一种大规模流式集合数据的分布式处理方法与流程
本发明涉及一种大规模流式集合数据的分布式处理方法,属于计算机数据处理技术领域。
背景技术:
随着大数据和物联网技术的发展以及在多个关键领域的普及,在工业互联网、气象信息网等重要应用领域中实时产生着大规模流式集合数据。流式集合数据的特点是:不同集合的数据成员都流式地产生,但仅当每个集合中的数据成员全部完备才可以进行处理。例如,在智慧气象领域中极为重要的集合预报数据,需要按照大气动力学方程的多个初始条件计算气象模式解,得到的多个数值解将构成一个完整的集合,而不同集合数据在全球各地的气象部门中是以流式方式产生的;要进行集合预报,就需要每个集合中的所有数据成员都到齐才可以进行。对于大规模流式集合数据这一重要的数据类型,现有的单机系统和简单的分布式系统都无法高效地处理,成为制约相关领域技术升级和业务增强的瓶颈之一。在复杂的数据产生环境下,如何快速有效的处理大规模流式集合数据,已成为分布式系统和大数据处理领域的一个重要问题。
面对如今庞大的计算任务,采用分布式计算系统的方案在工业界得到了广泛认可,如国内的百度、阿里巴巴、腾讯等都部署了大规模的分布式计算系统,用于海量数据的高效处理。随着分布式计算系统在各行各业优越的表现,一方面分布式计算系统的解决方案越来越多,同时越来越成熟,另一方面绝大部分的分布式计算系统面向大众提供开源的代码,降低了分布式计算系统使用的门槛,方便对分布式计算系统进行更好的学习使用和改进。虽然使用分布式计算系统进行大规模数据的高效处理已经成为主流的大数据解决方案,如何对大规模流式集合数据这一新的数据类型进行高效处理和持久化仍然是一个开放性问题,已经成为工业界聚焦的重要问题,也是大数据的前沿课题之一。
技术实现要素:
本发明的目的是提出一种大规模流式集合数据的分布式处理方法,针对目前大规模流式集合数据处理的问题,采用分布式消息系统记录集合数据完备状态,采用分布式存储系统对流式集合数据持久化,采用分布式计算系统进行批量高效处理,上述三个系统共同实现大规模流式集合数据的高效处理和存储。
本发明提出的大规模流式集合数据的分布式处理方法,包括以下步骤:
(1)监控系统从数据源接收集合数据,将接收的集合数据记为
(2)根据集合数据
(3)监控系统将集合数据
(4)监控系统访问分布式存储系统,对分布式存储系统的写入队列长度进行判断,若wcurrent<wmax,进入步骤(5),若wcurrent≥wmax,重复本步骤;
(5)分布式计算系统从分布式消息系统队列中q中获取消息,即集合数据s在分布式存储系统中的表名以及行、列位置,设定分布式计算系统最少处理的消息阈值为lmin,获取消息的时间阈值为tmax,记当前获取消息的等待时间为twait,对分布式消息系统中的消息队列q进行判断,若分布式消息系统的消息队列q中lcurrent≥lmin,且twait≤tmax,则分布式计算系统从分布式消息系统的消息队列q中获取消息,进入步骤(6),若分布式消息系统的队列q中lcurrent<lmin,或twait>tmax,则放弃本次获取的消息,返回上述步骤(2);
(6)分布式计算系统根据获取的消息,即集合数据s在分布式存储系统中的表名以及行、列位置,从分布式存储系统中获取相应的集合数据,并对从分布式存储系统中获取的集合数据进行判断,若分布式存储系统中存在与获取的消息相对应的集合数据,则进行步骤(7),若分布式存储系统中不存在与获取的消息相对应的集合数据,则返回上述步骤(2);
(7)分布式计算系统根据步骤(6)获得的集合数据,通过处理算法和业务逻辑对集合数据进行分布式的处理和计算,得到计算结果,并通知监控系统计算完成;
(8)记分布式计算系统写入分布式存储系统的最大等待时间为savemax,当前等待时间为savecurrent,监控系统对分布式计算系统写入分布式存储系统的等待时间进行判断,若savecurrent≥savemax,则返回步骤(6),若savecurrent<savemax,则监控系统根据获取的消息,即集合数据在分布式存储系统中的表名以及行、列位置,将分布式计算结果存储到分布式存储系统的相应位置。
