二存储数据子库中还能够存储的当前租户的数量;
选择模块,用于选取第二剩余租户的数量最多的第二存储数据子库作为当前租户的数据存储位置,并在元数据库表中生成第三新增数据,其中,第三新增数据包括当前租户标识和被选中的第二存储数据子库的访问地址;
第二存储模块,用于将当前租户的数据存储到被选中的第二存储数据子库中。
进一步的,上述装置还包括:
查找模块,用于根据当前租户标识在元数据表中查找,以获取存储当前租户数据的第三存储数据子库的访问地址;存储数据库还包括第三存储数据子库;
数据操作模块,用于根据获取到的第三存储数据子库的访问地址,对第三存储数据子库进行数据操作,其中,数据操作包括读数据和写数据。
进一步的,数据操作模块具体用于:
根据获取到的第三存储数据子库的访问地址,读取待迁移数据;待迁移数据为第三存储数据子库中存储的数据;
将待迁移数据存储至目标存储数据库中,并将待迁移数据从访问的第三存储数据子库中删除;
将元数据表中与当前租户标识对应的第三存储数据子库的访问地址修改为目标存储数据库的地址。
进一步的,数据操作模块具体用于:
获取当前租户的操作类型,操作类型包括读操作和写操作;第三存储数据子库包括读数据库和写数据库;
根据操作类型对读数据库或者写数据库进行相应操作。
本发明提供的分布式数据库实现方法及装置,通过在元数据库中添加第一存储数据子库与已有租户标识之间的关系,来将第一存储数据子库添加到存储数据库中,从而实现系统存储架构的可伸缩,并且将租户数据存储在存储数据库中,以实现分布式存储及处理。
附图说明
在下文中将基于实施例并参考附图来对本发明进行更详细的描述。其中:
图1为本发明实施例一提供的分布式数据库实现方法的第一流程示意图;
图2为本发明实施例一提供的分布式数据库实现方法的第二流程示意图;
图3为本发明实施例一提供的分布式数据库实现方法的第三流程示意图;
图4为本发明实施例一提供的分布式数据库实现方法的第四流程示意图;
图5为本发明实施例一提供的分布式数据库实现方法的第五流程示意图;
图6为本发明实施例二提供的分布式数据库实现装置的第一结构示意图;
图7为本发明实施例二提供的分布式数据库实现装置的第二结构示意图;
图8为本发明实施例二提供的分布式数据库实现装置的第三结构示意图。
在附图中,相同的部件使用相同的附图标记。附图并未按照实际的比例绘制。
具体实施方式
下面将结合附图对本发明作进一步说明。
实施例一
图1为本发明实施例一提供的分布式数据库实现方法的流程示意图;如图1所示,本实施例提供一种分布式数据库实现方法,包括步骤101-步骤104。
其中,步骤101,在元数据表中生成第一新增数据,第一新增数据包括已有租户标识和对应的第一存储数据子库的访问地址;分布式数据库包括检索数据库和存储数据库,其中,检索数据库用于存储元数据表;存储数据库用于存储数据,且包括第一存储数据子库。
具体的,检索数据库用于存储元数据表,元数据表包括多项元数据信息,每条元数据信息均包括已有租户与相应的存储数据库的相关信息。在访问时,首先访问检索数据库中的元数据表,并根据元数据表中的信息进行下一步操作。存储数据库用于存放已有租户的数据。第一存储数据子库包括在存储数据库中。已有租户为已经将数据存储到存储数据库中的租户,每个已有租户均设置有唯一的已有租户标识。
本步骤通过在元数据表中添加第一新增数据,该数据包括已有租户标识和第一存储数据子库的访问地址,该步骤的目的是为了将第一存储数据子库添加到分布式数据库(即存储数据库)中。
步骤102,根据第一存储数据子库的存储容量和已有租户的数量,确定第一剩余租户的数量,其中,第一剩余租户为第一存储数据子库中还能够存储的当前租户的数量。
当前租户为需要将数据存储到存储数据库中的租户,或者需要对存储数据库进行访问的租户。在本步骤中,计算第一存储数据子库还可以存储的当前租户的数量,以便后续判断是否需要将当前租户的数据存储在第一存储数据子库中。