本发明提出的大规模流式集合数据的分布式处理方法,其优点是:
1、本发明提出的大规模流式集合数据的分布式处理方法,可以有效的控制流式集合数据的处理流程,并利用集合数据的批量式计算提高系统的资源利用率。
2、本发明的大规模流式集合数据的分布式处理方法,基于分布式计算系统设计,可以快速、有效地处理目前日益增长的流式集合数据,并结合可视化界提供系统参数调整,降低了系统的使用门槛。
3、本发明的大规模流式集合数据的分布式处理方法,其中的分布式消息系统、分布式计算系统、分布式存储系统均支持快速动态的拓展,可迭代计算,十分适用于工业物联网、气象信息网等典型的大数据应用场景。
附图说明
图1是本发明提出的大规模流式集合数据的分布式处理方法的功能框架图。
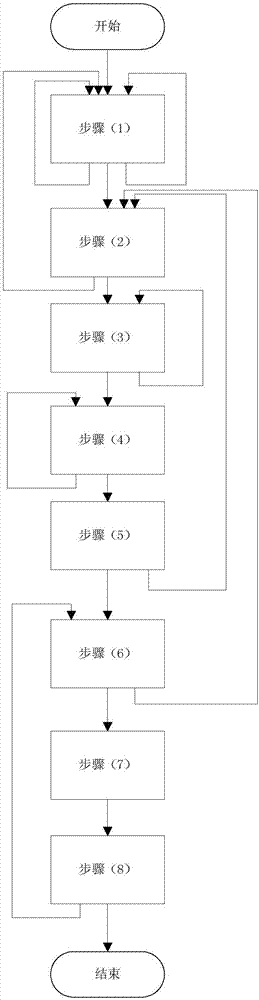
图2是本发明方法中各步骤的流程框图。
图3是本发明方法中步骤(1)的流程框图。
图4是本发明方法中步骤(2)的流程框图。
图5是本发明方法中步骤(3)的流程框图。
图6是本发明方法中步骤(4)的流程框图。
图7是本发明方法中步骤(5)的流程框图。
图8是本发明方法中步骤(6)的流程框图。
图9是本发明方法中步骤(7)的流程框图。
图10是本发明方法中步骤(8)的流程框图。
具体实施方式
本发明提出的大规模流式集合数据的分布式处理方法,其功能框架图如图1所示,其各步骤的流程框图如图2所示,包括以下步骤:
(1)监控系统从数据源接收集合数据,将接收的集合数据记为
(2)根据集合数据
(3)监控系统将集合数据
(4)由于需要往分布式存储系统写入数据,监控系统访问分布式存储系统,对分布式存储系统的写入队列长度进行判断,若wcurrent<wmax,进入步骤(5),若wcurrent≥wmax,此时分布式存储系统写入压力过大,分布式计算系统等待分布式存储系统完成写入任务,重复本步骤,其流程框图如图6所示;
(5)分布式计算系统从分布式消息系统队列中q中获取消息,即集合数据s在分布式存储系统中的表名以及行、列位置,设定分布式计算系统最少处理的消息阈值为lmin,获取消息的时间阈值为tmax,记当前获取消息的等待时间为twait,对分布式消息系统中的消息队列q进行判断,若分布式消息系统的消息队列q中lcurrent≥lmin,且twait≤tmax,则分布式计算系统从分布式消息系统的消息队列q中获取消息,进入步骤(6),若分布式消息系统的队列q中lcurrenr<lmin,或twait>tmax,则放弃本次获取的消息,返回上述步骤(2),其流程框图如图7所示;
(6)分布式计算系统根据获取的消息,即集合数据s在分布式存储系统中的表名以及行、列位置,从分布式存储系统中获取相应的集合数据,并对从分布式存储系统中获取的集合数据进行判断,若分布式存储系统中存在与获取的消息相对应的集合数据,则进行步骤(7),若分布式存储系统中不存在与获取的消息相对应的集合数据,则返回上述步骤(2),其流程框图如图8所示;
(7)分布式计算系统根据步骤(6)获得的集合数据,通过处理算法和业务逻辑对集合数据进行分布式的处理和计算,得到计算结果,并通知监控系统计算完成,其流程框图如图9所示;
(8)由于集合数据不断的流式到来,因此分布式计算完成后,分布式存储系统压力可能过大,监控系统需要协调两者的处理。记分布式计算系统写入分布式存储系统的最大等待时间为savemax,当前等待时间为savecurrent,监控系统对分布式计算系统写入分布式存储系统的等待时间进行判断,若savecurrent≥savemax,则返回步骤(6),若savecurrent<savemax,则监控系统根据获取的消息,即集合数据在分布式存储系统中的表名以及行、列位置,将分布式计算结果存储到分布式存储系统的相应位置,其流程框图如图10所示。
- 还没有人留言评论。精彩留言会获得点赞!