步骤103,若第一剩余租户的数量满足预设条件,则在元数据库表中生成第二新增数据,第二新增数据包括当前租户标识和对应的第一存储数据子库的访问地址。
预设条件根据实际情况进行设置,如当前租户的数量为2个,那么预设条件可设置为大于或等于2,此时,计算出的第一剩余租户的数量若大于或等于2,则说明当前租户的数据可以存储在第一存储数据子库中。因此,在元数据库表中生成第二新增数据,以记录当前租户与第一存储数据子库之间的关系。
步骤104,将当前租户的数据存储到第一存储数据子库中。
本实施例提供的分布式数据库实现方法,通过在元数据库中添加第一存储数据子库与已有租户标识之间的关系,来将第一存储数据子库添加到存储数据库中,从而实现系统存储架构的可伸缩,在进行数据访问时,由于不同租户的数据所存储的位置可以不同,可实现多个租户对数据的同时访问,突破了单存储系统的性能瓶颈,同时,由于可存在多个存储数据子库,根据存储数据子库的存储容量进行存储分配,极大地优化了数据存储不均衡的缺陷。
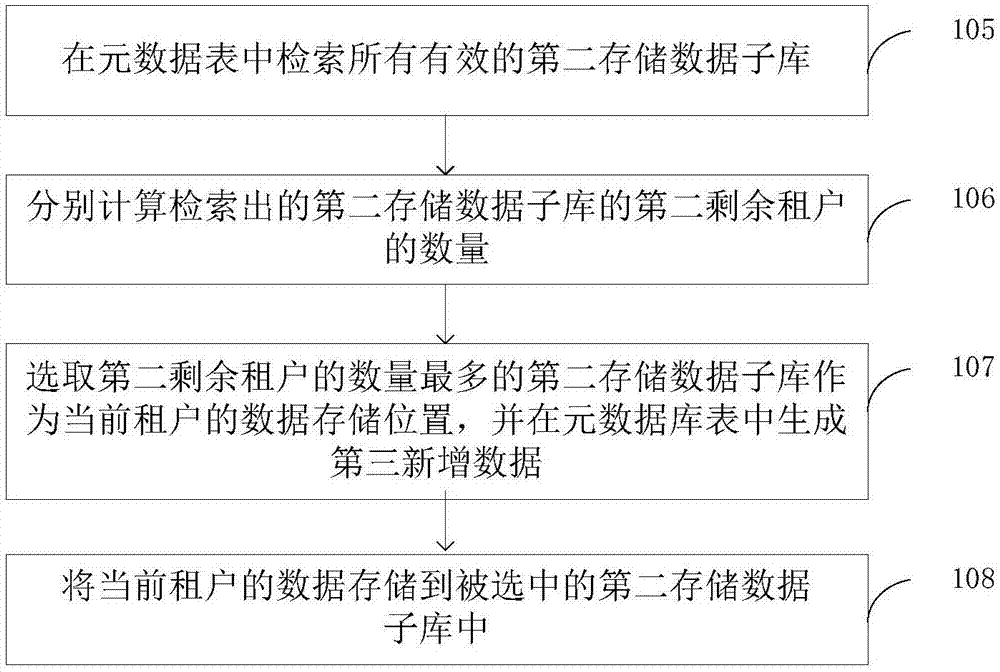
如图2所示,在本发明另一个具体实施例中,分布式数据库实现方法还包括步骤105-步骤108,用于为当前租户选择数据存储位置。
其中,步骤105,在元数据表中检索所有有效的第二存储数据子库;存储数据库还包括第二存储数据子库。若第二存储数据子库还能存储当前租户的数据,表明该第二存储数据子库有效。
步骤106,分别计算检索出的第二存储数据子库的第二剩余租户的数量;其中,第二剩余租户为检索出的第二存储数据子库中还能够存储的当前租户的数量。
根据步骤105的检索结果,计算检索出的每个第二存储数据子库的第二剩余租户的数量,以为当前租户的数据存储指定合适的存储位置。
步骤107,选取第二剩余租户的数量最多的第二存储数据子库作为当前租户的数据存储位置,并在元数据库表中生成第三新增数据,其中,第三新增数据包括当前租户标识和被选中的第二存储数据子库的访问地址。
将步骤106中计算出的第二剩余租户的数量进行筛选,选择第二剩余租户的数量最多的第二存储数据子库作为当前租户的数据存储位置。若值最大的第二剩余租户的数量不止一个,那么随机选择一个值最大的第二剩余租户的数量所对应的第二存储数据子库作为当前租户的数据存储位置。
步骤108,将当前租户的数据存储到被选中的第二存储数据子库中。
如图3所示,在本发明又一个具体实施例中,分布式数据库实现方法还包括步骤109-步骤110,用于当前租户对其所存储的数据进行操作。
步骤109,根据当前租户标识在元数据表中查找,以获取存储当前租户数据的第三存储数据子库的访问地址;存储数据库还包括第三存储数据子库。
步骤110,根据获取到的第三存储数据子库的访问地址,对第三存储数据子库进行数据操作,其中,数据操作包括读数据和写数据。
如图4所示,在本发明一个具体实施例中,步骤110具体包括步骤110a-步骤110c,本实施例用于对已有租户数据进行迁移,以将已有租户数据迁移到目标存储数据库中。
其中,步骤110a,据获取到的第三存储数据子库的访问地址,读取待迁移数据;待迁移数据为第三存储数据子库中存储的数据。
步骤110b,将待迁移数据存储至目标存储数据库中,并将待迁移数据从访问的第三存储数据子库中删除。
步骤110c,将元数据表中与当前租户标识对应的第三存储数据子库的访问地址修改为目标存储数据库的地址。
如图5所示,在本发明另一个具体实施例中,步骤110具体包括步骤110a-步骤110b,本实施例用于根据操作类型对已有租户数据进行访问,以将读操作和写操作分开,进一步提高数据访问效率。
其中,步骤110a,获取当前租户的操作类型,操作类型包括读操作和写操作;第三存储数据子库包括读数据库和写数据库。在本步骤中确定当前租户的操作类型,以便后续确定访问读数据库还是写数据库。
步骤110b,根据操作类型对读数据库或者写数据库进行相应操作。若操作类型为读操作,那么访问读数据库,若操作类型为写操作,则访问写数据库。读数据库中存储的数据仅能读取,而不能更改,写数据库中数据可被增加、更改或者删除,同时读数据库和写数据库中存储的数据相同,且当对写数据库中的数据进行增加、更改或者删除等写操作之后,需将读数据库中的相应数据做同步处理,以使读数据库和写数据库中存储的数据始终保持一致。
实施例二
图6为本发明实施例二提供的分布式数据库实现装置的结构示意图;如图6所示,本实施例提供一种分布式数据库实现装置,包括第一新增数据添加模块201、第一剩余租户计算模块202、第二新增数据添加模块203和第一存储模块204。
其中,第一新增数据添加模块201,用于在元数据表中生成第一新增数据,第一新增数据包括已有租户标识和对应的第一存储数据子库的访问地址;分布式数据库包括检索数据库和存储数据库,其中,检索数据库用于存储元数据表;存储数据库用于存储数据,且包括第一存储数据子库;
第一剩余租户计算模块202,用于根据第一存储数据子库的存储容量和已有租户的数量,确定第一剩余租户的数量,其中,第一剩余租户为第一存储数据子库中还能够存储的当前租户的数量;
第二新增数据添加模块203,用于若第一剩余租户的数量满足预设阈值,则在元数据库表中生成第二新增数据,第二新增数据包括当前租户标识和对应的第一存储数据子库的访问地址;
第一存储模块204,用于将当前租户的数据存储到第一存储数据子库中。
如图7所示,在本发明一个具体实施例中,上述装置还包括检索模块205、第二剩余租户计算模块206、选择模块207和第二存储模块208。
其中,检索模块205,用于在元数据表中检索所有有效的第二存储数据子库;存储数据库还包括第二存储数据子库;
第二剩余租户计算模块206,用于分别计算检索出的第二存储数据子库的第二剩余租户的数量;其中,第二剩余租户为检索出的第二存储数据子库中还能够存储的当前租户的数量;
选择模块207,用于选取第二剩余租户的数量最多的第二存储数据子库作为当前租户的数据存储位置,并在元数据库表中生成第三新增数据,其中,第三新增数据包括当前租户标识和被选中的第二存储数据子库的访问地址;
第二存储模块208,用于将当前租户的数据存储到被选中的第二存储数据子库中。
如图8所示,在本发明一个具体实施例中,上述装置还包括查找模块209和数据操作模块210。
其中,查找模块209,用于根据当前租户标识在元数据表中查找,以获取存储当前租户数据的第三存储数据子库的访问地址;存储数据库还包括第三存储数据子库;
数据操作模块210,用于根据获取到的第三存储数据子库的访问地址,对第三存储数据子库进行数据操作,其中,数据操作包括读数据和写数据。
在本发明一个具体实施例中,数据操作模块210具体用于根据获取到的第三存储数据子库的访问地址,读取待迁移数据;待迁移数据为第三存储数据子库中存储的数据;将待迁移数据存储至目标存储数据库中,并将待迁移数据从访问的第三存储数据子库中删除;将元数据表中与当前租户标识对应的第三存储数据子库的访问地址修改为目标存储数据库的地址。
在本发明另一个具体实施例中,数据操作模块210具体用于获取当前租户的操作类型,操作类型包括读操作和写操作;第三存储数据子库包括读数据库和写数据库;根据操作类型对读数据库或者写数据库进行相应操作。
实施例二是与实施例一对应的装置实施例,具体可参见实施例一中相应的描述,在此不做限定。
虽然已经参考优选实施例对本发明进行了描述,但在不脱离本发明的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,各个实施例中所提到的各项技术特征均可以任意方式组合起来。本发明并不局限于文中公开的特定实施例,而是包括落入权利要求的范围内的所有技术方案。
- 还没有人留言评论。精彩留言会获得点赞!